sekacorn/CodeSummarizer
GitHub: sekacorn/CodeSummarizer
一款基于 Tauri 和本地 Ollama 模型的隐私优先桌面应用,专为敏感环境下的开发者提供离线代码摘要、解释和风险扫描功能。
Stars: 1 | Forks: 0
# 代码摘要器
[](https://github.com/sekacorn/CodeSummarizer/releases/latest)
[](https://github.com/sekacorn/CodeSummarizer/actions/workflows/windows-release.yml)
[](LICENSE)



一款**本地优先、隐私优先、支持离线**的桌面应用程序,用于利用本地 AI 模型分析代码片段。它专为那些需要在不将源码发送到互联网的情况下理解代码的开发者而构建,特别是那些在不允许使用云工具的敏感环境中工作的初级开发者。由 Tauri (Rust) 和 React (TypeScript) 构建。
## 截图
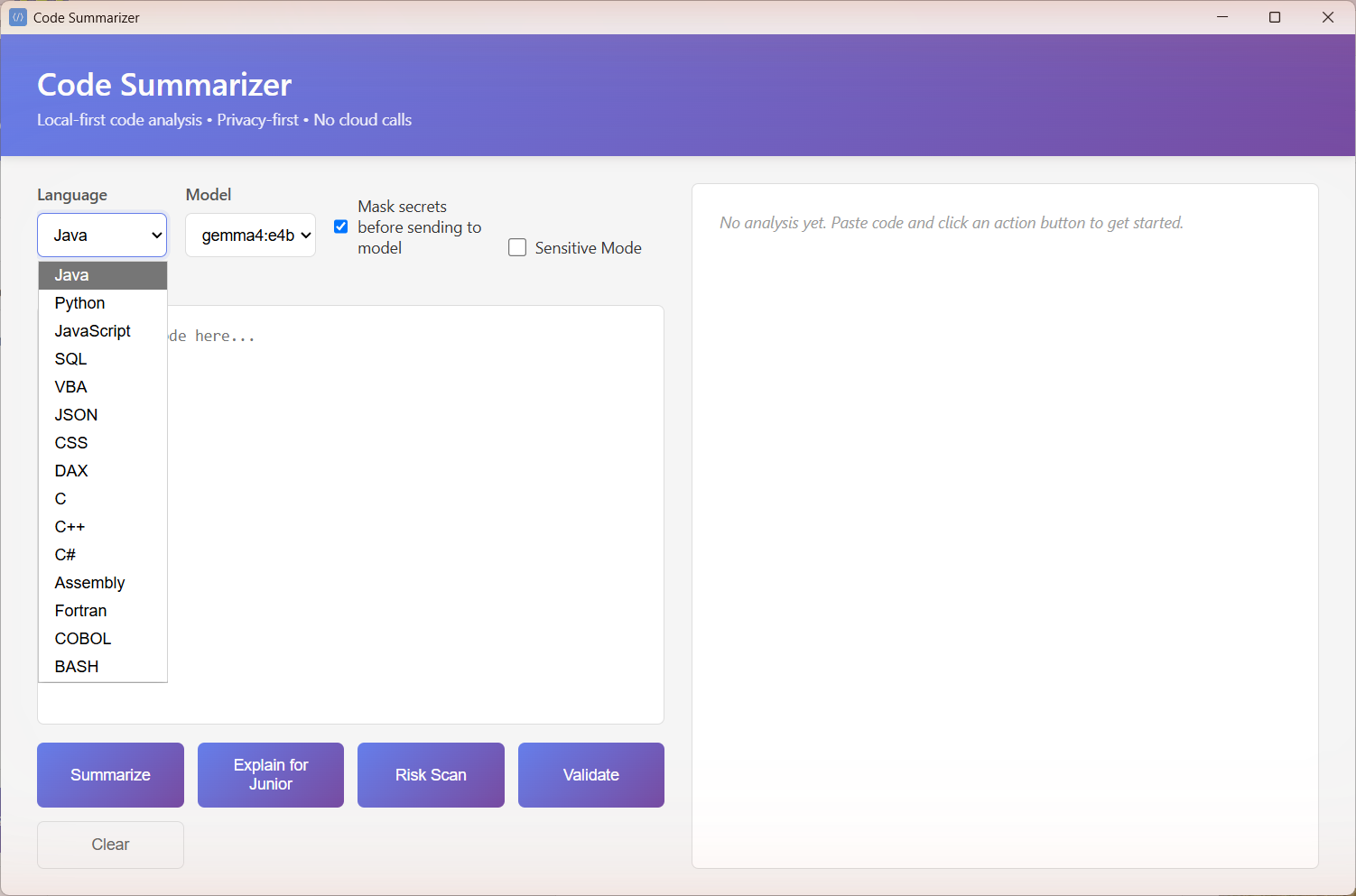
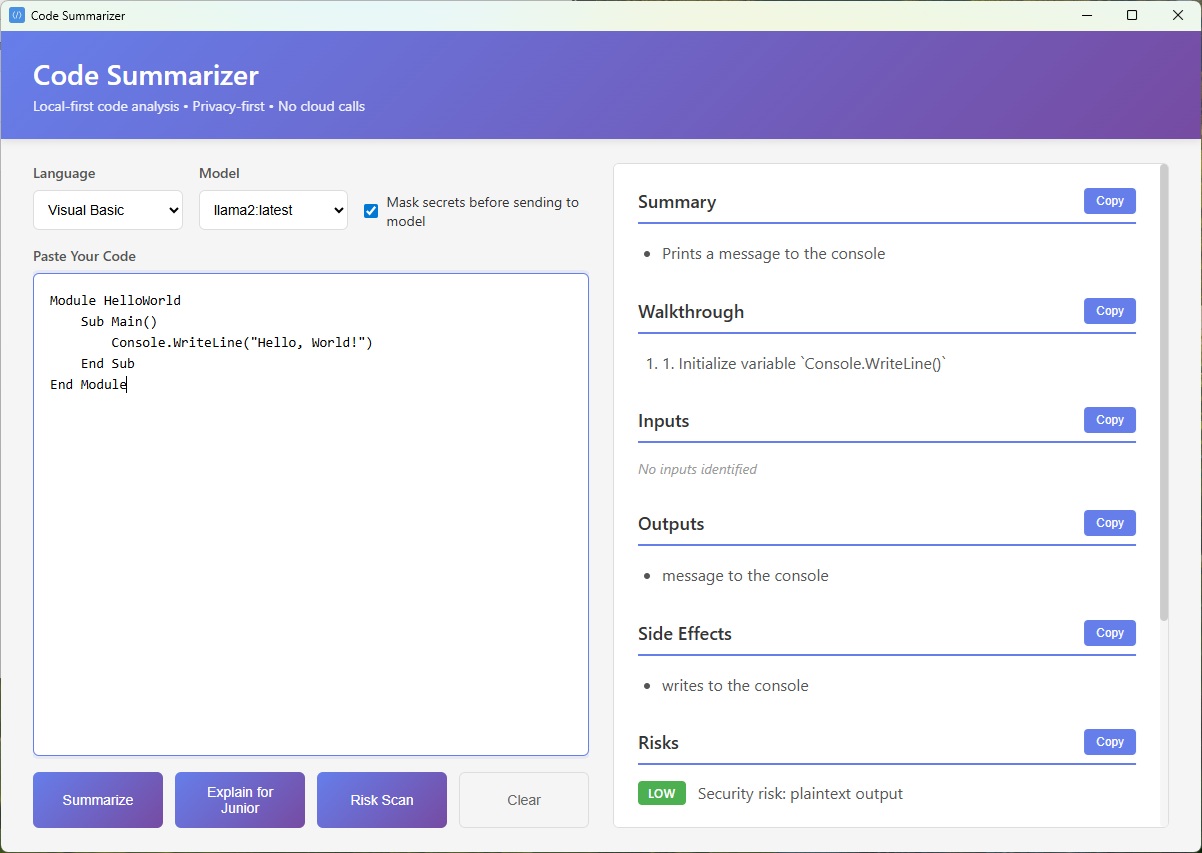
