rushil-thareja/dp-fusion-lib
GitHub: rushil-thareja/dp-fusion-lib
一个为大型语言模型推理提供数学可证明差分隐私保证的 Python 库,支持 PII 检测、改写和正式 (ε, δ)-DP 保护。
Stars: 45 | Forks: 2

[](https://pypi.org/project/dp-fusion-lib/)
[](https://www.python.org/downloads/)
[](LICENSE)
[](https://arxiv.org/abs/2507.04531)
[](https://www.documentprivacy.com/)
[](https://console.documentprivacy.com/)
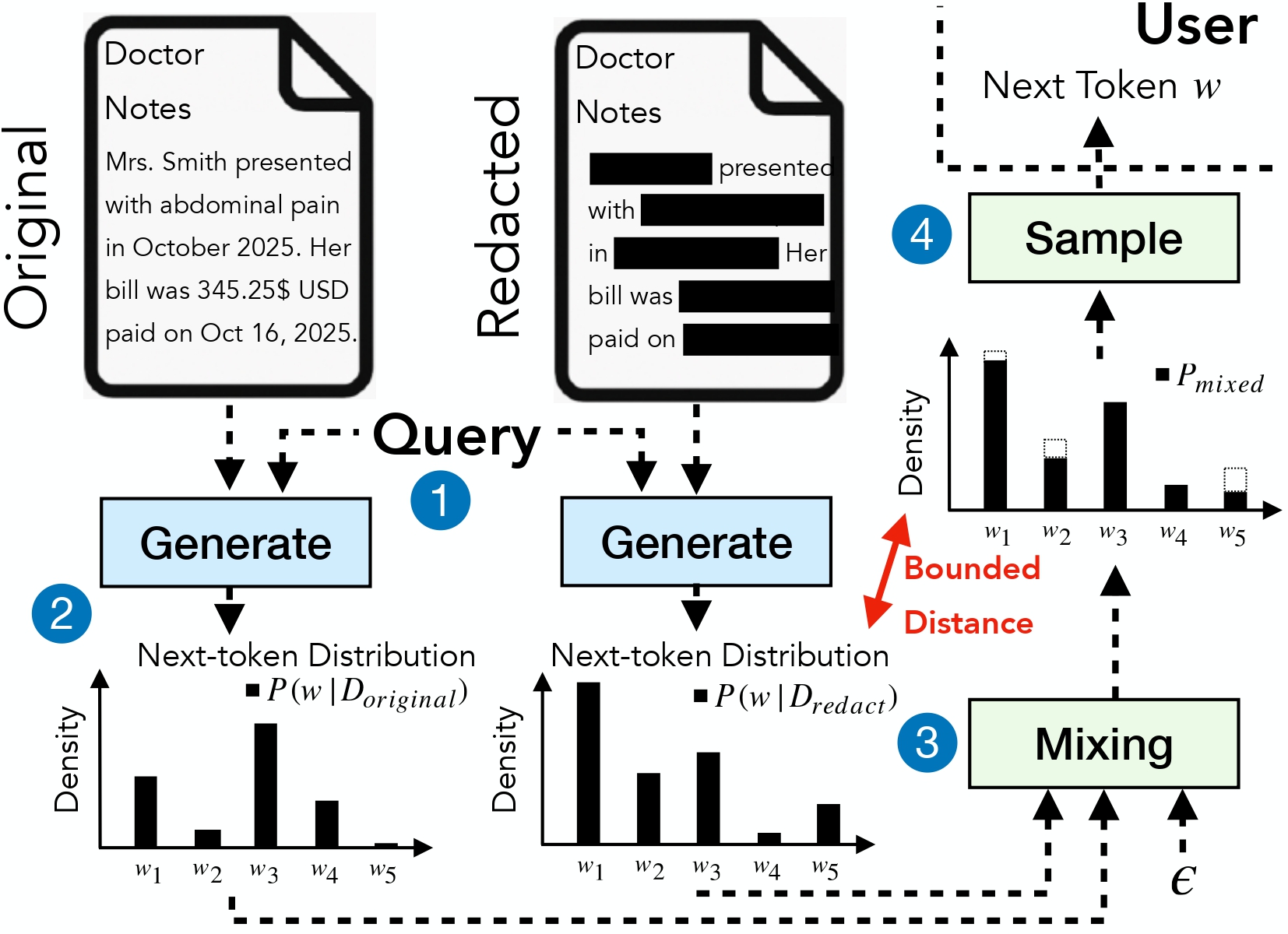
**DP-Fusion-Lib** 支持对大型语言模型进行具有数学可证明差分隐私保证的推理。基于我们的研究论文 [*"DP-Fusion: Token-Level Differentially Private Inference for Large Language Models"*](https://arxiv.org/abs/2507.04531),该库为敏感的文本生成工作流程提供正式的 (ε, δ)-DP 保护。
差分隐私是核心基础,但该库涵盖了**文本和文档隐私的完整领域**。其 **PII 检测和重写工具**可以**与 DP 一起使用或单独使用**,默认提供实用的隐私保护,启用 DP 时提供**正式保证**。
**[试用在线演示](https://www.documentprivacy.com)**
**[运行示例协作笔记本](https://colab.research.google.com/drive/1hzoUAXF_jsFU9E3D6U5ceZdYZ3wfXPPd?usp=sharing)**
## 概述
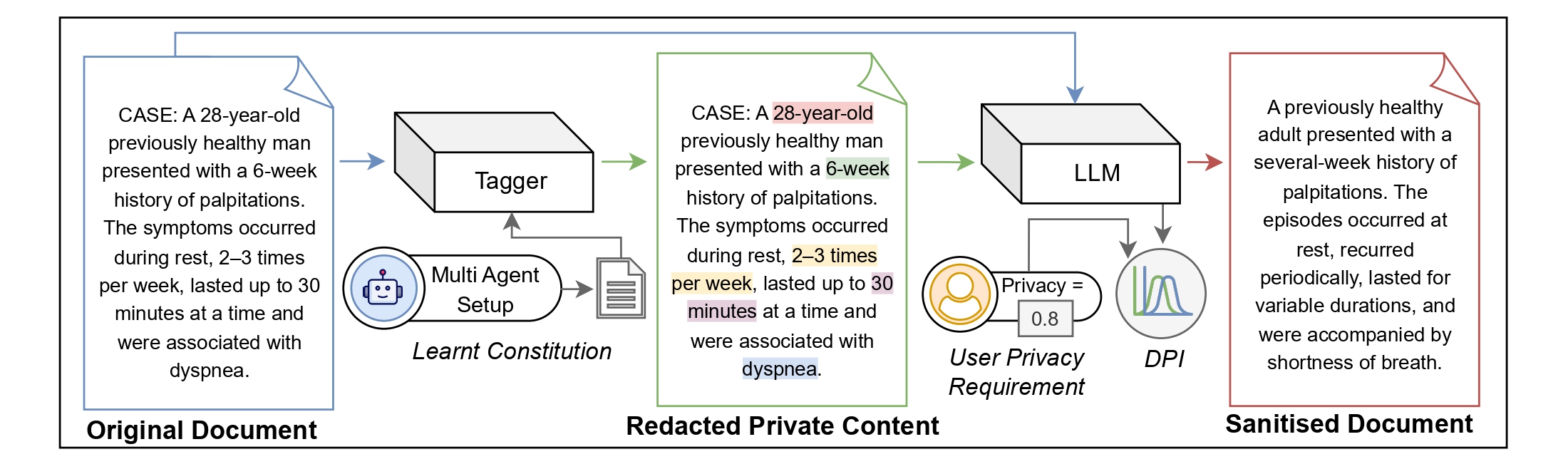
