flamehaven01/AI-SLOP-Detector
GitHub: flamehaven01/AI-SLOP-Detector
检测 AI 生成代码中的空函数、幻觉导入和虚假文档,在 CI/CD 中阻止劣质代码进入生产环境。
Stars: 64 | Forks: 6

AI-SLOP Detector









捕捉 AI 生成的“烂代码”——在它们进入生产环境之前。
问题不在于 AI 会写代码。
问题在于 AI 会引入一类特定的缺陷:
未实现的桩代码、断开的 pipeline、幻觉导入,以及充满流行术语的噪音。
代码本身会说话。
**导航:**
[快速开始](#quick-start) •
[v3.0.2 更新内容](#whats-new-in-v302) •
[v3.0.0 更新内容](#whats-new-in-v300) •
[检测内容](#what-it-detects) •
[评分模型](#scoring-model) •
[结构一致性](#structural-coherence) •
[自校准](#self-calibration) •
[历史追踪](#history-tracking) •
[CI/CD](#cicd-integration) •
[文档](docs/) •
[更新日志](CHANGELOG.md)
## 快速开始
```
pip install ai-slop-detector
slop-detector mycode.py # single file
slop-detector --project ./src # entire project
slop-detector mycode.py --json # machine-readable output
slop-detector --project . --ci-mode hard --ci-report # CI gate
# 可选附加组件
pip install "ai-slop-detector[js]" # JS/TS tree-sitter analysis
pip install "ai-slop-detector[ml]" # ML secondary signal
pip install "ai-slop-detector[ml-data]" # real training data pipeline
# uvx(无需安装)
uvx ai-slop-detector mycode.py
```
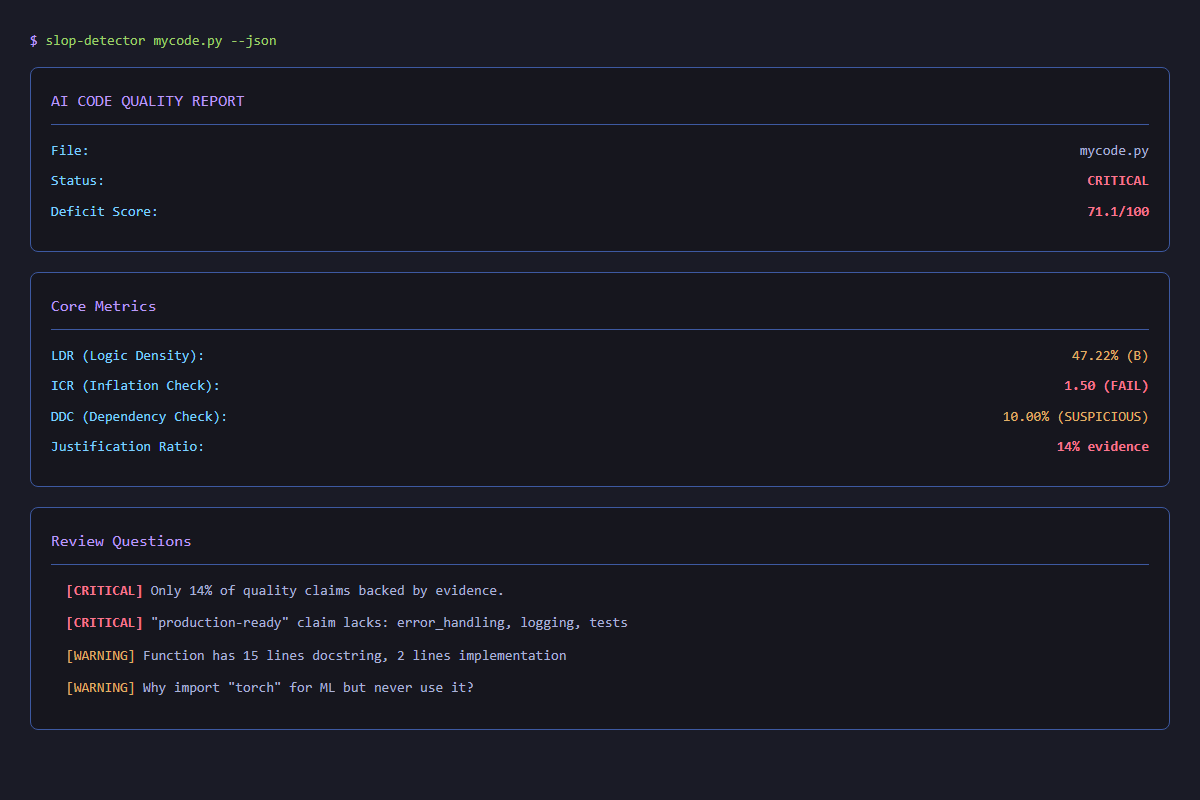
## v3.0.2 更新内容
### 幻觉导入误报消除
`PhantomImportPattern` 现在会在标记任何内容之前,先理解项目自身的包及其可选依赖项。之前的版本对自己扫描的项目一无所知 —— 每个 `src/` 布局的内部导入和每个被保护的可选依赖都会触发 CRITICAL 命中,这会通过 GQG 级联,导致每个文件的 `deficit_score → 100`。
三级分类(取代了原先的一刀切 CRITICAL):
| 等级 | 条件 | 严重程度 |
|---|---|---|
| Internal | 模块解析为当前项目 | (跳过) |
| Guarded | 位于 `try/except ImportError` / `Exception` 块内 | MEDIUM |
| Hard phantom | 无法解析且无保护 | CRITICAL |
项目包会自动从 `pyproject.toml` 的 `[project.dependencies]`、`[project.optional-dependencies]` 以及 `src/` 目录布局中发现 —— 无需配置。
### LDR 不再因空的 `__init__.py` 而崩溃
一个空的包初始化文件(`src/mypkg/__init__.py`,零内容行)之前会产生 `total_lines=0 → ldr_score=0.0 → GQG ln(1e-4) → deficit_score=100`。
v3.0.2 检测到这种情况并返回 `ldr_score=1.0, grade="N/A", is_packaging_init=True`。
`is_packaging_init` 标志已在 JSON 输出中暴露,供下游工具使用。
### GodFunctionPattern:长但简单的路径降级为 LOW
超过行数阈值但圈复杂度较低(`cc ≤ 5`)的函数现在被标记为 LOW 而不是 HIGH。这消除了针对物理常数表、路由分发块和领域规则列表的误报 —— 这些代码故意写得冗长,但在结构上并不复杂。
只有超过复杂度阈值的函数才会被标记为 HIGH,无论其长度如何。
### 占位符模式精度
- `NotImplementedPattern` —— 跳过带有 `@abstractmethod` 装饰器的方法(正确的 ABC 模式)。
