shaswata09/falcon
GitHub: shaswata09/falcon
FALCON 是一个利用大语言模型结合自我反思与多验证器反馈循环,将网络威胁情报报告自动转化为可部署 Snort/YARA 入侵检测规则的自动化框架。
Stars: 3 | Forks: 1
# FALCON:通过自我反思将网络威胁情报转化为可部署的 IDS 规则
[](https://arxiv.org/abs/2508.18684)
[](https://creativecommons.org/licenses/by-nc-nd/4.0/)
[](https://www.python.org/downloads/)
FALCON 是一个自动化框架,可将**网络威胁情报 (CTI)** 报告转化为可部署的 **Snort** 和 **YARA** 入侵检测规则。它使用由**自我反思、多验证器反馈循环**引导的大型语言模型 (LLM) ——在推理时无需人工干预。经过微调的 **CTI-Rule 双编码器**提供了闭合该循环的语义相似性信号。
## 目录
- [概述](#overview)
- [架构](#architecture)
- [LLM 列表](#llm-roster)
- [项目结构](#project-structure)
- [设置](#setup)
- [运行实验](#running-experiments)
- [评估流水线](#evaluation-pipeline)
- [结果](#results)
- [引用](#citation)
- [许可证](#license)
## 概述
给定一份 CTI 描述,FALCON 会:
1. 通过 vLLM 提供的 LLM **生成**候选的 IDS 规则(Snort 或 YARA)。
2. 通过一个三阶段流水线——**语法 → 语义 → 性能**——对规则进行**验证**,并采用短路排序。
3. **自我反思**:如果失败,验证器的反馈将被附加到对话历史记录中,LLM 会生成修正后的规则。这个**链式验证器循环**将不断重复,直到规则通过所有三个验证器的验证或重试次数用尽。
4. **评估**最终规则,包括根据输入的 CTI(面向部署场景)和留出的真实规则(离线评分)进行评估。
该框架在 22 个 LLM、两种规则系列以及可选的思考模式切换下,对比了**单次生成**(一次 LLM 调用,无反馈)与**链式验证器**生成(迭代优化)。
## 架构
```
CTI Report
│
▼
┌──────────────────────────────────────────────────────┐
│ LLM (vLLM-served) │
│ System prompt + one-shot example + CTI → rule │
└──────────────┬───────────────────────────────────────┘
│
▼
┌─── Syntactic Validator ───┐
│ Snort parser / YARA │
│ yara-python compile │
└────────┬──────────────────┘
│ pass?
▼
┌─── Semantic Validator ────┐
│ CTI-Rule bi-encoder │
│ (fine-tuned all-mpnet) │
