Tzohar/PassLLM
GitHub: Tzohar/PassLLM
基于大语言模型和PII信息的针对性密码猜测框架,通过LoRA微调在消费级硬件上实现业界领先的密码预测准确率。
Stars: 104 | Forks: 13
# PassLLM:基于 AI 的针对性密码猜测
[](https://www.usenix.org/conference/usenixsecurity25/presentation/zou-yunkai)
[](https://www.gnu.org/licenses/gpl-3.0)
[](https://pytorch.org/)
[](https://www.python.org/downloads/)
[](https://developer.nvidia.com/cuda-toolkit)
[](https://colab.research.google.com/github/Tzohar/PassLLM/blob/main/PassLLM_Demo.ipynb)
[](mailto:passllm@proton.me)
## 关于本项目
**PassLLM 是世界上最准确的针对性密码猜测框架**,在大多数场景下[比其他模型高出 15% 到 45%](https://www.usenix.org/conference/usenixsecurity25/presentation/zou-yunkai)。它利用个人身份信息 (PII) —— 例如 *姓名、生日、电话号码、电子邮件和以前的密码* —— 来预测目标最有可能使用的特定密码。
该模型使用 LoRA 在数百万条泄露的 PII 记录上对 7B/4B 参数的 LLM 进行微调,从而实现了一个完全在消费级 PC 上运行的私有、高精度框架。
 ## 能力
* **最先进的准确率:** 在大多数场景下,比主要基准(RankGuess, TarGuess)实现 **+45% 的更高成功率**。
* **PII 推断:** 在信息充足的情况下,仅需 **100 次猜测** 即能成功猜出 **12.5% - 31.6%** 的典型用户密码。
* **高效微调:** 利用 *LoRA* 的自定义训练循环,在不牺牲模型推理能力的前提下降低显存 (VRAM) 使用量。
* **高级推断:** 实现论文算法以最大化概率,优先考虑最可能的候选项,而非随机采样。
* **数据驱动:** 可基于数百万条真实凭据进行训练,以学习人类创建密码的深层统计模式。
* **预训练权重:** 包含基于数百万条主要 PII 泄露事件(例如 Post Millennial, ClixSense)的真实记录以及 COMB 数据集预训练的鲁棒模型。
## 使用指南
### 安装
* **Python:** 3.10+
* **密码猜测:** 可在 **任意 GPU** 上运行,支持 Nvidia 或 AMD。标准的 CPU 或 Mac (M1/M2) 也足以运行预训练模型。
* **训练:** 支持 CUDA 的 NVIDIA GPU(推荐 RTX 3090/4090,Google Colab 的免费层级通常就足够了)。
```
# 1. 克隆仓库
git clone https://github.com/tzohar/PassLLM.git
cd PassLLM
# 2. 安装依赖(选择一项)
# Option A: Install from requirements (Recommended)
pip install -r requirements.txt
# Option B: Manual install
pip install torch torch-directml "transformers<5.0.0" peft datasets bitsandbytes accelerate gradio
```
### 配置
下载[训练好的权重](https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth) (~126 MB) 并将其放入 `models/` 目录。
*或者,通过终端下载:*
```
curl -L https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth -o models/PassLLM_LoRA_Weights.pth
```
安装并下载完成后,调整 WebUI 或 `src/config.py` 中的设置以匹配您的硬件。
| 硬件 | 操作系统 | 设备 | 4-Bit 量化 | Torch DType | 推断 Batch Size |
| --- | --- | --- | --- | --- | --- |
| **NVIDIA** | Any | `cuda` | ✅ **开启** (推荐) | `bfloat16` | 高 (64+) |
| **AMD** | Windows | `dml` | ❌ **关闭** | `float16` | 低 (8-16) |
| **AMD (RDNA 3+)** | Linux/WSL | `cuda` | ❌ **关闭** | `bfloat16` | 中 (64+) |
| **AMD (较旧)** | Linux/WSL | `cuda` | ❌ **关闭** | `float16` | 低 (8-16) |
| **CPU** | Any | `cpu` | ❌ **关闭** | `float32` | 低 (1-4) |
### 密码猜测 (预训练)
您可以使用图形界面 (WebUI) 或命令行来生成候选项。