- `EmptyExceptPattern` —— 3 级:裸 `except: pass` → CRITICAL;`except ImportError: pass` → LOW 并提示“可选依赖保护”;带类型的 `except X: pass` → MEDIUM。
- `InterfaceOnlyClassPattern` —— `return self` / `return cls` 方法链桩代码现在计入占位符阈值。
## v3.0.0 更新内容
### 几何平均数取代算术平均数进行评分
之前的评分模型在三个维度(LDR、inflation、DDC)上使用加权算术平均数。算术平均数允许一个维度的高分部分抵消另一个维度的低分。
v3.0.0 切换到加权几何平均数:
```
quality = exp( sum(w_i * ln(max(1e-4, v_i))) / sum(w_i) )
```
任何单一维度的近零值都会将结果显著拉低,无论其他维度如何。这更好地反映了质量实际上是如何下降的 —— 一个导入使用率为 5% 的文件是糟糕的,即使其逻辑密度很高。
增加了第四个维度:`purity = exp(-0.5 * n_critical_patterns)`。
这使得 CRITICAL 严重级别的模式命中(幻觉导入等)产生复合效应,而不是在指标分数上简单叠加。
| 维度 | 来源 | 权重 |
|---|---|---|
| `ldr` | Logic Density Ratio | 配置 (默认 0.40) |
| `inflation_q` | `1 - normalized_inflation` | 配置 (默认 0.30) |
| `ddc` | Import usage ratio | 配置 (默认 0.20) |
| `purity` | `exp(-0.5 * n_critical_patterns)` | 固定 0.10 |
### 每个文件的 AST 节点类型分布
每个分析的文件现在都包含一个 `dcf` 字段:文件中每种 AST 节点类型的归一化频率。
```
result = detector.analyze_file("mycode.py")
print(result.dcf)
# {'FunctionDef': 0.12, 'Return': 0.09, 'Call': 0.14, 'Pass': 0.002, ...}
```
这是下述项目级结构距离指标的基础。
它也可以通过 `--json` 输出供外部工具使用。
### 项目级结构距离指标
`analyze_project()` 现在计算文件之间在 AST 节点类型组成上的相似度。
```
project = detector.analyze_project("./src")
print(project.structural_coherence) # 0.0 - 1.0
print(project.coherence_level) # "vr_structural" | "none"
```
该值为 `1 - d`,其中 `d` 是文件分布间成对 sqrt-JSD 距离的最小生成树中的最长边。接近 1.0 的值意味着文件在结构上相似;较低的值表示文件间差异较大。
这是一个实验性指标。请谨慎解读 —— 一个异构项目(工具类 + 模型 + 测试)自然会比统一项目得分更低,这并不是缺陷。
**在 JSON 输出中:**
```
{
"structural_coherence": 0.91,
"coherence_level": "vr_structural"
}
```
## v2.9.3 更新内容
### 自校准 —— 工具学习您的代码库
默认权重(`ldr: 0.40, inflation: 0.30, ddc: 0.30`)是针对一个代码库调整的。它们可能不适合您的代码库。Django 项目的结构性样板代码比数据 pipeline 多。一个文档详尽的库其逻辑密度配置文件与微服务不同。
从 v2.9.3 开始,该工具会根据您的使用历史校准其自身的权重。
```
slop-detector . --self-calibrate # see what your history suggests
slop-detector . --self-calibrate --apply-calibration # write to .slopconfig.yaml
```
**一句话说明其工作原理:**
在得分不佳后您编辑过的文件被确认为真正的“烂代码”。尽管得分不佳但您忽略的文件可能是误报。引擎搜索能最大化前者并最小化后者的权重 —— 仅使用您自己的历史数据,无需外部数据。
**首次实时运行结果(Flamehaven 代码库,180 个文件,62 个已确认修复):**
| 维度 | 默认值 | 校准后 |
|---|---:|---:|
| ldr | 0.40 | 0.10 |
| inflation | 0.30 | 0.25 |
| ddc | 0.30 | **0.65** |
| 综合误差 | 1.1069 | **0.9985** |
| 置信度差距 | — | 0.1088 |
