z-lab/dflash
GitHub: z-lab/dflash
DFlash 是一个基于块扩散的轻量级模型,专为提升大语言模型的推测解码效率而设计。
Stars: 5494 | Forks: 395
# DFlash:用于 Flash 推测解码的块扩散模型
[**论文**](https://arxiv.org/abs/2602.06036) | [**博客**](https://z-lab.ai/projects/dflash/) | [**模型**](https://huggingface.co/collections/z-lab/dflash)
**DFlash** 是一个轻量级的**块扩散**模型,专为推测解码设计。它能够实现高效且高质量的并行草稿生成。
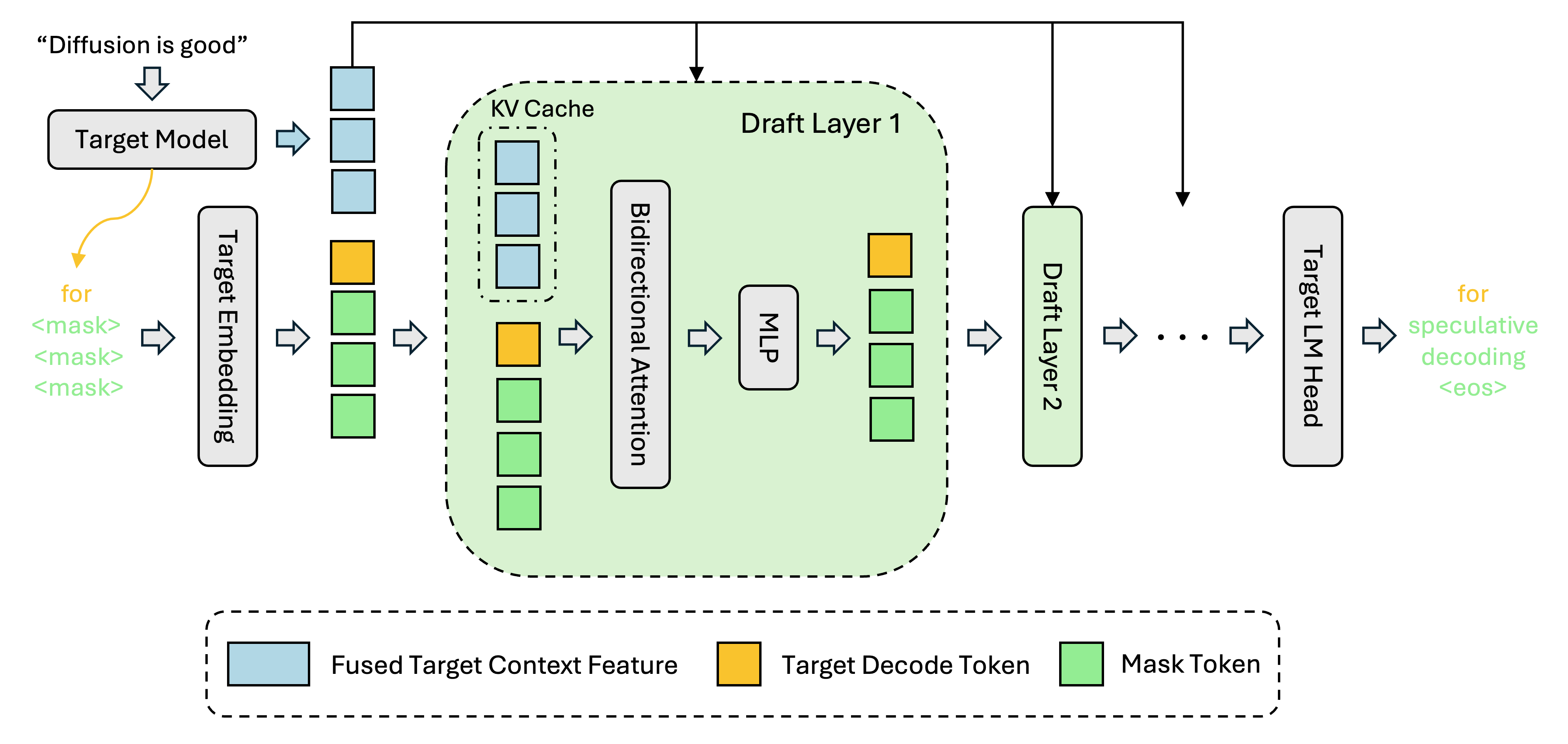
https://github.com/user-attachments/assets/5b29cabb-eb95-44c9-8ffe-367c0758de8c
## 支持的模型
| 模型 | DFlash 草稿 |
|---|---|
| Kimi-K2.5(预览版) | [z-lab/Kimi-K2.5-DFlash](https://huggingface.co/z-lab/Kimi-K2.5-DFlash) |
| Qwen3.5-4B | [z-lab/Qwen3.5-4B-DFlash](https://huggingface.co/z-lab/Qwen3.5-4B-DFlash) |
| Qwen3.5-9B | [z-lab/Qwen3.5-9B-DFlash](https://huggingface.co/z-lab/Qwen3.5-9B-DFlash) |
| Qwen3.5-27B | [z-lab/Qwen3.5-27B-DFlash](https://huggingface.co/z-lab/Qwen3.5-27B-DFlash) |
| Qwen3.5-35B-A3B | [z-lab/Qwen3.5-35B-A3B-DFlash](https://huggingface.co/z-lab/Qwen3.5-35B-A3B-DFlash) |
| Qwen3-Coder-Next | [z-lab/Qwen3-Coder-Next-DFlash](https://huggingface.co/z-lab/Qwen3-Coder-Next-DFlash) |
| Qwen3-Coder-30B-A3B | [z-lab/Qwen3-Coder-30B-A3B-DFlash](https://huggingface.co/z-lab/Qwen3-Coder-30B-A3B-DFlash) |
| gpt-oss-20b | [z-lab/gpt-oss-20b-DFlash](https://huggingface.co/z-lab/gpt-oss-20b-DFlash) |
| gpt-oss-120b | [z-lab/gpt-oss-120b-DFlash](https://huggingface.co/z-lab/gpt-oss-120b-DFlash) |
| Qwen3-4B(非思考模式) | [z-lab/Qwen3-4B-DFlash-b16](https://huggingface.co/z-lab/Qwen3-4B-DFlash-b16) |
| Qwen3-8B(非思考模式) | [z-lab/Qwen3-8B-DFlash-b16](https://huggingface.co/z-lab/Qwen3-8B-DFlash-b16) |
| Llama-3.1-8B-Instruct | [z-lab/LLaMA3.1-8B-Instruct-DFlash-UltraChat](https://huggingface.co/z-lab/LLaMA3.1-8B-Instruct-DFlash-UltraChat) |
| Qwen3.5-122B-A10B | 即将推出 |
| Qwen3.5-397B-A17B | 即将推出 |
| GLM-5.1 | 即将推出 |
## 📦 安装
为避免冲突,请为每个后端使用单独的虚拟环境。
| 后端 | 安装命令 |
|---|---|
| **Transformers** | `uv pip install -e ".[transformers]"` |
| **SGLang** | `uv pip install -e ".[sglang]"` |
| **vLLM** | 参见下方 |
| **MLX**(Apple Silicon) | `pip install -e ".[mlx]"` |