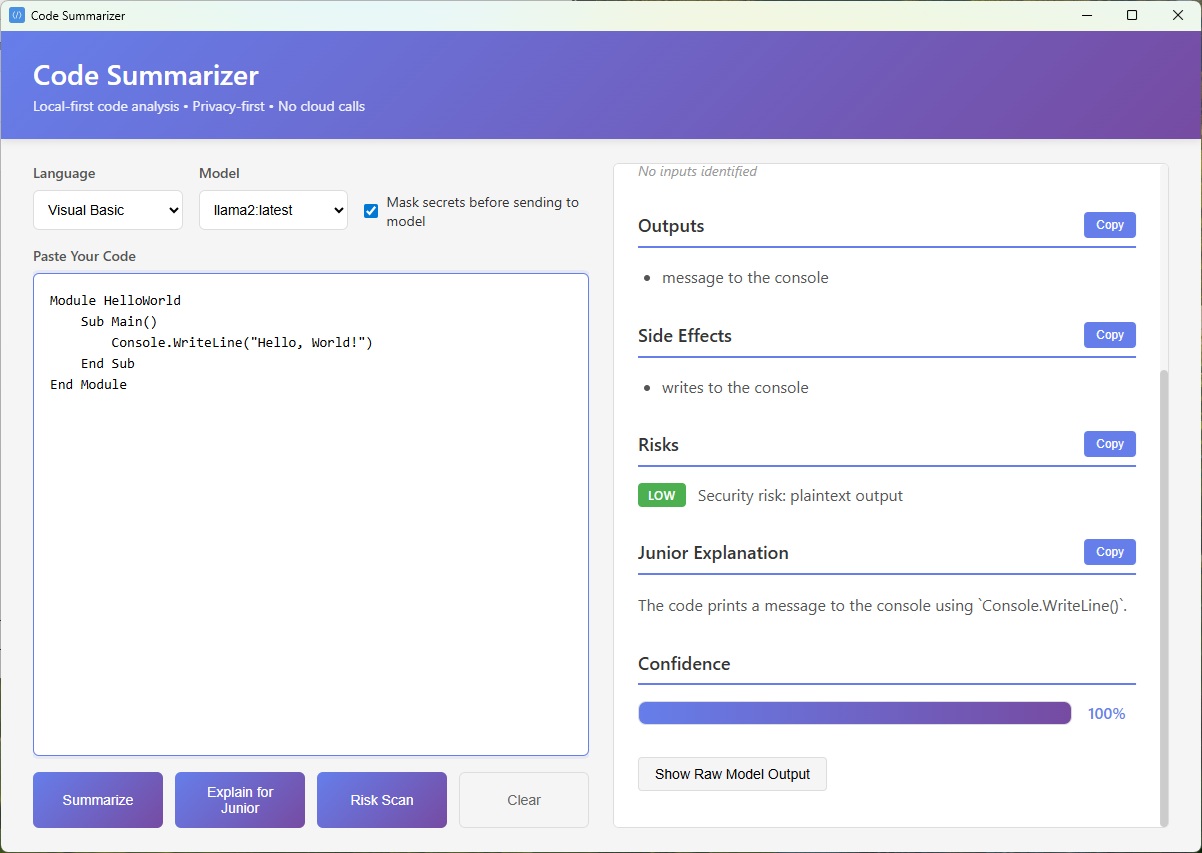
## 解决的问题
许多开发者,尤其是初级开发者,经常会遇到这样的情况:他们需要快速获得关于代码的解答,却无法安全地将代码粘贴到在线 AI 工具、论坛或第三方网站中。
这在**政府、受监管、涉密相关或其他敏感工作**中变得尤为重要,在这些环境中:
- 代码可能包含机密的业务逻辑、内部架构或受保护的数据模式
- 互联网访问可能受到限制或不鼓励使用
- 批准的工具必须在本地运行
- 高级开发者并不总是能立即有空来解释不熟悉的代码或审查复杂的代码片段
Code Summarizer 正是为了填补这一空白而设计的:
