Andrej-Art/Mailharpoon
GitHub: Andrej-Art/Mailharpoon
基于机器学习的钓鱼URL检测系统,通过多种分类模型分析URL特征并提供交互式风险评估界面。
Stars: 1 | Forks: 0
#  Mailharpoon:钓鱼检测与洞察

**Mailharpoon** 是一个基于机器学习的工具,旨在分析 URL 并识别潜在的钓鱼企图。该项目结合了数据科学技术与交互式 Web 界面,为用户提供风险评分以及关于可疑 URL 特征的详细洞察。
## 概述
钓鱼攻击通常使用欺骗性 URL 来诱骗用户泄露敏感信息。Mailharpoon 利用 **UCI Phishing Websites Dataset** 训练分类模型,该模型能够基于 30 多个特征(例如 URL 长度、SSL 状态、域名注册时长)来区分合法网站和恶意网站。
## 核心功能
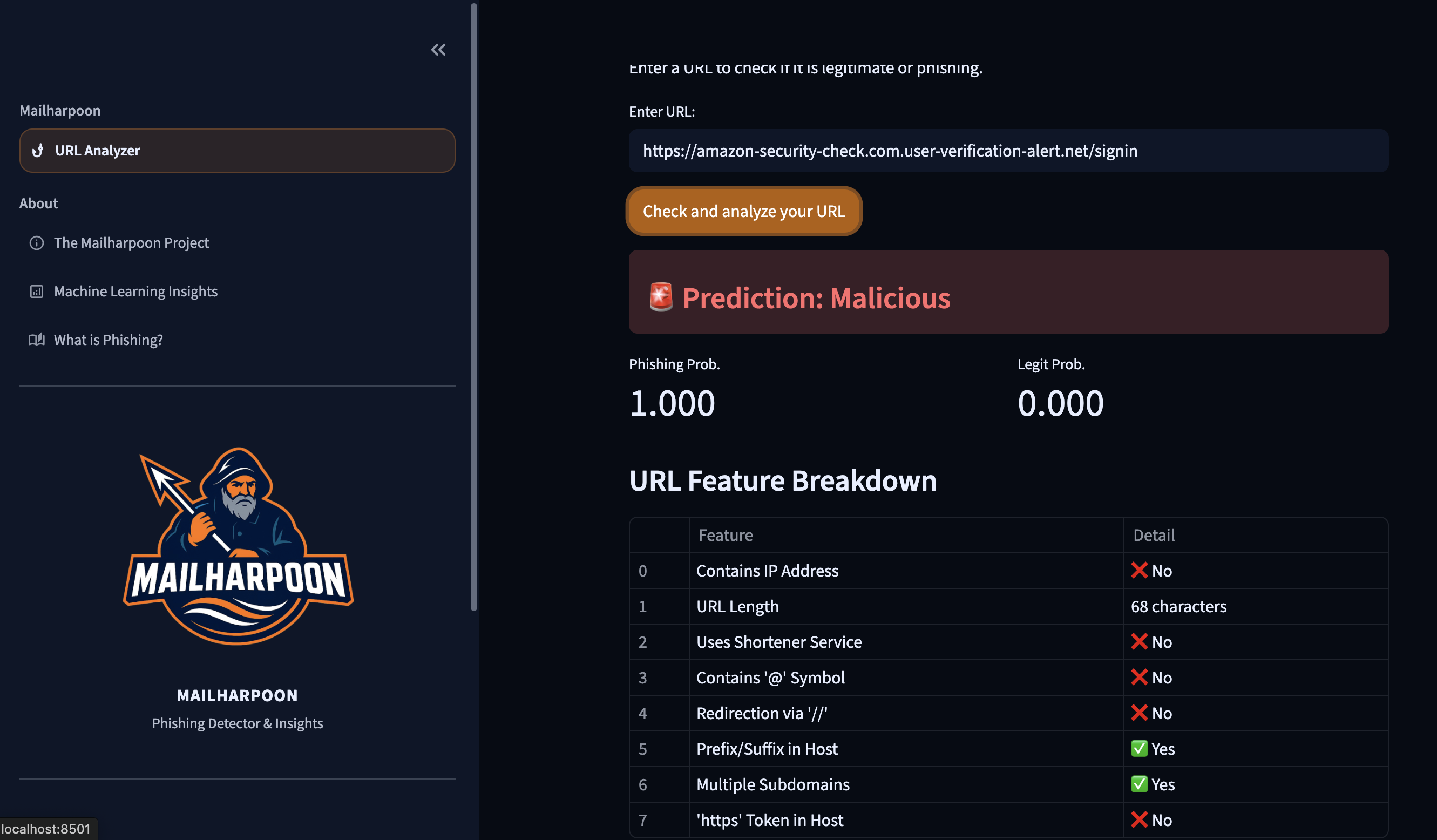
- **交互式 URL 分析器**:粘贴 URL 即可获得即时风险评估。
- **机器学习洞察**:探索分类模型背后的原理。
- **教育内容**:了解什么是钓鱼攻击以及如何自我保护。
- **现代化 UI**:使用 Streamlit 构建的时尚暗色模式仪表板。
## 机器学习模型
为了确定钓鱼检测的最佳模型,我们训练并评估了多种机器学习模型。以下模型已接受训练:
- Random Forest
- MLP
- Decision Tree
- SVM
- Gradient Boosting
- KNN
- Logistic Regression
- Naive Bayes

