aws-samples/sample-security-log-transfrom-with-config-driven-etl
GitHub: aws-samples/sample-security-log-transfrom-with-config-driven-etl
提供一个配置驱动的 ETL 框架,将安全日志转换为 OCSF 格式并加载到 AWS Security Lake。
Stars: 2 | Forks: 0
- [Security Lake ETL Framework](#security-lake-etl-framework)
- [Prerequisites](#prerequisites)
- [Assumptions/Limitations](#assumptionslimitations)
- [Environment Setup](#environment-setup)
- [CDK Setup](#cdk-setup)
- [Pre Deployment Configuration](#pre-deployment-configuration)
- [Deployment](#deployment)
- [Solution Usage](#solution-usage)
- [Step Function](#step-function)
- [Alerting & Monitoring](#alerting--monitoring)
- [Dynamo DB Table Details](#dynamo-db-table-details)
- [FAQs and Troubleshooting](#faqs-and-troubleshooting)
- [Loading historical Data](#loading-historical-data)
- [What is Enrichment and how can I use it?](#what-is-enrichment-and-how-can-i-use-it)
- [How can I change Spark Submit configurations?](#how-can-i-change-spark-submit-configurations)
- [Recommendations](#recommendations)
- [Limitations & Workarounds](#limitations--workarounds)
# Security Lake ETL Framework
本存储库提供了一种使用配置驱动的 ETL 框架将安全日志转换为 OCSF 格式的示例方法,并提供了逐步部署和使用说明。
# 先决条件
* 解决方案需要一个 VPC。用户可以提供 VPC,或自动创建一个。
* 如果用户提供 VPC:必须存在 Secrets Manager、S3、DynamoDB 和 SNS 的 VPC 终端节点。类型 `PRIVATE_WITH_EGRESS` 的子网必须存在,因为 Lambda、Glue、EMR 等资源会放置在其中。
* 如果使用 Enrichment:用户必须提供其所在的 VPC 以及部署期间访问所需的网络安全组和配置。
* 必须存在一个具有自引用规则作为入站规则的安全组,用于 Enrichment 数据库。
* 用户提供的 VPC 应具有足够的弹性 IP 容量,以便在内部部署 EMR Serverless。
* 如果不使用 Enrichment,用户可以提供已有 VPC 并配置所需终端节点,或自动创建一个。
