modelscope/sirchmunk
GitHub: modelscope/sirchmunk
无向量数据库的智能搜索框架,支持原始文档实时检索与自我进化知识簇构建。
Stars: 1137 | Forks: 127
 # Sirchmunk:原始数据到自我进化智能,实时
[](https://www.python.org/downloads/)
[](https://fastapi.tiangolo.com/)
[](https://nextjs.org/)
[](https://tailwindcss.com/)
[](https://duckdb.org/)
[](LICENSE)
[](https://github.com/phiresky/ripgrep-all)
[](https://github.com/openai/openai-python)
[](https://github.com/kreuzberg-dev/kreuzberg)
[](https://github.com/modelcontextprotocol/python-sdk)
📖 **[文档](https://modelscope.github.io/sirchmunk-web/)**
[**快速开始**](#-quick-start) · [**核心特性**](#-key-features) · [**MCP Server**](#-mcp-server) · [**Web UI**](#️-web-ui) · [**Docker**](#-docker-deployment) · [**工作原理**](#️-how-it-works) · [**FAQ**](#-faq)
# Sirchmunk:原始数据到自我进化智能,实时
[](https://www.python.org/downloads/)
[](https://fastapi.tiangolo.com/)
[](https://nextjs.org/)
[](https://tailwindcss.com/)
[](https://duckdb.org/)
[](LICENSE)
[](https://github.com/phiresky/ripgrep-all)
[](https://github.com/openai/openai-python)
[](https://github.com/kreuzberg-dev/kreuzberg)
[](https://github.com/modelcontextprotocol/python-sdk)
📖 **[文档](https://modelscope.github.io/sirchmunk-web/)**
[**快速开始**](#-quick-start) · [**核心特性**](#-key-features) · [**MCP Server**](#-mcp-server) · [**Web UI**](#️-web-ui) · [**Docker**](#-docker-deployment) · [**工作原理**](#️-how-it-works) · [**FAQ**](#-faq)
🔍 **Agentic Search** • 🧠 **知识聚类** • 📊 **蒙特卡洛证据采样**
⚡ **无索引检索** • 🔄 **自我进化知识库** • 💬 **实时聊天**
⚡ **无索引检索** • 🔄 **自我进化知识库** • 💬 **实时聊天**
[English](README.md) | [中文](README_zh.md) ## 🌰 为什么叫 “Sirchmunk”? 基于向量检索构建的智能流水线往往_僵化且脆弱_。它们依赖于静态的向量嵌入,这些嵌入**计算成本高昂、对实时变化视而不见,并且与原始上下文脱节**。我们推出 **Sirchmunk** 以开启一种更敏捷的范式,在这种范式下,数据不再被视为快照,洞察力可以与数据共同演化。 ## ✨ 核心特性 ### 1. 无需 EmbeddingDB:数据的最纯粹形式 **Sirchmunk** 直接处理**原始数据** —— 无需承担将丰富文件强行压缩为固定维度向量的繁重开销。 * **即时搜索:** 无需耗时数小时的复杂预处理流水线和索引;只需放入文件即可立即搜索。 * **完全保真:** 零信息丢失 —— 保持数据的真实性,无需向量近似。 ### 2. 自我进化:活体索引 数据是流,而非快照。**Sirchmunk** 在设计上就是**动态的**,而向量 DB 会在数据变更的那一刻过时。 * **上下文感知:** 随着数据上下文实时演化。 * **LLM 驱动的自主性:** 为感知活体数据的 Agent 而设计,利用**token 高效**的推理,仅在必要时触发 LLM 推理,以最大化智能并最小化成本。 ### 3. 规模化智能:实时且海量 **Sirchmunk** 以**高吞吐量**和**实时感知**连接海量本地存储库与网络。
它作为 AI Agent 的统一智能枢纽,以思维的速度在庞大数据集上提供深度洞察。 ### 传统 RAG vs. Sirchmunk
直接访问文件即可开始聊天
 ## 🎉 新闻
* 🚀 **2026年3月5日**: Sirchmunk v0.0.5
- **破坏性变更**:统一的 Search API:精简了 search() 接口,引入新的 SearchContext 对象并简化了参数控制 (return_context)。
- **健壮的 RAG 聊天**:通过新的重试机制和细粒度的异常处理,显著提高了对话可靠性。
- **稳定的 MCP 集成**:修复了 mcp run 初始化问题,确保 Model Context Protocol 用户的无缝服务器部署。
- **PyPI Web UI 修复**:修正了 Next.js 源码打包,以支持标准 pip install 用户的完美 Web UI 启动。
* 🚀 **2026年2月27日**: Sirchmunk v0.0.4
- **Docker 支持**:一流的 Docker 部署支持,提供预构建镜像以实现无缝的容器化设置。
- **FAST 搜索模式**:新的默认贪婪搜索模式,使用 2 级关键字级联和上下文窗口采样 —— 检索速度显著提升,仅需 2 次 LLM 调用(2-5秒 vs 10-30秒)。
- **简化的部署**:简化了 CLI 和 Web UI 配置工作流程,加快上手速度。
- **Windows 兼容性**:修复了 Windows 环境的兼容性问题。
* 🚀 **2026年2月12日**: Sirchmunk v0.0.3:升级了 MCP 集成 & 核心搜索算法
- **MCP 增强**:增强了 Model Context Protocol 支持,并更新了设置指南。
- **细粒度搜索**:添加了 glob 模式(包含/排除)支持;自动过滤临时/缓存文件。
- **新文档**:深入探讨了“蒙特卡洛证据采样”和“自我进化知识簇”。
- **系统稳定性**:重构了搜索流水线,并为知识簇实施了 SHA256 确定性 ID。
* 🚀 **2026年2月5日**: 发布 **v0.0.2** — MCP 支持、CLI 命令 & 知识持久化!