- 你需要帮助来理解代码
- 你需要**立即**获得帮助
- 你不能依赖基于云的开发助手
- 你仍然希望在不暴露敏感材料的情况下获得可靠、结构化的答案
这个项目源于一个真实的需求:在经验丰富的开发者无法提供帮助时需要完成任务的协助,同时仍需尊重隐私和环境限制。
## 卖点
- **100% 本地化**:所有处理都在你的机器上完成。没有云端调用,没有外部 AI API。
- **设计上的隐私优先**:你潜在的敏感代码会保留在你的计算机上。
- **专为敏感工作流构建**:适用于政府、企业、受监管或物理隔离风格的环境。
- **对初级开发者友好**:当你需要指导且没有高级开发者在场时,用通俗易懂的语言解释代码。
- **密钥保护**:在将代码发送到本地模型之前,自动检测并可以掩盖密钥。
- **支持离线**:一旦在本地安装了 Ollama 和你的模型,无需互联网访问即可工作。
- **多种分析模式**:获取摘要、适合初学者的解释、安全风险评估或语法验证。
- **桌面应用,不依赖浏览器**:是一个专注的本地应用程序,而不是需要信任外部基础设施的网络服务。
## 为什么选择 Code Summarizer?
- 在你需要解释、合理性检查或快速风险审查时,**充当本地编码助手**
- 比基于云的聊天工具**更适合敏感代码**
- 当团队成员不可用时,**有助于入职和自我排障**
- **结构化的输出**使得在内部审查、复制和分享脱敏后的发现变得更容易
- 使用 Ollama 进行**简单的本地设置**,保持技术栈易于理解和审计
## 功能
- **支持分析的语言**:Java、Python、JavaScript、SQL、VBA、JSON、CSS、DAX、C、C++、C#、Assembly、Fortran、COBOL、BASH、PL/SQL、T-SQL、SAS、R、MATLAB、VHDL、Verilog、SystemVerilog、VB.NET、Pascal、Delphi/Object Pascal、ABAP、XML、XSLT、Terraform/HCL
- **分析模式**:
- **Summarize(摘要)**:通过结构化分解获得简洁的概述
- **Explain for Junior(初级解释)**:适合初学者的解释和详细的代码走读
- **Risk Scan(风险扫描)**:以安全为重点的分析,突出潜在的漏洞
- **Validate(验证)**:基于 LLM 的验证,检查可能的语法错误和结构问题,并在模型能够推断时提供行/列位置
- **密钥扫描**:检测 AWS 密钥、JWT token、密码、API 密钥、PEM 密钥和 Bearer token
- **结构化输出**:经过 JSON 验证的响应,包含摘要、代码走读、输入、输出、副作用、风险和置信度分数等部分
- **复制功能**:可将任何部分单独复制到剪贴板
### “支持”的含义
在这个项目中,支持某种语言意味着:
- 你可以在应用中选择它
- 所选的语言会被传入 prompt,以便本地模型在该语言上下文中分析代码片段
- 你可以对它使用所有四种分析模式:Summarize(摘要)、Explain for Junior(初级解释)、Risk Scan(风险扫描)和 Validate(验证)
它目前**不**意味着:
- 专门的编译器集成
- 语言服务器集成
- 形式化解析器或基于 AST 的验证器
- 保证编译器级别准确的语法检查
**Validate** 功能目前是**模型引导的验证**,不能替代为该语言运行真正的编译器、解释器、linter 或汇编器。
## 适用人群
- 使用不熟悉代码库的初级开发者
- 在政府或安全敏感环境中工作的开发者
- 由于隐私或合规限制而无法使用云 AI 工具的团队
- 希望拥有一个仅限本地的助手来解释代码片段、检查风险和验证结构的工程师
## 典型用例
- 在没有高级工程师可用时理解遗留函数
- 从内部任务中获取对代码片段的初级友好解释
- 在要求正式审查之前审查代码的明显风险
- 在将工作交接给队友之前验证语法或结构
- 安全地检查不应离开受保护环境的代码
## 前置条件
发布版本用户需要:
1. Windows 10 或 Windows 11(64 位)
2. **Ollama**,需从 [ollama.com](https://ollama.com/) 单独下载并安装
3. 至少一个本地 Ollama 模型
MSI 和 NSIS 安装程序包含离线的 Microsoft Edge WebView2 安装程序。发布版本用户**不需要** Node.js 或 Rust。从源码构建的开发者需要 Node.js 22 和稳定的 Rust 工具链。
