raphaelmansuy/edgequake
GitHub: raphaelmansuy/edgequake
基于 Rust 实现的 LightRAG 算法,将向量检索与知识图谱遍历结合,提供高性能、可扩展的文档智能检索与多跳推理能力。
Stars: 2002 | Forks: 229
# EdgeQuake
[](CHANGELOG.md)
[](https://www.rust-lang.org)
[](LICENSE)
[](https://github.com/raphaelmansuy/edgequake)
[](docs/README.md)
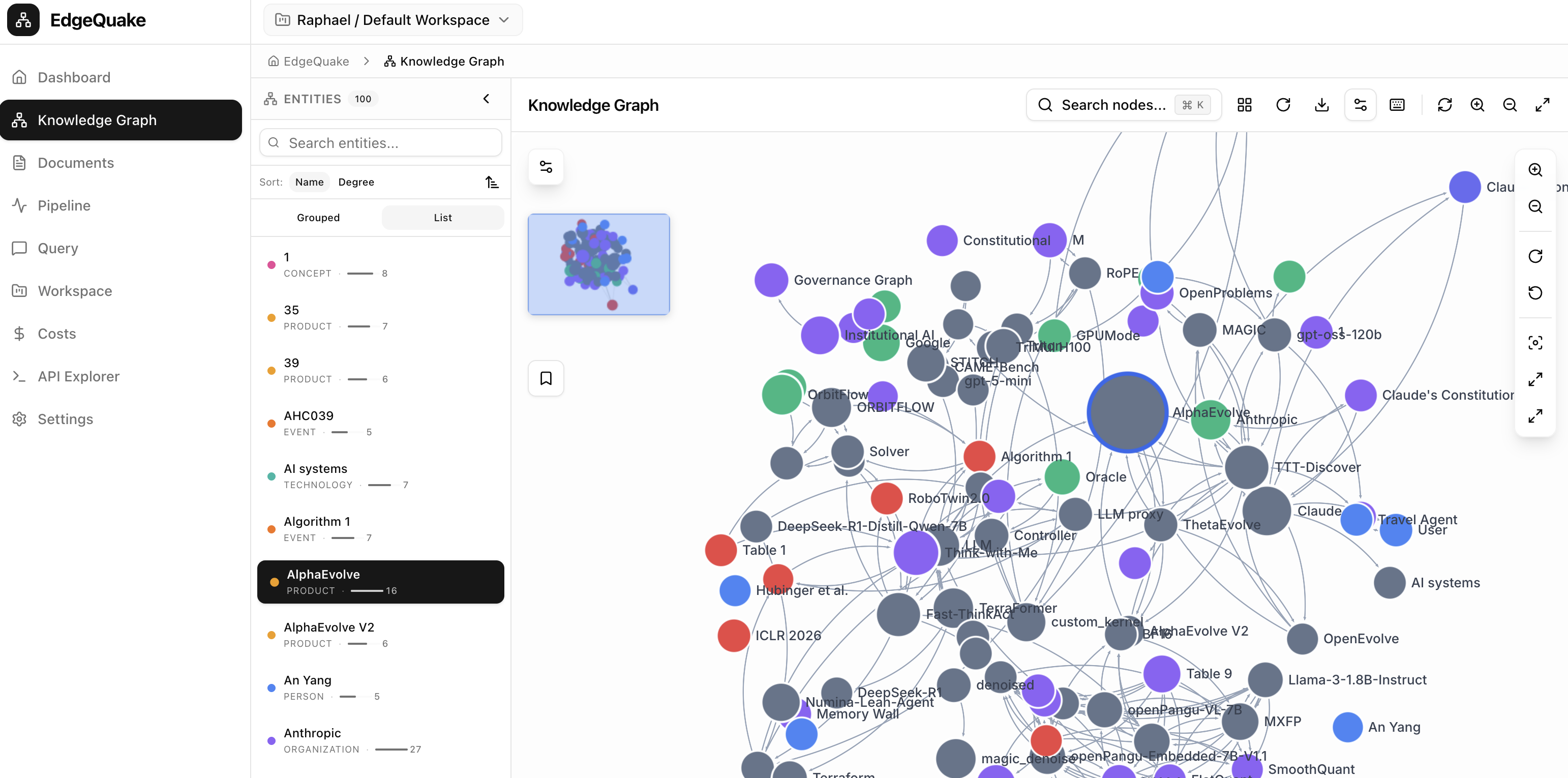
## 为什么选择 EdgeQuake?
传统的 RAG 系统仅使用向量相似性来检索文档块。这对于简单的查找有效,但在多跳推理(“X 如何通过 Z 与 Y 关联?”)、主题性问题(“主要主题是什么?”)以及关系查询方面表现不佳。核心问题在于:**向量捕捉了语义相似性,但丢失了概念之间的结构关系**。
**EdgeQuake** 通过在 Rust 中实现 [LightRAG 算法](https://arxiv.org/abs/2410.05779) 解决了这个问题:文档不仅被分块和嵌入,还被分解为由实体和关系组成的**知识图谱**。在查询时,系统同时遍历向量空间和图结构,结合了向量搜索的速度和图遍历的推理能力。
### EdgeQuake 的独特之处
- **知识图谱**:LLM 驱动的实体提取和关系映射创建了对文档的结构化理解 —— 不仅仅是关键词匹配
- **6 种查询模式**:从快速的朴素向量搜索到图遍历混合查询,每种模式都针对不同的问题类型进行了优化
- **Rust 性能**:Async-first Tokio 架构,零拷贝操作 —— 可处理数千个并发请求
- **PDF LLM 视觉管道 ✅ 0.4.0 版本新增**:多模态 LLM(GPT-4o、Claude、Gemini)将 PDF 页面作为图像读取 —— 开箱即处理扫描文档、复杂表格和多栏布局
- **生产就绪**:OpenAPI 3.0 REST API、SSE 流式传输、健康检查、多租户工作空间隔离
- **现代前端**:React 19 配合交互式 Sigma.js 图可视化
### 性能基准测试
| 指标 | EdgeQuake | 传统 RAG | 提升 |
| ---------------------- | ---------------- | --------------- | ----------- |
| 实体提取 | ~2-3x 更多 | 基线 | 3x |
| 查询延迟(混合) | < 200ms | ~1000ms | 快 5x |
| 文档处理 | 25s (10k tokens) | ~60s | 快 2.4x |
| 并发用户 | 1000+ | ~100 | 10x |
| 内存使用(每文档) | 2MB | ~8MB | 优 4x |
## 功能特性
### 🚀 高性能
- **Async-First**:基于 Tokio 的运行时,实现最大并发
- **Zero-Copy**:利用 Rust 所有权机制进行高效的内存管理
- **并行处理**:多线程实体提取和嵌入
- **快速存储**:使用 PostgreSQL AGE 存储图 + pgvector 存储嵌入
### 知识图谱
- **实体提取**:自动检测人员、组织、地点、概念、事件、技术和产品(7 种可配置类型)
- **关系映射**:LLM 驱动的关系识别与关键词标记
- **Gleaning**:多轮提取比单轮提取多发现 15-25% 的实体
- **社区发现**:Louvain 模块度优化将相关实体聚类,用于主题查询
- **图可视化**:支持缩放/平移的交互式 Sigma.js 前端
### 📄 PDF 处理(v0.4.0 版本已生产就绪)
- **文本模式**:基于 pdfium 的快速提取,适用于标准 PDF(默认,零配置)
- **视觉模式** ✨:LLM 将每一页作为图像读取 —— 支持 GPT-4o、Claude 3.5+、Gemini 2.5
- **自动回退**:视觉失败时优雅回退到文本提取 (BR1010)
- **表格重构**:视觉模式能恢复被文本解析器破坏的复杂表格
- **多栏布局**:LLM 理解多栏页面的阅读顺序
- **内嵌 pdfium**:无需 `PDFIUM_DYNAMIC_LIB_PATH` 环境变量 —— 二进制文件内置于程序中
### 🔍 6 种查询模式
1. **Naive**:简单的向量相似性 —— 最适合类关键词查找(~100-300ms)
2. **Local**:以实体为中心的局部图邻域 —— 最适合特定关系查询(~200-500ms)
3. **Global**:基于社区的语义搜索 —— 最适合主题性/高层次问题(~300-800ms)
4. **Hybrid** _(默认)_:结合 Local + Global 获得平衡、全面的结果(~400-1000ms)
5. **Mix**:Naive + 图结果的可配置加权组合
6. **Bypass**:无 RAG 检索的直接 LLM 查询 —— 适用于一般性问题
### 🌐 REST API
- **OpenAPI 3.0**:完整的 Swagger 文档位于 `/swagger-ui`
- **流式传输**:Server-Sent Events (SSE) 实现实时响应