- **MCP 集成**:完全支持 [Model Context Protocol](https://modelcontextprotocol.io),可与 Claude Desktop 和 Cursor IDE 无缝协作。
- **CLI 命令**:新的 `sirchmunk` CLI,包含 `init`、`serve`、`search`、`web` 和 `mcp` 命令。
- **KnowledgeCluster 持久化**:由 DuckDB 驱动的存储,支持 Parquet 导出,实现高效的知识管理。
- **知识复用**:基于语义相似性的簇检索,通过嵌入向量实现更快的搜索。
* 🎉🎉 2026年1月22日:推出 **Sirchmunk**:初始版本 v.0.1 现已上线!
## 🚀 快速开始
### 前置条件
- **Python** 3.10+
- **LLM API Key**(OpenAI 兼容端点,本地或远程)
- **Node.js** 18+(可选,用于 Web 界面)
### 安装
```
# 创建虚拟环境(推荐)
conda create -n sirchmunk python=3.13 -y && conda activate sirchmunk
pip install sirchmunk
# 或通过 UV:
uv pip install sirchmunk
# 或者,从源码安装:
git clone https://github.com/modelscope/sirchmunk.git && cd sirchmunk
pip install -e .
```
### Python SDK 用法
```
import asyncio
from sirchmunk import AgenticSearch
from sirchmunk.llm import OpenAIChat
llm = OpenAIChat(
api_key="your-api-key",
base_url="your-base-url", # e.g., https://api.openai.com/v1
model="your-model-name" # e.g., gpt-5.2
)
async def main():
searcher = AgenticSearch(llm=llm)
# FAST mode (default): greedy search, 2 LLM calls, 2-5s
result: str = await searcher.search(
query="How does transformer attention work?",
paths=["/path/to/documents"],
)
# DEEP mode: comprehensive analysis with Monte Carlo sampling, 10-30s
result_deep: str = await searcher.search(
query="How does transformer attention work?",
paths=["/path/to/documents"],
mode="DEEP",
)
print(result)
asyncio.run(main())
```
**⚠️ 注意:**
- 初始化时,`AgenticSearch` 会自动检查 `ripgrep-all` 和 `ripgrep` 是否已安装。如果缺失,它将尝试自动安装。如果自动安装失败,请手动安装。
- 参考:https://github.com/BurntSushi/ripgrep | https://github.com/phiresky/ripgrep-all
- 请将 `"your-api-key"`、`"your-base-url"`、`"your-model-name"` 和 `/path/to/documents` 替换为您的实际值。
### 命令行界面
Sirchmunk 提供了强大的 CLI 用于服务器管理和搜索操作。
#### 安装
```
pip install "sirchmunk[web]"
# 或通过 UV 安装
uv pip install "sirchmunk[web]"
```
#### 初始化
```
# 使用默认设置初始化 Sirchmunk(默认工作路径:`~/.sirchmunk/`)
sirchmunk init
# 或者,使用自定义工作路径初始化
sirchmunk init --work-path /path/to/workspace
```
#### 启动服务器
```
# 仅启动后端 API 服务器
sirchmunk serve
# 自定义主机和端口
sirchmunk serve --host 0.0.0.0 --port 8000
```
#### 搜索
```
# 在当前目录搜索(默认为 FAST 模式)
sirchmunk search "How does authentication work?"
# 在指定路径搜索
sirchmunk search "find all API endpoints" ./src ./docs
# DEEP 模式:使用 Monte Carlo 采样进行综合分析
sirchmunk search "database architecture" --mode DEEP
# 快速文件名搜索
sirchmunk search "config" --mode FILENAME_ONLY
# 输出为 JSON
sirchmunk search "database schema" --output json
# 使用 API 服务器(需要运行服务器)
sirchmunk search "query" --api --api-url http://localhost:8584
```
#### 可用命令
| 命令 | 描述 |
|---------|-------------|
| `sirchmunk init` | 初始化工作目录、.env 和 MCP 配置 |
| `sirchmunk serve` | 启动后端 API 服务器 |
| `sirchmunk search` | 执行搜索查询 |
| `sirchmunk web init` | 构建 WebUI 前端(需要 Node.js 18+) |
| `sirchmunk web serve` | 启动 API + WebUI(单端口) |
| `sirchmunk web serve --dev` | 启动 API + Next.js 开发服务器(热重载) |
| `sirchmunk mcp serve` | 启动 MCP 服务器 (stdio/HTTP) |