│ cosine sim ≥ threshold │
└────────┬──────────────────┘
│ pass?
▼
┌─── Performance Validator ─┐
│ Rule-quality scoring │
│ (specificity, coverage, │
│ false-positive risk) │
└────────┬──────────────────┘
│
all passed? ──yes──▶ Final Rule
│
no
│
▼
Feedback appended to
conversation history
│
▼
LLM re-generates
(up to 15 retries)
```
## LLM 列表
所有模型均通过 **vLLM** 提供服务,并使用兼容 OpenAI 的 endpoint。该列表定义于 [`script/run_experiment/llm_registry.json`](script/run_experiment/llm_registry.json)。
| 区间 | 模型 | 供应商 | 参数量 | 网络安全微调 | 思考模式 | 工具调用 |
|--------|-------|--------|--------|:-----------:|:--------:|:---------:|
| **<8B** | Llama-3.2-3B-Instruct | Meta | 3.2B | | | ✅ |
| | Phi-4-mini-instruct | Microsoft | 3.8B | | | ✅ |
| | Qwen3-4B | Qwen | 4.0B | | ✅ | ✅ |
| | Gemma-3-4B-it | Google | 4.3B | | | ✅ |
| | Foundation-Sec-8B-Instruct | Foundation AI | 8.0B | ✅ | | |
| | Lily-Cybersecurity-7B-v0.2 | Sego Lily Labs | 7.0B | ✅ | | |
| | SecGPT | Clouditera | 7.0B | ✅ | | |
| | Llama-Primus-Base | Trend Micro | 8.0B | ✅ | | |
| | Granite-4.1-3B | IBM | 3.0B | | | ✅ |
| **8–30B** | Llama-3.1-8B-Instruct | Meta | 8.0B | | | ✅ |
| | Qwen3-14B | Qwen | 14.0B | | ✅ | ✅ |
| | Mistral-Small-3.2-24B | Mistral | 24.0B | | | ✅ |
| | Nemotron-3-Nano-30B-A3B | NVIDIA | 30B/3B | | ✅ | ✅ |
| | Granite-4.1-8B | IBM | 8.0B | | | ✅ |
| | Granite-4.1-30B | IBM | 30.0B | | | ✅ |
| **30–120B** | Qwen3-32B | Qwen | 32.0B | | ✅ | ✅ |
| | Nemotron-Super-49B | NVIDIA | 49.0B | | ✅ | ✅ |