- **版本化**:`/api/v1/*` 保证向后兼容性
- **健康检查**:Kubernetes 就绪的 `/health`、`/ready`、`/live`
### 🎯 React 19 前端
- **实时流式传输**:逐 Token 生成显示
- **图可视化**:支持缩放/平移的交互式网络图
- **文档上传**:拖放上传并跟踪进度
- **配置 UI**:可视化 PDF 处理配置构建器
### 🔌 MCP (Model Context Protocol)
- **Agent 集成**:通过 [MCP](https://modelcontextprotocol.io/) 将 EdgeQuake 能力暴露给 AI Agent
- **工具发现**:Agent 可以编程方式查询、上传和探索知识图谱
- **互操作性**:兼容 Claude、Cursor 和其他 MCP 兼容客户端
详见 [mcp/](mcp/) 获取服务器实现细节。
## 快速开始
### 前置条件
- **Rust**:1.78 或更高版本([安装 Rust](https://rustup.rs))
- **Node.js**:18+ 或 Bun 1.0+([安装 Node](https://nodejs.org))
- **Docker**:用于 PostgreSQL([安装 Docker](https://www.docker.com/get-started))
- **Ollama**:用于本地 LLM(可选,[安装 Ollama](https://ollama.ai))
### 安装(5 分钟)
```
# 1. Clone 仓库
git clone https://github.com/raphaelmansuy/edgequake.git
cd edgequake
# 2. 安装依赖
make install
# 3. 启动 Full Stack (PostgreSQL + Backend + Frontend)
make dev
```
**完成了!** 🎉
- **后端**:http://localhost:8080
- **前端**:http://localhost:3000
- **Swagger UI**:http://localhost:8080/swagger-ui
- **提供商**:Ollama(本地,免费)
### 首次文档上传
```
# 上传文件 (PDF, TXT, MD 等)
curl -X POST http://localhost:8080/api/v1/documents/upload \
-F "file=@your-document.pdf"
```
**响应**:
```
{
"id": "doc-123",
"status": "completed",
"chunk_count": 15,
"entity_count": 12,
"relationship_count": 8,
"processing_time_ms": 2500
}
```
### 首次查询
```
# 查询知识图谱
curl -X POST http://localhost:8080/api/v1/query \
-H "Content-Type: application/json" \
-d '{
"query": "What are the main concepts?",
"mode": "hybrid"
}'
```
**响应**:
```
{
"answer": "The main concepts are: knowledge graphs, entity extraction, and hybrid retrieval...",
"sources": [
{ "chunk_id": "chunk-1", "similarity": 0.92 },
{ "chunk_id": "chunk-5", "similarity": 0.87 }
],
"entities": ["KNOWLEDGE_GRAPH", "ENTITY_EXTRACTION"],
"relationships": [
{
"source": "KNOWLEDGE_GRAPH",
"target": "ENTITY_EXTRACTION",
"type": "ENABLES"
}
]
}
```
## 架构
```
┌────────────────────────────────────────────────────────────────────────────┐
│ EdgeQuake System │
└────────────────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────────────────┐
│ Frontend (React 19 + TypeScript) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Document │ │ Query │ │ Graph │ │ Settings │ │
│ │ Upload │ │ Interface │ │ Visualization│ │ Config │ │
│ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │ │ │
│ └─────────────────┴─────────────────┴─────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────────────────────────────────────────────┐ │
│ │ REST API (Axum) │ │
│ │ /api/v1/documents • /api/v1/query • /api/v1/graph │ │
│ │ OpenAPI 3.0 Spec • SSE Streaming • Health Checks │ │
│ └────────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────────┐
│ Backend (Rust - 11 Crates) │
│ ┌──────────────────────────────────────────────────────────────────────┐ │
│ │ edgequake-core │ Orchestration & Pipeline │ │
│ │ edgequake-llm │ OpenAI, Ollama, LM Studio, Mock │ │
│ │ edgequake-storage │ PostgreSQL AGE, Memory adapters │ │
│ │ edgequake-api │ REST API server │ │
│ │ edgequake-pipeline │ Document ingestion pipeline │ │
│ │ edgequake-query │ Query engine (6 modes) │ │
│ │ edgequake-pdf │ PDF extraction (text/vision/hybrid) │ │
│ │ edgequake-auth │ Authentication & authorization │ │
│ │ edgequake-audit │ Compliance & audit logging │ │
│ │ edgequake-tasks │ Background job processing │ │
│ │ edgequake-rate-limiter │ Rate limiting middleware │ │
│ └──────────────────────────────────────────────────────────────────────┘ │
│ │ │
│ ┌───────────────┴───────────────┐ │
│ ▼ ▼ │
│ ┌─────────────────────────────┐ ┌──────────────────────────────────┐ │
│ │ LLM Providers │ │ Storage Backends │ │
│ │ • OpenAI (gpt-4.1-nano) │ │ • PostgreSQL 15+ (AGE + vector) │ │
│ │ • Ollama (gemma3:12b) │ │ • In-Memory (dev/testing) │ │
│ │ • LM Studio (local models) │ │ • Graph: Property graph model │ │
│ │ • Mock (testing, free) │ │ • Vector: pgvector embeddings │ │
│ │ Auto-detection via env │ │ │ │
│ └─────────────────────────────┘ └──────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────────┘
Data Flow: Document → Chunks → Entities → Graph
Query Flow: Question → Graph Traversal → LLM → Answer
```
### 算法工作原理
EdgeQuake 在 Rust 中实现了 [LightRAG 算法](https://arxiv.org/abs/2410.05779)。核心洞察:**在索引期间提取知识图谱,在查询期间遍历它**。
**索引管道**(每个文档):
1. **Chunk(分块)** — 将文档拆分为 ~1200 Token 的片段,100 Token 重叠
2. **Extract(提取)** — LLM 将每个块解析为 `(实体, 类型, 描述)` 和 `(源, 目标, 关键词, 描述)` 元组
3. **Glean(拾遗)** — 可选的第二轮提取捕获遗漏的实体(召回率提升约 18%)
4. **Normalize(归一化)** — 通过大小写归一化和描述合并来去重实体(减少重复约 36-40%)
5. **Embed(嵌入)** — 为块和实体生成向量嵌入
6. **Store(存储)** — 写入 PostgreSQL:块存入 pgvector,实体/关系存入 Apache AGE 图
**查询流程**(6 种模式):
- **Naive** — 仅对块进行向量相似性计算(快,无图)
- **Local** — 通过向量搜索找到相关实体,然后遍历其局部图邻域
- **Global** — 使用 Louvain 社区发现找到主题聚类,检索社区摘要