| `sirchmunk mcp version` | 显示 MCP 版本信息 |
| `sirchmunk version` | 显示版本信息 |
## 🔌 MCP 服务器
Sirchmunk 提供了一个 [Model Context Protocol (MCP)](https://modelcontextprotocol.io) 服务器,将其智能搜索能力作为 MCP 工具暴露出来。这使得与 **Claude Desktop** 和 **Cursor IDE** 等 AI 助手的无缝集成成为可能。
### 快速开始
```
# 安装 MCP 支持
pip install sirchmunk[mcp]
# 初始化(生成 .env 和 mcp_config.json)
sirchmunk init
# 使用您的 LLM API 密钥编辑 ~/.sirchmunk/.env
# 使用 MCP Inspector 测试
npx @modelcontextprotocol/inspector sirchmunk mcp serve
```
### `mcp_config.json` 配置
运行 `sirchmunk init` 后,会生成一个 `~/.sirchmunk/mcp_config.json` 文件。将其复制到您的 MCP 客户端配置目录。
**示例:**
```
{
"mcpServers": {
"sirchmunk": {
"command": "sirchmunk",
"args": ["mcp", "serve"],
"env": {
"SIRCHMUNK_SEARCH_PATHS": "/path/to/your_docs,/another/path"
}
}
}
}
```
| 参数 | 描述 |
|---|---|
| `command` | 启动 MCP 服务器的命令。如果在虚拟环境中运行,请使用完整路径(例如 `/path/to/venv/bin/sirchmunk`)。 |
| `args` | 命令参数。`["mcp", "serve"]` 以 stdio 模式启动 MCP 服务器。 |
| `env.SIRCHMUNK_SEARCH_PATHS` | 默认文档搜索目录(逗号分隔)。支持英文 `,` 和中文 `,` 作为分隔符。设置后,如果在工具调用期间未提供 `paths` 参数,则这些路径将用作默认值。 |
### 特性
- **多模式搜索**:FAST 模式(默认,贪婪 2-5秒),DEEP 模式用于全面分析,FILENAME_ONLY 用于快速文件发现
- **知识簇管理**:自动提取、存储和复用知识
- **标准 MCP 协议**:支持 stdio 和 Streamable HTTP 传输
📖 **详细文档请参阅 [Sirchmunk MCP README](src/sirchmunk_mcp/README.md)**。
## 🖥️ Web UI
Web UI 专为快速、透明的工作流程而构建:集聊天、知识分析和系统监控于一体。
## 🎉 新闻
* 🚀 **2026年3月5日**: Sirchmunk v0.0.5
- **破坏性变更**:统一的 Search API:精简了 search() 接口,引入新的 SearchContext 对象并简化了参数控制 (return_context)。
- **健壮的 RAG 聊天**:通过新的重试机制和细粒度的异常处理,显著提高了对话可靠性。
- **稳定的 MCP 集成**:修复了 mcp run 初始化问题,确保 Model Context Protocol 用户的无缝服务器部署。
- **PyPI Web UI 修复**:修正了 Next.js 源码打包,以支持标准 pip install 用户的完美 Web UI 启动。
* 🚀 **2026年2月27日**: Sirchmunk v0.0.4
- **Docker 支持**:一流的 Docker 部署支持,提供预构建镜像以实现无缝的容器化设置。
- **FAST 搜索模式**:新的默认贪婪搜索模式,使用 2 级关键字级联和上下文窗口采样 —— 检索速度显著提升,仅需 2 次 LLM 调用(2-5秒 vs 10-30秒)。
- **简化的部署**:简化了 CLI 和 Web UI 配置工作流程,加快上手速度。
- **Windows 兼容性**:修复了 Windows 环境的兼容性问题。
* 🚀 **2026年2月12日**: Sirchmunk v0.0.3:升级了 MCP 集成 & 核心搜索算法
- **MCP 增强**:增强了 Model Context Protocol 支持,并更新了设置指南。
- **细粒度搜索**:添加了 glob 模式(包含/排除)支持;自动过滤临时/缓存文件。
- **新文档**:深入探讨了“蒙特卡洛证据采样”和“自我进化知识簇”。
- **系统稳定性**:重构了搜索流水线,并为知识簇实施了 SHA256 确定性 ID。
* 🚀 **2026年2月5日**: 发布 **v0.0.2** — MCP 支持、CLI 命令 & 知识持久化!
- **MCP 集成**:完全支持 [Model Context Protocol](https://modelcontextprotocol.io),可与 Claude Desktop 和 Cursor IDE 无缝协作。
- **CLI 命令**:新的 `sirchmunk` CLI,包含 `init`、`serve`、`search`、`web` 和 `mcp` 命令。
- **KnowledgeCluster 持久化**:由 DuckDB 驱动的存储,支持 Parquet 导出,实现高效的知识管理。
- **知识复用**:基于语义相似性的簇检索,通过嵌入向量实现更快的搜索。
* 🎉🎉 2026年1月22日:推出 **Sirchmunk**:初始版本 v.0.1 现已上线!
## 🚀 快速开始
### 前置条件
- **Python** 3.10+
- **LLM API Key**(OpenAI 兼容端点,本地或远程)
- **Node.js** 18+(可选,用于 Web 界面)
### 安装
```
# 创建虚拟环境(推荐)
conda create -n sirchmunk python=3.13 -y && conda activate sirchmunk
pip install sirchmunk
# 或通过 UV:
uv pip install sirchmunk
# 或者,从源码安装:
git clone https://github.com/modelscope/sirchmunk.git && cd sirchmunk
pip install -e .