| | Llama-4-Scout-17B-16E | Meta | 109B/17B | | | ✅ |
| | GLM-4.5-Air | Z.ai | 106B/12B | | ✅ | ✅ |
| **120–400B** | GPT-OSS-120B | OpenAI | 117B/5.1B | | ✅ | ✅ |
| | Qwen3-235B-A22B | Qwen | 235B/22B | | ✅ | ✅ |
| | Nemotron-Ultra-253B | NVIDIA | 253B | | ✅ | ✅ |
| | Mistral-Medium-3.5-128B | Mistral | 128B | | | ✅ |
**网络安全微调模型**仅在 `single_shot` + `chain_validator` 模式下运行(无原生工具调用)。
**思考切换模型**会在 `thinking_on` 和 `thinking_off` 状态下分别进行评估。
## 项目结构
```
falcon/
├── src/ # Core library
│ ├── pipeline/ # Rule extraction / post-processing
│ │ └── parser_vllm.py # Qwen3-32B-based rule extractor for cybersec LLMs
│ ├── validator/
│ │ ├── syntactic/ # Snort parser + YARA yara-python compile check
│ │ ├── semantic/ # Fine-tuned CTI-Rule bi-encoder similarity scorer
│ │ ├── performance/ # Rule quality / specificity / FP-risk scorer
│ │ └── operational/ # Operational testing (PCAP replay, etc.)
│ ├── models/cybersec/ # Cybersec model definitions
│ ├── data_io/loaders/ # Dataset loaders
│ └── hypotheses/ # Hypothesis testing utilities
│
├── script/ # Experiment scripts & notebooks
│ ├── run_experiment/ # End-to-end experiment runners
│ │ ├── llm_registry.json # Central LLM roster (22 models)
│ │ ├── _lib/ # Shared experiment library
│ │ │ ├── modes.py # single_shot, chain_validator pipelines
│ │ │ ├── validators.py # ValidatorBundle (syntax → semantic → perf)
│ │ │ ├── vllm_client.py # vLLM discovery + thinking-toggle translation
│ │ │ ├── registry.py # LLM registry loader