传统的大型语言模型隐私方法依赖于启发式编辑或事后过滤。**DP-Fusion-Lib** 通过提供具有三个保护级别的完整隐私框架更进一步:
| 级别 | 方法 | 保护 |
|-------|----------|------------|
| 1 | **编辑** | 通过 Constitutional Tagger API 自动检测和替换 PII |
| 2 | **改写** | 上下文重写以隐藏风格和上下文特征 |
| 3 | **差分隐私** | 通过受控分布融合提供正式的 (ε, δ)-DP 保证 |
该库通过融合来自私有和编辑上下文的 token 概率分布来实现第 3 级保护,在每个生成步骤中限制 Rényi 散度,从而提供可证明的隐私保证。
## 技术方法
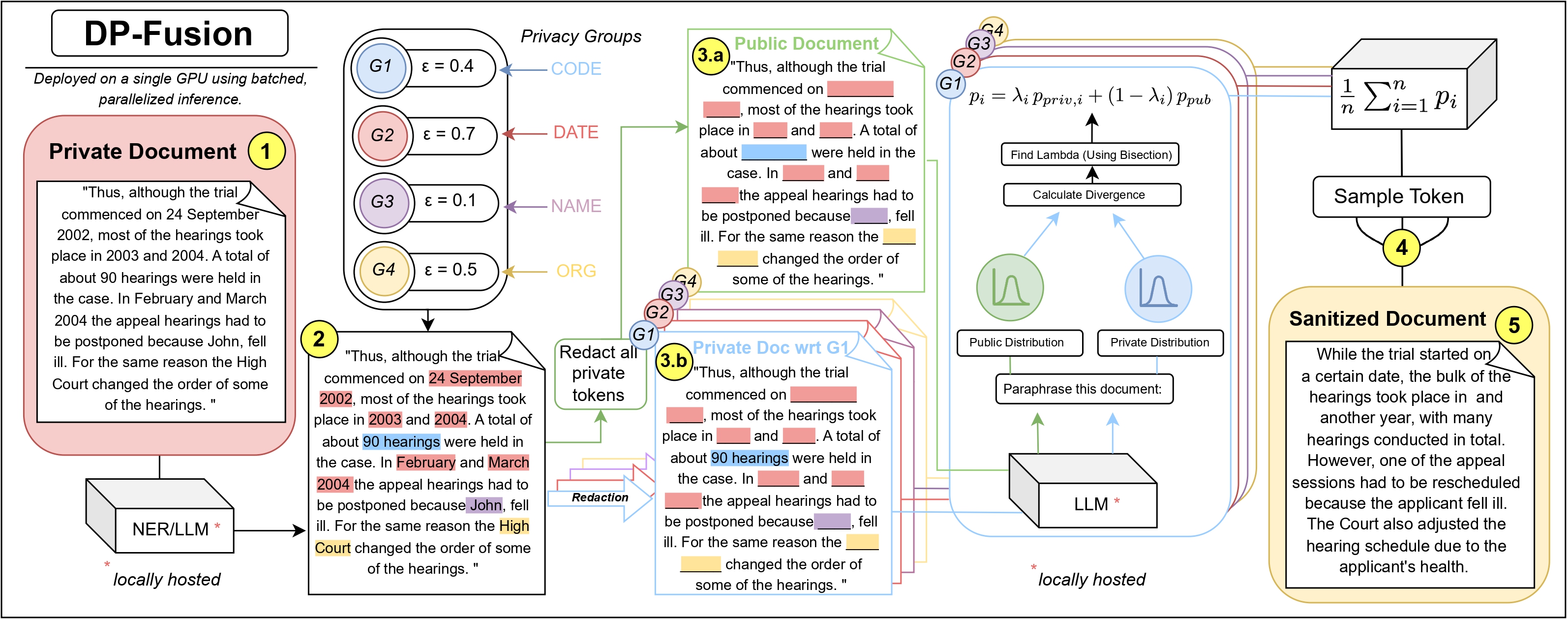
DP-Fusion 通过在生成过程中维护两个并行上下文来运行:
- **私有上下文**:包含敏感信息的原始文档
- **公共上下文**:用占位符替换敏感短语后的编辑版本
在每个 token 生成步骤中,算法:
1. 计算两个上下文的下一个 token 概率分布
2. 执行二分搜索找到最优混合参数 λ
3. 确保融合分布满足 Rényi 散度约束
4. 从保护隐私的混合分布中采样
这种方法保证输出分布无论是否存在特定私有信息都统计相似,从而提供正式的差分隐私。
## 安装
```
pip install dp-fusion-lib
```
**硬件要求**:此库需要 PyTorch。对于生产部署,建议使用 NVIDIA GPU 加速。`Qwen/Qwen2.5-7B-Instruct` 模型在生成质量和隐私效用之间提供了有效的平衡。
```
# For CUDA 12.1 环境
pip install torch --index-url https://download.pytorch.org/whl/cu121
pip install dp-fusion-lib
```
## 快速入门
有关完整的工作示例,请参阅[基本使用脚本](examples/basic_usage.py)或运行交互式 [Jupyter 笔记本](examples/basic_usage.ipynb)。
### 步骤 1:初始化组件
Tagger API 使用 Constitutional AI 提供自动敏感短语检测。API 密钥可在 [console.documentprivacy.com](https://console.documentprivacy.com) 获取。
```
from dp_fusion_lib import DPFusion, Tagger, compute_epsilon_single_group
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype=torch.float16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
# 初始化 Tagger
tagger = Tagger(api_key="your_api_key")
tagger.set_model("gpt-oss-120b") # Strong extraction model
tagger.set_constitution("LEGAL") # Options: LEGAL, HEALTH, FINANCE
```
### 步骤 2:构建上下文
该库仅对标记为私有的段落应用差分隐私,允许精确控制哪些内容受到保护。
```
dpf = DPFusion(model=model, tokenizer=tokenizer, max_tokens=100, tagger=tagger)
# 包含敏感信息的示例文档
document = """The applicant was born in 1973 and currently resides in
Les Salles-sur-Verdon, France. In the early 1990s, a new criminal
phenomenon emerged in Denmark known as 'tax asset stripping cases'."""