```
### Python SDK 用法
```
import asyncio
from sirchmunk import AgenticSearch
from sirchmunk.llm import OpenAIChat
llm = OpenAIChat(
api_key="your-api-key",
base_url="your-base-url", # e.g., https://api.openai.com/v1
model="your-model-name" # e.g., gpt-5.2
)
async def main():
searcher = AgenticSearch(llm=llm)
# FAST mode (default): greedy search, 2 LLM calls, 2-5s
result: str = await searcher.search(
query="How does transformer attention work?",
paths=["/path/to/documents"],
)
# DEEP mode: comprehensive analysis with Monte Carlo sampling, 10-30s
result_deep: str = await searcher.search(
query="How does transformer attention work?",
paths=["/path/to/documents"],
mode="DEEP",
)
print(result)
asyncio.run(main())
```
**⚠️ 注意:**
- 初始化时,`AgenticSearch` 会自动检查 `ripgrep-all` 和 `ripgrep` 是否已安装。如果缺失,它将尝试自动安装。如果自动安装失败,请手动安装。
- 参考:https://github.com/BurntSushi/ripgrep | https://github.com/phiresky/ripgrep-all
- 请将 `"your-api-key"`、`"your-base-url"`、`"your-model-name"` 和 `/path/to/documents` 替换为您的实际值。
### 命令行界面
Sirchmunk 提供了强大的 CLI 用于服务器管理和搜索操作。
#### 安装
```
pip install "sirchmunk[web]"
# 或通过 UV 安装
uv pip install "sirchmunk[web]"
```
#### 初始化
```
# 使用默认设置初始化 Sirchmunk(默认工作路径:`~/.sirchmunk/`)
sirchmunk init
# 或者,使用自定义工作路径初始化
sirchmunk init --work-path /path/to/workspace
```
#### 启动服务器
```
# 仅启动后端 API 服务器
sirchmunk serve
# 自定义主机和端口
sirchmunk serve --host 0.0.0.0 --port 8000
```
#### 搜索
```
# 在当前目录搜索(默认为 FAST 模式)
sirchmunk search "How does authentication work?"
# 在指定路径搜索
sirchmunk search "find all API endpoints" ./src ./docs
# DEEP 模式:使用 Monte Carlo 采样进行综合分析
sirchmunk search "database architecture" --mode DEEP
# 快速文件名搜索
sirchmunk search "config" --mode FILENAME_ONLY
# 输出为 JSON
sirchmunk search "database schema" --output json
# 使用 API 服务器(需要运行服务器)
sirchmunk search "query" --api --api-url http://localhost:8584