│ │ │ └── encoder.py # Fine-tuned CTI-Rule bi-encoder loader
│ │ ├── snort/ # Per-model Snort experiment notebooks
│ │ ├── yara/ # Per-model YARA experiment notebooks
│ │ └── test_vllm_parser.py # Parser integration tests
│ ├── fine_tuning/ # Encoder fine-tuning
│ │ ├── bi-encoder/ # Bi-encoder (all-mpnet, MiniLM, e5) sweeps
│ │ └── dual-encoder/ # Dual-encoder architecture sweeps
│ ├── dataset/ # Dataset construction notebooks
│ ├── model_prep/ # Model download scripts
│ ├── analysis/ # Hypothesis testing & analysis
│ └── validator/ # Standalone validator demo notebooks
│
├── configs/ # Configuration files
│ ├── datasets/falcon/ # FALCON dataset config
│ ├── models/cybersec/ # Cybersec model configs
│ ├── embeddings/general/ # Embedding model configs (mpnet, MiniLM, e5)
│ └── prompts/{snort,yara}/ # Prompt templates
│
├── data/ # Datasets
│ ├── evaluation/cti-rule/ # (CTI, rule) eval pairs for Snort & YARA
│ ├── generation/ # Ground-truth rules, dummy rules, CTI splits
│ ├── processed/ # Preprocessed dataset splits
│ └── qualitative/ # SME-rated PDFs for qualitative eval
│
├── results/ # Experiment outputs
│ ├── end-to-end_quantitative/ # Per-model e2e notebooks & pickles (Snort + YARA)
│ ├── LLM_cti-rule/ # Generated-rule vs CTI scoring
│ ├── LLM_Rule_GtRule/ # Generated-rule vs ground-truth scoring
│ ├── cti-rule_retriever/ # Retriever (encoder) evaluation
│ ├── mode_model_evaluation/ # Cross-model/mode analysis, figures, CSV/LaTeX