- **Hybrid** _(默认)_ — 结合局部实体上下文 + 全局社区上下文
- **Mix** — Naive 向量结果和图增强结果的加权混合
- **Bypass** — 完全跳过检索,将问题直接传递给 LLM
完整的技术解释请参阅 [LightRAG 算法深入解析](docs/deep-dives/lightrag-algorithm.md)。
## 文档
### 📚 完整文档索引
在 [docs/README.md](docs/README.md) 探索完整文档
### 📦 SDK
EdgeQuake 为多种语言提供官方 SDK:
- [Python SDK](sdks/python/README.md) ([更新日志](sdks/python/CHANGELOG.md))
- [TypeScript SDK](sdks/typescript/README.md) ([更新日志](sdks/typescript/CHANGELOG.md))
- [Rust SDK](sdks/rust/README.md)
- [其他 SDK](sdks/) 适用于 C#、Go、Java、Kotlin、PHP、Ruby、Swift
SDK 和核心更新请参阅 [CHANGELOG.md](CHANGELOG.md)。
### 🚀 入门指南(15 分钟)
| 指南 | 描述 | 时间 |
| ---------------------------------------------------------- | -------------------------- | ------ |
| [安装](docs/getting-started/installation.md) | 前置条件和设置 | 5 分钟 |
| [快速开始](docs/getting-started/quick-start.md) | 首次摄入和查询 | 10 分钟 |
| [首次摄入](docs/getting-started/first-ingestion.md) | 理解管道 | 15 分钟 |
### 📖 教程(实践)
| 教程 | 描述 |
| -------------------------------------------------------------------- | ------------------------------- |
| [构建你的第一个 RAG 应用](docs/tutorials/first-rag-app.md) | 端到端教程 |
| [PDF 摄入](docs/tutorials/pdf-ingestion.md) | PDF 上传和配置 |
| [多租户设置](docs/tutorials/multi-tenant.md) | 工作空间隔离 |
| [文档摄入](docs/tutorials/document-ingestion.md) | 上传和处理工作流 |
| [从 LightRAG 迁移](docs/tutorials/migration-from-lightrag.md) | Python 到 Rust 迁移指南 |
### 🏗️ 架构(工作原理)
| 文档 | 描述 |
| -------------------------------------------- | ------------------------------------- |
| [概述](docs/architecture/overview.md) | 系统设计和组件 |
| [数据流](docs/architecture/data-flow.md) | 文档如何在系统中流动 |
| [Crate 参考](docs/architecture/crates/) | 11 个 Rust crates 解释 |
### 💡 核心概念(理论)
| 概念 | 描述 |
| ------------------------------------------------------- | --------------------------------- |
| [Graph-RAG](docs/concepts/graph-rag.md) | 为什么知识图谱能增强 RAG |
| [实体提取](docs/concepts/entity-extraction.md) | 基于 LLM 的实体识别 |
| [知识图谱](docs/concepts/knowledge-graph.md) | 节点、边和社区 |
| [混合检索](docs/concepts/hybrid-retrieval.md) | 结合向量和图搜索 |
### 深入解析(进阶)
| 文章 | 描述 |
| --------------------------------------------------------------- | -------------------------------------------- |
| [LightRAG 算法](docs/deep-dives/lightrag-algorithm.md) | 核心算法:提取、图、检索 |
| [查询模式](docs/deep-dives/query-modes.md) | 6 种模式及其权衡解释 |
| [实体归一化](docs/deep-dives/entity-normalization.md) | 去重和描述合并 |
| [Gleaning](docs/deep-dives/gleaning.md) | 多轮提取以保证完整性 |