解读:此代码库的风格倾向于重文档且依赖使用有意义 —— 这里 DDC 是比逻辑密度更强的质量信号。
工具已适应这一点。您的工具也会适应您的风格。
更多数据 = 更好的校准。您用得越多,工具就越准确。
[完整文档:自校准 →](docs/SELF_CALIBRATION.md)
## v2.9.1 更新内容
### 自检补丁 —— 零亏损文件
v2.9.1 将工具应用于自身并修补发现的问题。
在其自己的代码库上运行 `slop-detector --project src/` 产生了三个亏损文件。这三个均已解决。
**之前 → 之后:**
| 指标 | v2.9.0 | v2.9.1 |
| :--- | ---: | ---: |
| 亏损文件 | 3 | **0** |
| 平均亏损分 | 11.65 | **9.57** |
| 加权亏损分 | 15.88 | **12.42** |
**修复内容:**
**`cli.py` (53.5 → 29.1)** —— 巨型函数分解。
`print_rich_report`、`main`、`generate_markdown_report`、`generate_text_report` 和 `_handle_output` 都超过了 50 行 / 复杂度 10 的阈值。
提取了 9 个专注的辅助函数;每个函数现在都符合限制。
**`registry.py` (39.5 → 干净)** —— DDC 误报 + `global` 语句。
`BasePattern` 仅为了类型注解而被导入。
`UsageCollector`(按设计)跳过注解,因此 DDC 将其评为 0% 使用。
修复:将仅用于注解的导入移至 `if TYPE_CHECKING:` 下。
还将惰性 `global _global_registry` 单例替换为积极的模块级初始化,移除了模式检测器标记的 `global` 语句。
**`question_generator.py` (30.0 → 干净)** —— 同样的 DDC 误报。
`FileAnalysis` 仅用于注解。同样的 `TYPE_CHECKING` 保护修复。
将 Python 3.10+ 联合语法(`int | None`, `str | None`)转换为 `Optional[int]`、`Optional[str]` 以兼容 Python 3.8。
## v2.9.0 更新内容
### `phantom_import` —— 幻觉包检测 (CRITICAL)
AI 模型有时会生成听起来合理但不存在的包名。
此功能在它们变成运行时 `ModuleNotFoundError` 之前捕捉它们。
```
import tensorflow_magic # CRITICAL — does not exist
from requests_async_v2 import get # CRITICAL — does not exist
import numpy # OK — installed
from os.path import join # OK — stdlib
from . import utils # OK — relative, excluded by design
```
解析顺序:`sys.builtin_module_names` → `sys.stdlib_module_names` → `importlib.metadata.packages_distributions()` → `importlib.util.find_spec`
完整规格:[docs/PHANTOM_IMPORT.md](docs/PHANTOM_IMPORT.md)
### 历史自动追踪
每次运行都会自动记录到 `~/.slop-detector/history.db`。
```
slop-detector mycode.py --show-history # per-file trend
slop-detector --history-trends # 7-day project aggregate
slop-detector --export-history data.jsonl # ML training export
slop-detector mycode.py --no-history # opt-out
```
```
History: src/mymodule.py
----------------------------------------------------------------------
Timestamp Deficit LDR Patterns Grade
----------------------------------------------------------------------
2026-03-06T09:12:43 42.0 0.631 7 suspicious
2026-03-07T11:03:21 18.0 0.812 3 clean
2026-03-08T14:55:09 0.0 1.000 0 clean