#### 选项 A: WebUI (推荐)
1. **启动界面:**
```
python webui.py
```
2. **生成:**
* 打开本地 URL(例如 `http://127.0.0.1:7860`)。
* **选择模型:** 从下拉菜单中选择最新的模型。
* **输入 PII:** 在表单中填入目标的姓名、电子邮件、出生年份等信息。
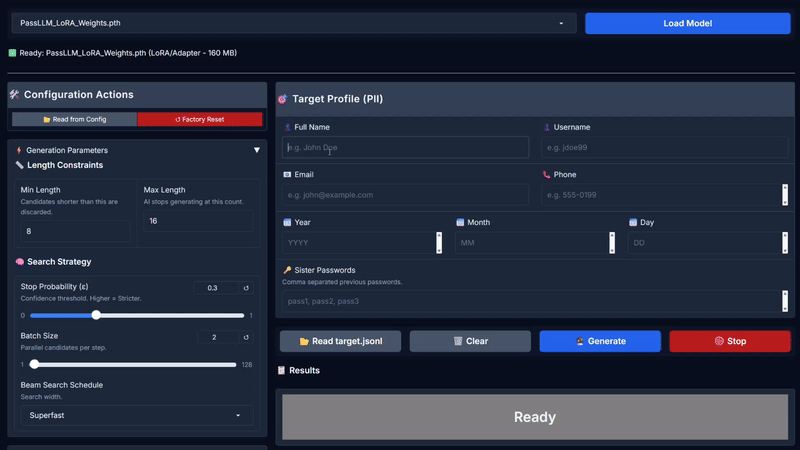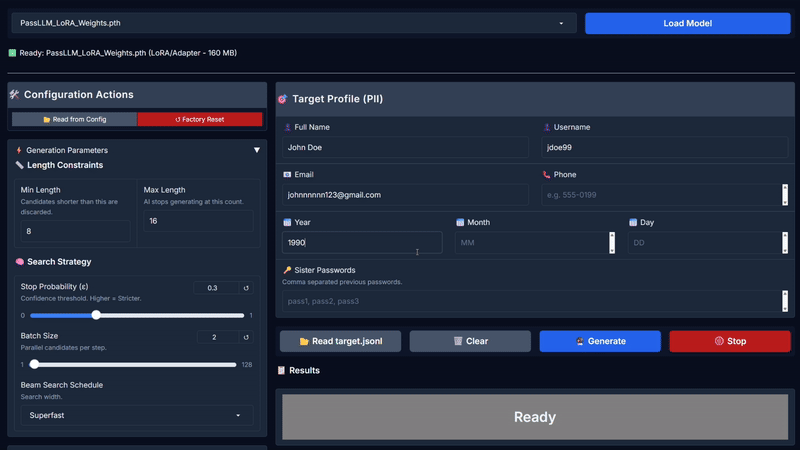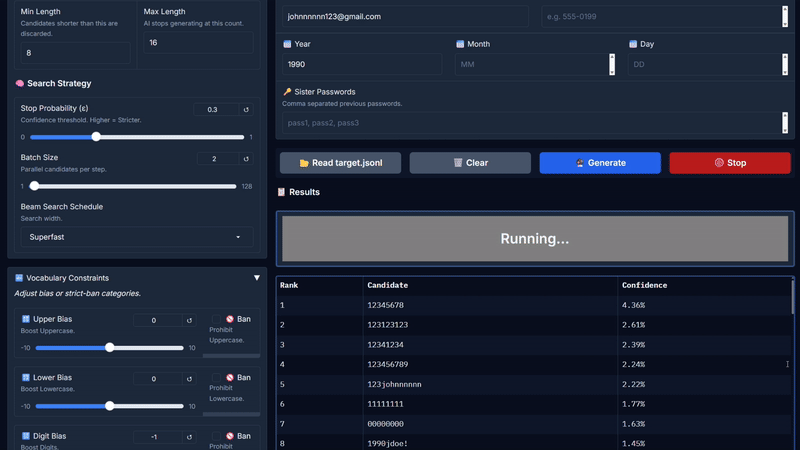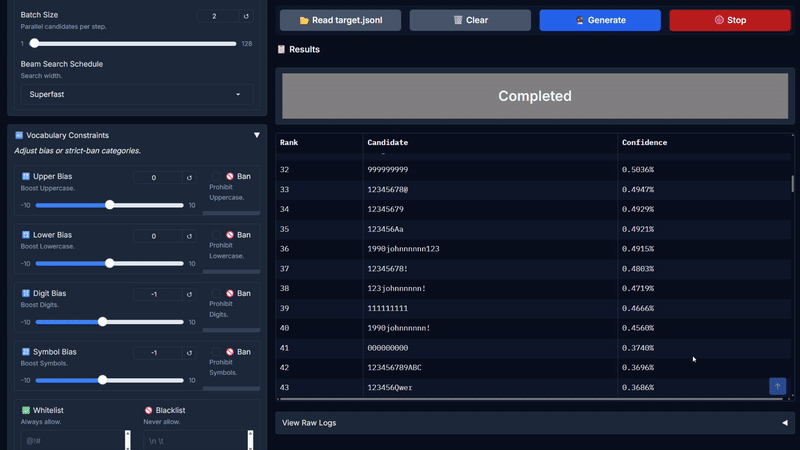
* **点击生成:** 引擎将实时流式输出排序后的候选项。
#### 选项 B: 命令行 (CLI)
最适合自动化或无头服务器。
1. **创建目标文件:**
在主文件夹中创建一个 `target.jsonl` 文件(或使用现有的)。您可以包含 `src/config.py` 中定义的任何字段。
```
{
"name": "Johan P.",
"birth_year": "1966",
"email": "johan66@gmail.com",
"sister_pw": "Johan123"
}
```
2. **运行引擎:**
```
python app.py --file target.jsonl --weights models/PassLLM-Qwen3-4B-v1.0.pth --fast
```
* `--file`: 您的目标 PII 文件的路径。
* `--fast`: 使用优化的浅层 Beam Search(省略此选项则进行完整的深层搜索)。
* `--weights`: 您下载的模型权重的路径(例如 .pth 文件)。
* `--superfast`: 非常快但准确率较低,主要用于测试。
### 基于数据库训练
要复现论文结果或在新的泄露数据上训练,您必须提供一个 **PII 到密码对** 的数据集。
1. **准备您的数据集:**
在 `training/passllm_raw_data.jsonl` 创建一个文件。每一行必须是一个有效的 JSON 对象,包含一个 `pii` 字典和目标 `output` 密码。
*示例 `passllm_raw_data.jsonl`:*
{"pii": {"name": "Alice", "birth_year": "1990"}, "output": "Alice1990!"}
{"pii": {"email": "bob@test.com", "sister_pw": "iloveyou"}, "output": "iloveyou2"}
*注意:确保您的键(例如 `first_name`, `email`)与 `src/config.py` 中定义的模式匹配。*
2. **配置参数:**
编辑 `src/config.py` 以匹配您的硬件和数据集细节:
# Hardware Settings
TRAIN_BATCH_SIZE = 4 # 如果在消费级 GPU 上遇到 OOM,请降至 1 或 2
GRAD_ACCUMULATION = 16 # 模拟更大的批次 (Effective Batch = 4 * 16 = 64)
# Model Settings
LORA_R = 16 # 秩维度 (标准复现请保持为 16)
VOCAB_BIAS_DIGITS = -4.0 # 非密码模式的惩罚强度
3. **开始训练:**
python train.py
此脚本会自动化整个流程:
* **冻结** 基础模型 (Mistral/Qwen)。
* **注入** 可训练的 LoRA 适配器到注意力层 (Attention layers)。
* **掩码** 损失函数,使模型只学习预测 *密码*,而不是 PII。
* **保存** 轻量级适配器权重到 `models/PassLLM_LoRA_Weights.pth`。
## 结果与演示
`{"name": "Marcus Thorne", "birth_year": "1976", "username": "mthorne88", "country": "Canada"}`:
```
$ python app.py --file target.jsonl --superfast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
1.96% | marcus1976
1.91% | thorne1976
1.20% | mthorne1976
1.19% | marc1976 (marc is a common diminutive of Marcus, used in many passwords)
1.18% | a123456 (a high-probability global baseline across users with similar PII)
1.16% | marci1976 (another common variation of Marcus)
1.01% | winniethepooh (our training dataset demonstrated Winnie-related passwords to be common in Canada)
... (907 passwords generated)
```