| [社区发现](docs/deep-dives/community-detection.md) | 用于全局查询的 Louvain 聚类 |
| [分块策略](docs/deep-dives/chunking-strategies.md) | 带重叠的基于 Token 的分割 |
| [嵌入模型](docs/deep-dives/embedding-models.md) | 模型选择和维度权衡 |
| [图存储](docs/deep-dives/graph-storage.md) | Apache AGE 属性图后端 |
| [向量存储](docs/deep-dives/vector-storage.md) | pgvector HNSW 索引和搜索 |
| [PDF 处理](docs/deep-dives/pdf-processing.md) | 文本/视觉/混合提取管道 |
| [成本追踪](docs/deep-dives/cost-tracking.md) | 每次操作的 LLM 成本监控 |
| [管道进度](docs/deep-dives/pipeline-progress.md) | 时进度跟踪 |
### 📊 对比
| 对比 | 关键洞察 |
| -------------------------------------------------------------- | ---------------------------------- |
| [对比 LightRAG (Python)](docs/comparisons/vs-lightrag-python.md) | 性能和设计差异 |
| [对比 GraphRAG](docs/comparisons/vs-graphrag.md) | Microsoft 方案对比 |
| [对比传统 RAG](docs/comparisons/vs-traditional-rag.md) | 为什么图很重要 |
### API 参考
| API | 描述 |
| -------------------------------------------------- | --------------------- |
| [REST API](docs/api-reference/rest-api.md) | HTTP 端点 |
| [扩展 API](docs/api-reference/extended-api.md) | 高级 API 功能 |
### 运维(生产)
| 指南 | 描述 |
| ----------------------------------------------------------- | --------------------- |
| [部署](docs/operations/deployment.md) | 生产环境部署 |
| [配置](docs/operations/configuration.md) | 所有配置选项 |
| [监控](docs/operations/monitoring.md) | 可观测性设置 |
| [性能调优](docs/operations/performance-tuning.md) | 优化指南 |
### 🐛 故障排除
| 指南 | 描述 |
| -------------------------------------------------------- | ---------------------------- |
| [常见问题](docs/troubleshooting/common-issues.md) | 调试指南 |
| [PDF 提取](docs/troubleshooting/pdf-extraction.md) | PDF 特定故障排除 |
### 🔗 集成
| 集成 | 描述 |
| ----------------------------------------------------- | ------------------------------------ |
| [MCP 服务器](mcp/) | AI Agent 的模型上下文协议 |
| [OpenWebUI](docs/integrations/open-webui.md) | 带 Ollama 仿真的聊天界面 |
| [LangChain](docs/integrations/langchain.md) | Retriever 和 Agent 集成 |
| [自定义客户端](docs/integrations/custom-clients.md) | Python、TypeScript、Rust、Go 客户端 |
### 📓 更多资源
- [FAQ](docs/faq.md) - 常见问题
- [Cookbook](docs/cookbook.md) - 实用配方
- [安全](docs/security/) - 安全最佳实践
## 开发
### 构建和测试
```
# 构建 Backend
cd edgequake && cargo build --release
# 运行测试
cargo test
# Lint 和格式化
cargo clippy
cargo fmt
# 构建 Frontend
cd edgequake_webui
bun run build
```
### Make 命令
EdgeQuake 使用统一的 Makefile 处理所有开发任务:
```