----------------------------------------------------------------------
Trend (3 runs): improved delta=-42.0
```
完整规格:[docs/HISTORY_TRACKING.md](docs/HISTORY_TRACKING.md)
## 检测内容
**5 个类别中的 25 种模式。** 完整目录:[docs/PATTERNS.md](docs/PATTERNS.md)
| 类别 | 模式 | 信号 |
|---|---|---|
| **Placeholder** | `empty_except`, `not_implemented`, `pass_placeholder`, `ellipsis_placeholder`, `return_none_placeholder`, `todo_comment`, `fixme_comment`, `hack_comment`, `xxx_comment`, `interface_only_class` | 未完成 / 脚手架代码 |
| **Structural** | `bare_except`, `mutable_default_arg`, `star_import`, `global_statement` | 反模式 |
| **Cross-Language** | `js_push`, `java_equals`, `ruby_each`, `go_print`, `csharp_length`, `php_strlen` | 错误语言语法 |
| **Python Advanced** | `god_function`, `dead_code`, `deep_nesting`, `lint_escape` | 结构复杂性 |
| **Phantom** | `phantom_import` | 幻觉包 |
除了模式外,每个文件还计算三个指标轴:
| 指标 | 衡量内容 |
|---|---|
| **LDR** (Logic Density Ratio) | `logic_lines / total_lines` —— 代码与空白/注释的比例 |
| **ICR** (Inflation) | `jargon_density × complexity_modifier` —— 流行术语权重 |
| **DDC** (Dependency Check) | `used_imports / total_imports` —— 导入利用率 |
## 评分模型
**v3.0.0:加权几何平均数**
```
purity = exp(-0.5 * n_critical_patterns)
quality = exp( (w_ldr*ln(ldr) + w_inf*ln(1-inf) + w_ddc*ln(ddc) + w_pur*ln(purity))
/ (w_ldr + w_inf + w_ddc + w_pur) )
deficit_score = 100 * (1 - quality) + pattern_penalty
```
| 分数 | 状态 |
|---|---|
| >= 70 | `CRITICAL_DEFICIT` |
| >= 50 | `INFLATED_SIGNAL` |
| >= 30 | `SUSPICIOUS` |
| < 30 | `CLEAN` |
项目聚合使用 SR9 保守加权计算 LDR:
`project_ldr = 0.6 × min(file_ldrs) + 0.4 × mean(file_ldrs)`
完整数学规格:[docs/MATH_MODELS.md](docs/MATH_MODELS.md)
## 结构一致性
```
project = detector.analyze_project("./src")
print(project.structural_coherence) # 0.0 - 1.0
```
报告文件在 AST 节点类型组成上的相似度。
`1.0` = 所有文件具有几乎相同的结构配置;较低的值 = 文件间差异较大。
这是一个实验性信号。异构项目(例如 CLI 代码 + 数据模型 + 测试)按设计会比统一项目得分更低。请将其用于同一项目内的纵向比较,而不是作为绝对的质量关卡。
## 自校准
默认权重有效。校准后的权重效果更好 —— 对您而言。
```
# 检查历史记录建议
slop-detector . --self-calibrate
# 自动应用到 .slopconfig.yaml
slop-detector . --self-calibrate --apply-calibration
# 在信任结果前需要更多数据
slop-detector . --self-calibrate --min-history 50
```
引擎从您的历史数据库中提取两个信号:
| 事件 | 定义 | 标签 |
|---|---|---|
| **Improvement** | 亏损分高 → 您编辑了文件 → 分数下降 | 真阳性 |