`{"name": "Elena Rodriguez", "birth_year": "1995", "birth_month": "12", "birth_day": "04", "email": "elena1.rod51@gmail.com", "id":"489298321"}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
8.55% | elena1204 (all variations of name + birth date are naturally given very high probability)
8.16% | elena1995
7.77% | elena951204
6.29% | elena9512
5.37% | Elena1995
5.32% | elena1.rod51
5.00% | 120495
... (5,895 passwords generated)
```
`{"name": "Sophia M. Turner", "birth_year": "2001", "pet_name": "Fluffy", "username": "soph_t", "email": "sturner99@yahoo.com", "country": "England", "sister_pw": ["soph12345", "13rockm4n", "01mamamia"]}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
2.93% | sophia123 (this is a mix of the target's first name and the sister password "soph12345")
2.53% | mamamia01 (a simple variation of another sister password)
1.96% | sophia2001
1.78% | sophie123 (UK passwords often interchange between "sophie" and "sophia")
1.45% | 123456a (a very commmon password, ranked high due to the "12345" pattern)
1.39% | sophiesophie1
1.24% | sturner999
... (10,169 passwords generated)
```
`{"name": "Omar Al-Fayed", "birth_year": "1992", "birth_month": "05", "birth_day": "18", "username": "omar.fayed92", "email": "o.alfayed@business.ae", "address": "Villa 14, Palm Jumeirah", "phone": "+971-50-123-4567", "country": "UAE", "sister_pw": "Amira1235"}`:
```
$ python app.py --file target.jsonl
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
79.75% | amira1235 (sister password, with lower case a)
43.77% | Ammira1235 (common pattern in reusing passwords)
19.14% | Omar1235 (drawing on the sister password pattern)
11.03% | Omar1234
8.52% | omarr.alfayid
8.20% | omar1235
7.52% | 051892
... (24,559 passwords generated)
```
## 免责声明
**使用前请仔细阅读本节。**
* **非官方实现:** 本代码库是研究论文 *"Password Guessing Using Large Language Models"* (USENIX Security 2025) 的独立复现和实现。我 **不是** 原始论文的作者,也未参与其研究或发表。概念和方法论的完全功劳归功于 **Yunkai Zou, Maoxiang An, 和 Ding Wang** (南开大学)。
* **仅限教育目的:** 此工具 **仅用于教育目的和安全研究**。旨在帮助安全专业人员、公司、机构和普通用户了解基于 LLM 的密码攻击风险并改进防御机制。
* **无责任:** 本代码库的作者不对本软件的任何滥用负责。您不得在未经明确授权同意的情况下使用此工具攻击目标。**严禁将本软件用于任何非法用途。**
## 能力
* **最先进的准确率:** 在大多数场景下,比主要基准(RankGuess, TarGuess)实现 **+45% 的更高成功率**。
* **PII 推断:** 在信息充足的情况下,仅需 **100 次猜测** 即能成功猜出 **12.5% - 31.6%** 的典型用户密码。
* **高效微调:** 利用 *LoRA* 的自定义训练循环,在不牺牲模型推理能力的前提下降低显存 (VRAM) 使用量。
* **高级推断:** 实现论文算法以最大化概率,优先考虑最可能的候选项,而非随机采样。
* **数据驱动:** 可基于数百万条真实凭据进行训练,以学习人类创建密码的深层统计模式。
