Thishithasai406/signSpeak
GitHub: Thishithasai406/signSpeak
SignSpeak 是一个基于 MediaPipe 和 CNN 的实时 ASL 手语指语转文本与语音平台,旨在弥合听觉与非听觉社区之间的沟通鸿沟。
Stars: 0 | Forks: 0
SignSpeak ✋
实时 ASL 手语转文本和语音转换平台
(⬆ 回到顶部)
## ✨ 功能 ### 核心 AI 功能 - 实时 ASL 字母识别 (A–Z) - 通过 MediaPipe 进行 21 点手部关键点追踪 - 作为 CNN 输入的骨骼渲染 - CNN 预测手势组别 (0–7) - 基于规则的精确字母识别与细化 - 使用手势控制进行句子构建 - 使用 `pyenchant` 提供拼写建议 - 使用 `pyttsx3` 进行文本转语音输出 ### 网站功能 - 学习字母 (A–Z) 交互式版块 - 带有实时网络摄像头预览和实时反馈的练习模式 - 用于评估用户学习效果的练习测试 - 得分追踪、连续答对计数和测验完成反馈 - 简洁友好的 Web 界面,带有流畅的动画效果(⬆ 回到顶部)
## 🗂️ 项目结构 ``` signSpeak-main/ │ ├── app.py # Flask web server — serves UI, launches prediction engine ├── prediction.py # Core real-time ASL recognition logic (Tkinter + OpenCV + CNN) ├── cnn8grps_rad1_model.h5 # Pre-trained CNN model (8-group classifier) ├── requirements.txt # Python dependencies (pinned versions) ├── prediction_errors.log # Runtime error log (auto-generated) │ ├── templates/ │ └── index.html # SignSpeak web UI (Home, Learn, Practice, Live Preview) │ ├── static/ # ASL alphabet sign images (A–Z) + background assets │ ├── A.png … Z.png # Per-letter hand sign reference images │ └── background.png # Hero section background │ ├── SignSpeak.png # Website preview banner ├── sign.png # ASL alphabet reference chart ├── handlandmark.png # MediaPipe 21-point hand landmark diagram └── Evaluation.png # Model evaluation results (group-level accuracy) ```(⬆ 回到顶部)
## 🖥️ 技术栈 ### 后端与 AI - **Web 框架**:[Flask](https://flask.palletsprojects.com/) — 轻量级的 Python Web 服务器 - **编程语言**:Python 3.9+ (在 Windows 上测试) - **深度学习**:[TensorFlow 2.13](https://www.tensorflow.org/) + Keras — CNN 模型推理 - **计算机视觉**:[OpenCV](https://opencv.org/) — 网络摄像头捕获和图像处理 - **手部追踪**:[MediaPipe](https://mediapipe.dev/) + [CVZone](https://github.com/cvzone/cvzone) — 21 点手部关键点检测 - **桌面 GUI**:Tkinter + Pillow — 实时预览识别窗口 - **文本转语音**:[pyttsx3](https://pyttsx3.readthedocs.io/) — 离线语音合成 - **拼写检查**:[pyenchant](https://pyenchant.github.io/pyenchant/) — 基于词典的单词建议 ### 前端 - **UI**:单页 HTML/CSS/JavaScript (`templates/index.html`) - **样式**:带有深色主题、渐变和滚动动画的自定义 CSS - **资源**:包含所有 26 个 ASL 字母手势的静态 PNG 图像 ### 基础设施 - **进程管理**:`subprocess` + 可选的 `psutil`,用于预测进程追踪 - **模型格式**:Keras `.h5` (8 类 softmax 输出)(⬆ 回到顶部)
## 📄 页面与版块 ### Web 界面 (`http://localhost:5000`) | 版块 | 导航链接 | 描述 | |---|---|---| | 首页 | 首页 | Hero 横幅、功能卡片和项目故事 | | 功能 | 功能 | 实时识别、学习、测验、UI、进度、设计 | | 关于 | 关于 | 项目灵感和使命宣言 | | 学习 | 学习 | 交互式的 A–Z 字母网格,包含手势图像和模态框详情 | | 练习 | 练习 | 带有模式选择和 10 题一轮的测验中心 | | 实时预览 | 摄像头按钮 | 启动 `prediction.py` 桌面应用程序进行实时识别 | ### 学习页面 | 元素 | 描述 | |---|---| | 字母网格 | 26 个可点击的卡片——每个显示字母、手势图像/表情符号和描述模态框 | | 字母模态框 | 完整的手势图像、字母名称以及逐步的手势描述 | ### 练习页面 | 模式 | 描述 | |---|---| | 手势 → 字母 | 显示一张手势图像;用户从 4 个选项中选出正确的字母 | | 字母 → 手势 | 显示一个字母;用户从 4 个选项中选出正确的手势 | | 测验完成 | 根据正确率显示奖杯、最终得分和表现评语 | ### 实时预览桌面应用 (`prediction.py`) | 面板 | 描述 | |---|---| | 摄像头画面 | 带有手部骨骼覆盖层的实时镜像网络摄像头视图 | | 字符显示 | 当前检测到的字母 (A–Z) | | 句子构建器 | 从已确认的手势中累积的文本 | | 建议 | 最多 4 个拼写检查单词建议(点击应用) | | 操作按钮 | **Clear**(重置文本)和 **Speak**(文本转语音输出) | | LIVE 徽章 | 摄像头面板上的实时状态指示器 |(⬆ 回到顶部)
## 🚀 快速开始 ### 前置条件 - Python `3.9`(推荐——为了与 TensorFlow 2.13 兼容) - 可正常工作的**网络摄像头** - Windows(主要测试平台;Linux/macOS 可能需要在调整依赖项后运行) - Git ### 分步设置 **1. 克隆代码仓库:** ``` git clone(⬆ 回到顶部)
## 🧠 模型与数据集 ### 数据集 - **名称**:ASL Mediapipe Landmarked Dataset (A–Z) - **来源**:[Kaggle — granthgaurav/asl-mediapipe-converted-dataset](https://www.kaggle.com/datasets/granthgaurav/asl-mediapipe-converted-dataset) - **类别**:美国手语指语的 26 个字母 (A–Z) - **每类样本数**:每个字母 180 张图像 - **总图像数**:约 4,681 张(3,276 张训练集 / 702 张验证集 / 703 张测试集) - **输入尺寸**:400 × 400 × 3 骨骼渲染图像 - **数据格式**:使用 MediaPipe 预处理过的手部图像——每张图像将 21 个手部关键点编码为白色背景上渲染的骨骼 ### 为什么分为 8 组而不是 26 个直接类别? 