mpoojaverma/SteganoML
GitHub: mpoojaverma/SteganoML
基于 CatBoost 机器学习的音频隐写框架,通过智能筛选声学稳定帧嵌入加密数据,实现抗压缩和抗噪声的隐蔽安全通信。
Stars: 0 | Forks: 0
# SteganoML
基于自适应机器学习的音频隐写术,用于稳健的安全通信
[]()
[]()
[]()
[]()
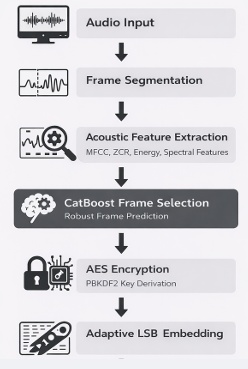
SteganoML 是一个基于自适应机器学习的音频隐写框架,它通过将加密的 payload 选择性嵌入到声学稳定的音频区域中,从而提高了鲁棒性、不可感知性以及安全的隐蔽通信能力。与传统的随机最低有效位 (LSB) 隐写方法不同,SteganoML 在嵌入秘密数据之前,使用监督机器学习来识别鲁棒的音频帧。该系统结合了基于 CatBoost 的帧选择、AES 加密、PBKDF2 密钥派生以及自适应 LSB 嵌入技术,以增强对压缩、噪声和信号处理攻击的抵抗力。
## 框架概述
# 发表信息
本工作发表于:
**2026 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET)** -
IEEE Xplore 收录
**论文标题:**
*SteganoML: An Adaptive ML-Driven Audio Steganography for Robust Secure Communication*
**DOI:**
[https://doi.org/10.1109/WiSPNET69615.2026.11489464](https://doi.org/10.1109/WiSPNET69615.2026.11489464)
**会议日期:**
2026年3月17–19日
**作者:**
M Pooja Verma, Sanjay Sakamuri, Sahaya Sakila V
# 主要特性
* 自适应 ML 指导的帧选择
* 基于 CatBoost 的监督分类
* AES-256 加密的 payload 保护
* PBKDF2 安全密钥派生
* 自适应 LSB 嵌入
* 抵御 MP3 压缩攻击的鲁棒性
* Payload 容量分析
* 定量的 PSNR、SNR、BER 和 NC 评估
* 用于编码和解码工作流的研究原型 GUI
* 音频可视化和频谱图分析
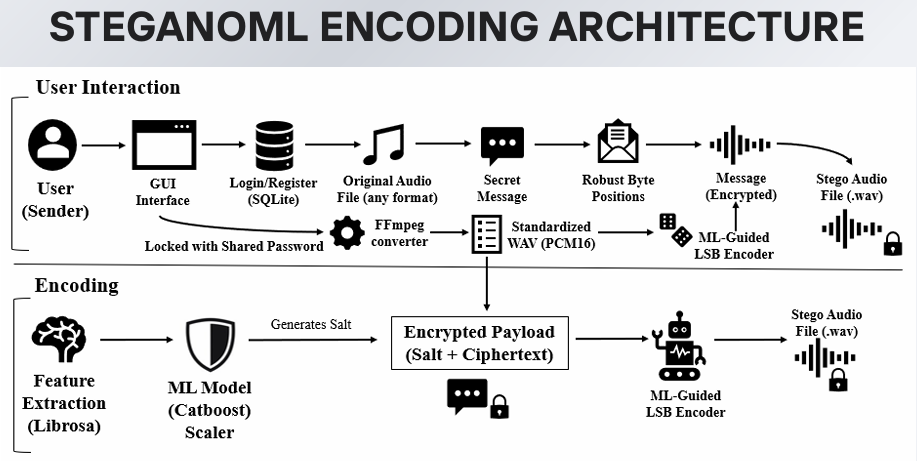
# 系统架构
## 编码架构
## 解码架构
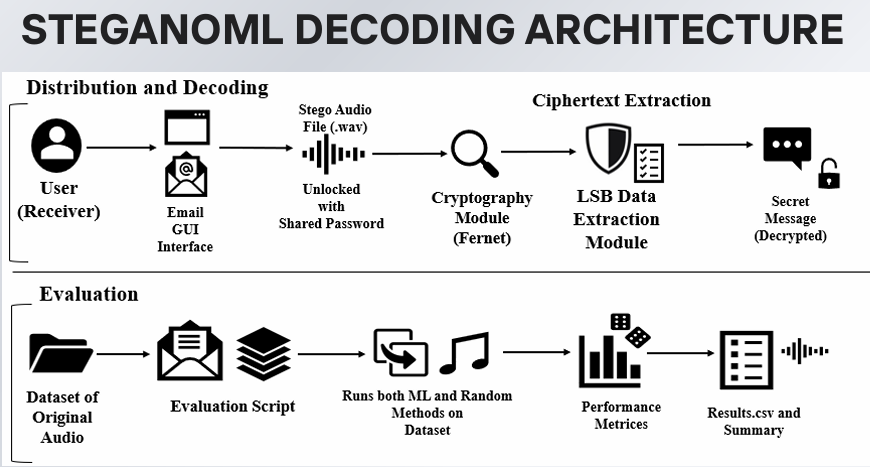
该框架有意识地将鲁棒性和不可感知性置于暴力的 payload 容量之上。
# 机器学习流程
监督学习流程使用了:
* MFCCs、过零率 (ZCR)
* 频谱质心、频谱对比度
* 色度、速度和能量特征
评估的候选模型:
| 模型 | ROC-AUC |
| ------------- | ------- |
| CatBoost | 0.9581 |
| XGBoost | 0.9580 |
| Random Forest | 0.9553 |
由于 CatBoost 具有卓越的鲁棒性和分类性能,因此被选中。
# 实验结果
SteganoML 使用以下指标针对传统的随机 LSB 基线进行了评估:
* 峰值信噪比 (PSNR)
* 信噪比 (SNR)
* 误码率 (BER)
* 归一化相关性 (NC)
## 定量比较
| 方法 | PSNR (dB) ↑ | SNR (dB) ↑ | BER ↓ | NC ↑ |
| -------------- | ----------- | ---------- | ----- | ---- |