```
#### 可用命令
| 命令 | 描述 |
|---------|-------------|
| `sirchmunk init` | 初始化工作目录、.env 和 MCP 配置 |
| `sirchmunk serve` | 启动后端 API 服务器 |
| `sirchmunk search` | 执行搜索查询 |
| `sirchmunk web init` | 构建 WebUI 前端(需要 Node.js 18+) |
| `sirchmunk web serve` | 启动 API + WebUI(单端口) |
| `sirchmunk web serve --dev` | 启动 API + Next.js 开发服务器(热重载) |
| `sirchmunk mcp serve` | 启动 MCP 服务器 (stdio/HTTP) |
| `sirchmunk mcp version` | 显示 MCP 版本信息 |
| `sirchmunk version` | 显示版本信息 |
## 🔌 MCP 服务器
Sirchmunk 提供了一个 [Model Context Protocol (MCP)](https://modelcontextprotocol.io) 服务器,将其智能搜索能力作为 MCP 工具暴露出来。这使得与 **Claude Desktop** 和 **Cursor IDE** 等 AI 助手的无缝集成成为可能。
### 快速开始
```
# 安装 MCP 支持
pip install sirchmunk[mcp]
# 初始化(生成 .env 和 mcp_config.json)
sirchmunk init
# 使用您的 LLM API 密钥编辑 ~/.sirchmunk/.env
# 使用 MCP Inspector 测试
npx @modelcontextprotocol/inspector sirchmunk mcp serve
```
### `mcp_config.json` 配置
运行 `sirchmunk init` 后,会生成一个 `~/.sirchmunk/mcp_config.json` 文件。将其复制到您的 MCP 客户端配置目录。
**示例:**
```
{
"mcpServers": {
"sirchmunk": {
"command": "sirchmunk",
"args": ["mcp", "serve"],
"env": {
"SIRCHMUNK_SEARCH_PATHS": "/path/to/your_docs,/another/path"
}
}
}
}
```
| 参数 | 描述 |
|---|---|
| `command` | 启动 MCP 服务器的命令。如果在虚拟环境中运行,请使用完整路径(例如 `/path/to/venv/bin/sirchmunk`)。 |
| `args` | 命令参数。`["mcp", "serve"]` 以 stdio 模式启动 MCP 服务器。 |
| `env.SIRCHMUNK_SEARCH_PATHS` | 默认文档搜索目录(逗号分隔)。支持英文 `,` 和中文 `,` 作为分隔符。设置后,如果在工具调用期间未提供 `paths` 参数,则这些路径将用作默认值。 |
### 特性
- **多模式搜索**:FAST 模式(默认,贪婪 2-5秒),DEEP 模式用于全面分析,FILENAME_ONLY 用于快速文件发现
- **知识簇管理**:自动提取、存储和复用知识
- **标准 MCP 协议**:支持 stdio 和 Streamable HTTP 传输
📖 **详细文档请参阅 [Sirchmunk MCP README](src/sirchmunk_mcp/README.md)**。
## 🖥️ Web UI
Web UI 专为快速、透明的工作流程而构建:集聊天、知识分析和系统监控于一体。
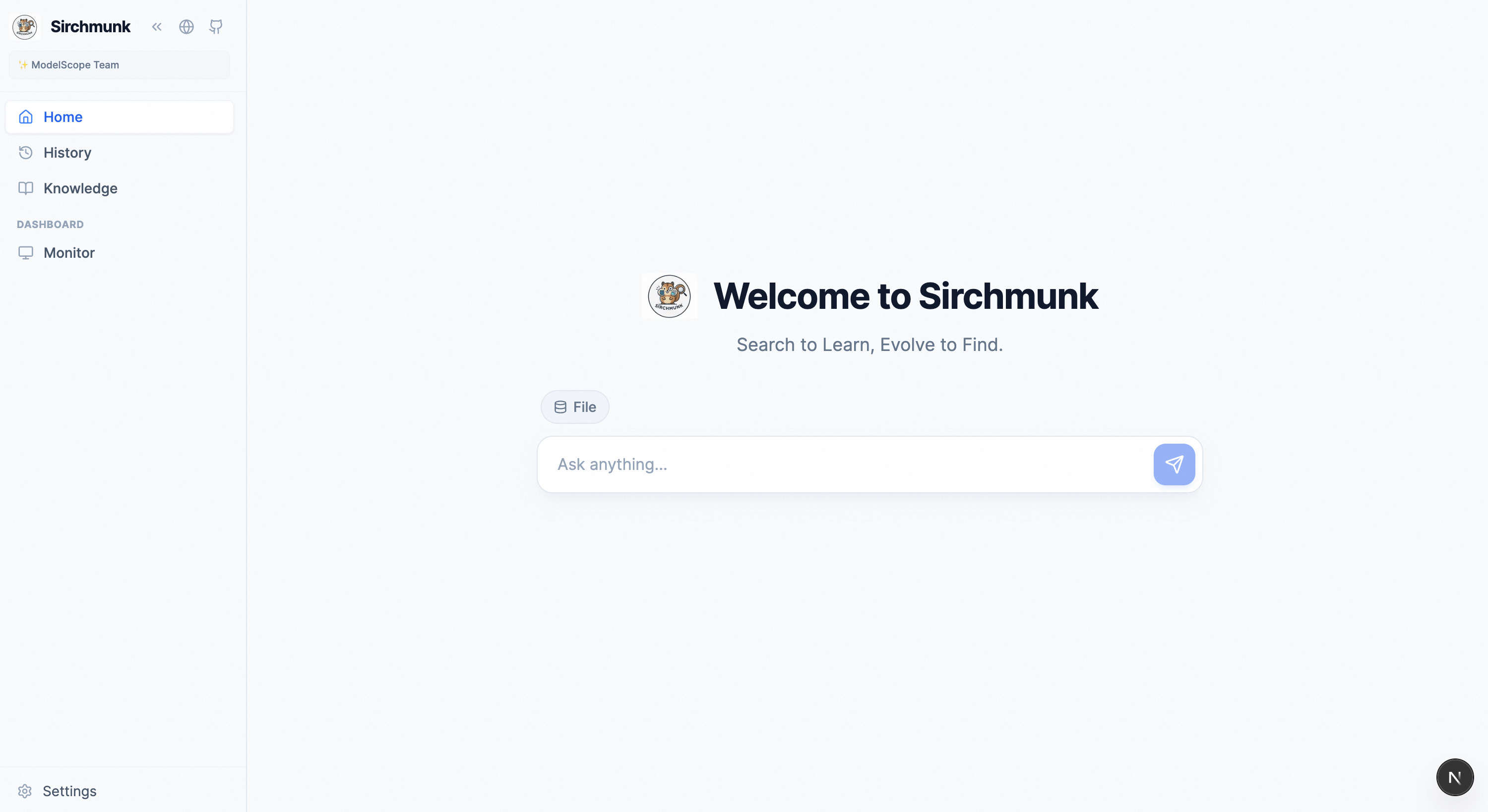
Home — Chat with streaming logs, file-based RAG, and session management.