│ ├── qualitative/sme_likert/ # SME Likert-scale evaluation
│ └── operational/pcap_replay/ # Operational PCAP-replay testing
│
├── models/cybersec/ # Downloaded model weights (gitignored)
├── appendix/ # Paper appendix figures (PDF + PNG)
├── ui/ # Dashboard (client + server)
├── start_vllm.sh # vLLM server launcher (GPU-aware, multi-model)
├── gpu_monitor.sh # Real-time GPU utilization monitor
├── config.py # Legacy transformer training config
├── requirements.txt # Python dependencies
└── .env # API keys (gitignored)
```
## 设置
### 前置条件
- **Python 3.12+**
- **支持 CUDA 的 GPU**——整个名单在 6× H200 NVL(每块 141 GB)上进行了评估
- 安装在独立 conda 环境中的 **vLLM**(参见 `start_vllm.sh`)
### 安装说明
```
# 克隆 repository
git clone https://github.com/shaswata09/falcon_private.git
cd falcon
# 安装支持 CUDA 12.8 的 PyTorch(根据你的 GPU 进行调整)
pip install --index-url https://download.pytorch.org/whl/cu128 \
torch==2.11.0 torchvision==0.26.0 torchaudio==2.11.0 xformers==0.0.35
# 安装剩余依赖
pip install -r requirements.txt
```
### 环境变量
创建一个 `.env` 文件(已被 gitignore 忽略),包含以下内容:
```
HF_TOKEN=
UPLOAD_TO_HF=true
```
### 模型下载
```
# 下载 cybersec-specialized LLMs
./script/model_prep/download_cybersec_models.sh
# 或下载特定模型
./script/model_prep/download_cybersec_models.sh --only foundation_sec_8b secgpt
# 从 configs/ 下载所有模型 + embeddings
python -m script.model_prep.download_all
```
## 运行实验
### 1. 启动 vLLM 服务器
`start_vllm.sh` 脚本会从 `llm_registry.json` 读取模型名单,根据模型参数量自动选择张量并行大小,并在遵循 NVLink 拓扑结构的前提下选择空闲的 GPU:
```
