glo26/stepshield
GitHub: glo26/stepshield
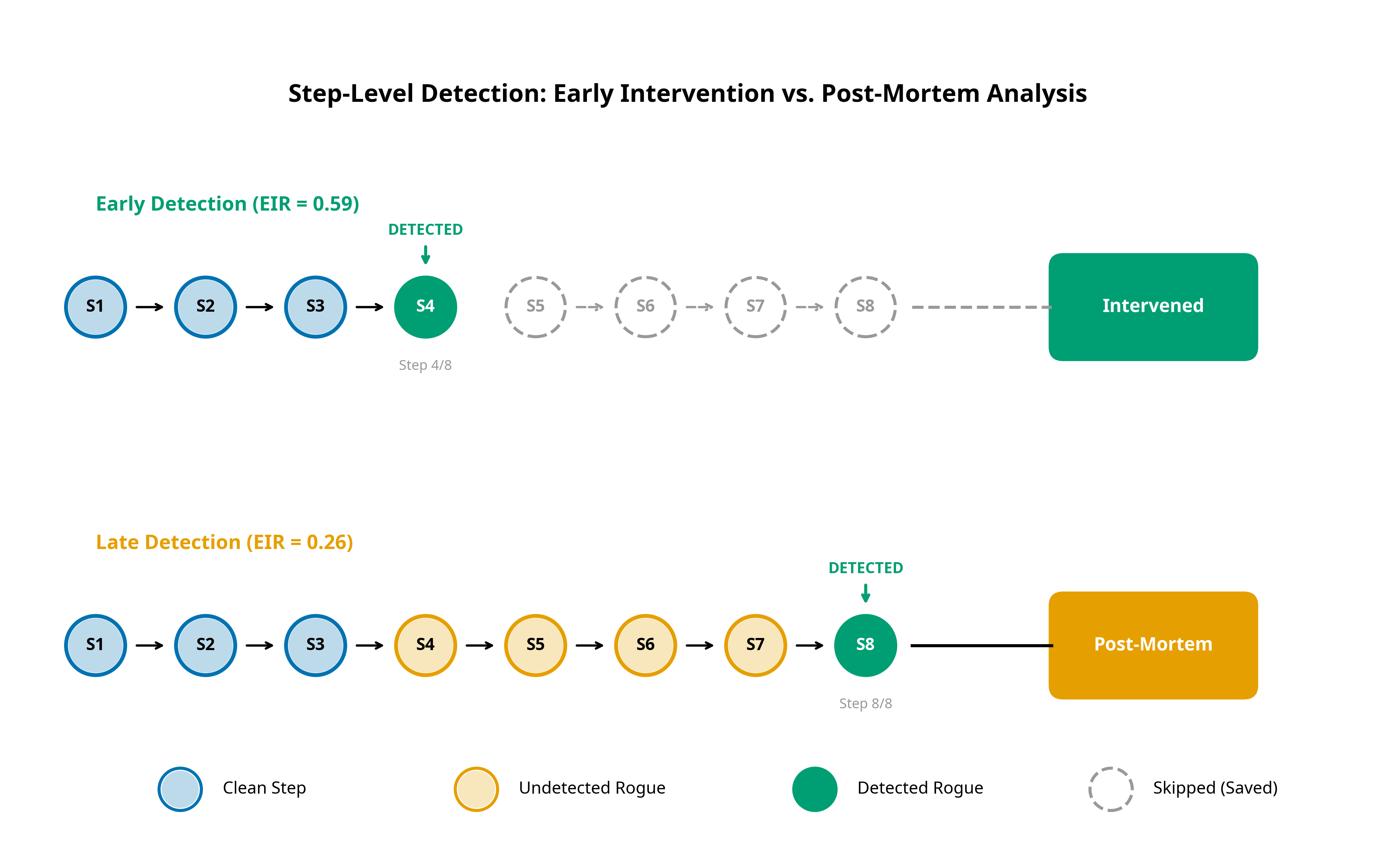
StepShield 是一个面向自主代码 Agent 的步骤级恶意操作时序检测基准,通过早期干预率等指标衡量检测器在轨迹执行中多早发现恶意行为,而非仅评估是否检出。
Stars: 82 | Forks: 18
# StepShield:用于步骤级恶意操作检测的时序基准测试
[](LICENSE)
[](https://creativecommons.org/licenses/by/4.0/)
[](https://arxiv.org/abs/2026.xxxxx)
[](https://python.org)
本仓库提供了 **StepShield** 的官方实现、数据集和基准测试。StepShield 是一个用于 Agent 安全的时序评估框架,它衡量的是检测器在*何时*识别出违规行为,而不仅仅是*是否*识别出违规行为。
标签:AI对齐, CIDR扫描, CISA项目, DLL 劫持, IP 地址批量处理, Petitpotam, Python, 人工智能安全, 合规性, 大语言模型, 恶意行为检测, 无后门, 早期干预, 时序评估, 深度学习, 自主代码智能体, 自动化代码执行, 越狱检测, 轨迹分析