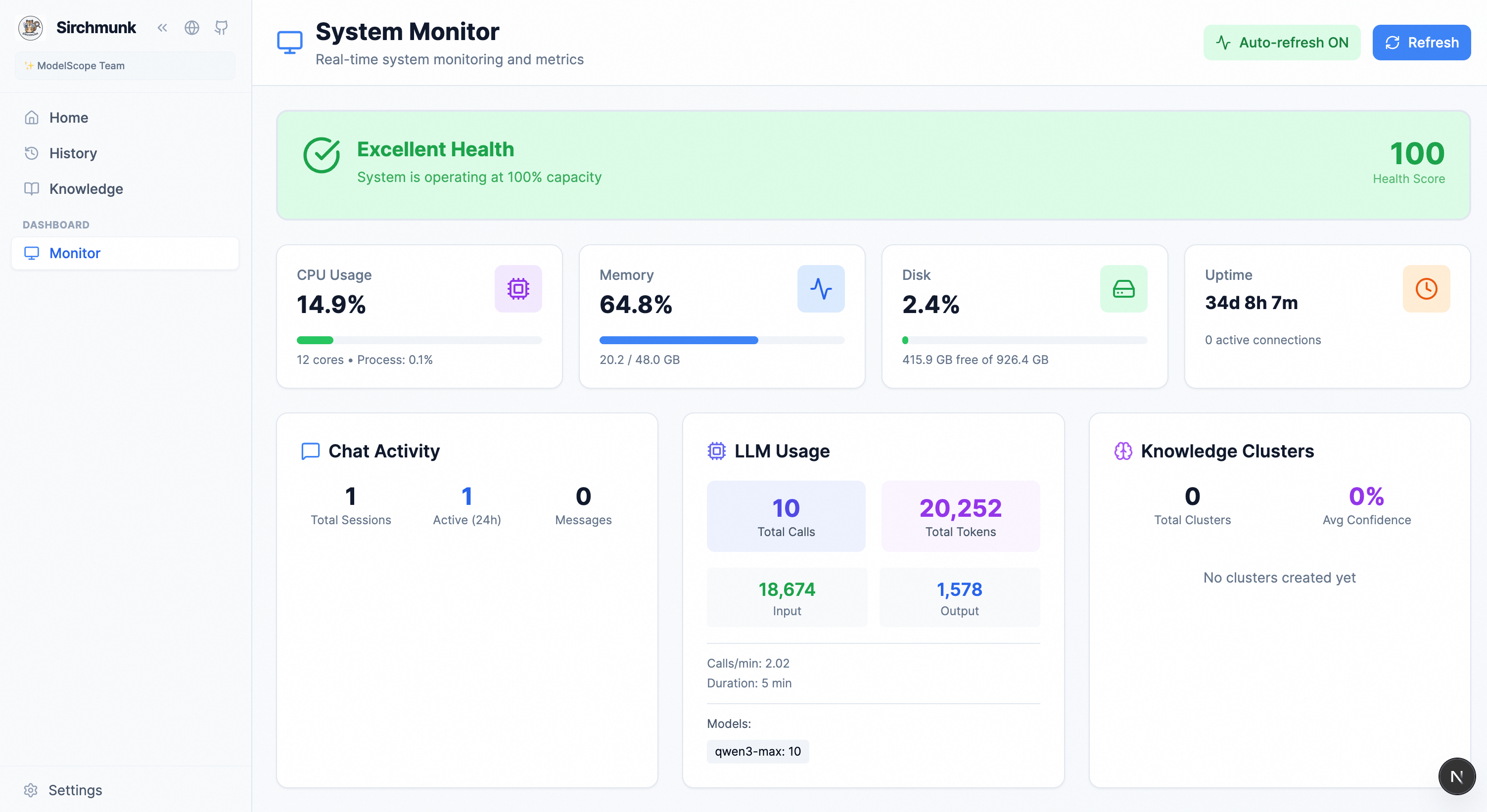
Monitor — System health, chat activity, knowledge analytics, and LLM usage.
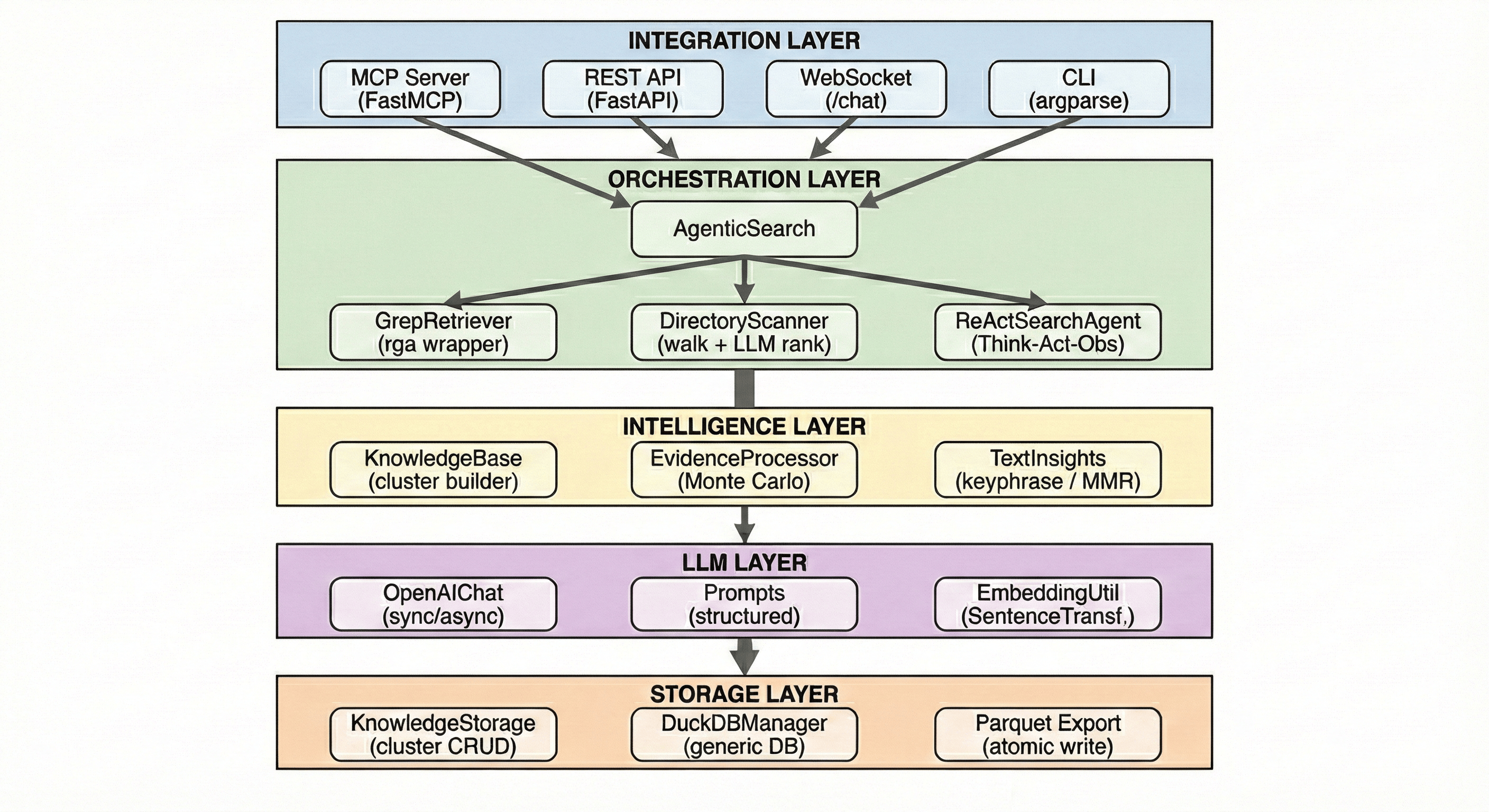
