yifanfeng97/Hyper-Extract
GitHub: yifanfeng97/Hyper-Extract
一个由 LLM 驱动的知识提取框架,通过命令行将非结构化文档转化为知识图谱、超图和时空图等结构化知识。
Stars: 1678 | Forks: 195

**智能知识提取 CLI** **一条命令,将文档转化为结构化知识。** [📖 英文版](./README.md) · [中文版](./README_ZH.md) [](https://pypi.org/project/hyperextract/) [](https://python.org) [](LICENSE) []() [](https://yifanfeng97.github.io/Hyper-Extract/latest/)
📄 研究人员 — 将论文转化为知识图谱
输入一份 20 页的学术论文,获取关键概念、作者和引文的交互式图谱。 ``` he parse paper.pdf -t general/academic_graph -o ./paper_kb/ he show ./paper_kb/ ```
🏦 金融分析师 — 从财报中提取实体
从非结构化报告中自动识别公司、高管、财务指标及其关系。 ``` he parse earnings.md -t finance/earnings_graph -o ./finance_kb/ he search ./finance_kb/ "What are the key risk factors?" ```
🔒 本地部署 — 使用 vLLM 让数据保留在本地
通过 vLLM 在本地运行 Qwen3.5-9B + bge-m3。数据绝不离开您的机器。 ``` from hyperextract import create_client llm, emb = create_client( llm="vllm:Qwen3.5-9B@http://localhost:8000/v1", embedder="vllm:bge-m3@http://localhost:8001/v1", api_key="dummy", ) ```
🐍 Python API(点击展开)
``` uv pip install hyperextract ``` ``` from hyperextract import Template ka = Template.create("general/biography_graph") with open("examples/en/tesla.md") as f: result = ka.parse(f.read()) result.show() ```
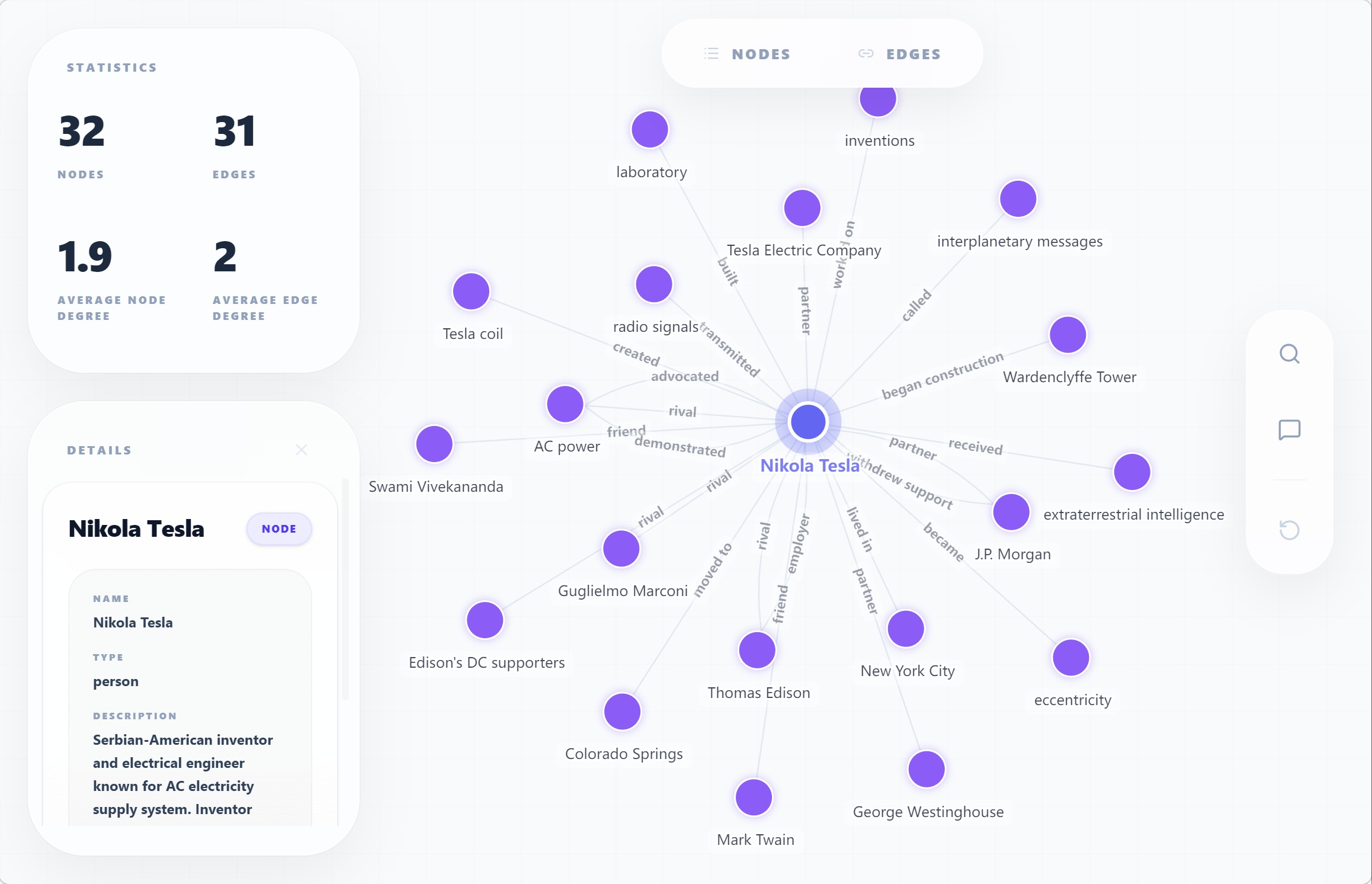
 **示例 — AutoGraph 可视化:**
**示例 — AutoGraph 可视化:**
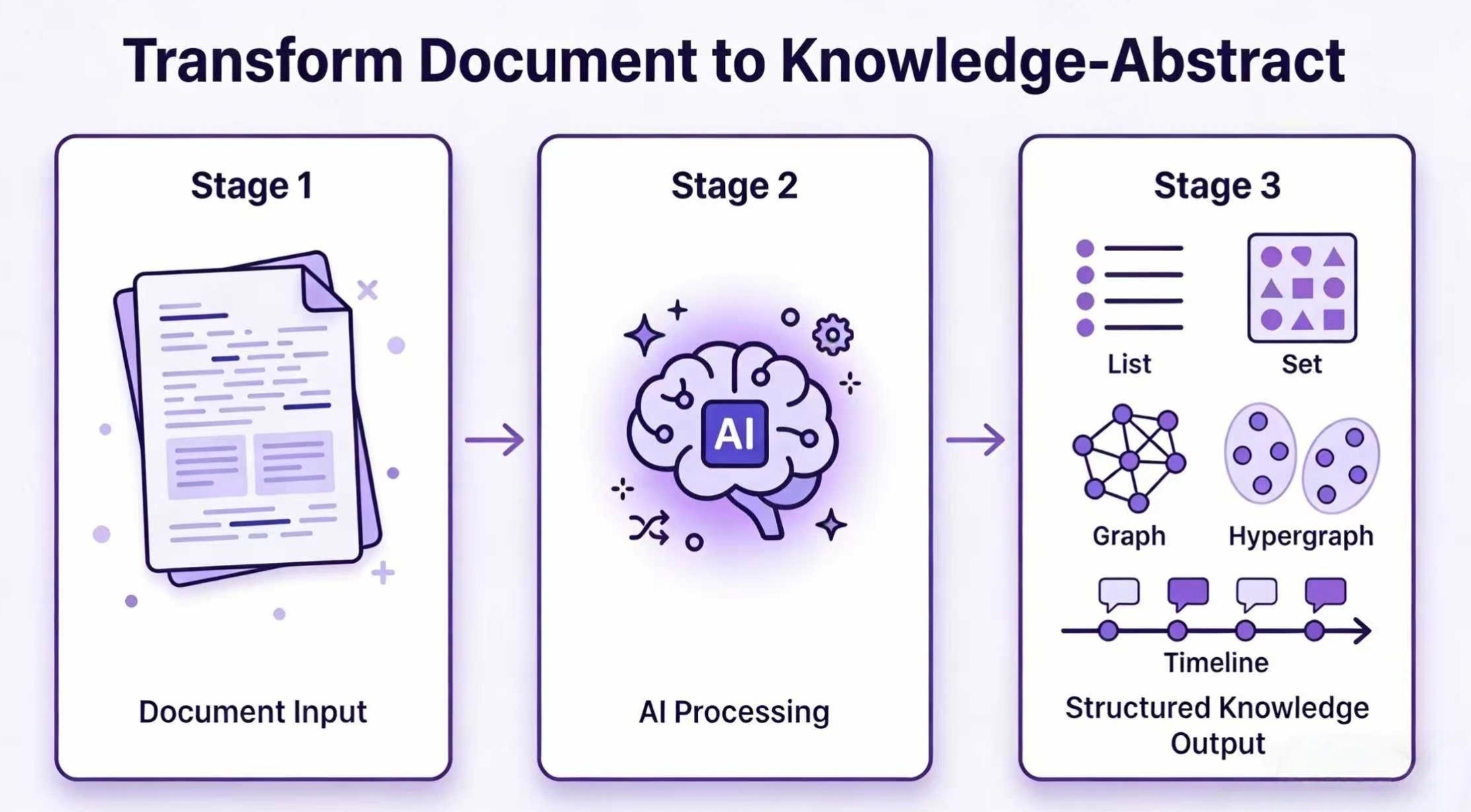