# 假设/限制
1. 当前 Security Lake ETL 在与 S3 存储桶相同的账户中运行。不支持跨账户配置。
2. 如果使用 Enrichment,JDBC 源应在 AWS 中与 ETL 框架相同的 VPC 中运行。
3. JDBC 凭证、主机和端口应存在于 Secrets Manager 中。Secret ID 将在部署期间传递。
4. 如果需要 Enrichment,Glue/EMR 作业应在与 JDBC 源相同的 VPC 中运行。
5. 历史源数据应按年、月、日进行分区。
6. 支持的 JDBC 引擎包括:POSTGRESQL、ORACLE、MYSQL 和 SQL_SERVER。
7. 当前不支持条件映射和一对多源到目标映射。
# 环境设置
## 本地环境先决条件
* 部署已测试通过 Python >=3.9。
* 我们建议用户设置[命名配置文件以管理 AWS CLI 凭据](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html#cli-configure-files-using-profiles)。本部署说明假设用户已完成此步骤。
* 如果用户选择不使用命名配置文件而使用默认配置文件,则无需在以下命令中传递配置文件名称。
1. `cd cdk`
2. `python3 -m venv .venv`
3. `source .venv/bin/activate`
4. `pip install -r requirements.txt`
5. 如果尚未在目标环境中部署过 CDK,可能需要[引导账户](https://docs.aws.amazon.com/cdk/v2/guide/bootstrapping.html) `cdk bootstrap aws://ACCOUNT-NUMBER-1/REGION-1 --profile NAMED_PROFILE`
## 部署前配置
为了方便起见,提供了一个 CLI 脚本,可交互式地设置解决方案的配置。如需使用默认配置(无 Enrichment 数据库)部署到新创建的 VPC 并包含两个子网,可跳过此步骤。
* 在 `cdk` 目录中运行 `python create_config.py`。
* 根据环境需求回答问题,系统会生成配置文件。例如,默认配置:
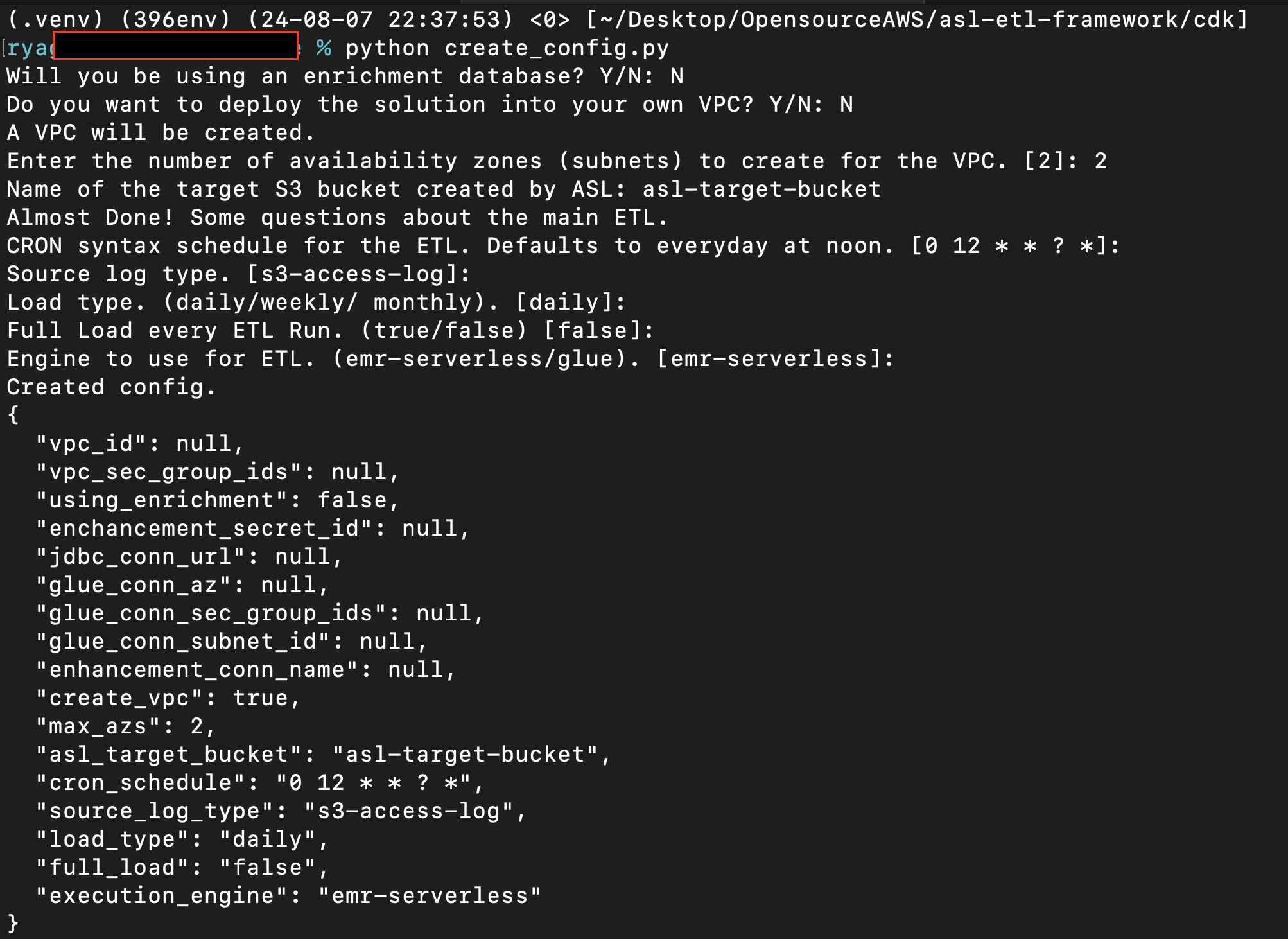
## 设置 OCSF Schema
OCSF 类名称将决定从日志中提取哪些数据。在 `config.py` 顶部设置 `CLASS_NAMES` 变量为你需要的值,默认为 `network_activity`。可参考 [https://schema.ocsf.io/1.0.0-rc.3/classes?extensions=](https://schema.ocsf.io/1.0.0-rc.3/classes?extensions=)。
## 部署
1. 运行 `cdk deploy SecureDatalakeStack --profile NAMED_PROFILE`
2. **SNS 配置**:CDK 部署完成后,请订阅所需的邮件到 SNS 主题。
3. 该 CDK 部署已预配置为转换 VPC 流日志。可按以下步骤快速执行:
1. 执行参考 Lambda(asl-etl-framework_update-reference-ddb),从 https://schema.ocsf.io/ 提取所需类的模式定义并存储到参考 DynamoDB 表。