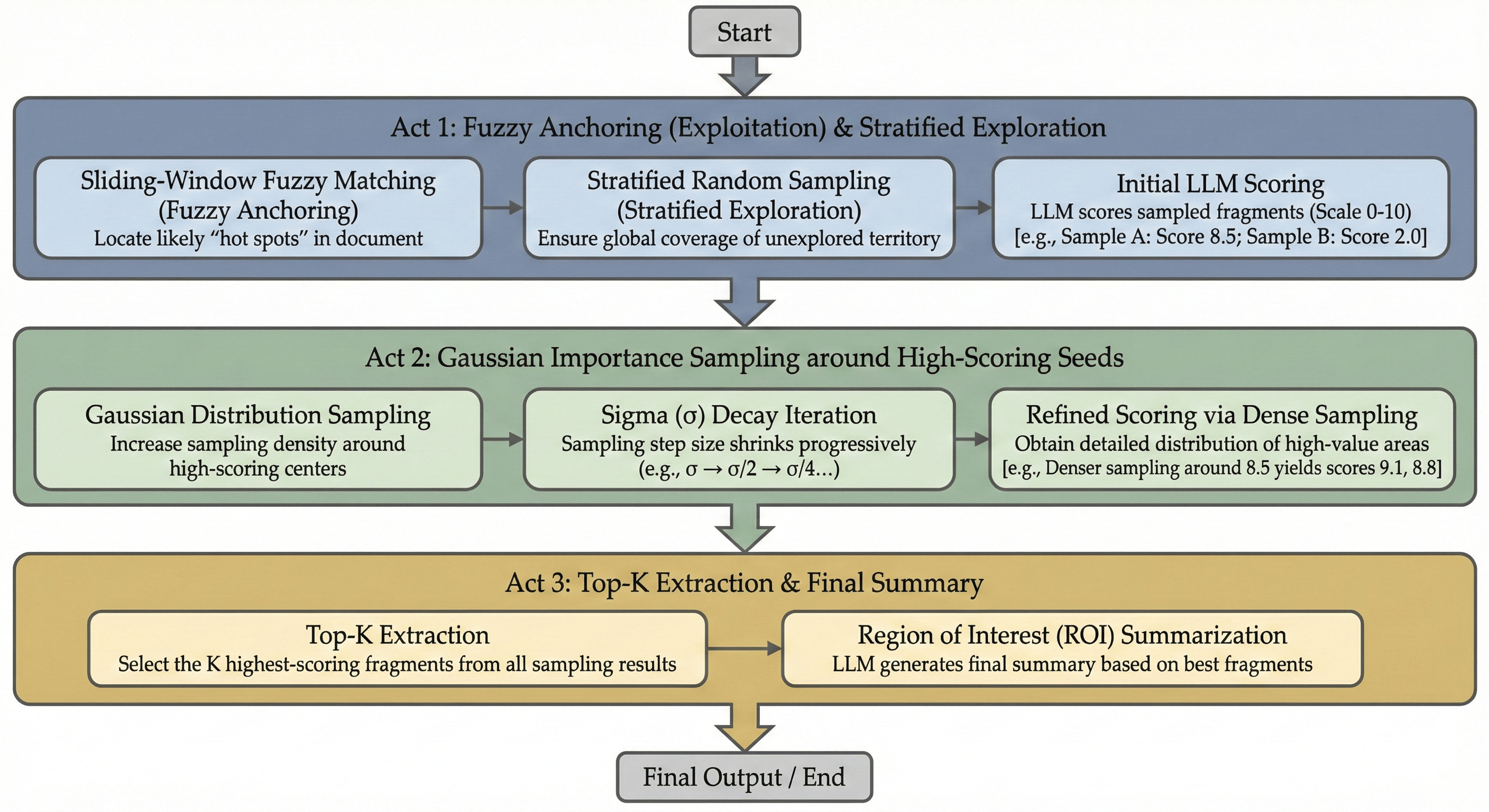
Monte Carlo Evidence Sampling — A three-phase exploration-exploitation strategy for extracting relevant evidence from large documents.
