NVlabs/vibetensor
GitHub: NVlabs/vibetensor
VibeTensor 是一个完全由 AI 代理生成的深度学习运行时系统,旨在验证 AI 辅助软件工程能否构建涵盖从语言绑定到 CUDA 底层管理的完整技术栈。
Stars: 635 | Forks: 49
# VibeTensor:由 AI Agent 完全生成的深度学习系统软件
[[`研究论文`](https://arxiv.org/abs/2601.16238)]
*从 Node.js/Python 到 PTX 汇编:*一个完全由 AI agent 生成的研究型深度学习系统。
## 研究定位
VIBETENSOR 是一个开源的系统研究产物,由 LLM 驱动的编码 agent 在高级人类指导下生成。“完全生成”指的是代码的来源和验证:实现变更作为 agent 生成的 diff 被提出并应用,其正确性通过构建、测试和差异化检查来保证,而不是依赖对每次变更的人工审查。我们将此次开源发布视为 AI 辅助软件工程的一个里程碑:它证明了编码 agent 能够生成并验证一个连贯的深度学习 runtime,涵盖从语言绑定到 CUDA 内存管理的全过程,且其正确性主要受构建和测试的约束。**作为对系统完整性的合理性检查,我们使用生成的 stack 成功地在三个涵盖计算机视觉和语言建模的小型工作负载上运行了端到端训练,包括多 GPU 执行路径。**
VibeTensor 是一个受 PyTorch 启发的 eager runtime,拥有全新的 **C++20** 核心(CPU + CUDA)、torch 风格的 **Python** 覆盖层,以及一个实验性的 **Node.js / TypeScript** API。
与“薄包装器”不同,VibeTensor 实现了自己的 tensor/storage、dispatcher、autograd 引擎、CUDA runtime + 缓存分配器和插件 ABI。
- **C++ 核心**:`TensorImpl`/`Storage`、轻量级 schema dispatcher、TensorIterator、反向模式 autograd、indexing、RNG。
- **CUDA 子系统**:streams/events、流序缓存分配器(统计/快照、比例上限、GC 阶梯)、CUDA Graph 捕获/重放。
- **互操作**:DLPack 导入/导出(CPU + CUDA),用于与其他框架进行零拷贝交换。全新的 C++20 Safetensors 加载器/保存器。
- **可扩展性**:动态算子插件(稳定的 C ABI)、Python 覆盖(`vibetensor.library`)、Triton 桥接器和 CuTeDSL runtime。
- **实验性多 GPU**:Fabric tensor(UVA/NVLink 拓扑 + 可观测性)以及尽力而为的 CUTLASS Blackwell ring allreduce 插件(需要 CUDA 13+ 和支持 sm103a 的工具链)。
规模(撰写本文时):约 218 个 C++/CUDA 源文件(约 6 万非空行),外加约 5 万非空行的测试(C++ + Python + JS)。
## 该仓库存在的原因
VibeTensor 最初是一个**系统软件实验**:AI agent 能否生成一个连贯的深度学习 stack,涵盖 Python/JS 绑定 → C++ runtime → CUDA 分配器/streams → GPU kernel?