# 完整开发 Stack
make dev # Start all services (PostgreSQL + Backend + Frontend)
make dev-bg # Start in background (for agents/automation)
make dev-memory # Start with in-memory storage (testing only)
make stop # Stop all services
make status # Check service status
# 仅 Backend
make backend-dev # Run backend with PostgreSQL
make backend-memory # Run backend with in-memory storage
make backend-bg # Run backend in background
make backend-test # Run backend tests
# 仅 Frontend
make frontend-dev # Start frontend dev server
make frontend-build # Build frontend for production
# 数据库
make db-start # Start PostgreSQL container
make db-stop # Stop PostgreSQL container
make db-wait # Wait for database to be ready
# 质量检查
make test # Run all tests
make lint # Lint all code
make format # Format all code
make clean # Clean build artifacts
```
### Agent 工作流
EdgeQuake 开发遵循使用 `edgecode` SOTA 编码 Agent 的**规范驱动开发**方法。
- **AGENTS.md**:全面的 Agent 指南和工作流
- **specs/**:所有开发规范
- **OODA 循环**:迭代开发周期(观察、定向、决策、行动)
详细的 Agent 工作流文档请参阅 [AGENTS.md](AGENTS.md)。
## 贡献
EdgeQuake 使用由 **Raphaël MANSUY** 创建的 **edgecode** SOTA 编码 Agent 进行开发。该项目遵循**规范驱动开发**方法,所有更改在实现之前都在 `specs/` 目录中指定。
**当前状态**:`edgecode` 尚未公开,但将很快发布。
**目前,贡献应直接通过 Raphaël MANSUY 进行:**
- **GitHub Issues**:报告错误和请求功能
- **GitHub Discussions**:提问和分享想法
- **直接联系**:对于重大贡献,请联系 [@raphaelmansuy](https://github.com/raphaelmansuy)
详细的贡献指南请参阅 [CONTRIBUTING.md](CONTRIBUTING.md)。
## 社区与支持
### 行为准则
我们致力于提供热情和包容的环境。请阅读我们的[行为准则](CODE_OF_CONDUCT.md)。
### 支持渠道
- **GitHub Issues**:错误报告和功能请求
- **GitHub Discussions**:问题和社区帮助
- **LinkedIn**:[@raphaelmansuy](https://www.linkedin.com/in/raphaelmansuy)
- **Twitter/X**:[@raphaelmansuy](https://twitter.com/raphaelmansuy)
### 创始人
**Raphaël MANSUY** 🇫🇷 - 🇭🇰🇨🇳 — 香港永久居民,构建智能文档检索系统和上下文图系统的未来。
## 许可证
根据 Apache License, Version 2.0(“许可证”)授权。
您可以在以下位置获取许可证副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则根据许可证分发的软件是按“原样”分发的,没有任何形式的明示或暗示的保证。请参阅 [LICENSE](LICENSE) 文件以了解管理权限和限制的具体语言。
**Copyright © 2024-2026 Raphaël MANSUY**
## 致谢
EdgeQuake 的灵感来源于并构建于以下优秀工作之上:
- **LightRAG 研究论文** ([arxiv.org/abs/2410.05779](https://arxiv.org/abs/2410.05779)):我们感谢基础 LightRAG 算法的作者,该算法为 EdgeQuake 中的核心知识图谱提取和检索能力提供了支持。他们在实体提取、关系映射和混合检索方面的创新方法对我们框架的设计起到了重要作用。
**特别感谢 LightRAG 作者:**
- [Zirui Guo](https://arxiv.org/search/cs?searchtype=author&query=Guo,+Z)
- [Lianghao Xia](https://arxiv.org/search/cs?searchtype=author&query=Xia,+L)