## 安装说明
### Windows 发布版本
1. 从 [GitHub Releases](https://github.com/sekacorn/CodeSummarizer/releases) 下载 NSIS `Setup.exe`(推荐大多数用户使用)或 MSI。
2. 下载 `SHA256SUMS.txt` 并验证文件,例如:
Get-FileHash .\CodeSummarizer-1.0.0-windows-x64-setup.exe -Algorithm SHA256
3. 运行安装程序。未签名的社区构建可能会显示 Microsoft SmartScreen 警告;在继续之前,请验证校验和和发布来源。
4. 按照下文所述安装 Ollama 并拉取模型。
当不允许安装时,便携版 ZIP 非常有用。解压并运行 `Code Summarizer.exe`;它要求已安装 WebView2。有关安装程序、静默安装、卸载和打包的详细信息,请参阅 [WINDOWS_RELEASE.md](WINDOWS_RELEASE.md)。
### 1. 安装 Ollama
从 [ollama.com](https://ollama.com/) 下载并安装 Ollama。Ollama 及其模型文件不由 Code Summarizer 捆绑、安装、更新或许可。
### 2. 拉取模型
安装 Ollama 后,拉取一个模型。**根据你可用的 RAM 进行选择:**
```
# 非常轻量 - 约 650MB model,适用于 2-4GB RAM 的系统
ollama pull tinyllama
# 轻量级 - 约 2GB model,需要 4-6GB 系统 RAM
ollama pull llama2
# 更高质量 - 约 4GB model,需要 8GB+ 系统 RAM
ollama pull codellama
# 高质量 - 约 4.5GB model,需要 8GB+ 系统 RAM
ollama pull mistral
```
**重要提示**:每个模型在运行时需要大约其大小 2 倍的 RAM。如果出现内存错误,请使用较小的模型。
验证 Ollama 是否正在运行:
```
ollama list
```
### 3. 从源码构建(仅限开发者)
```
# Clone the repository
git clone https://github.com/sekacorn/CodeSummarizer.git
cd CodeSummarizer
# 运行 setup script(检查 prerequisites、安装 deps、生成 icons、运行 tests)
# Windows:
setup.bat
# macOS/Linux:
chmod +x setup.sh && ./setup.sh
```
或者,如果你更喜欢手动操作:
```
npm ci
npm run generate-icons
```
**注意**:如果图标缺失,你可以随时使用 `npm run generate-icons` 重新生成它们。
## 运行应用程序
### 开发模式
```
npm run tauri dev
```
这将:
1. 启动 Vite 开发服务器
2. 编译 Rust 后端
3. 启动应用程序窗口
### 生产 Windows 构建
```
npm run tauri:build:windows
```
验证过的 MSI、NSIS 安装程序、便携版 ZIP 和 SHA-256 清单将位于 `artifacts/` 目录中。
## 用法
1. **启动 Ollama**:确保 Ollama 正在运行(`ollama serve`)
2. **启动应用程序**:从“开始”菜单启动已安装的应用程序(或者在开发时使用 `npm run tauri dev`)
3. **选择语言**:选择你的代码所使用的编程语言
4. **选择模型**:从下拉菜单中选择一个 Ollama 模型
5. **配置密钥掩盖**:切换“Mask secrets before sending to model”(默认开启)
6. **粘贴代码**:在文本区域中输入你的代码
7. **选择操作**:
- 点击 **Summarize** 获取高级概述
- 点击 **Explain for Junior** 获取适合初学者的解释
- 点击 **Risk Scan** 获取安全分析
- 点击 **Validate** 检查语法错误(显示行号和列号)