# 交互式模型选择器
./start_vllm.sh
# 启动特定模型
./start_vllm.sh qwen3_32b
# 指定 GPU 放置
./start_vllm.sh mistral_small_32_24b --gpus 2,3
# 列出所有已注册的模型
./start_vllm.sh --list
# 检查 GPU 使用情况和正在运行的 vLLM 进程
./start_vllm.sh --status
```
**GPU 分配策略**(针对 6× H200 NVL):
| 模型大小 | 张量并行 | GPU 选择 |
|-----------|:--------------:|---------------|
| ≤ 32B | TP=1 | 优先分配 Island B {2,3},然后是 A |
| 33–120B | TP=2 | NVLink 对:{2,3}, {0,1}, {4,5} |
| > 120B | TP=4 | 完整 Island A: {0,1,4,5} |
### 2. 运行端到端实验
每个模型在 `results/end-to-end_quantitative/{snort,yara}/` 下都有对应的 notebook:
```
# 为特定模型运行 Snort 实验(legacy CLI runner)
python -m script.run_experiment.snort.run_C2 --model foundation_sec_8b --limit 50
# 或打开 per-model notebook
jupyter notebook results/end-to-end_quantitative/snort/qwen3_32b.ipynb
```
**实验模式:**
- **`single_shot`** —— 一次 LLM 调用,无验证器反馈
- **`chain_validator`** —— 带有累积对话历史的迭代优化(最多重试 15 次)
**思考切换模型**会被评估两次:`thinking_on` 和 `thinking_off`。
### 3. 网络安全 LLM 的规则解析器
经过网络安全微调的模型(Foundation-Sec、Lily、SecGPT 等)会在其输出的规则周围生成散文。一个独立的 **Qwen3-32B vLLM** 实例将作为确定性的规则提取器:
```
from src.pipeline.parser_vllm import VllmRuleParser
parser = VllmRuleParser()
result = parser.parse_snort(noisy_llm_output)
print(result.rule) # Clean rule body
```
测试解析器:
```
python -m script.run_experiment.test_vllm_parser
```
## 评估流水线
### 三阶段验证
`ValidatorBundle` 会按顺序运行验证器,并提供可选的短路机制:
| 阶段 | 检查内容 | 通过条件 |
|-------|---------------|----------------|
| **语法** | Snort 语法 / YARA 编译 | 规则解析无误 |