2. 以 Parquet 格式上传测试 VPC 流源数据到路径:Source-Bucket/vpc-flow-logs/2019/12/31/
3. 从 Artifact-Bucket/config/metadata/ 下载元数据文件 vpc-flow-log-metadata.csv,并重新上传至同一路径以触发所需的事件通知,进而调用 Lambda 函数更新 DynamoDB 表。
4. 进入 Step Function,使用以下输入运行步骤函数:
```
{
"source_log_type": "s3-access-log",
"load_type": "historical",
"full_load": "false",
"execution_engine": "glue",
"ddb_lookup_table": "asl-etl-framework-table-details",
"ddb_mapping_table": "asl-etl-framework-ocsf-attribute-mapping",
"ddb_metadata_table": "asl-etl-framework-source-ocsf-metadata",
"ddb_reference_table": "asl-etl-framework-ocsf-reference",
"asl_status_table": "asl-etl-framework-run-status",
"asl_job_name": "asl-etl-framework-init-ocsf-conversion"
}
```
# 解决方案用法
1. 确定目标 OCSF 类并根据使用场景更新 `asl-etl-framework_update-reference-ddb` Lambda 函数的环境变量 `class_names`(如需要)。该 Lambda 函数会从 https://schema.ocsf.io/ 提取指定类的所需字段并存储到参考 DynamoDB 表。在继续之前,请执行此 Lambda 函数。
2. 准备 CSV 文件,存储源日志与目标 OCSF 属性之间的一一映射关系。映射文件详情如下。示例 VPC 流日志映射文件已由 CDK 部署预置:
1. 位置:Artifact-Bucket/config/mapping
2. 结构:该 CSV 应包含以下四列,顺序需与源日志一致:
1. **src_log_type**:源日志类型名称。全局一致。
2. **src_column_name**:源日志中的列名,保持与源文件中的顺序一致。
3. **tgt_column**:目标列,格式为 `:`,若目标列位于 OCSF 对象内则数据类型为 `object`。示例:
- `metadata.product.version` → `metadata:object.product:object.version:string`
- `start_time` → `time:timestamp`
- `bytes` → `traffic:object.bytes:bigint`
4. **default_values**:用于为目标列填充默认值,填写对应的目标列名。
3. 示例文件请参考 [这里](src/sample_config_files/config/mapping/)。
3. 将映射文件上传至 Artifact S3 存储桶。