* **预训练权重:** 包含基于数百万条主要 PII 泄露事件(例如 Post Millennial, ClixSense)的真实记录以及 COMB 数据集预训练的鲁棒模型。
## 使用指南
### 安装
* **Python:** 3.10+
* **密码猜测:** 可在 **任意 GPU** 上运行,支持 Nvidia 或 AMD。标准的 CPU 或 Mac (M1/M2) 也足以运行预训练模型。
* **训练:** 支持 CUDA 的 NVIDIA GPU(推荐 RTX 3090/4090,Google Colab 的免费层级通常就足够了)。
```
# 1. 克隆仓库
git clone https://github.com/tzohar/PassLLM.git
cd PassLLM
# 2. 安装依赖(选择一项)
# Option A: Install from requirements (Recommended)
pip install -r requirements.txt
# Option B: Manual install
pip install torch torch-directml "transformers<5.0.0" peft datasets bitsandbytes accelerate gradio
```
### 配置
下载[训练好的权重](https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth) (~126 MB) 并将其放入 `models/` 目录。
*或者,通过终端下载:*
```
curl -L https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth -o models/PassLLM_LoRA_Weights.pth
```
安装并下载完成后,调整 WebUI 或 `src/config.py` 中的设置以匹配您的硬件。
| 硬件 | 操作系统 | 设备 | 4-Bit 量化 | Torch DType | 推断 Batch Size |
| --- | --- | --- | --- | --- | --- |
| **NVIDIA** | Any | `cuda` | ✅ **开启** (推荐) | `bfloat16` | 高 (64+) |
| **AMD** | Windows | `dml` | ❌ **关闭** | `float16` | 低 (8-16) |
| **AMD (RDNA 3+)** | Linux/WSL | `cuda` | ❌ **关闭** | `bfloat16` | 中 (64+) |
| **AMD (较旧)** | Linux/WSL | `cuda` | ❌ **关闭** | `float16` | 低 (8-16) |
| **CPU** | Any | `cpu` | ❌ **关闭** | `float32` | 低 (1-4) |
### 密码猜测 (预训练)
您可以使用图形界面 (WebUI) 或命令行来生成候选项。
#### 选项 A: WebUI (推荐)
1. **启动界面:**
```
python webui.py
```
2. **生成:**
* 打开本地 URL(例如 `http://127.0.0.1:7860`)。
* **选择模型:** 从下拉菜单中选择最新的模型。
* **输入 PII:** 在表单中填入目标的姓名、电子邮件、出生年份等信息。
* **点击生成:** 引擎将实时流式输出排序后的候选项。
#### 选项 B: 命令行 (CLI)
最适合自动化或无头服务器。
1. **创建目标文件:**
在主文件夹中创建一个 `target.jsonl` 文件(或使用现有的)。您可以包含 `src/config.py` 中定义的任何字段。
```
{
"name": "Johan P.",
"birth_year": "1966",
"email": "johan66@gmail.com",
"sister_pw": "Johan123"
}
```
2. **运行引擎:**
```
python app.py --file target.jsonl --weights models/PassLLM-Qwen3-4B-v1.0.pth --fast
```
* `--file`: 您的目标 PII 文件的路径。
* `--fast`: 使用优化的浅层 Beam Search(省略此选项则进行完整的深层搜索)。
* `--weights`: 您下载的模型权重的路径(例如 .pth 文件)。
* `--superfast`: 非常快但准确率较低,主要用于测试。
### 基于数据库训练
要复现论文结果或在新的泄露数据上训练,您必须提供一个 **PII 到密码对** 的数据集。
1. **准备您的数据集:**
在 `training/passllm_raw_data.jsonl` 创建一个文件。每一行必须是一个有效的 JSON 对象,包含一个 `pii` 字典和目标 `output` 密码。
*示例 `passllm_raw_data.jsonl`:*
{"pii": {"name": "Alice", "birth_year": "1990"}, "output": "Alice1990!"}
{"pii": {"email": "bob@test.com", "sister_pw": "iloveyou"}, "output": "iloveyou2"}