该项目采用“最少干预”的方法论:通过高级架构 prompt 指导,其成功与否取决于系统能否构建、通过测试并产生正确的结果。
### 性能注意事项(“科学怪人效应”)
VibeTensor 的设计以正确性为先,**目前在性能上无法与 PyTorch 竞争**。我们观察到的一种失败模式是,各个组件单独看可能很稳健,但组合在一起时就会在全局上变得次优(例如,hot path 中的全局序列化)。
请将 VibeTensor 视为一个**研究原型**。
## 架构(宏观视图)
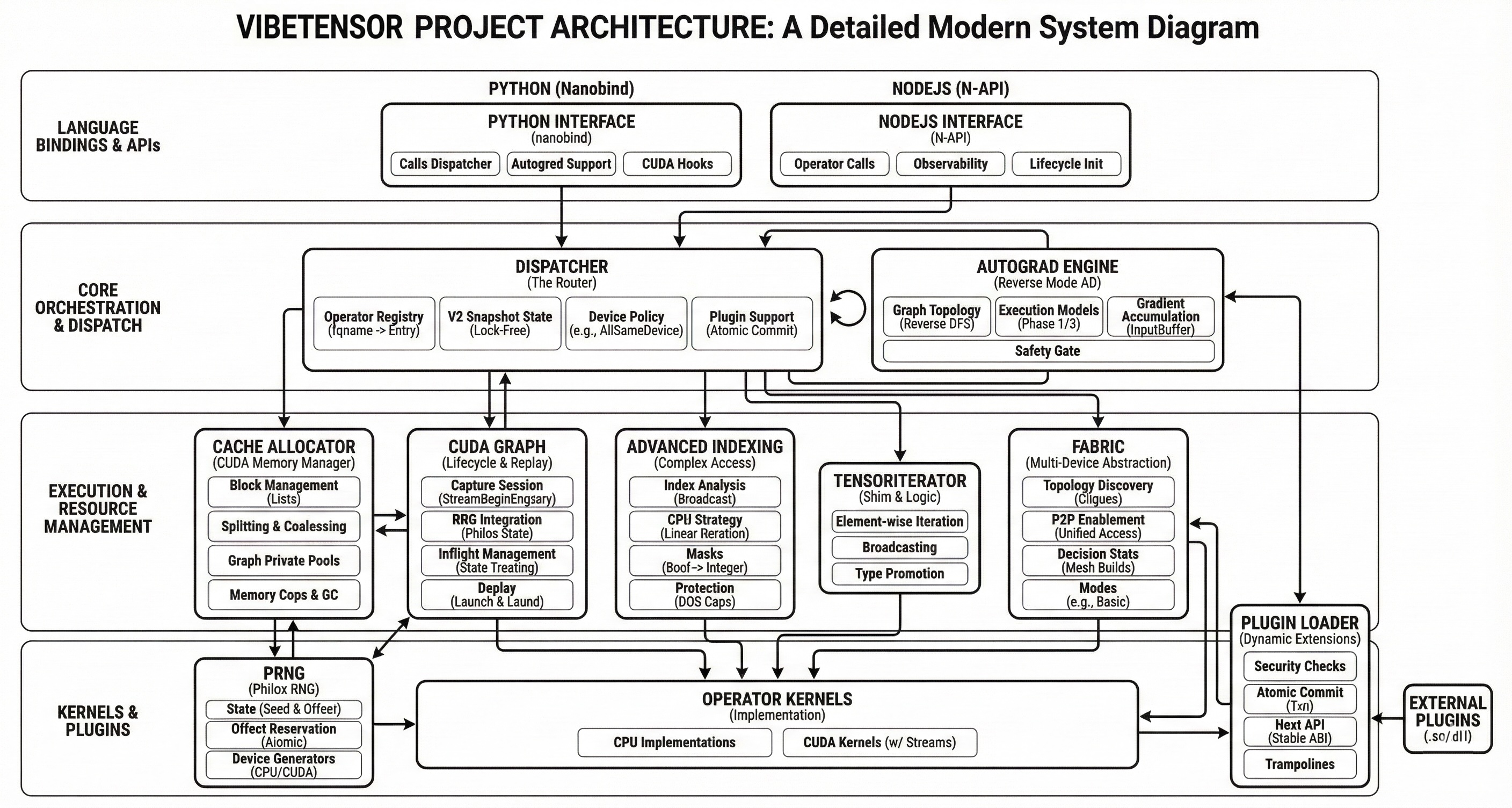
在较高层次上:
- **前端**:Python (nanobind) 和 Node.js (N-API) 都会 dispatch 到同一个 C++ 算子注册表中。
- **核心 runtime**:tensor/storage + dispatcher + autograd + indexing + RNG。
- **CUDA runtime**:stream/event 包装器、分配器、graphs、kernel 启动辅助程序。
- **计算层**:内置 CUDA kernel + 可选的 Triton/CuTeDSL kernel + 插件加载的 kernel。
- **多 GPU 实验**:Fabric tensor 和可观测性(统计 + event ring)。
### 模块架构图
关于各个模块更详细的架构,请参见 `docs/images/` 中的图表:
| 模块 | 描述 |
|--------|-------------|
| [缓存分配器](docs/images/cache-allocator.jpg) | 流序 CUDA 内存分配和缓存 |
| [Dispatcher](docs/images/dispatcher.jpg) | 中央算子路由和注册表 |
| [Autograd](docs/images/autograd.jpg) | 反向模式自动微分引擎 |
| [Fabric](docs/images/fabric.jpg) | 多设备拓扑和统一内存访问 |
| [CUDA Graph](docs/images/cuda-graph.jpg) | 图捕获和重放管理 |
| [TensorIterator](docs/images/tensor-iterator.jpg) | 逐元素操作和广播引擎 |
## 项目状态
VibeTensor 是一个活跃的研究项目;API 和行为可能随时更改,恕不另行通知。
当前代码涵盖:
- CPU 和 CUDA tensor、views 以及 DLPack 导入/导出。
- 带有 CPU/CUDA kernel 的 Dispatcher,用于限定范围的 `vt::` 算子集(通过 TensorIterator 实现逐元素操作和归约)。
- 带有可观测性钩子(统计/快照、比例上限、GC 阶梯)的流序 CUDA 缓存分配器。
- 带有原地/视图保护和装箱回退(外加实验性的多设备模式)的反向模式 autograd。
- Indexing:基础 indexing 加上高级 indexing(可通过环境标志配置;部分 CUDA 路径)。
- Fabric:实验性的单进程多 GPU 逐元素操作(`vibetensor.fabric`),带有统计/事件快照。
- Python 覆盖层(`vibetensor.torch`),包含工厂、`ops` namespace、CUDA 辅助程序和 Triton 集成。
- 实验性的 Node N-API 插件和 JS/TS 覆盖层(CPU tensor + CUDA runtime 辅助程序;在 CI 中为尽力而为)。
## 平台和要求
- Linux x86_64(参考平台)
- Python >= 3.10
- CMake >= 3.26 和 C++20 编译器(GCC/Clang)
- NVIDIA GPU + CUDA 工具包(CI 使用 CUDA 13.0.2;预期支持 CUDA 12+)。**必须安装 CUDA**;禁用仅 CPU 构建。
- 可选(用于 JS/TS 覆盖层 / 插件构建):
- Node.js 22 + npm
- CMake 可发现的 Node-API 头文件(`node_api.h`)(如有需要,请设置 `NODE_INCLUDE_DIR` / `NODEJS_INCLUDE_DIR`)
## 安装与构建
### 可编辑的开发安装(推荐)
在仓库根目录下执行:
```