4. 准备元数据文件(CSV 格式)。示例文件已存在于 Artifact-Bucket/config/mapping。可参考以下字段说明:
1. **source_log_type**:源名称,全局一致。
2. **load_type**:`"historical"` 或 `"daily"`。
3. **batch_load_type**:目标分区类型,可为 `"daily"`、`"monthly"` 或 `"yearly"`。
4. **daily_load_number_of_days**:若 `load_type` 为 `"daily"`,表示回溯天数。若设为 `"1"`,则任务运行时拉取前一天的分区数据。
5. **default_values**:若目标列存在默认值且源中缺失,设为 `"true"`。
6. **delimiter**:源文件分隔符(如 `|`、空格),空格需写为 `" "`。
7. **source_format**:源文件格式(`json`、`parquet`、`csv`、`txt`)。
8. **header**:是否包含表头(`"true"` 或 `"false"`)。
9. **historical_days_to_process**:回溯处理的天数。
10. **historical_load_start_date**:若时间范围不基于当前日期,填写起始日期(格式:`yyyy-MM-dd`)。
11. **historical_load_end_date**:若时间范围不基于当前日期,填写结束日期(格式:`yyyy-MM-dd`)。
12.batch_load_type**:历史加载方式,可为 `"monthly"`、`"yearly"` 或 `"daily"`。
13. **is_source_partitioned**:若源数据按年、月、日分区,设为 `"true"`。
14. **source_log_s3_bucket**:源文件存储桶名称。
15. **source_log_s3_prefix**:源文件路径前缀。
16. **source_log_timestamp_format**:时间戳格式(如 `[dd/MMM/yyyy:HH:mm:ssZZZZ]`),若为 epoch 时间则填写 `"epoch"`。
17. **source_log_ts_and_delimiter_as_whitespaces**:若分隔符为空格且时间戳含空格,设为 `true`。
18. **target_s3_bucket**:转换后的 OCSF Parquet 文件存储桶。
19. **target_s3_prefix**:转换后文件存储路径。
20. **mapping_file_s3_bucket**:映射文件存储桶。
21. **mapping_file_s3_prefix**:映射文件路径。
22. **hive_style_partition**:若源分区格式为 `year=xxxx/month=xx/day=xx`,设为 `true`;若为 `xxxx/xx/xx`,设为 `false`。
23. **hour_level_partition**:若存在小时级分区,设为 `true`。
24. **is_multiline**:若源数据跨多行,设为 `true`。
25. **is_enrichment_required**:是否需要 Enrichment。
26. **enrichment_column**:需要 Enrichment 的源列。