某些 ASL 字母的**手形非常相似**。训练一个 26 类的 CNN 会导致在相似的组内出现频繁的错误分类: | 相似的组别 | 包含字母 | |---|---| | 握拳变体 | A, E, M, N, S, T | | 张开手掌变体 | B, D, F, I, U, V, W, K, R | | 弯曲手形 | C, O | | 食指/拇指对 | G, H | | 单个字母 | L | | 复杂形状 | P, Q, Z | | 交叉手指 | X | | 扩展形状 | Y, J | **解决方案:**将 26 个字母分为 **8 个手势类别**。CNN 负责对组进行分类;基于规则的几何逻辑对 MediaPipe 关键点进行处理以确定具体的字母。 | 组别 | 组内字母 | |---|---| | 0 | A, E, M, N, S, T | | 1 | B, D, F, I, U, V, W, K, R | | 2 | C, O | | 3 | G, H | | 4 | L | | 5 | P, Q, Z | | 6 | X | | 7 | Y, J | #### 8 组分类方法的优势 | 优势 | 描述 | |---|---| | **更高的准确率** | 模型只需区分 8 个组别——学习更容易,性能更好 | | **所需训练数据更少** | 26 类训练需要大得多的数据集;分组方法仅需约 4,680 张图像即可工作 | | **减少错误分类** | 形似的字母通过几何规则进行区分,而不仅仅依靠 CNN | | **更快更稳定的推理** | 输出复杂性降低 → 训练和实时预测更快 | | **实现规则整合** | 关节位置使得进行距离/角度检查成为可能,而这仅靠原始图像是无法实现的 | ### 为什么使用骨骼图像而不是原始手部照片? | 优势 | 描述 | |---|---| | **不受背景影响** | 仅捕捉手部姿势——没有背景、衣物或光线的干扰 | | **不受肤色影响** | 性能不依赖于肤色——只有关节几何起作用 | | **更高准确率,更少数据** | 约 4,680 张骨骼图像就够了;原始图像可能需要 50,000+ 个样本 | | **实时稳健性** | 能够在不同环境和摄像头画质下流畅运行 | | **几何规则整合** | 精确的关节位置使得能够对形似字母 (M/N/S/T, U/V/W, G/H, P/Q/Z) 进行细化 | | **快速训练与推理** | 更小、更有意义的输入 → 更快的预测速度 → 实现实时性能 | ### MediaPipe 手部关键点 MediaPipe 每只手可检测并追踪 **21 个手部关键点**: - **关键点 0**:手腕(手部基部) - **关键点 1–4**:拇指 (CMC, MCP, IP, Tip) - **关键点 5–8**:食指 (MCP, PIP, DIP, Tip) - **关键点 9–12**:中指 (MCP, PIP, DIP, Tip) - **关键点 13–16**:无名指 (MCP, PIP, DIP, Tip) - **关键点 17–20**:小指 (MCP, PIP, DIP, Tip) 每个关键点都有归一化的 `(x, y, z)` 坐标,可用于: 1. 渲染输入到 CNN 的骨骼图像 2. 提取几何特征,用于基于规则的字母细化 3. 