API 端点
| 方法 | 端点 | 描述 | |--------|----------|-------------| | `POST` | `/api/v1/search` | 执行搜索查询 | | `GET` | `/api/v1/search/status` | 检查服务器和 LLM 配置状态 | **交互式文档:** http://localhost:8584/docs (Swagger UI)cURL 示例
``` # FAST 模式(默认,贪婪搜索,包含 2 次 LLM 调用) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "How does authentication work?", "paths": ["/path/to/project"] }' # DEEP 模式(使用 Monte Carlo 采样进行综合分析) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "database connection pooling", "paths": ["/path/to/project/src"], "mode": "DEEP" }' # 文件名搜索(无需 LLM) curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "config", "paths": ["/path/to/project"], "mode": "FILENAME_ONLY" }' # 完整参数 curl -X POST http://localhost:8584/api/v1/search \ -H "Content-Type: application/json" \ -d '{ "query": "database connection pooling", "paths": ["/path/to/project/src"], "mode": "DEEP", "max_depth": 10, "top_k_files": 20, "keyword_levels": 3, "include_patterns": ["*.py", "*.java"], "exclude_patterns": ["*test*", "*__pycache__*"], "return_context": true }' # 检查服务器状态 curl http://localhost:8584/api/v1/search/status ```Python 客户端示例
**使用 `requests`:** ``` import requests response = requests.post( "http://localhost:8584/api/v1/search", json={ "query": "How does authentication work?", "paths": ["/path/to/project"], }, timeout=60 ) data = response.json() if data["success"]: print(data["data"]["result"]) ``` **使用 `httpx`(异步):** ``` import httpx import asyncio async def search(): async with httpx.AsyncClient(timeout=300) as client: resp = await client.post( "http://localhost:8584/api/v1/search", json={ "query": "find all API endpoints", "paths": ["/path/to/project"], } ) data = resp.json() print(data["data"]["result"]) asyncio.run(search()) ```JavaScript 客户端示例
``` const response = await fetch("http://localhost:8584/api/v1/search", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ query: "How does authentication work?", paths: ["/path/to/project"], }) }); const data = await response.json(); if (data.success) { console.log(data.data.result); } ```请求参数
| 参数 | 类型 | 默认值 | 描述 | |-----------|------|---------|-------------| | `query` | `string` | *必填* | 搜索查询或问题 | | `paths` | `string[]` | *必填* | 要搜索的目录或文件(至少 1 个) | | `mode` | `string` | `"FAST"` | `FAST`、`DEEP` 或 `FILENAME_ONLY` | | `max_depth` | `int` | `null` | 最大目录深度 | | `top_k_files` | `int` | `null` | 返回的热门文件数量 | | `keyword_levels` | `int` | `null` | 关键字粒度级别 | | `include_patterns` | `string[]` | `null` | 要包含的文件 glob 模式 | | `exclude_patterns` | `string[]` | `null` | 要排除的文件 glob 模式 | | `return_context` | `bool` | `false` | 返回带有簇和遥测数据的 SearchContext |<>这与传统 RAG 系统有何不同?
Sirchmunk 采用**无索引方法**: 1. **无预索引**:无需设置向量数据库即可直接搜索文件 2. **自我进化**:知识簇根据搜索模式演化 3. **多级检索**:自适应关键字粒度以获得更好的召回率 4. **基于证据**:蒙特卡洛采样用于精确的内容提取支持哪些 LLM 提供商?
任何 OpenAI 兼容的 API 端点,包括(但不限于): - OpenAI (GPT-5.2, ...) - 通过 Ollama、llama.cpp、vLLM、SGLang 等提供的本地模型 - 通过 API 代理的 Claude如何添加文档进行搜索?
只需在搜索查询中指定路径: ``` result = await searcher.search( query="Your question", paths=["/path/to/folder", "/path/to/file.pdf"] ) ``` 无需预处理或索引!知识簇存储在哪里?
知识簇以 Parquet 格式持久化存储在: ``` {SIRCHMUNK_WORK_PATH}/.cache/knowledge/knowledge_clusters.parquet ``` 您可以使用 DuckDB 或 `KnowledgeManager` API 查询它们。如何监控 LLM token 使用情况?
1. **Web 仪表板**:访问 Monitor 页面查看实时统计数据 2. **API**:`GET /api/v1/monitor/llm` 返回使用指标 3. **代码**:搜索完成后访问 `searcher.llm_usages`
**[ModelScope](https://github.com/modelscope)** · [⭐ 为我们加星](https://github.com/modelscope/sirchmunk/stargazers) · [🐛 报告 Bug](https://github.com/modelscope/sirchmunk/issues) · [💬 讨论](https://github.com/modelscope/sirchmunk/discussions)
*✨ Sirchmunk:原始数据到自我进化智能,实时。*
❤️ Thanks for Visiting ✨ Sirchmunk !
标签:AV绕过, Docker, DuckDB, FastAPI, MCP, Model Context Protocol, OLAP, OpenAI, Petitpotam, Python, RAG, ripgrep-all, TailwindCSS, 个人AI助理, 人工智能, 企业知识库, 全文搜索, 内存规避, 安全防御评估, 实时数据处理, 开源, 数据索引, 文本提取, 文档解析, 无后门, 智能体搜索, 本地知识库, 检索增强生成, 用户模式Hook绕过, 知识管理, 知识聚类, 自我进化, 语义搜索, 请求拦截, 逆向工具, 非结构化数据