*注意:确保您的键(例如 `first_name`, `email`)与 `src/config.py` 中定义的模式匹配。*
2. **配置参数:**
编辑 `src/config.py` 以匹配您的硬件和数据集细节:
# Hardware Settings
TRAIN_BATCH_SIZE = 4 # 如果在消费级 GPU 上遇到 OOM,请降至 1 或 2
GRAD_ACCUMULATION = 16 # 模拟更大的批次 (Effective Batch = 4 * 16 = 64)
# Model Settings
LORA_R = 16 # 秩维度 (标准复现请保持为 16)
VOCAB_BIAS_DIGITS = -4.0 # 非密码模式的惩罚强度
3. **开始训练:**
python train.py
此脚本会自动化整个流程:
* **冻结** 基础模型 (Mistral/Qwen)。
* **注入** 可训练的 LoRA 适配器到注意力层 (Attention layers)。
* **掩码** 损失函数,使模型只学习预测 *密码*,而不是 PII。
* **保存** 轻量级适配器权重到 `models/PassLLM_LoRA_Weights.pth`。
## 结果与演示
`{"name": "Marcus Thorne", "birth_year": "1976", "username": "mthorne88", "country": "Canada"}`:
```
$ python app.py --file target.jsonl --superfast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
1.96% | marcus1976
1.91% | thorne1976
1.20% | mthorne1976
1.19% | marc1976 (marc is a common diminutive of Marcus, used in many passwords)
1.18% | a123456 (a high-probability global baseline across users with similar PII)
1.16% | marci1976 (another common variation of Marcus)
1.01% | winniethepooh (our training dataset demonstrated Winnie-related passwords to be common in Canada)
... (907 passwords generated)
```
`{"name": "Elena Rodriguez", "birth_year": "1995", "birth_month": "12", "birth_day": "04", "email": "elena1.rod51@gmail.com", "id":"489298321"}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
8.55% | elena1204 (all variations of name + birth date are naturally given very high probability)
8.16% | elena1995
7.77% | elena951204
6.29% | elena9512
5.37% | Elena1995
5.32% | elena1.rod51
5.00% | 120495
... (5,895 passwords generated)
```
`{"name": "Sophia M. Turner", "birth_year": "2001", "pet_name": "Fluffy", "username": "soph_t", "email": "sturner99@yahoo.com", "country": "England", "sister_pw": ["soph12345", "13rockm4n", "01mamamia"]}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
2.93% | sophia123 (this is a mix of the target's first name and the sister password "soph12345")
2.53% | mamamia01 (a simple variation of another sister password)
1.96% | sophia2001
1.78% | sophie123 (UK passwords often interchange between "sophie" and "sophia")
1.45% | 123456a (a very commmon password, ranked high due to the "12345" pattern)
1.39% | sophiesophie1
1.24% | sturner999
... (10,169 passwords generated)
```