为了评估 Random Forest 分类器的稳定性和泛化能力,我们在完整数据集上进行了 5 折分层交叉验证(5-fold Stratified Cross-Validation)。分层确保了每一折中的类别分布(钓鱼与合法)保持一致。

Random Forest 模型展示了:
- 在所有评估指标上均具有极高的预测性能。
- 极低的标准差,表明在不同数据划分下具有很强的稳定性。
- 一致的钓鱼检测召回率,这在安全背景下至关重要。
- 卓越的判别能力,这一点从接近完美的 ROC-AUC 值中得到了体现。
各折之间微小的差异表明 Random Forest 模型泛化能力良好,并且不过度依赖于特定的训练-测试划分。这证实了之前观察到的强劲测试性能并非源于随机性或数据泄露。
## 项目结构
- `backend/`:数据处理与模型开发。
- `data/`:原始数据集与处理后数据集。
- `notebooks/`:用于 EDA、预处理和建模的 Jupyter Notebooks。
- `frontend_streamlit/`:交互式 Web 应用程序。
- `images/`:品牌资产与补充视觉材料。
- `requirements.txt`:项目依赖项。
## 技术栈
- **语言**:Python
- **Web 框架**:Streamlit
- **数据科学**:Pandas, NumPy, Scikit-learn
- **可视化**:Matplotlib, Seaborn
## 如何运行
1. **克隆仓库**:
git clone https://github.com/Andrej-Art/Mailharpoon.git
cd Mailharpoon
2. **安装依赖**:
pip install -r requirements.txt
3. **运行 Streamlit 应用**:
streamlit run frontend_streamlit/app.py
## 部分截图


*由 Andrej Artuschenko 开发*
Mailharpoon:钓鱼检测与洞察

**Mailharpoon** 是一个基于机器学习的工具,旨在分析 URL 并识别潜在的钓鱼企图。该项目结合了数据科学技术与交互式 Web 界面,为用户提供风险评分以及关于可疑 URL 特征的详细洞察。
## 概述
钓鱼攻击通常使用欺骗性 URL 来诱骗用户泄露敏感信息。Mailharpoon 利用 **UCI Phishing Websites Dataset** 训练分类模型,该模型能够基于 30 多个特征(例如 URL 长度、SSL 状态、域名注册时长)来区分合法网站和恶意网站。
## 核心功能
- **交互式 URL 分析器**:粘贴 URL 即可获得即时风险评估。
- **机器学习洞察**:探索分类模型背后的原理。
- **教育内容**:了解什么是钓鱼攻击以及如何自我保护。
- **现代化 UI**:使用 Streamlit 构建的时尚暗色模式仪表板。
## 机器学习模型
为了确定钓鱼检测的最佳模型,我们训练并评估了多种机器学习模型。以下模型已接受训练:
- Random Forest
- MLP
- Decision Tree
- SVM
- Gradient Boosting
- KNN
- Logistic Regression
- Naive Bayes

为了评估 Random Forest 分类器的稳定性和泛化能力,我们在完整数据集上进行了 5 折分层交叉验证(5-fold Stratified Cross-Validation)。分层确保了每一折中的类别分布(钓鱼与合法)保持一致。