| **FP** | 亏损分高 → 同一文件,无更改,下次运行仍然糟糕 | 可能是误报 |
然后它对 200 多种权重组合进行网格搜索,并找到能最大限度减少遗漏的真实“烂代码”和不必要警报的组合 —— 针对您的特定代码库。
至少需要 10 个标记事件(随着您使用工具自动积累)。
只有当前两名候选者之间的置信度差距超过 0.10 时,才会写入结果 —— 这与 Copilot Guardian 多假设选择中使用的模式相同。
| 状态 | 含义 |
|---|---|
| `ok` | 找到可信的获胜者 —— `--apply-calibration` 写入配置 |
| `no_change` | 当前权重已接近最优 |
| `insufficient_data` | 需要更多历史记录,或候选者太接近而无法判断 |
[完整文档:自校准 →](docs/SELF_CALIBRATION.md)
## 历史追踪
历史数据库是纵向质量分析的基础。
在多次运行中从 `deficit=42` 提升到 `deficit=0` 的文件为 ML pipeline 提供独立的训练信号。
```
from slop_detector.history import HistoryTracker
tracker = HistoryTracker()
regression = tracker.detect_regression("src/api.py", current_score=55.0)
trends = tracker.get_project_trends(days=7)
count = tracker.export_jsonl("training.jsonl") # → DatasetLoader.load_jsonl()
```
[完整文档 →](docs/HISTORY_TRACKING.md)
## CI/CD 集成
```
# Soft — 提供信息,永不导致构建失败
slop-detector --project . --ci-mode soft --ci-report
# Hard — 在 deficit_score >= 70 或 critical_patterns >= 3 时导致构建失败
slop-detector --project . --ci-mode hard --ci-report
# Quarantine — 在 3 次违规后升级重复违规者
slop-detector --project . --ci-mode quarantine --ci-report
```
**GitHub Actions:**
```
- name: Slop Gate
run: |
pip install ai-slop-detector
slop-detector --project . --ci-mode hard --ci-report
```
[CI/CD 集成指南 →](docs/CI_CD.md)
## 配置
```
# .slopconfig.yaml
weights:
ldr: 0.40
inflation: 0.35
ddc: 0.25
thresholds:
ldr:
critical: 0.30
warning: 0.60
disabled_patterns:
- lint_escape # opt-out specific patterns
```
[完整配置指南 →](docs/CONFIGURATION.md)
## VS Code 扩展
实时内联诊断、防抖输入时检查、状态栏中的 ML 分数。
从 [VS Code Marketplace](https://marketplace.visualstudio.com/items?itemName=Flamehaven.vscode-slop-detector) 安装
或在本地构建:`cd vscode-extension && vsce package`
## 开发
```
git clone https://github.com/flamehaven01/AI-SLOP-Detector.git
cd AI-SLOP-Detector
pip install -e ".[dev]"
pytest tests/ -v --cov
black src/ tests/
ruff check src/ tests/
```
[开发指南 →](docs/DEVELOPMENT.md)
## 许可证
MIT —— 详见 [LICENSE](LICENSE)。
Flamehaven Labs •
Issues •
Discussions •
文档
标签:AIGC, AI代码检测, DevSecOps, DLL 劫持, 上游代理, 人工智能, 代码坏味道, 代码安全, 代码审查, 代码洁癖, 大语言模型, 威胁情报, 开发者工具, 技术债务, 数据管道, 漏洞枚举, 生产就绪, 用户模式Hook绕过, 空函数检测, 自动化payload嵌入, 虚假文档检测, 软件工程, 逆向工具, 错误基检测, 防范AI幻觉, 静态代码分析