# 构建带有隐私注释的上下文
dpf.add_message("system", "You are a helpful assistant that paraphrases text.", is_private=False)
dpf.add_message("user", document, is_private=True) # Mark sensitive content as private
dpf.add_message("system", "Now paraphrase this text for privacy", is_private=False)
dpf.add_message("assistant", "Sure, here is the paraphrase of the above text that ensures privacy:", is_private=False)
```
### 步骤 3:运行 Tagger 构建私有和公共上下文
Tagger 自动识别敏感短语并创建两个并行上下文:
```
# 运行 tagger 以提取 PII 并构建编辑后的上下文
dpf.run_tagger()
# 提取的短语: ['1973', 'Les Salles-sur-Verdon', 'early 1990s', 'tax asset stripping cases']
# 查看 DP-Fusion 使用的两个上下文:
print(dpf.private_context) # Original text with real values
print(dpf.public_context) # Redacted text with ____ placeholders
```
**私有上下文**(模型看到完整信息的版本):
```
The applicant was born in 1973 and currently resides in Les Salles-sur-Verdon, France.
In the early 1990s, a new criminal phenomenon emerged in Denmark...
```
**公共上下文**(编辑后的版本):
```
The applicant was born in ____ and currently resides in _________.
In the _______, a new criminal phenomenon emerged in Denmark...
```
### 步骤 4:使用差分隐私进行生成
```
# 使用差分隐私生成
output = dpf.generate(
alpha=2.0, # Rényi order
beta=0.01, # Per-token privacy budget
max_new_tokens=100
)
print(output['text'])
```
### 步骤 5:计算隐私保证
该库提供两个 epsilon 值用于全面的隐私核算:
```
alpha = 2.0
beta = 0.01
delta = 1e-5
eps_result = compute_epsilon_single_group(
divergences=output['divergences']['PRIVATE'],
alpha=alpha,
delta=delta,
beta=beta
)
print(f"(ε, δ)-DP Guarantee (α={alpha}, δ={delta}, T={eps_result['T']} tokens):")
print(f" Empirical ε = {eps_result['empirical']:.4f} (from actual divergences)")
print(f" Theoretical ε = {eps_result['theoretical']:.4f} (worst-case, β={beta} per step)")
```
| Epsilon 类型 | 描述 | 使用场景 |
|--------------|-------------|----------|
| **经验 ε** | 根据生成过程中观察到的实际每步散度计算 | 反映真实隐私成本的更严格界限 |
| **理论 ε** | 假设每一步都存在最大散度 (α·β) 的最坏情况界限 | 合规报告的保守上限 |
## 隐私参数
| 参数 | 符号 | 描述 | 权衡 |
|-----------|--------|-------------|-----------|
| Beta | β | 每个 token 的最大 Rényi 散度 | β 越低 → 隐私越强,效用降低 |
| Alpha | α | Rényi 散度阶数(必须 > 1) | α 越高 → 界限越紧,不同的隐私机制 |
| Delta | δ | 隐私失败概率 | δ 越低 → 保证越强,ε 越高 |
| Epsilon | ε | 总隐私预算(计算得出) | ε 越低 → 隐私保证越强 |
**建议**:对于大多数应用,从 `alpha=2.0` 和 `beta=0.01` 开始。根据您的隐私-效用需求进行调整。
## 数据隐私
虽然 `dp-fusion-lib` 完全在您的基础设施上运行,但 Tagger API 需要外部调用来进行敏感短语检测。对于有严格数据驻留或合规要求的人,请联系我,我会提供帮助。
联系 [rushil.thareja@mbzuai.ac.ae](mailto:rushil.thareja@mbzuai.ac.ae)。
## 引用
如果您在学术工作中使用此库,请引用:
```
@misc{thareja2025dpfusion,
title={DP-Fusion: Token-Level Differentially Private Inference for Large Language Models},
author={Rushil Thareja and Preslav Nakov and Praneeth Vepakomma and Nils Lukas},
year={2025},
eprint={2507.04531},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.04531}
}
```
## 许可证
DP-Fusion-Lib 采用双许可证:
| 使用场景 | 许可证 | 费用 |
|----------|---------|------|
| 学术研究 | 非商业许可证 | 免费 |
| 教育用途 | 非商业许可证 | 免费 |
| 商业产品 | 商业许可证 | 联系询价 |
## 支持
- **文档**:[GitHub 仓库](https://github.com/rushil-thareja/dp-fusion-lib)
- **问题**:[GitHub Issues](https://github.com/rushil-thareja/dp-fusion-lib/issues)
- **任何问题?给我发邮件**:[rushil.thareja@mbzuai.ac.ae](mailto:rushil.thareja@mbzuai.ac.ae)
标签:AI安全, Chat Copilot, DLL 劫持, NLP, PII检测, 个人信息保护, 凭据扫描, 大语言模型, 差分隐私, 差分隐私库, 敏感数据保护, 数据脱敏, 数据隐私, 文本清洗, 文本重写, 文本隐私, 文档隐私, 网络安全, 逆向工具, 隐私保护, 隐私计算