Random Forest 模型展示了:
- 在所有评估指标上均具有极高的预测性能。
- 极低的标准差,表明在不同数据划分下具有很强的稳定性。
- 一致的钓鱼检测召回率,这在安全背景下至关重要。
- 卓越的判别能力,这一点从接近完美的 ROC-AUC 值中得到了体现。
各折之间微小的差异表明 Random Forest 模型泛化能力良好,并且不过度依赖于特定的训练-测试划分。这证实了之前观察到的强劲测试性能并非源于随机性或数据泄露。
## 项目结构
- `backend/`:数据处理与模型开发。
- `data/`:原始数据集与处理后数据集。
- `notebooks/`:用于 EDA、预处理和建模的 Jupyter Notebooks。
- `frontend_streamlit/`:交互式 Web 应用程序。
- `images/`:品牌资产与补充视觉材料。
- `requirements.txt`:项目依赖项。
## 技术栈
- **语言**:Python
- **Web 框架**:Streamlit
- **数据科学**:Pandas, NumPy, Scikit-learn
- **可视化**:Matplotlib, Seaborn
## 如何运行
1. **克隆仓库**:
git clone https://github.com/Andrej-Art/Mailharpoon.git
cd Mailharpoon
2. **安装依赖**:
pip install -r requirements.txt
3. **运行 Streamlit 应用**:
streamlit run frontend_streamlit/app.py
## 部分截图



*由 Andrej Artuschenko 开发*
Mailharpoon:钓鱼检测与洞察

**Mailharpoon** 是一个基于机器学习的工具,旨在分析 URL 并识别潜在的钓鱼企图。该项目结合了数据科学技术与交互式 Web 界面,为用户提供风险评分以及关于可疑 URL 特征的详细洞察。
## 概述
钓鱼攻击通常使用欺骗性 URL 来诱骗用户泄露敏感信息。Mailharpoon 利用 **UCI Phishing Websites Dataset** 训练分类模型,该模型能够基于 30 多个特征(例如 URL 长度、SSL 状态、域名注册时长)来区分合法网站和恶意网站。
## 核心功能
- **交互式 URL 分析器**:粘贴 URL 即可获得即时风险评估。
- **机器学习洞察**:探索分类模型背后的原理。
- **教育内容**:了解什么是钓鱼攻击以及如何自我保护。
- **现代化 UI**:使用 Streamlit 构建的时尚暗色模式仪表板。
## 机器学习模型
为了确定钓鱼检测的最佳模型,我们训练并评估了多种机器学习模型。以下模型已接受训练:
- Random Forest
- MLP
- Decision Tree
- SVM
- Gradient Boosting
- KNN
- Logistic Regression
- Naive Bayes

为了评估 Random Forest 分类器的稳定性和泛化能力,我们在完整数据集上进行了 5 折分层交叉验证(5-fold Stratified Cross-Validation)。分层确保了每一折中的类别分布(钓鱼与合法)保持一致。

Random Forest 模型展示了:
- 在所有评估指标上均具有极高的预测性能。
- 极低的标准差,表明在不同数据划分下具有很强的稳定性。
- 一致的钓鱼检测召回率,这在安全背景下至关重要。
- 卓越的判别能力,这一点从接近完美的 ROC-AUC 值中得到了体现。
各折之间微小的差异表明 Random Forest 模型泛化能力良好,并且不过度依赖于特定的训练-测试划分。这证实了之前观察到的强劲测试性能并非源于随机性或数据泄露。
## 项目结构
- `backend/`:数据处理与模型开发。
- `data/`:原始数据集与处理后数据集。
- `notebooks/`:用于 EDA、预处理和建模的 Jupyter Notebooks。
- `frontend_streamlit/`:交互式 Web 应用程序。
- `images/`:品牌资产与补充视觉材料。
- `requirements.txt`:项目依赖项。
## 技术栈
- **语言**:Python
- **Web 框架**:Streamlit
- **数据科学**:Pandas, NumPy, Scikit-learn
- **可视化**:Matplotlib, Seaborn
## 如何运行
1. **克隆仓库**:
git clone https://github.com/Andrej-Art/Mailharpoon.git
cd Mailharpoon
2. **安装依赖**:
pip install -r requirements.txt
3. **运行 Streamlit 应用**:
streamlit run frontend_streamlit/app.py
## 部分截图



*由 Andrej Artuschenko 开发*标签:Apex, Kubernetes, K近邻, Streamlit, UCI数据集, URL分析, 交互式仪表板, 人工神经网络, 决策树, 分类模型, 恶意网站识别, 支持向量机, 数据科学, 朴素贝叶斯, 机器学习, 梯度提升, 欺诈检测, 特征工程, 监督学习, 网络安全, 访问控制, 资源验证, 逆向工具, 逻辑回归, 邮件安全, 钓鱼检测, 随机森林, 隐私保护