| Randomized LSB | 94.28 | 71.62 | 1e-6 | 1.0 |
| SteganoML | 94.69 | 72.03 | 1e-6 | 1.0 |
所提出的框架实现了:
* 更高的 PSNR、改善的 SNR、强大的鲁棒性以及最小的听觉感知失真
# 鲁棒性分析
该框架针对以下情况进行了评估:
- MP3 压缩攻击
- 高斯噪声攻击
- 针对安静帧的定向噪声注入
- 信号处理失真
# 仓库结构
```
SteganoML/
│
├── data/ # Dataset used for model training
├── models/ # Trained CatBoost model and scalers
├── results/plots/ # Experimental plots and visual analysis
├── src/ # Research implementation
│
├── README.md
├── requirements.txt
└── .gitignore
```
# 研究范围
本仓库包含与已发表的 SteganoML 系统相关的研究实现、训练模型、评估框架、基准测试脚本和参考原型。
当前版本反映了在项目研究和发表阶段所使用的实现。
未来的开发将重点把该框架扩展为一个更高级的独立应用程序,具有改进的部署架构、可扩展性、优化和扩展的特性支持。
# 引用
如果您在研究中使用了本工作,请引用:
```
@inproceedings{steganoml2026,
title={SteganoML: An Adaptive ML-Driven Audio Steganography for Robust Secure Communication},
author={Verma, M Pooja and Sakamuri, Sanjay and Sakila, Sahaya V},
booktitle={2026 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET)},
year={2026},
organization={IEEE},
doi={10.1109/WiSPNET69615.2026.11489464}
}
```
# 安装说明
## 克隆仓库
```
git clone https://github.com/mpoojaverma/SteganoML.git
cd SteganoML
```
## 创建虚拟环境
```
python -m venv venv
```
## 安装依赖
```
pip install -r requirements.txt
```
# 环境要求
* 推荐使用 Python 3.10
* 安装 FFmpeg 并将其添加到 PATH
* 支持 Windows/Linux
由于某些音频处理和播放库的兼容性要求,推荐使用 Python 3.10。
# 使用方法
## 启动 GUI 应用
```
python main_app.py
```
GUI 支持:
* 音频编码
* 安全消息嵌入
* 音频解码
* 密码保护的提取
* 基于电子邮件的隐写音频分享
# 可重复性
本仓库包含了在论文中复现主要结果所需的实验框架、训练模型、评估方法和基准测试组件。
# 许可证
本项目基于 MIT 许可证发布。
标签:AES-256, Apex, CatBoost, IEEE论文, LSB隐写, Python, 不可见性, 信号处理, 信噪比(SNR), 信息隐藏, 安全通信, 密钥派生(PBKDF2), 峰值信噪比(PSNR), 抗压缩隐写, 搜索语句(dork), 数据加密, 无后门, 机器学习, 漏洞评估, 特征提取, 网络安全, 自适应隐写, 逆向工具, 隐写分析, 隐私保护, 隐蔽通信, 音频处理, 音频隐写术, 鲁棒性分析