`{"name": "Omar Al-Fayed", "birth_year": "1992", "birth_month": "05", "birth_day": "18", "username": "omar.fayed92", "email": "o.alfayed@business.ae", "address": "Villa 14, Palm Jumeirah", "phone": "+971-50-123-4567", "country": "UAE", "sister_pw": "Amira1235"}`:
```
$ python app.py --file target.jsonl
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
79.75% | amira1235 (sister password, with lower case a)
43.77% | Ammira1235 (common pattern in reusing passwords)
19.14% | Omar1235 (drawing on the sister password pattern)
11.03% | Omar1234
8.52% | omarr.alfayid
8.20% | omar1235
7.52% | 051892
... (24,559 passwords generated)
```
## 免责声明
**使用前请仔细阅读本节。**
* **非官方实现:** 本代码库是研究论文 *"Password Guessing Using Large Language Models"* (USENIX Security 2025) 的独立复现和实现。我 **不是** 原始论文的作者,也未参与其研究或发表。概念和方法论的完全功劳归功于 **Yunkai Zou, Maoxiang An, 和 Ding Wang** (南开大学)。
* **仅限教育目的:** 此工具 **仅用于教育目的和安全研究**。旨在帮助安全专业人员、公司、机构和普通用户了解基于 LLM 的密码攻击风险并改进防御机制。
* **无责任:** 本代码库的作者不对本软件的任何滥用负责。您不得在未经明确授权同意的情况下使用此工具攻击目标。**严禁将本软件用于任何非法用途。**
## 能力
* **最先进的准确率:** 在大多数场景下,比主要基准(RankGuess, TarGuess)实现 **+45% 的更高成功率**。
* **PII 推断:** 在信息充足的情况下,仅需 **100 次猜测** 即能成功猜出 **12.5% - 31.6%** 的典型用户密码。
* **高效微调:** 利用 *LoRA* 的自定义训练循环,在不牺牲模型推理能力的前提下降低显存 (VRAM) 使用量。
* **高级推断:** 实现论文算法以最大化概率,优先考虑最可能的候选项,而非随机采样。
* **数据驱动:** 可基于数百万条真实凭据进行训练,以学习人类创建密码的深层统计模式。
* **预训练权重:** 包含基于数百万条主要 PII 泄露事件(例如 Post Millennial, ClixSense)的真实记录以及 COMB 数据集预训练的鲁棒模型。
## 使用指南
### 安装
* **Python:** 3.10+
* **密码猜测:** 可在 **任意 GPU** 上运行,支持 Nvidia 或 AMD。标准的 CPU 或 Mac (M1/M2) 也足以运行预训练模型。
* **训练:** 支持 CUDA 的 NVIDIA GPU(推荐 RTX 3090/4090,Google Colab 的免费层级通常就足够了)。
```
# 1. 克隆仓库
git clone https://github.com/tzohar/PassLLM.git
cd PassLLM
# 2. 安装依赖(选择一项)
# Option A: Install from requirements (Recommended)
pip install -r requirements.txt
# Option B: Manual install
pip install torch torch-directml "transformers<5.0.0" peft datasets bitsandbytes accelerate gradio
```
### 配置
下载[训练好的权重](https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth) (~126 MB) 并将其放入 `models/` 目录。
*或者,通过终端下载:*
```
curl -L https://github.com/Tzohar/PassLLM/releases/download/v1.3.0/PassLLM-Qwen3-4B-v1.0.pth -o models/PassLLM_LoRA_Weights.pth
```
安装并下载完成后,调整 WebUI 或 `src/config.py` 中的设置以匹配您的硬件。
| 硬件 | 操作系统 | 设备 | 4-Bit 量化 | Torch DType | 推断 Batch Size |
| --- | --- | --- | --- | --- | --- |
| **NVIDIA** | Any | `cuda` | ✅ **开启** (推荐) | `bfloat16` | 高 (64+) |
| **AMD** | Windows | `dml` | ❌ **关闭** | `float16` | 低 (8-16) |
| **AMD (RDNA 3+)** | Linux/WSL | `cuda` | ❌ **关闭** | `bfloat16` | 中 (64+) |