python -m pip install -U pip build pytest numpy
export CUDACXX=$(which nvcc)
CMAKE_BUILD_TYPE=Debug \
python -m pip install -v -e .[test]
# 构建树:build-py/(在 pyproject.toml 中配置)
```
这将通过 scikit-build-core 驱动 CMake(构建目录:`build-py/`),用于构建:
- `vbt_core` C++ 静态库和 C++ 测试到 `build-py/` 目录中,
- 编译后的扩展 `build-py/python/vibetensor/_C*.so`(安装到您的 Python 环境中)以及 `python/vibetensor/` 下的 Python 源码,
- 当 Node + Node-API 头文件可用时,构建 Node 插件 `js/vibetensor/vbt_napi.node`(尽力而为)。
默认配置在 `pyproject.toml` 中;可以通过 `-Ccmake.define.*` 进行覆盖(例如,`-Ccmake.define.VBT_BUILD_NODE=OFF`)。
如果 CMake 找不到 `node_api.h`,请设置 `NODE_INCLUDE_DIR=/path/to/include/node`(或传入 `-Ccmake.define.NODEJS_INCLUDE_DIR=...`)。
### 手动 CMake 构建
```
cmake -S . -B build -DCMAKE_BUILD_TYPE=Debug \
-DVBT_USE_CUDA=ON -DVBT_BUILD_TESTS=ON -DVBT_WITH_AUTOGRAD=ON
cmake --build build -j
```
### Wheels(Release)
```
CMAKE_BUILD_TYPE=Release python -m build --wheel
```
## 快速入门
### Python:torch 风格的覆盖层
主要的面向用户的 API 是 `vibetensor.torch`,这是一个构建在 C++ 核心之上的轻量级 torch 风格覆盖层。
```
import vibetensor.torch as vt
# 创建 CPU tensors
a = vt.tensor([[1.0, 2.0], [3.0, 4.0]], dtype="float32")
b = vt.ones_like(a)
# 通过 ops namespace 调用 dispatcher 支持的 ops
c = vt.ops.vt.add(a, b)
d = vt.ops.vt.relu(c)
print(d.sizes, d.dtype, d)
# 与其他框架(例如 PyTorch)的 DLPack 互操作
from torch.utils import dlpack as torch_dlpack
torch_tensor = torch_dlpack.from_dlpack(vt.to_dlpack(d))
```
CUDA 辅助程序(streams、events、内存统计)位于 `vibetensor.torch.cuda` 下:
```
from vibetensor.torch import cuda
stream = cuda.Stream()
with stream:
pass
stream.synchronize()
```
要进行更底层的访问(绑定/测试),请直接导入原生扩展:
```
from vibetensor import _C as C
print(C._has_cuda, C._cuda_device_count())
a = C._cpu_zeros([2, 2], "float32")
b = C._cpu_full([2, 2], "float32", 3.0)
c = C.vt.add(a, b) # vt::add(Tensor, Tensor) -> Tensor
r = C.vt.relu(c) # vt::relu(Tensor) -> Tensor
print(r.sizes, r.dtype, r.device)
```
### Node.js / TypeScript(实验性)
Node 插件和 JS/TS 覆盖层位于 `js/vibetensor/` 下。