**vLLM:** DFlash 支持需要夜间构建版本:
```
uv pip install -e ".[vllm]"
uv pip install -U vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
```
## 🚀 快速开始
### vLLM
```
vllm serve Qwen/Qwen3.5-27B \
--speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}' \
--attention-backend flash_attn \
--max-num-batched-tokens 32768
```
### SGLang
```
export SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1
# 可选:启用计划重叠(实验性,可能不稳定)
# export SGLANG_ENABLE_SPEC_V2=1
# export SGLANG_ENABLE_DFLASH_SPEC_V2=1
# export SGLANG_ENABLE_OVERLAP_PLAN_STREAM=1
python -m sglang.launch_server \
--model-path Qwen/Qwen3.5-35B-A3B \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3.5-35B-A3B-DFlash \
--speculative-num-draft-tokens 16 \
--tp-size 1 \
--attention-backend trtllm_mha \
--speculative-draft-attention-backend fa4 \
--mem-fraction-static 0.75 \
--mamba-scheduler-strategy extra_buffer \
--trust-remote-code
```
### Transformers
仅 Qwen3 和 LLaMA-3.1 模型支持 Transformers 后端。
```
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
draft = AutoModel.from_pretrained("z-lab/Qwen3-8B-DFlash-b16", trust_remote_code=True, dtype="auto", device_map="cuda:0").eval()
target = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-8B", dtype="auto", device_map="cuda:0").eval()
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
messages = [{"role": "user", "content": "How many positive whole-number divisors does 196 have?"}]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True, enable_thinking=False).to(draft.device)
output = draft.spec_generate(input_ids=input_ids, max_new_tokens=2048, temperature=0.0, target=target, stop_token_ids=[tokenizer.eos_token_id])
print(tokenizer.decode(output[0], skip_special_tokens=False))
```
### MLX(Apple Silicon)
MLX 上已有许多优秀的社区 DFlash 实现;我们在此提供了一个简单且高效的版本,已在搭载 Qwen3 和 Qwen3.5 模型的 Apple M5 Pro 上测试通过。
```
from dflash.model_mlx import load, load_draft, stream_generate
model, tokenizer = load("Qwen/Qwen3.5-4B")
draft = load_draft("z-lab/Qwen3.5-4B-DFlash")