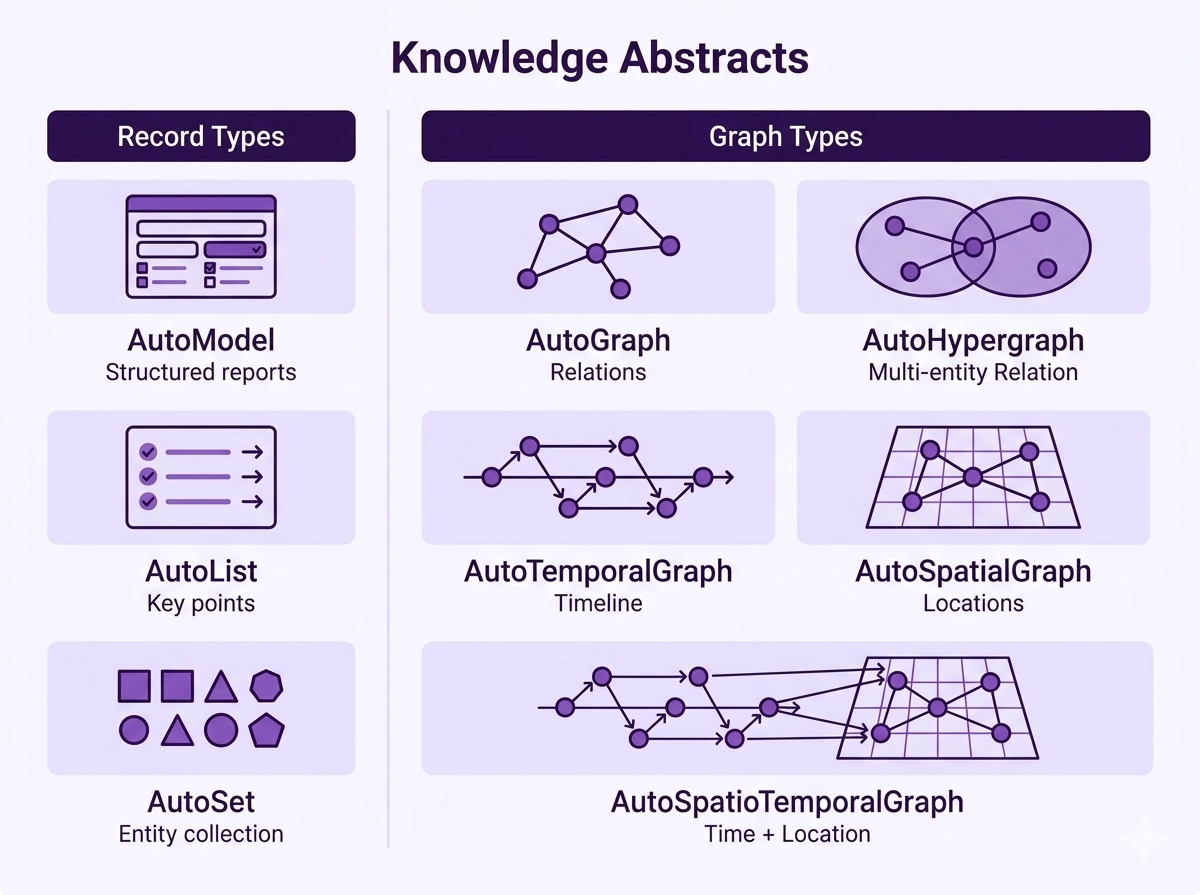
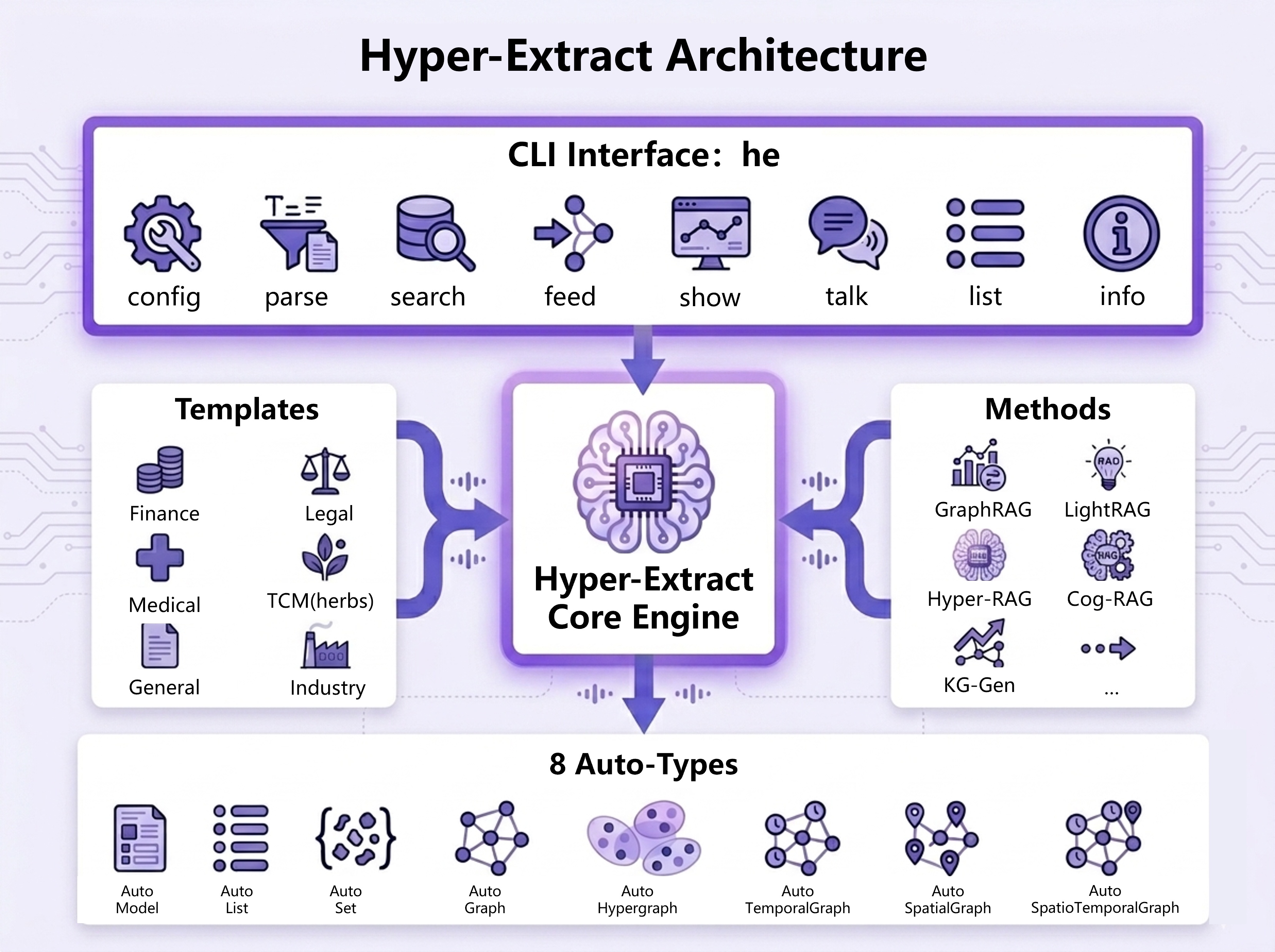
📋 底层原理是什么?(架构与模板)
Hyper-Extract 遵循**三层架构**: - **Auto-Types** — 8 种强类型数据结构(Model、List、Set、Graph、Hypergraph、Temporal Graph、Spatial Graph、Spatio-Temporal Graph) - **Methods** — 提取算法:KG-Gen、GraphRAG、LightRAG、Hyper-RAG、Cog-RAG 等 - **Templates** — 涵盖 6 个领域的 80 多种预设。零代码设置。
 **模板示例(Graph 类型):**
```
language: en
name: Knowledge Graph
type: graph
tags: [general]
description: 'Extract entities and their relationships.'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [浏览所有 80+ 模板](./hyperextract/templates/presets/)
- [创建自定义模板](./hyperextract/templates/DESIGN_GUIDE.md)
**模板示例(Graph 类型):**
```
language: en
name: Knowledge Graph
type: graph
tags: [general]
description: 'Extract entities and their relationships.'
output:
entities:
fields:
- name: name
type: str
- name: type
type: str
- name: description
type: str
relations:
fields:
- name: source
type: str
- name: target
type: str
- name: type
type: str
identifiers:
entity_id: name
relation_id: '{source}|{type}|{target}'
```
- [浏览所有 80+ 模板](./hyperextract/templates/presets/)
- [创建自定义模板](./hyperextract/templates/DESIGN_GUIDE.md)
标签:DLL 劫持, IPv6支持, Petitpotam, Python, 信息抽取, 大语言模型, 无后门, 逆向工具, 非结构化数据