| **AMD (较旧)** | Linux/WSL | `cuda` | ❌ **关闭** | `float16` | 低 (8-16) |
| **CPU** | Any | `cpu` | ❌ **关闭** | `float32` | 低 (1-4) |
### 密码猜测 (预训练)
您可以使用图形界面 (WebUI) 或命令行来生成候选项。
#### 选项 A: WebUI (推荐)
1. **启动界面:**
```
python webui.py
```
2. **生成:**
* 打开本地 URL(例如 `http://127.0.0.1:7860`)。
* **选择模型:** 从下拉菜单中选择最新的模型。
* **输入 PII:** 在表单中填入目标的姓名、电子邮件、出生年份等信息。
* **点击生成:** 引擎将实时流式输出排序后的候选项。
#### 选项 B: 命令行 (CLI)
最适合自动化或无头服务器。
1. **创建目标文件:**
在主文件夹中创建一个 `target.jsonl` 文件(或使用现有的)。您可以包含 `src/config.py` 中定义的任何字段。
```
{
"name": "Johan P.",
"birth_year": "1966",
"email": "johan66@gmail.com",
"sister_pw": "Johan123"
}
```
2. **运行引擎:**
```
python app.py --file target.jsonl --weights models/PassLLM-Qwen3-4B-v1.0.pth --fast
```
* `--file`: 您的目标 PII 文件的路径。
* `--fast`: 使用优化的浅层 Beam Search(省略此选项则进行完整的深层搜索)。
* `--weights`: 您下载的模型权重的路径(例如 .pth 文件)。
* `--superfast`: 非常快但准确率较低,主要用于测试。
### 基于数据库训练
要复现论文结果或在新的泄露数据上训练,您必须提供一个 **PII 到密码对** 的数据集。
1. **准备您的数据集:**
在 `training/passllm_raw_data.jsonl` 创建一个文件。每一行必须是一个有效的 JSON 对象,包含一个 `pii` 字典和目标 `output` 密码。
*示例 `passllm_raw_data.jsonl`:*
{"pii": {"name": "Alice", "birth_year": "1990"}, "output": "Alice1990!"}
{"pii": {"email": "bob@test.com", "sister_pw": "iloveyou"}, "output": "iloveyou2"}
*注意:确保您的键(例如 `first_name`, `email`)与 `src/config.py` 中定义的模式匹配。*
2. **配置参数:**
编辑 `src/config.py` 以匹配您的硬件和数据集细节:
# Hardware Settings
TRAIN_BATCH_SIZE = 4 # 如果在消费级 GPU 上遇到 OOM,请降至 1 或 2
GRAD_ACCUMULATION = 16 # 模拟更大的批次 (Effective Batch = 4 * 16 = 64)
# Model Settings
LORA_R = 16 # 秩维度 (标准复现请保持为 16)
VOCAB_BIAS_DIGITS = -4.0 # 非密码模式的惩罚强度
3. **开始训练:**
python train.py
此脚本会自动化整个流程:
* **冻结** 基础模型 (Mistral/Qwen)。
* **注入** 可训练的 LoRA 适配器到注意力层 (Attention layers)。
* **掩码** 损失函数,使模型只学习预测 *密码*,而不是 PII。
* **保存** 轻量级适配器权重到 `models/PassLLM_LoRA_Weights.pth`。
## 结果与演示
`{"name": "Marcus Thorne", "birth_year": "1976", "username": "mthorne88", "country": "Canada"}`:
```
$ python app.py --file target.jsonl --superfast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
1.96% | marcus1976
1.91% | thorne1976
1.20% | mthorne1976
1.19% | marc1976 (marc is a common diminutive of Marcus, used in many passwords)
1.18% | a123456 (a high-probability global baseline across users with similar PII)
1.16% | marci1976 (another common variation of Marcus)
1.01% | winniethepooh (our training dataset demonstrated Winnie-related passwords to be common in Canada)
... (907 passwords generated)
```