在可编辑安装生成了 `js/vibetensor/vbt_napi.node` 之后,您可以在本地运行 JS 测试:
```
# 在 repository root 中,完成 editable install 之后
export VBT_NODE_ADDON_PATH="$(pwd)/js/vibetensor/vbt_napi.node"
cd js/vibetensor
npm ci
npm test # runs TypeScript build then `node --test`
```
一个最小的使用示例(在 `npm run build` 之后,于 `js/vibetensor` 中执行):
```
import { zeros, ops, cuda } from './dist/index.js'; // or 'vibetensor' when packaged
async function main() {
const a = await zeros([2, 2]);
const b = await zeros([2, 2]);
const c = await ops.vt.add(a, b);
console.log('sizes=', c.sizes, 'dtype=', c.dtype, 'device=', c.device);
if (cuda.isAvailable()) {
const stream = cuda.Stream.create(0);
await stream.synchronize();
}
}
main().catch((err) => {
console.error(err);
process.exitCode = 1;
});
```
JS 覆盖层是完全异步的:繁重的工作(CUDA 操作、H2D/D2H 拷贝、等待)是通过 `napi_async_work` 调度的,不会阻塞 Node 事件循环。
注意:JS `Tensor` 对象目前仅支持 CPU;CUDA 通过 `cuda.*`(streams/events)、显式的 `h2d`/`d2h` 以及 DLPack 导入/导出进行暴露。
## 动态算子、插件和 Triton
VibeTensor 暴露了几个扩展点:
- **Python 覆盖**(`vibetensor.library`):一个 `torch.library` 风格的接口,用于定义运行在 C++ dispatcher 之上的 Python 实现。
- **C / CUDA 插件**:`_C._load_library("/path/to/libvbt_*.so")` 加载外部的共享库,以注册新的 vt 算子。
- **Triton 桥接器**(`vibetensor.triton` 和 `vibetensor.torch.triton` 下的辅助工具):将 Triton kernel 编译为 PTX 并将其接入 dispatcher。
简单的 Python 覆盖:
```
import vibetensor.torch as vt
from vibetensor import library
lib = library.Library("ext", "DEF")
lib.define("ext::square(Tensor) -> Tensor")
def square(x):
return vt.ops.vt.mul(x, x)
lib.impl("square", square, dispatch_key="CPU")
y = vt.ops.ext.square(vt.ones((2, 2)))
```
加载 C/CUDA 插件:
```
from vibetensor import _C
_C._load_library("/path/to/libvbt_reference_add.so")
# 已注册的 symbols 将通过 dispatcher 可用,例如 `vt::add`。
```
## 测试
在进行可编辑安装后,典型的测试命令如下:
### C++ 测试 (CTest)
```
ctest --test-dir build-py -j"$(nproc)" --output-on-failure
# 侧重于 CUDA 的 slice
ctest --test-dir build-py -R vbt_cuda_ -j"$(nproc)" --output-on-failure
```
### Python 测试 (pytest)
```
pytest -q
pytest -q tests/py/test_dlpack.py