messages = [{"role": "user", "content": "How many positive whole-number divisors does 196 have?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True, enable_thinking=True)
tps = 0.0
for r in stream_generate(model, draft, tokenizer, prompt, block_size=16, max_tokens=2048, temperature=0.6):
print(r.text, end="", flush=True)
tps = r.generation_tps
print(f"\nThroughput: {tps:.2f} tok/s")
```
## 📊 评估
所有基准测试使用相同的数据集(gsm8k、math500、humaneval、mbpp、mt-bench)。数据集会在首次运行时自动下载并缓存为 `cache/` 目录下的 JSONL 文件。
**vLLM**:
```
python -m dflash.benchmark --backend vllm \
--base-url http://127.0.0.1:8000 --model Qwen/Qwen3.5-27B \
--dataset gsm8k --num-prompts 128 --concurrency 1 --enable-thinking
```
**SGLang**:
```
python -m dflash.benchmark --backend sglang \
--base-url http://127.0.0.1:30000 --model Qwen/Qwen3.5-35B-A3B \
--dataset gsm8k --num-prompts 128 --concurrency 1 --enable-thinking
```
**Transformers**(仅 Qwen3 和 LLaMA):
```
torchrun --nproc_per_node=8 -m dflash.benchmark --backend transformers \
--model Qwen/Qwen3-8B --draft-model z-lab/Qwen3-8B-DFlash-b16 \
--dataset gsm8k --max-samples 128
```
**MLX**:
```
python -m dflash.benchmark --backend mlx \
--model Qwen/Qwen3.5-4B --draft-model z-lab/Qwen3.5-4B-DFlash \
--dataset gsm8k --max-samples 128 --enable-thinking
```
## 感谢
衷心感谢 [@dcw02](https://github.com/dcw02)、[@gongy](https://github.com/gongy) 以及 [@modal-labs](https://github.com/modal-labs) 团队在将 DFlash 引入 SGLang 方面提供的快速、高质量支持。同时也要感谢 [@benchislett](https://github.com/benchislett) 在 NVIDIA 为将 DFlash 引入 vLLM 所做的贡献,并帮助使其更易于被更广泛的服务社区使用。
## 引用
如果您发现 DFlash 有用,请引用我们的工作。如需对 DFlash 提供反馈或请求新增模型支持,请填写以下表单:[DFlash 反馈](https://forms.gle/4YNwfqb4nJdqn6hq9)。
```
@article{chen2026dflash,
title = {{DFlash: Block Diffusion for Flash Speculative Decoding}},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
journal = {arXiv preprint arXiv:2602.06036},
year = {2026}
}
```
标签:AI 部署, Attention, CI/CD安全, DFlash, DLL 劫持, Draft Model, Flash Speculative Decoding, GLM, GPT-OSS, HuggingFace, Kimi K2.5, Llama, Qwen3.5, Qwen3-Coder-Next, Transformer, Z-Lab, 云端推理, 凭据扫描, 加速推理, 块扩散, 大语言模型, 并行草案, 扩散模型, 投机解码, 模型压缩, 模型服务, 生成式AI, 系统调用监控, 索引, 逆向工具, 高效推理