| **语义** | 微调后的双编码器计算出的生成规则与输入 CTI 之间的余弦相似度 | 分数 ≥ F1 最优阈值(Snort: 0.7112, YARA: 0.7107) |
| **性能** | 规则的特异性、覆盖率、误报风险 | 综合得分 ≤ 20 |
### CTI-Rule 双编码器
语义验证器使用了一个**微调后的 `all-mpnet-base-v2`** 双编码器:
- 架构:CLS token 提取 + L2 归一化
- 训练:在带有困难负样本的 (CTI, 规则) 对上进行对比学习
- 选择:在 3 个骨干网络 × 5 次训练中进行 F1 上限排名 → `bi/all-mpnet-base-v2 RUN=4`
- 检查点:`script/fine_tuning/bi-encoder/{snort,yara}/all-mpnet-base-v2/r4_best.pt`
### 下游评分
端到端生成完成后,两条评分流水线将离线运行:
1. **LLM_cti-rule** (`results/LLM_cti-rule/`) —— 生成规则与输入 CTI 的相似度(面向部署场景)
2. **LLM_Rule_GtRule** (`results/LLM_Rule_GtRule/`) —— 生成规则与留出的真实规则的对比(质量基准)
两者均使用 RAGAS 余弦相似度、BERTScore F1 以及 FALCON 双编码器的 sigmoid 分数。
### 跨模型分析
位于 [`results/mode_model_evaluation/mode_model_analysis.ipynb`](results/mode_model_evaluation/mode_model_analysis.ipynb) 的统一分析 notebook 会生成:
- 通过率比较(全部 3 个验证器、仅语法、生成覆盖率)
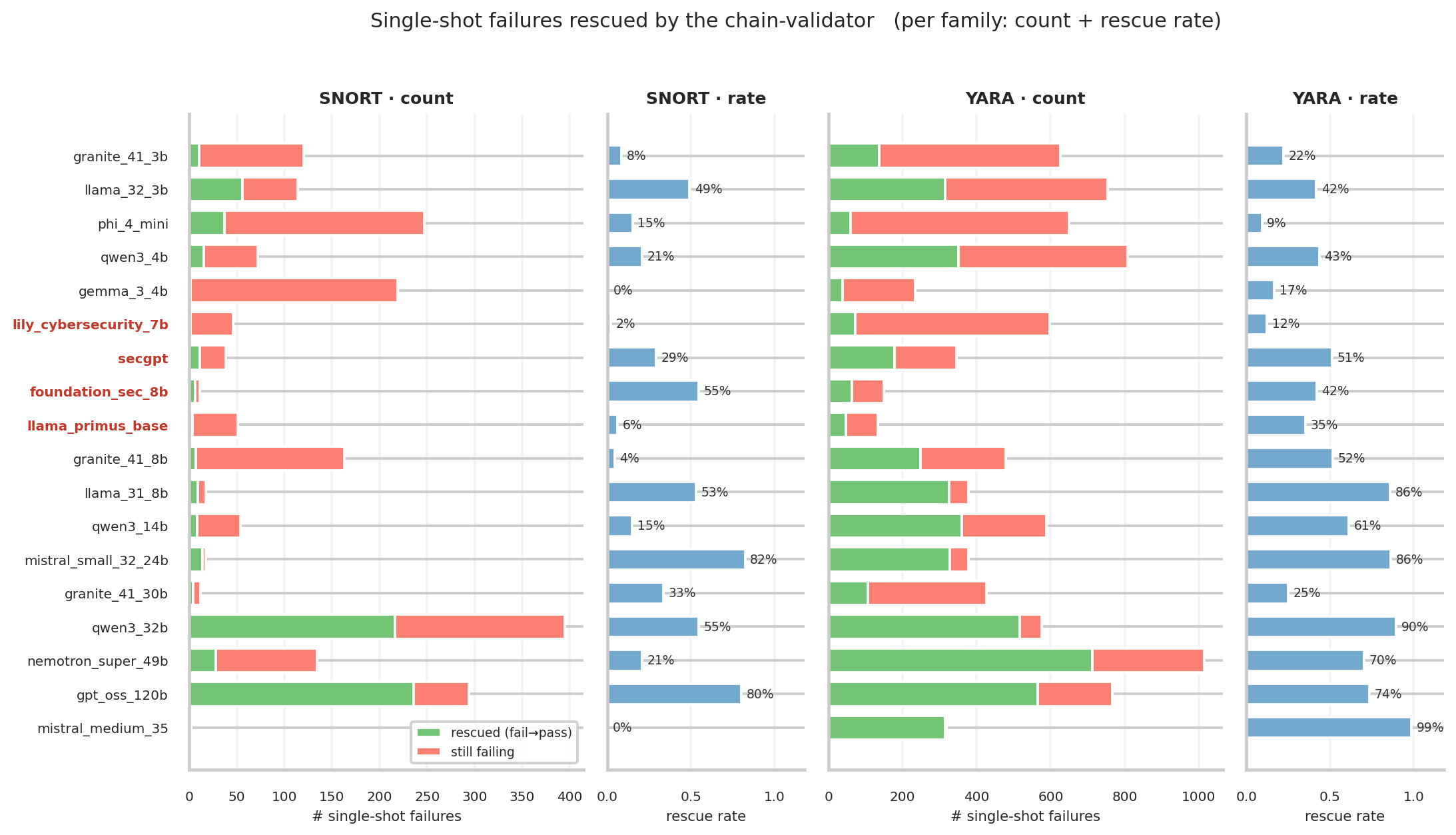
- 链式验证器挽救分析(有多少样本被链式过程“挽救”相较于单次生成)
- 思考模式切换效应分析
- 每个模型的质量热力图(Snort × YARA × 评分指标)
- 综合排名和 LaTeX 表格
## 结果
22 个模型评估的主要发现:
| 指标 | 链式 vs. 单次生成差异 | 开启 vs. 关闭思考差异 |
|--------|:----------------------:|:---------------------:|
| 全部 3 个验证器通过率 | **+13.0 pp** (+18.0%) | −0.05 pp (−0.06%) |
| 语法通过率 | **+12.7 pp** (+17.2%) | +0.58 pp (+0.70%) |
| 生成覆盖率 | +0.22 pp (+0.22%) | −0.94 pp (−0.94%) |
| CTI-Rule 相似度 | −0.04 pp (−0.05%) | −0.08 pp (−0.12%) |
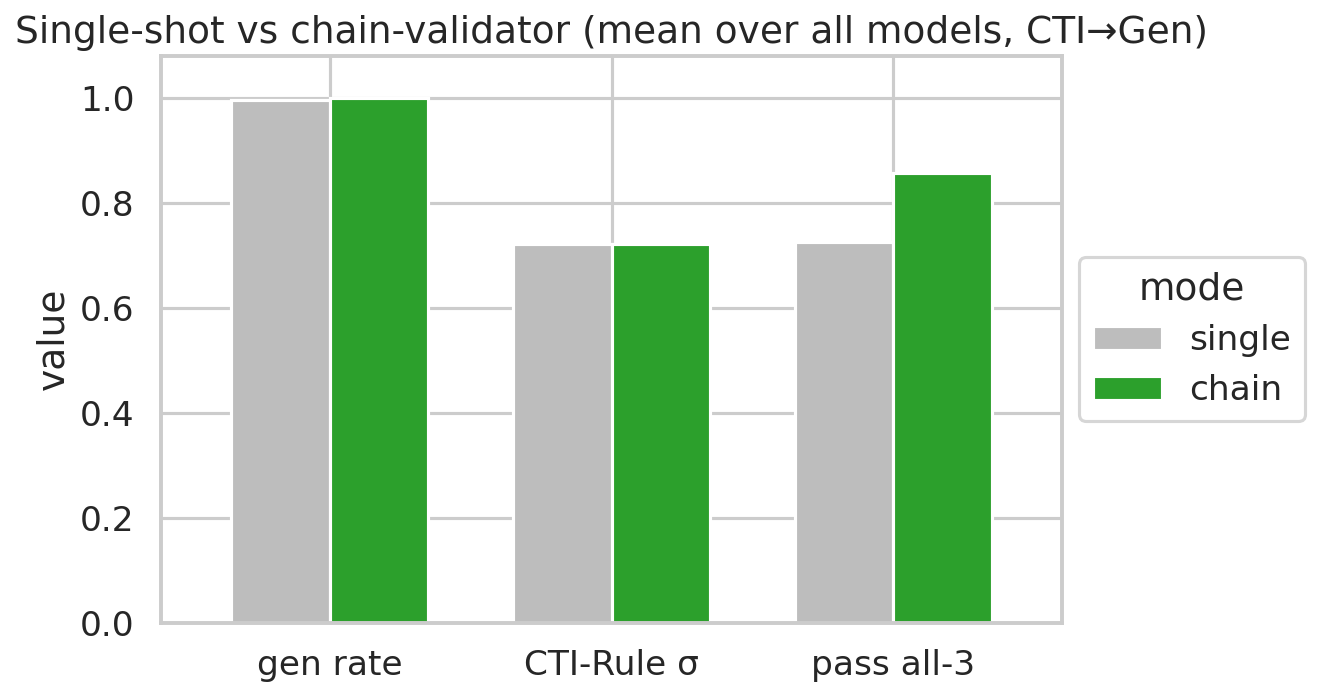
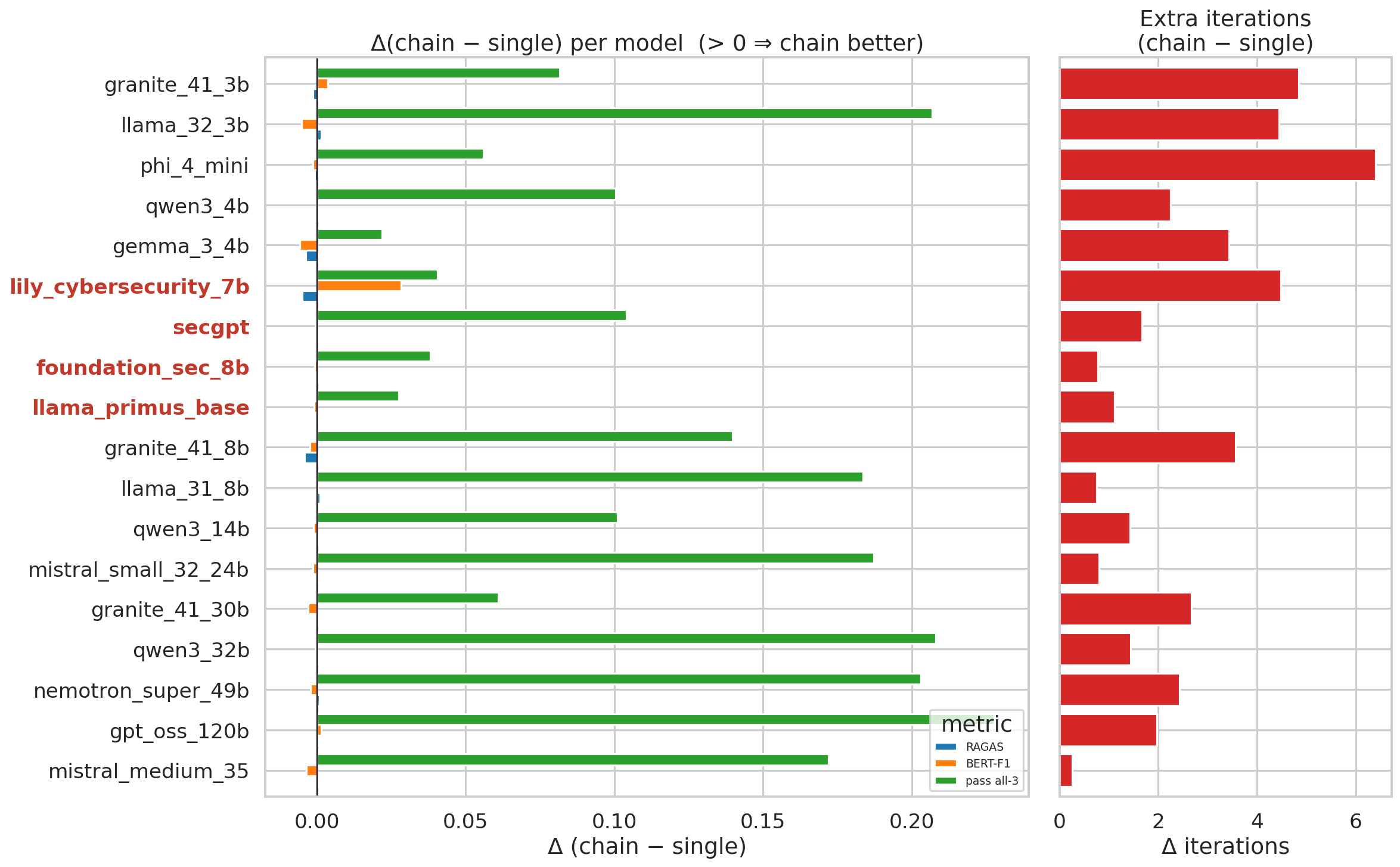
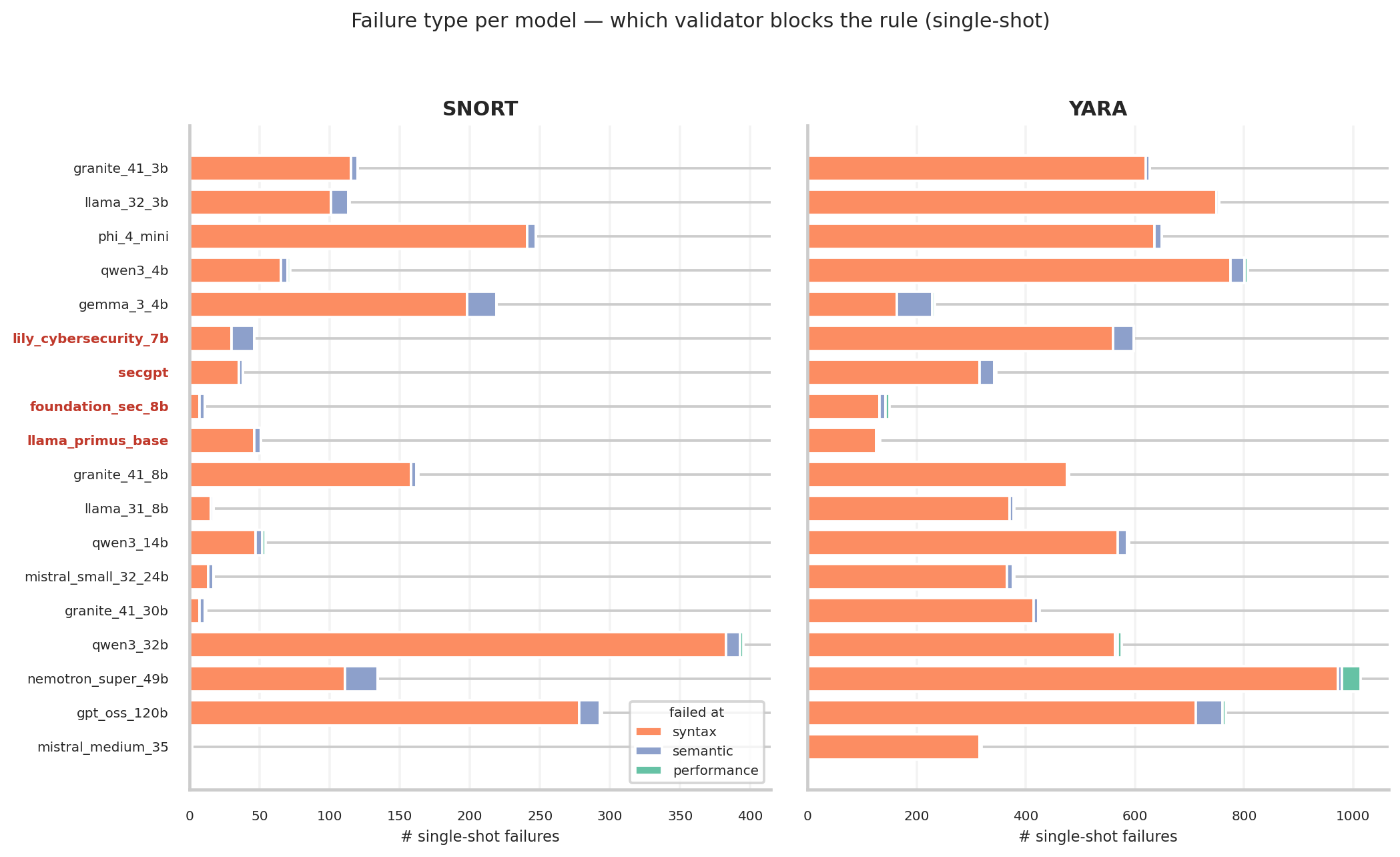
**链式验证器优化持续提升了所有模型和规则类型的语法正确性和总体通过率。思考模式的切换在总体上显示出极小的效果。**
### 附录图表
#### 验证器通过率
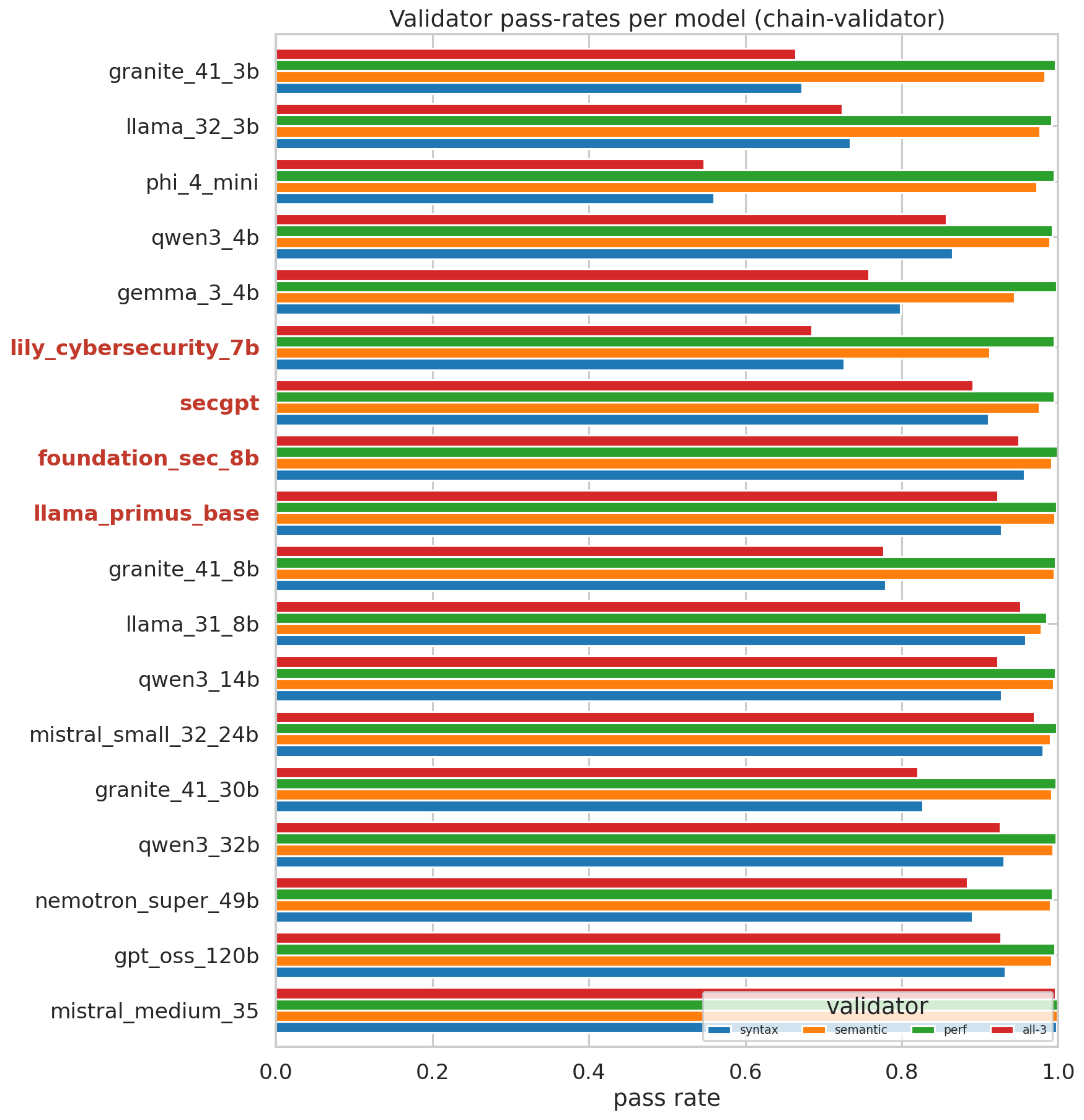