- [Yanhua Yu](https://arxiv.org/search/cs?searchtype=author&query=Yu,+Y)
- [Tu Ao](https://arxiv.org/search/cs?searchtype=author&query=Ao,+T)
- [Chao Huang](https://arxiv.org/search/cs?searchtype=author&query=Huang,+C)
- **GraphRAG** ([arxiv.org/abs/2404.16130](https://arxiv.org/abs/2404.16130)):Microsoft 的“从局部到全局”知识图谱方法,用于聚焦查询的摘要。
- [Shuai Wang](https://www.microsoft.com/en-us/research/people/shuaiw/)
- [Yingqiang Ge](https://www.microsoft.com/en-us/research/people/yinge/)
- [Ying Shen](https://www.microsoft.com/en-us/research/people/yingshen/)
- [Jianfeng Gao](https://www.microsoft.com/en-us/research/people/jfgao/)
- [Xiaodong Liu](https://www.microsoft.com/en-us/research/people/xiaodl/)
- [Yelong Shen](https://www.microsoft.com/en-us/research/people/yelongshen/)
- [Jianfeng Wang](https://www.microsoft.com/en-us/research/people/jianfw/)
- [Ming Zhou](https://www.microsoft.com/en-us/research/people/zhou/)
- **Rust 社区**:感谢 amazing 的异步生态系统(Tokio、Axum、SQLx),使 EdgeQuake 的高性能成为可能
- **React 社区**:感谢 React 19 和现代前端技术栈,为我们的交互式 UI 提供动力
## 快速链接
| 资源 | URL |
| --------------------- | -------------------------------------------------------------------------------- |
| 📚 完整文档 | [docs/README.md](docs/README.md) |
| 🚀 快速开始指南 | [docs/getting-started/quick-start.md](docs/getting-started/quick-start.md) |
| 📦 SDK 概述 | [sdks/](sdks/) |
| 🐍 Python SDK | [sdks/python/README.md](sdks/python/README.md) |
| 🦀 Rust SDK | [sdks/rust/README.md](sdks/rust/README.md) |
| 🟦 TypeScript SDK | [sdks/typescript/README.md](sdks/typescript/README.md) |
| 📜 更新日志 | [CHANGELOG.md](CHANGELOG.md) |
| 🔧 Agent 工作流 | [AGENTS.md](AGENTS.md) |
| 🤝 贡献 | [CONTRIBUTING.md](CONTRIBUTING.md) |
| 📜 行为准则 | [CODE_OF_CONDUCT.md](CODE_OF_CONDUCT.md) |
| 📄 许可证 | [LICENSE](LICENSE) |
| 🐛 报告问题 | [GitHub Issues](https://github.com/raphaelmansuy/edgequake/issues) |
| 💬 讨论 | [GitHub Discussions](https://github.com/raphaelmansuy/edgequake/discussions) |
| 🌐 仓库 | [github.com/raphaelmansuy/edgequake](https://github.com/raphaelmansuy/edgequake) |
**准备好构建智能文档检索了吗?**[立即开始!](docs/getting-started/quick-start.md)
## Star 历史
[](https://www.star-history.com/#raphaelmansuy/edgequake&type=date&legend=top-left)
标签:Claude, CVE检测, DNS解析, Gemini, GPT-4o, GraphRAG, LightRAG, PDF解析, RAG引擎, Rust, Tokio, 人工智能, 可视化界面, 向量搜索, 多模态处理, 多跳推理, 实体关系抽取, 开源项目, 异步编程, 文档理解, 检索增强生成, 测试用例, 用户模式Hook绕过, 网络流量审计, 语义检索, 通知系统, 通知系统, 高性能计算