8. **查看结果**:右侧面板将显示带有可复制部分的结构化分析
### 敏感环境下的推荐工作流
1. 在批准的机器上本地运行 Ollama
2. 保持启用 **“Mask secrets before sending to model”**
3. 仅粘贴你需要帮助理解的代码片段
4. 如果你需要通俗语言的指导,请从 **Explain for Junior** 开始
5. 在审查可能涉及身份验证、数据访问或外部系统的代码时,使用 **Risk Scan**
6. 当你需要快速的本地语法或结构检查时,使用 **Validate**
## 故障排除
### Ollama 未运行
**错误**:“Ollama is not running. Please start Ollama and try again.”
**解决方案**:
```
# 启动 Ollama server
ollama serve
```
或者如果 Ollama 是作为服务安装的,请确保它正在后台运行。
### 未找到模型
**错误**:“No models found. Please pull a model using 'ollama pull '.”
**解决方案**:
```
# Pull a model
ollama pull llama2
# 验证已安装
ollama list
```
### 内存不足错误
**错误**:“model requires more system memory (X GiB) than is available (Y GiB)”
**解决方案**:
这意味着你选择的模型对于系统的可用 RAM 来说太大了。每个模型在运行时大约需要其下载大小 2 倍的系统内存。
```
# 适用于 2-4GB RAM 的系统
ollama pull tinyllama
# 适用于 4-6GB RAM 的系统
ollama pull llama2
# 适用于 8GB+ RAM 的系统
ollama pull codellama
ollama pull mistral
```
拉取较小的模型后,在应用程序的下拉菜单中选择它,然后重试。
### 请求超时 / CPU 上运行缓慢
**错误**:“Request to Ollama timed out. The model may be too large or your system may be slow.”
**解决方案**:
- 使用较小的模型(例如,使用 `tinyllama` 或 `llama2` 代替 `codellama`)
- 确保 Ollama 配置为使用 GPU(如果可用)
- 关闭其他资源密集型应用程序
- 增加超时时间(需要修改 `src-tauri/src/commands/ollama.rs` 中的代码)
### 未找到模型
**错误**:“Model 'xyz' not found. Please pull it using 'ollama pull xyz'.”
**解决方案**:
```
ollama pull
```
### JSON 解析失败
**问题**:模型输出不是有效的 JSON
**解释**:有时模型不严格遵守 JSON 格式,尤其是较小的模型。
**解决方案**:
- 尝试使用功能更强大的模型(例如,`mistral` 或 `codellama`)
- 勾选“Show Raw Model Output”以查看模型返回的内容
- 重试分析
### 端口冲突
如果你看到关于端口 1420 被占用的错误:
1. 停止任何其他 Vite/Tauri 开发服务器
2. 或者修改 `vite.config.ts` 中的端口
## 安全功能
### 密钥检测
应用程序会自动扫描:
- **AWS Access Keys**:模式 `AKIA[0-9A-Z]{16}`
- **JWT Tokens**:由点分隔的三个 base64url 片段
- **凭证**:password/secret/api_key 赋值
- **PEM Private Keys**:`-----BEGIN PRIVATE KEY-----` 块
- **Bearer Tokens**:带有 Bearer token 的 Authorization 标头
### 密钥掩盖
启用后(默认),在发送到本地模型之前,检测到的密钥将被替换为 `***REDACTED***`。
Sensitive Mode 在 Rust 命令边界独立强制执行脱敏,隐藏模型的原始输出,并禁用剪贴板导出。在处理响应期间,解析后的输出和原始模型输出仍会暂时存在于应用程序内存中。
### 无数据持久化
- 代码**绝不**会被此应用程序写入磁盘
没有关于你的代码的遥测或日志记录
- 所有处理均在内存中进行
### 仅限本地通信
- 所有模型请求都仅发送至 `http://127.0.0.1:11434`
- 不发起任何外部网络请求
- Rust 后端使用固定的环回 URL;前端无法选择其他 endpoint
## 架构
```
code-summarizer/
├── src/ # Frontend (React + TypeScript)
│ ├── components/ # React components
│ ├── lib/ # API, schemas, utilities
│ ├── App.tsx # Main application
│ ├── main.tsx # Entry point
│ └── styles.css # Styling
├── src-tauri/ # Backend (Rust)
│ ├── src/
│ │ ├── commands/ # Tauri commands
│ │ │ ├── ollama.rs # Ollama integration
│ │ │ ├── secrets.rs # Secret scanning
│ │ │ ├── prompt.rs # Prompt templates
│ │ │ └── types.rs # Shared types
│ │ └── main.rs # Tauri entry point
│ ├── Cargo.toml # Rust dependencies
│ └── tauri.conf.json # Tauri configuration
├── package.json # Node dependencies