`{"name": "Elena Rodriguez", "birth_year": "1995", "birth_month": "12", "birth_day": "04", "email": "elena1.rod51@gmail.com", "id":"489298321"}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
8.55% | elena1204 (all variations of name + birth date are naturally given very high probability)
8.16% | elena1995
7.77% | elena951204
6.29% | elena9512
5.37% | Elena1995
5.32% | elena1.rod51
5.00% | 120495
... (5,895 passwords generated)
```
`{"name": "Sophia M. Turner", "birth_year": "2001", "pet_name": "Fluffy", "username": "soph_t", "email": "sturner99@yahoo.com", "country": "England", "sister_pw": ["soph12345", "13rockm4n", "01mamamia"]}`:
```
$ python app.py --file target.jsonl --fast
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
2.93% | sophia123 (this is a mix of the target's first name and the sister password "soph12345")
2.53% | mamamia01 (a simple variation of another sister password)
1.96% | sophia2001
1.78% | sophie123 (UK passwords often interchange between "sophie" and "sophia")
1.45% | 123456a (a very commmon password, ranked high due to the "12345" pattern)
1.39% | sophiesophie1
1.24% | sturner999
... (10,169 passwords generated)
```
`{"name": "Omar Al-Fayed", "birth_year": "1992", "birth_month": "05", "birth_day": "18", "username": "omar.fayed92", "email": "o.alfayed@business.ae", "address": "Villa 14, Palm Jumeirah", "phone": "+971-50-123-4567", "country": "UAE", "sister_pw": "Amira1235"}`:
```
$ python app.py --file target.jsonl
--- TOP CANDIDATES ---
CONFIDENCE | PASSWORD
------------------------------
79.75% | amira1235 (sister password, with lower case a)
43.77% | Ammira1235 (common pattern in reusing passwords)
19.14% | Omar1235 (drawing on the sister password pattern)
11.03% | Omar1234
8.52% | omarr.alfayid
8.20% | omar1235
7.52% | 051892
... (24,559 passwords generated)
```
## 免责声明
**使用前请仔细阅读本节。**
* **非官方实现:** 本代码库是研究论文 *"Password Guessing Using Large Language Models"* (USENIX Security 2025) 的独立复现和实现。我 **不是** 原始论文的作者,也未参与其研究或发表。概念和方法论的完全功劳归功于 **Yunkai Zou, Maoxiang An, 和 Ding Wang** (南开大学)。
* **仅限教育目的:** 此工具 **仅用于教育目的和安全研究**。旨在帮助安全专业人员、公司、机构和普通用户了解基于 LLM 的密码攻击风险并改进防御机制。
* **无责任:** 本代码库的作者不对本软件的任何滥用负责。您不得在未经明确授权同意的情况下使用此工具攻击目标。**严禁将本软件用于任何非法用途。**标签:CUDA, DLL 劫持, DOS头擦除, LLM, LoRA微调, NLP, PassLLM, PyTorch, Unmanaged PE, USENIX 2025, Vectored Exception Handling, 个人信息PII, 人工智能, 凭据扫描, 反取证, 大语言模型, 安全评估, 密码安全, 密码猜测, 密码破解, 深度学习, 用户模式Hook绕过, 系统调用监控, 逆向工具, 针对性攻击, 隐私数据利用, 高准确率