pytest -q tests/py/test_cuda_* # CUDA-focused slice
```
### Node / JS 覆盖层测试
```
# 在 repository root 中,完成 editable install 之后
export VBT_NODE_ADDON_PATH="$(pwd)/js/vibetensor/vbt_napi.node"
cd js/vibetensor
npm ci
npm test
```
Node 步骤在 CI 中被视为**尽力而为**:当缺少 `js/vibetensor/vbt_napi.node` 时,JS 测试将被跳过并显示成功状态。
### API 一致性检查
```
python tools/check_api_parity.py --manifest api/manifest_import_only.json
# 如果本地未安装 torch:
export VBT_SKIP_PARITY=1 # script exits with status 2 to indicate "skipped"
```
## 仓库布局
- `python/` - Python 包,包括 `vibetensor.torch`、`vibetensor.autograd`、`vibetensor.library`、`vibetensor.triton`。
- `js/vibetensor/` - Node N-API 插件构建输出(`vbt_napi.node`)和 JS/TS 覆盖层(`src/*.ts`、`test/*.mjs`)。
- `include/vbt/` - C++ 公共头文件(核心 tensor/storage、dispatcher、autograd、CUDA runtime、插件 ABI、Node 绑定)。
- `src/vbt/` - 核心库、CUDA runtime、算子、插件、Python 和 Node 绑定的 C++ 源码。
- `plugins/` - 作为共享库构建的参考 C/CUDA 插件。
- `ring_allreduce_plugin/` - 尽力而为的 CUTLASS Blackwell ring allreduce 插件源码。
- `tests/cpp/` - GoogleTest 套件。
- `tests/py/` - Pytest 套件(Python 覆盖层、CUDA 分配器/runtime、Triton 路径、插件、CUDA Graphs、RNG)。
- `tools/` - 开发工具(API 一致性检查器等)。
- `api/` - 被 `tools/check_api_parity.py` 使用的 API 一致性清单。
- `examples/` - 示例 Triton kernel 和 autograd 用法。
- `3rdparty/` - 内置依赖项(abseil-cpp、googletest、nanobind、dlpack)。
- `AGENTS.md` - 针对本环境的仓库指南,包括最新的测试/构建快速入门。
## 引用
```
@inproceedings{xu2026vibetensor,
title={{VibeTensor: System Software for Deep Learning, Fully Generated by AI Agents}},
author={Bing Xu, Terry Chen, Fengzhe Zhou, Tianqi Chen, Yangqing Jia, Vinod Grover, Haicheng Wu, Wei Liu, Craig Wittenbrink, Wen-mei Hwu, Roger Bringmann, Ming-Yu Liu, Luis Ceze, Michael Lightstone, Humphrey Shi},
journal={arXiv preprint arXiv:2601.16238},
year={2026}
}
```
## 许可证
VibeTensor 采用 Apache License, Version 2.0 授权。有关详细信息,请参见 `pyproject.toml` 和仓库的许可证文件。内置的第三方代码保留其原始许可证。
标签:AI代码生成, Bash脚本, C++, CUDA, MITM代理, Vectored Exception Handling, 数据擦除, 数据管道, 深度学习框架, 系统软件, 自动微分, 软件工程, 逆向工具