└── vite.config.ts # Vite configuration
```
## 使用的技术
- **前端**:React 18、TypeScript、Vite、Zod(schema 验证)
- **后端**:Rust、Tauri、reqwest(HTTP 客户端)、regex(模式匹配)、serde(序列化)
- **AI**:Ollama(本地 LLM 服务器)
## 开发说明
### 图标生成
该应用使用自定义的图标生成脚本。图标会自动从 SVG 模板生成:
```
# 生成所有必需的 icon formats
npm run generate-icons
```
这会创建:
- Windows:`icon.ico`
- macOS:`icon.icns`
- Linux/Web:各种 PNG 尺寸(32x32、128x128 等)
生成的图标放置在 `src-tauri/icons/` 中。源文件(`app-icon.svg` 和 `app-icon.png`)是临时的,并被排除在 git 之外。
### 开发脚本
```
# 启动 dev server(仅 frontend)
npm run dev
# 以 dev mode 启动完整的 Tauri app
npm run tauri:dev
# Build for production
npm run tauri:build:windows
# 运行 TypeScript/schema tests、frontend build、Rust/redaction tests 和 release checks
npm run verify
# 生成 icons
npm run generate-icons
```
### 添加新语言
编辑 `src/lib/languages.ts` 并将你的语言添加到 `SUPPORTED_LANGUAGES` 中。
因为语言处理目前是基于 prompt 的,所以在列表中添加语言使其可用于 UI 中的模型驱动分析。它不会自动为该语言添加编译器感知或解析器感知的验证。
### 自定义 Prompts
修改 `src-tauri/src/commands/prompt.rs` 以调整不同分析模式的 prompt 构建方式。
### 添加新的密钥模式
在 `src-tauri/src/commands/secrets.rs` 的 `scan_for_secrets` 函数中添加 regex 模式。
## 许可证
本项目基于 GNU General Public License v3.0 或更高版本授权
(GPL-3.0-or-later)。详情请参阅 [LICENSE](LICENSE) 文件。
## 贡献
欢迎贡献!请确保:
- 代码通过 TypeScript 和 Rust 编译
- 密钥扫描测试通过
- UI 保持整洁且功能完善
- 坚持安全第一的原则
## 常见问题
**问:这会将我的代码发送到互联网吗?**
答:不会。所有处理都是 100% 本地的。该应用仅与运行在 localhost (127.0.0.1) 上的 Ollama 进行通信。
**问:我可以在离线状态下使用吗?**
答:可以,只要 Ollama 和所需的模型已经安装在本地并正在运行即可。
**问:这是为初级开发者准备的吗?**
答:是的。主要目标之一是帮助初级开发者在询问云端 AI 工具不可行、而高级开发者可能又无法立即提供帮助的环境中,安全地理解代码。
**问:为什么不直接使用 ChatGPT、Copilot 或其他在线工具?**
答:在许多敏感环境中,这可能是不被允许或不合适的。Code Summarizer 专为隐私、本地执行和零互联网依赖比云便利性更重要的情况而设计。
**问:这对政府或受监管的工作有用吗?**
答:这是核心用例之一。如果你的环境需要本地处理、最小的数据暴露且无外部 API 调用,那么这个应用就是为适应这种工作流而构建的。
**问:哪些模型效果最好?**
答:对于代码分析:
- **有限 RAM 下最佳 (2-4GB)**:`tinyllama` - 速度快但分析基础
- **均衡型 (4-6GB)**:`llama2` - 质量好且速度合理
- **最佳质量 (8GB+)**:`codellama` 或 `mistral` - 最准确的分析
请根据你可用的系统 RAM 进行选择。模型在运行时需要大约其大小 2 倍的内存。
**问:“Validate”功能是否为每种语言使用真正的编译器或解析器?**
答:不。目前,Validate 使用本地语言模型来识别可能的语法、类型和结构问题。它对于快速的本地反馈很有用,但不应将其视为真正的编译器、解释器、linter、shell 检查器、汇编器或特定语言工具链的替代品。
**问:为什么分析很慢?**
答:在 CPU 上进行 LLM 推理可能会很慢。建议在 Ollama 中使用 GPU 加速的配置,或者使用更小的模型。
**问:我可以分析大文件吗?**
答:该应用程序专为代码片段而设计。非常大的文件可能会达到模型的 token 限制。请将它们分解为较小的逻辑部分。
## 支持
如有问题或疑问:
- 查看上方的故障排除部分
- 验证 Ollama 是否正在运行且已安装模型
- 检查浏览器/开发者控制台是否有错误(在开发模式下)
## 安全
有关项目的安全策略、限制、漏洞报告流程以及在敏感环境中评估该应用的指导,请参阅 [SECURITY.md](SECURITY.md)。
其他以审查为导向的文档:
- [PRIVACY.md](PRIVACY.md)
- [THREAT_MODEL.md](THREAT_MODEL.md)
- [ARCHITECTURE.md](ARCHITECTURE.md)
- [WINDOWS_RELEASE.md](WINDOWS_RELEASE.md)
- [RELEASE_NOTES.md](RELEASE_NOTES.md)
- [AUDIT_READINESS.md](AUDIT_READINESS.md)
- [RESTRICTED_DEPLOYMENT.md](RESTRICTED_DEPLOYMENT.md)
**专为在不放弃隐私的情况下需要帮助的开发者而构建。你的代码将保留在你的机器上。**
标签:AI辅助编程, AI风险缓解, Rust, SOC Prime, Tauri, 代码摘要, 可视化界面, 开发工具, 本地AI, 网络安全, 网络流量审计, 通知系统, 隐私保护