#### 链式验证器 vs. 单次生成
#### 链式 vs. 单次生成 —— 各模型对比
#### 链式验证器挽救分析
#### 链式挽救 —— 哑铃图
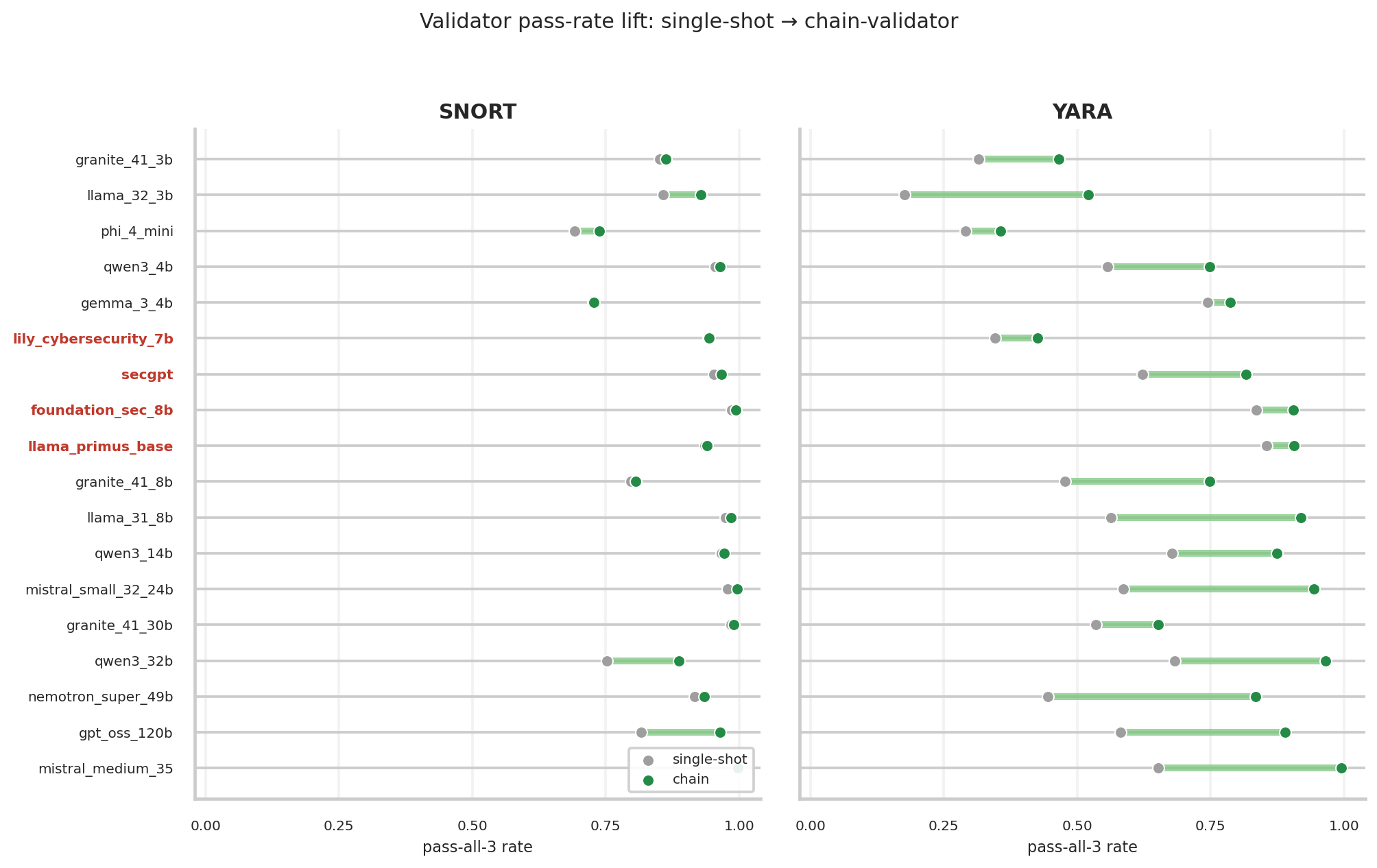
#### 思考切换效应
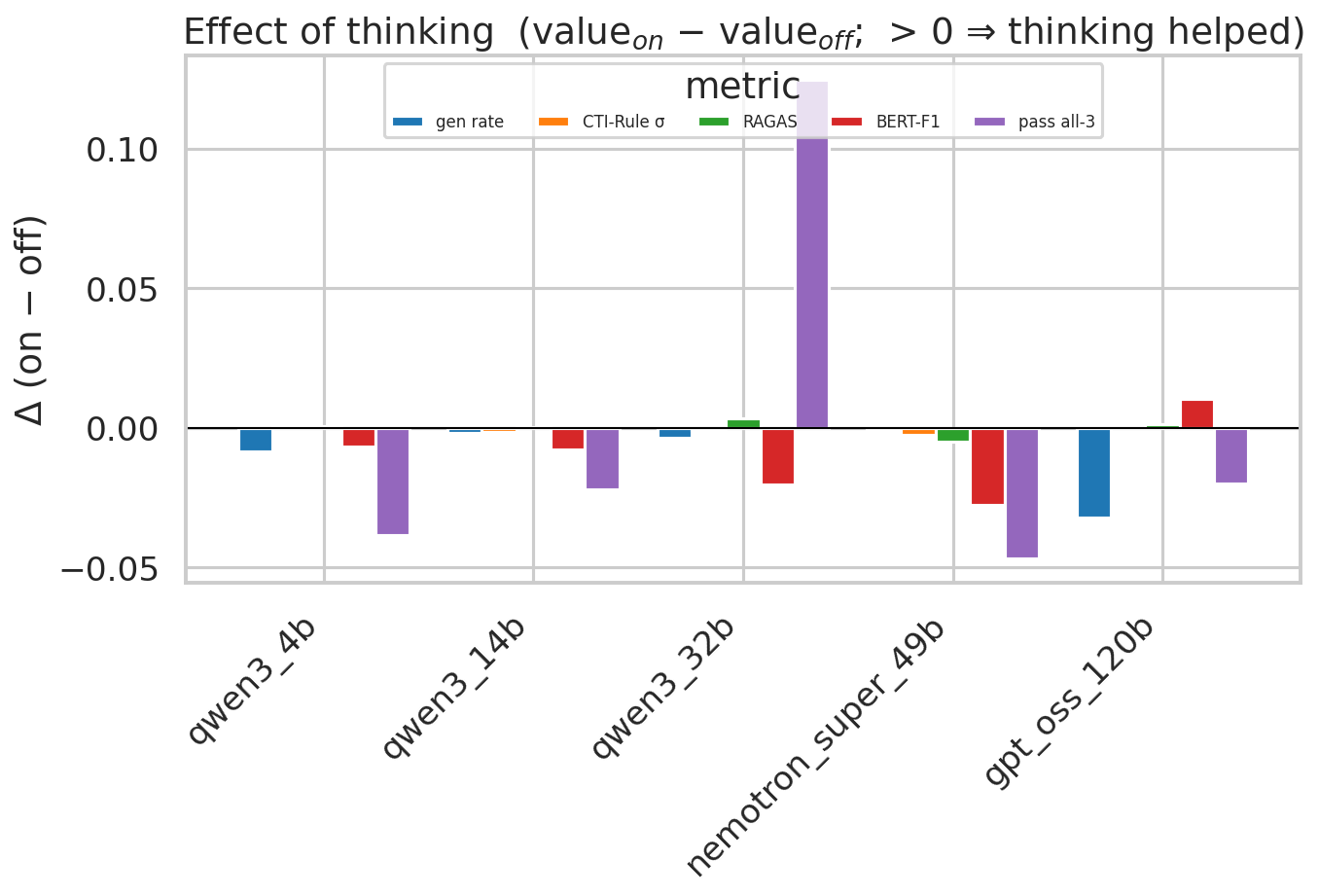
#### 综合质量热力图
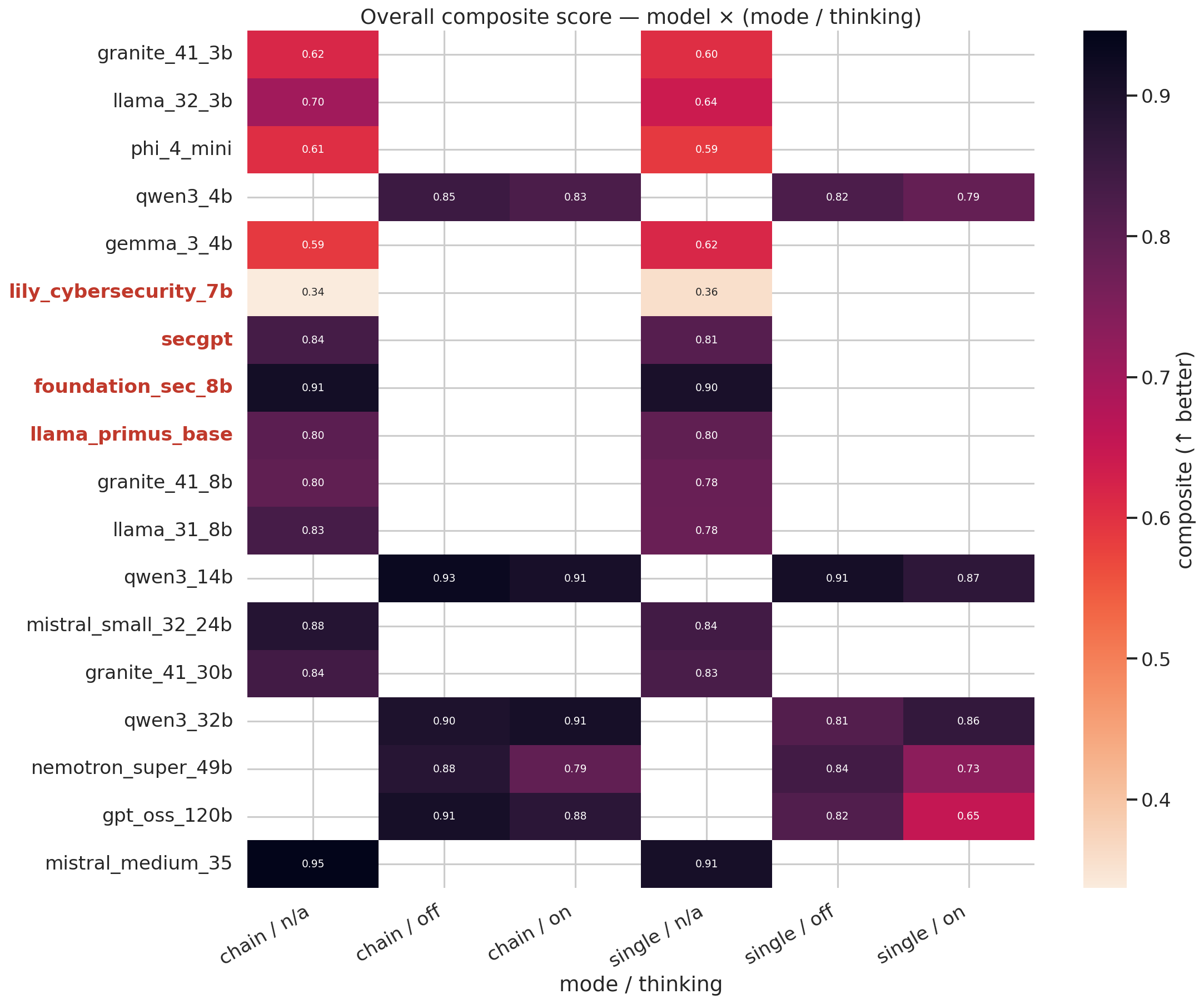
#### 验证器失败分析
#### CTI-Rule 质量 —— FALCON 双编码器得分
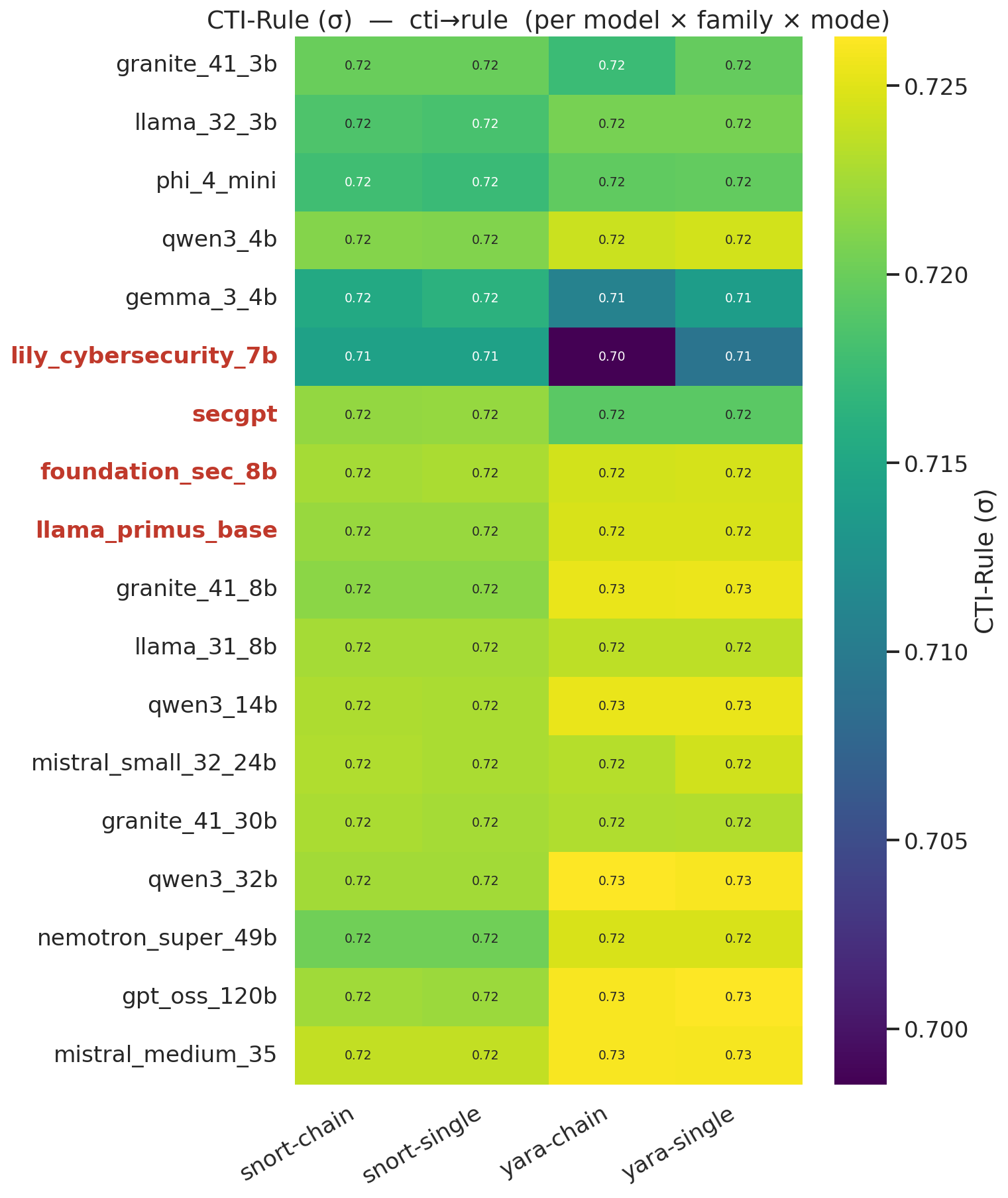
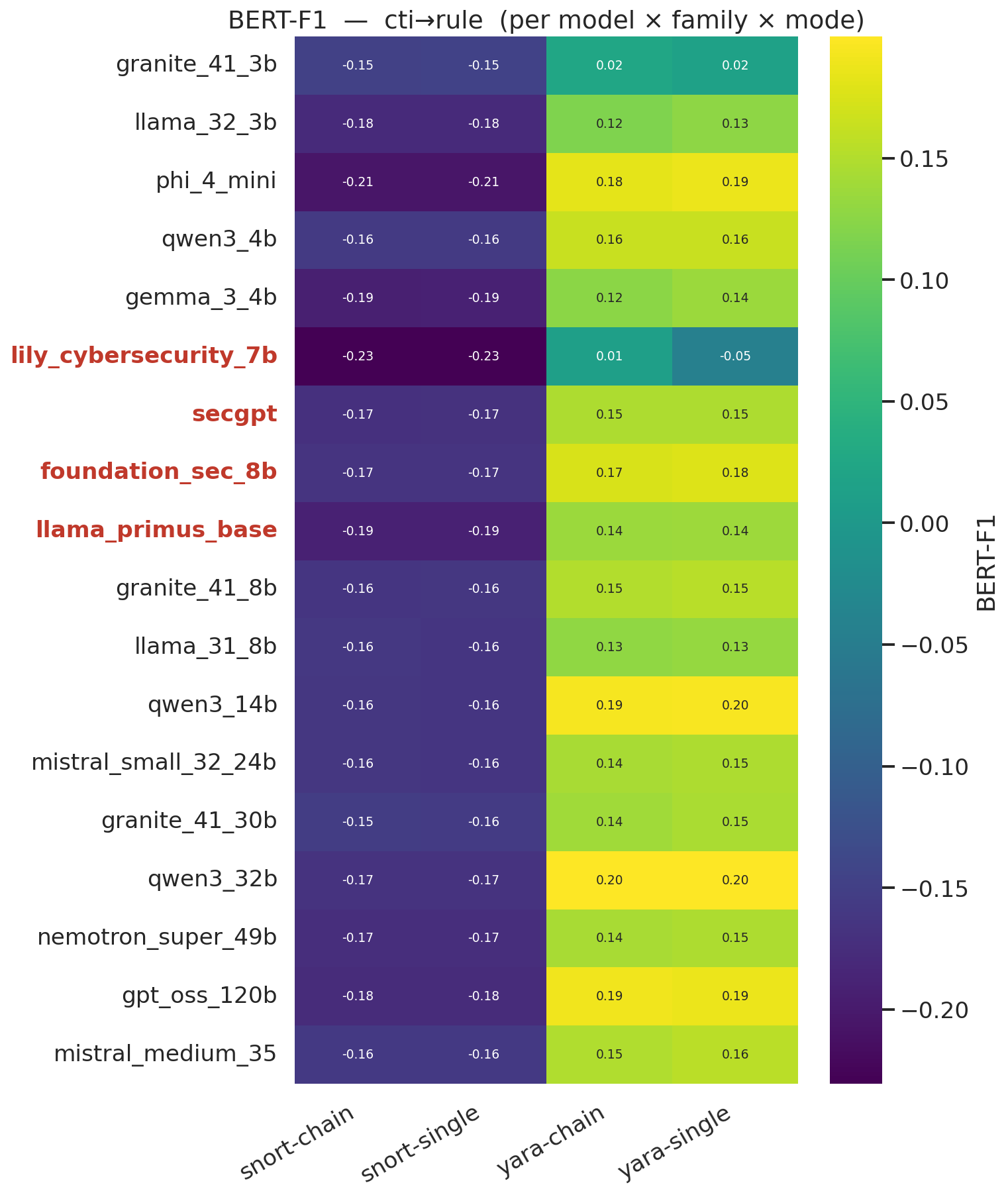
#### CTI-Rule 质量 —— BERTScore F1
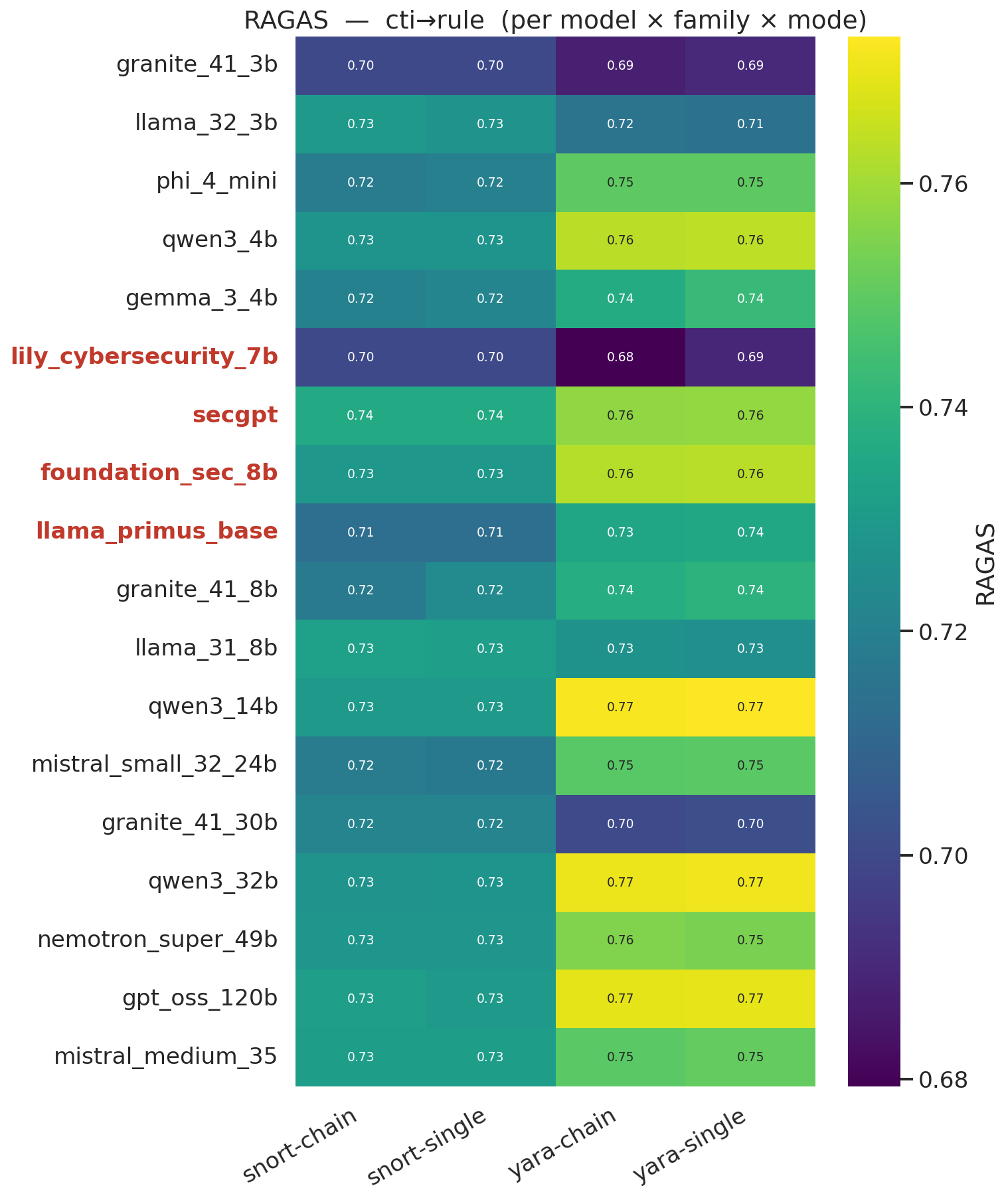
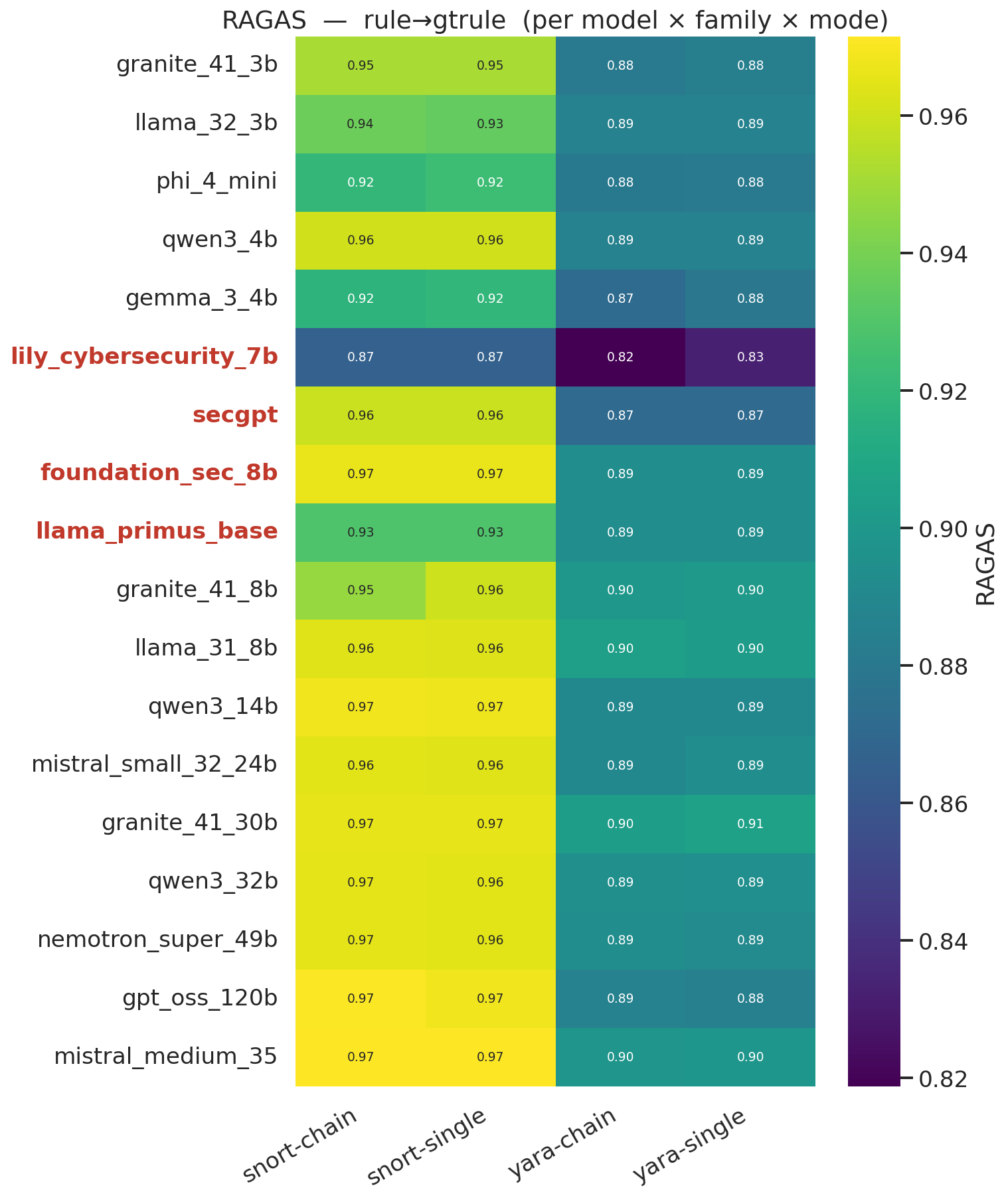
#### CTI-Rule 质量 —— RAGAS 余弦相似度
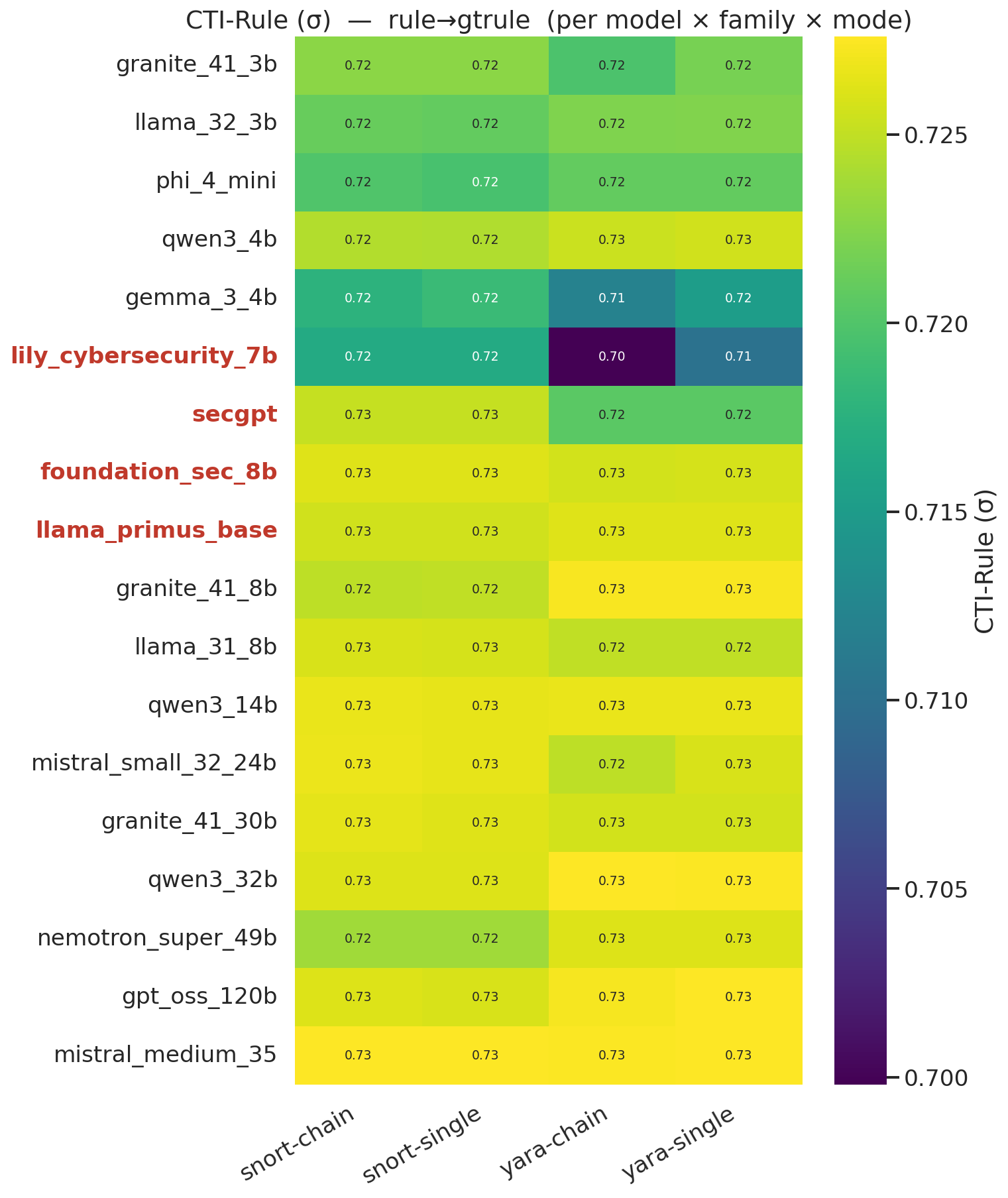
#### 规则 vs. 真实规则 —— FALCON 双编码器
#### 规则 vs. 真实规则 —— BERTScore F1
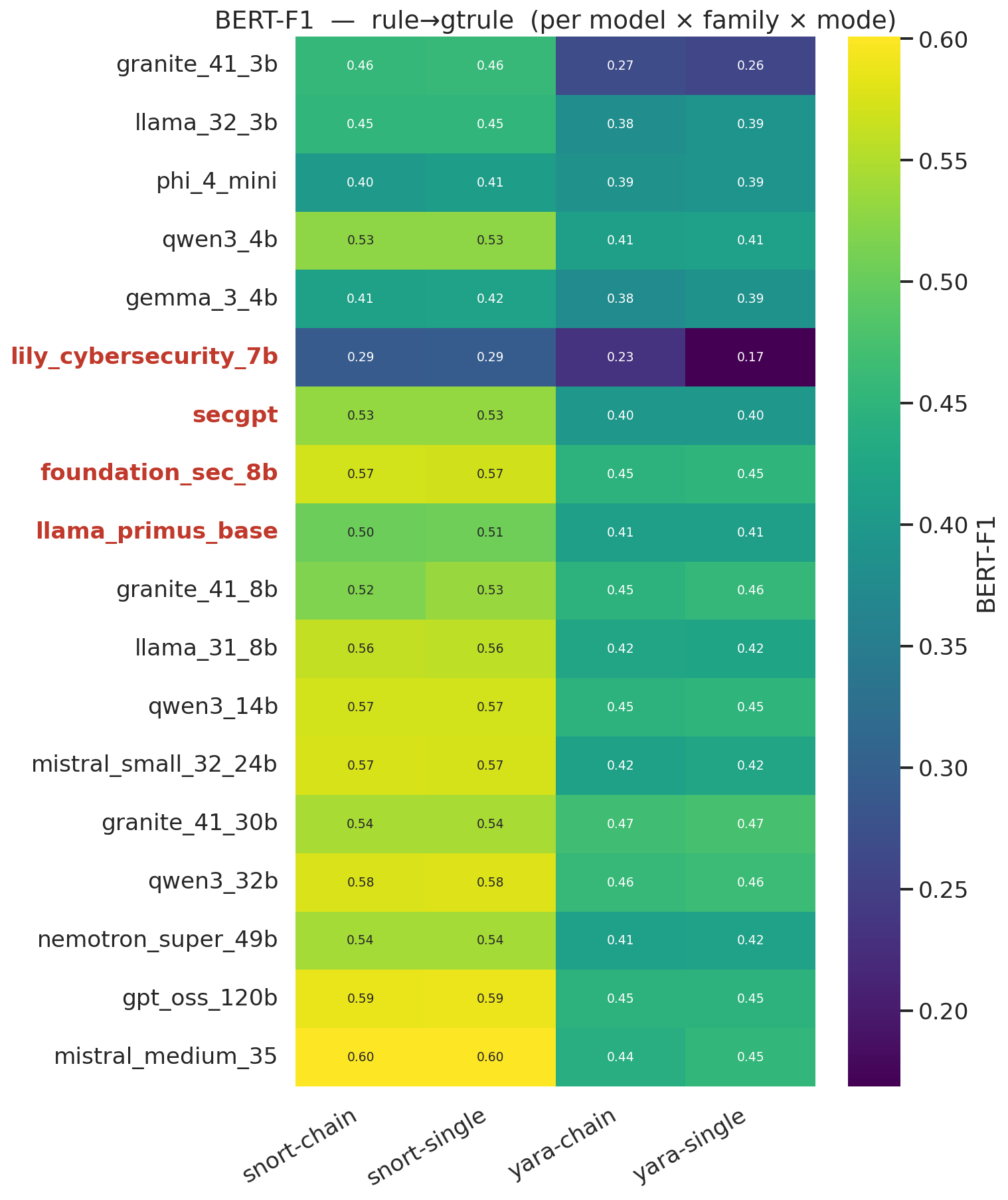
#### 规则 vs. 真实规则 —— RAGAS 余弦相似度
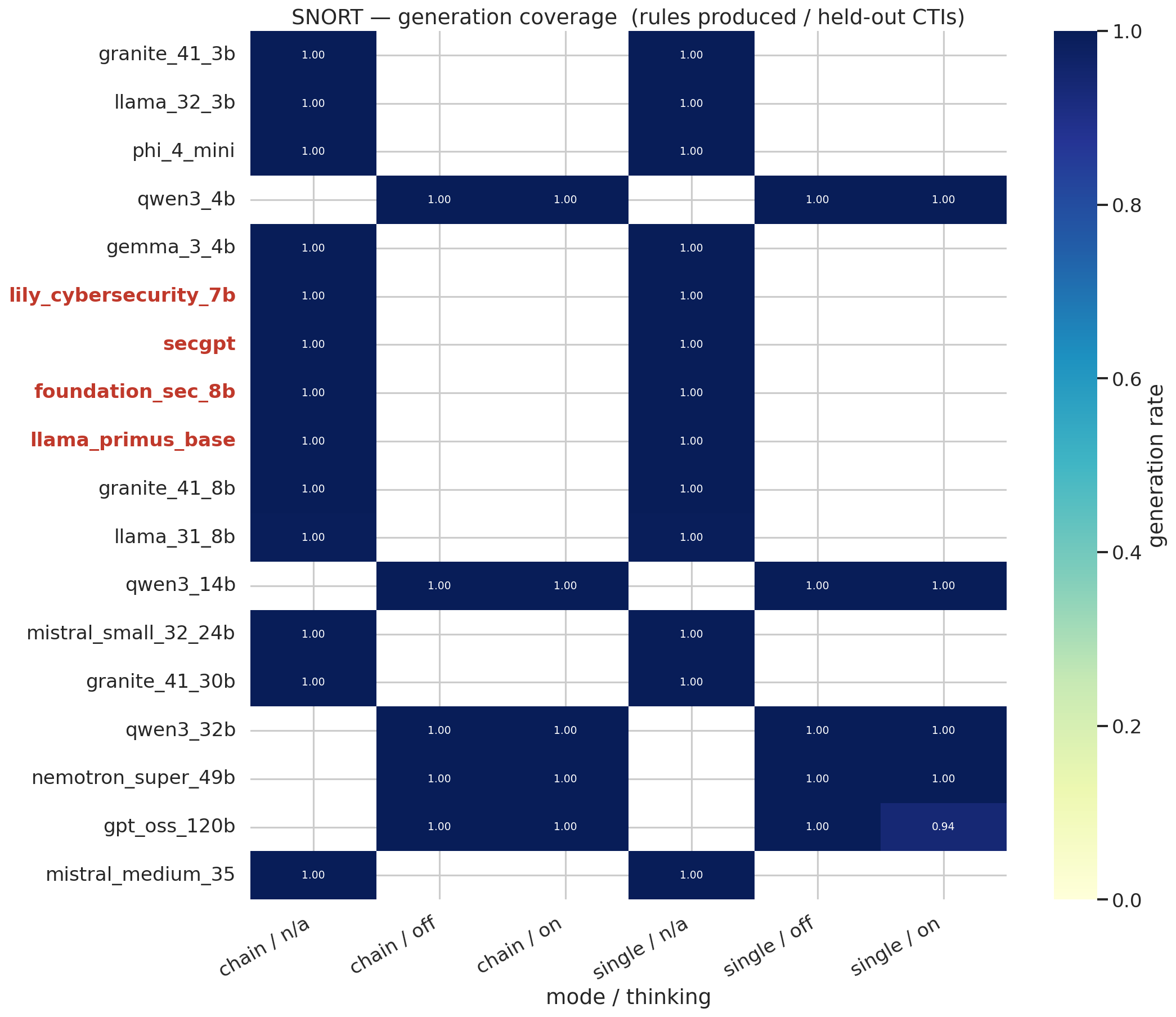
#### 生成覆盖率 —— Snort
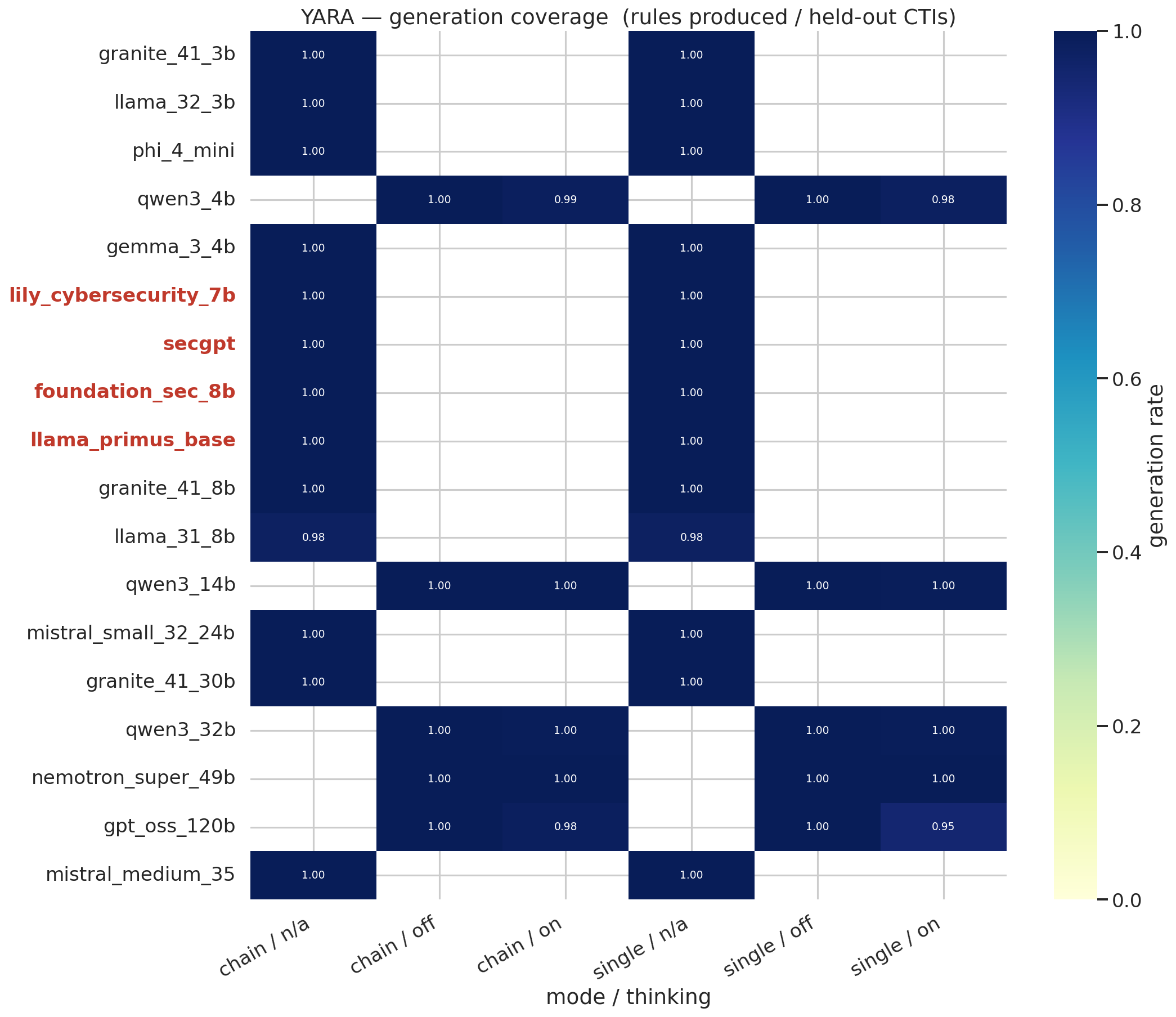
#### 生成覆盖率 —— YARA
## 引用
如果您使用了此数据集或代码库,请引用我们的论文:
```
@article{mitra2025falcon,
title={FALCON: Autonomous Cyber Threat Intelligence Mining with LLMs for IDS Rule Generation},
author={Mitra, Shaswata and Bazarov, Azim and Duclos, Martin and Mittal, Sudip and Piplai, Aritran and Rahman, Md Rayhanur and Zieglar, Edward and Rahimi, Shahram},
journal={arXiv preprint arXiv:2508.18684},
year={2025}
}
```
论文:https://arxiv.org/abs/2508.18684
## 许可证
本项目采用 [知识共享署名-非商业性使用-禁止演绎 4.0 国际 (CC BY-NC-ND 4.0)](https://creativecommons.org/licenses/by-nc-nd/4.0/) 许可证授权。
标签:DLL 劫持, DNS 反向解析, Python, 凭据扫描, 大语言模型, 威胁情报, 开发者工具, 无后门, 网络安全, 自动化规则生成, 逆向工具, 隐私保护