使系统对背景、光线和摄像头变化保持稳健性 ### 模型训练 | 参数 | 值 | |---|---| | **架构** | 卷积神经网络 (CNN) — TensorFlow + Keras | | **各层** | 卷积 → 最大池化 → 全连接 → Softmax (8 类) | | **输入** | 400 × 400 × 3 骨骼图像 | | **预处理** | 调整大小至 400×400,将像素归一化到 0–1 | | **损失** | 交叉熵分类损失 | | **指标** | Top-1 准确率,Top-3 准确率,交叉熵 | | **输出** | `cnn8grps_rad1_model.h5` — 8 组 softmax 分类器 | | **数据集划分** | 80% 训练集 / 20% 验证集 (按组别级别划分) | ``` Skeleton Image (400×400) → CNN → Group (0–7) → Rules → Letter (A–Z) ``` ### 模型评估 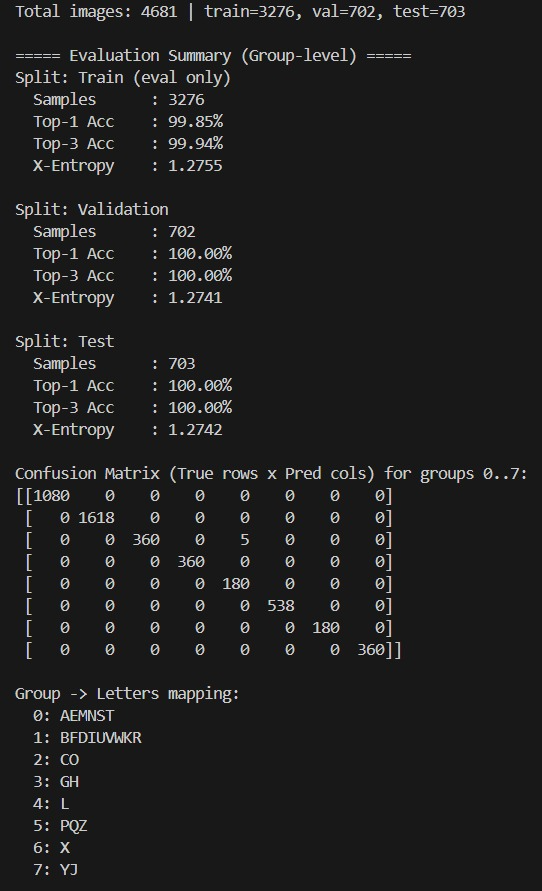 ### ASL 字母参考表  ### MediaPipe 手部关键点示意图 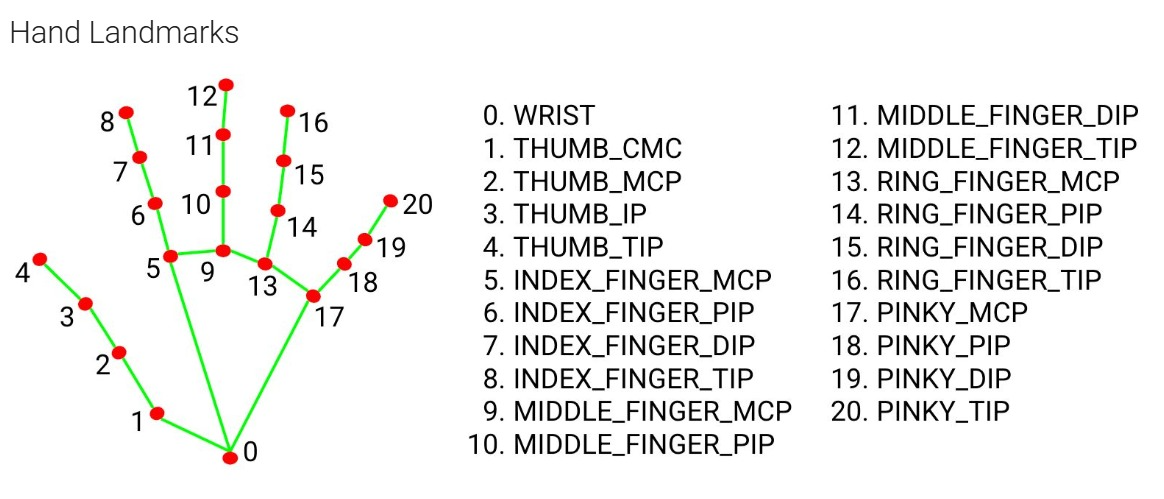(⬆ 回到顶部)
## 📝 句子构建 SignSpeak 专为**完整句子构建**而设计——而不是每次只显示一个字母。用户可以逐个字母拼写单词、构建完整的句子、纠正拼写错误并朗读结果。 ### 控制手势 | 手势 | 动作 | |---|---| | **Next** | 确认当前字符并将其添加到句子中 | | **Backspace** | 删除句子中的最后一个字符 | | **Pause / Double Space (暂停 / 双空格)** | 在单词之间插入一个空格字符 | 一个包含**最近 10 次预测**的时间缓冲区可防止因画面噪点而造成的误触发。此功能在 `prediction.py` 中的 `predict()` 内实现。 ### 如何构建句子 1. 在网络摄像头前**展示一个手势** 2. **查看预测到的字母**,该字母将实时显示在字符面板上 3. **执行 Next 手势**确认并将该字母添加到您的句子中 4. 对每个字母**重复此过程**以拼出一个单词(例如:H → E → L → L → O) 5. 使用暂停/双空格手势**插入一个空格**以移至下一个单词 6. **使用拼写建议**——将检查最后一个单词是否符合词典;最多会显示 4 个更正建议 7. **点击一个建议**即可立即替换拼写错误的单词 8. **点击 Clear** 重置整个句子,或点击 **Speak** 大声朗读 9. **pyttsx3 朗读完整的句子**——将手语文本转化为口语交流 ### 示例工作流 ``` Sign "H" → Next → Sign "I" → Next → Pause (space) → Sign "T" → Next → Sign "H" → Next → Sign "E" → Next → Sign "R" → Next → Sign "E" → Next Result: "HI THERE" → Apply spell suggestion if needed → Press Speak ``` ### 完整的系统流程 ``` Camera → MediaPipe (21 landmarks extracted) → CVZone (skeleton rendered on white background) → CNN Model (predicts gesture group 0–7) → Rule-Based Logic (refines to exact letter A–Z) → Sentence Builder (Next / Backspace / Space gestures) → Spell Suggestions (pyenchant dictionary check) → Text-to-Speech (pyttsx3 speaks the sentence) ```(⬆ 回到顶部)
## 🔧 故障排除 | 问题 | 解决方案 | |---|---| | 实时预览中未显示摄像头画面 | 确保没有其他应用程序正在使用网络摄像头;关闭并重新启动实时预览 | | 预览窗口为空白 | 检查项目根目录下的 `prediction_errors.log` 以查看运行时错误 | | `findHands` 解包错误 | 使用 `cvzone==1.5.6` —— 当 `draw=False` 时,`findHands()` 返回的是一个单一的列表,而不是元组 | | 未找到模型 | 将 `cnn8grps_rad1_model.h5` 放在项目根目录 (`signSpeak-main/`) 下 | | 首次启动缓慢 | 属于正常现象——首次运行时 TensorFlow 模型加载需要 15–30 秒 | | 拼写建议无效 | 安装 Enchant 词典:`pip install pyenchant` 并确保操作系统词典可用 |(⬆ 回到顶部)
## 🚀 未来增强计划 - 📱 使用 TensorFlow Lite 或 WebAssembly 的移动端/基于 Web 的识别 - 🤖 直接的关键点神经网络(基于 3D 坐标而非渲染骨骼进行训练) - 🌍 多语言手语支持 (ISL, BSL 等) - 🔄 在多样化的光照条件和肤色下对模型进行 fine-tuning - 🎬 动态手势序列识别(单词和短语,而不仅仅是字母) - 🐳 Docker 容器化,实现一键部署 - 🧪 使用 Playwright 进行自动化的端到端测试 - ☁️ 云部署,带有基于浏览器的网络摄像头识别(无需桌面应用程序)(⬆ 回到顶部)
## 🤝 贡献指南 欢迎您的贡献!请按照以下步骤操作: 1. Fork 本代码仓库 2. 创建您的功能分支 (`git checkout -b feature/AmazingFeature`) 3. 提交您的更改 (`git commit -m 'Add some AmazingFeature'`) 4. 推送到该分支 (`git push origin feature/AmazingFeature`) 5. 发起一个 Pull Request(⬆ 回到顶部)
## 🙏 致谢 - [ASL Mediapipe Landmarked Dataset (A–Z)](https://www.kaggle.com/datasets/granthgaurav/asl-mediapipe-converted-dataset) — 由 Granth Gaurav 提供的训练数据集 - [MediaPipe](https://mediapipe.dev/) — 实时手部关键点检测 - [CVZone](https://github.com/cvzone/cvzone) — 手部追踪封装和可视化 - [TensorFlow](https://www.tensorflow.org/) — 用于 CNN 训练和推理的深度学习框架 - [OpenCV](https://opencv.org/) — 图像捕获、处理和显示 - [Flask](https://flask.palletsprojects.com/) — Web 应用程序框架 - [pyttsx3](https://pyttsx3.readthedocs.io/) — 离线文本转语音引擎 - [pyenchant](https://pyenchant.github.io/pyenchant/) — 拼写检查和单词建议(⬆ 回到顶部)
## 📜 许可证 基于 MIT 许可证分发。查看 `LICENSE` 了解更多信息。 *SignSpeak —— 通过通用的手势语言,弥合听觉与非听觉社区之间的鸿沟。*标签:Flask, Python, 卷积神经网络, 后端开发, 手语识别, 无后门, 深度学习, 计算机视觉, 语音合成, 辅助技术, 逆向工具