27. **enrichment_col_db**:JDBC 数据源中的对应列。
28. **enrichment_db**:JDBC 数据库名称。
29. **enrichment_table**:源表名称。
30. **enrichment_identifier**:Secrets Manager 中包含数据库用户名、密码及 JDBC 信息的字符串。
31. **ocsf_class_id**:映射对应的 OCSF 类 ID。
32. **ocsf_class_name**:映射对应的 OCSF 类名称。
5. 元数据文件上传后,S3 事件通知会触发 **Insert Metadata**,更新元数据 DynamoDB 表。
6. 该 Lambda 会调用 **Update Mapping** Lambda 更新对应的映射 DynamoDB 表。
7. 若需要 Enrichment,元数据 CSV 中需填写对应的 Enrichment 详情(如 JDBC 表、数据库等),具体见上文。
8. Enrichment 数据源的凭证应存储在 Secrets Manager,并在元数据 CSV 中指定 Secret Manager 字符串。
9. 任务会根据 CRON 计划触发,也可通过 Step Function 手动触发。
## 步骤函数
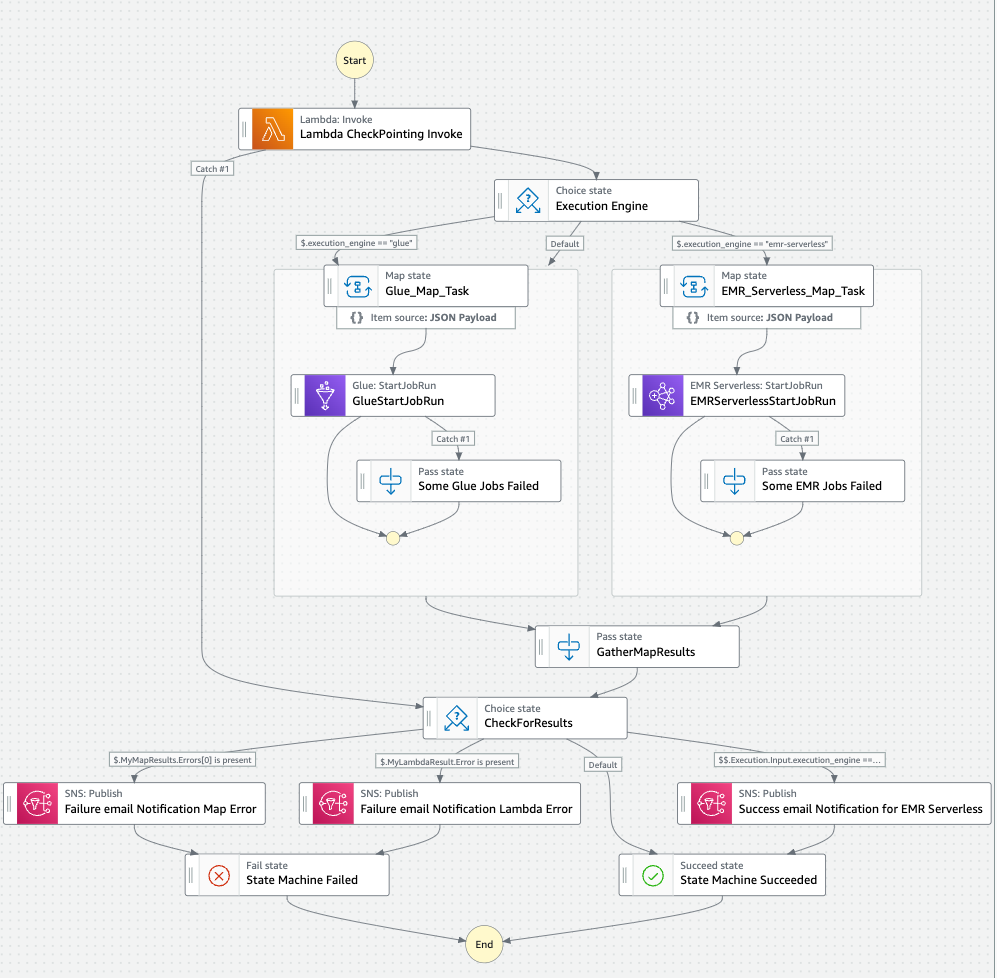
运行步骤函数需要提供输入,可通过 EventBridge 计划事件传递。以下为示例输入参数:
```
{
"source_log_type": "s3-access-log",
"load_type": "historical",
"full_load": "false",
"execution_engine": "glue",
"ddb_lookup_table": "asl-etl-framework-table-details",
"ddb_mapping_table": "asl-etl-framework-ocsf-attribute-mapping",
"ddb_metadata_table": "asl-etl-framework-source-ocsf-metadata",
"ddb_reference_table": "asl-etl-framework-ocsf-reference",
"asl_status_table": "asl-etl-framework-run-status",
"asl_job_name": "asl-etl-framework-init-ocsf-conversion"
}
```
**各步骤说明**
1. **lambda checkpointing invoke**:运行预处理器 Lambda,返回基于 `load_type` 的分区列表。若为 `"daily"`,返回天级分区;若为 `"historical"`,返回月级分区。
2. **Execution Engine choice state**:根据 `execution_engine` 输入路由到 Glue 或 EMR-Serverless 的映射状态。有效值为 `"glue"` 或 `"emr-serverless"`。
3. **Glue Map**:并行运行 Glue 作业处理每个分区。若有错误,会在 **Some Map Failed** 步骤中捕获,并等待每个作业完成,返回成功或失败状态。
4. **EMR-Serverless Map**:并行调用 EMR Serverless 作业处理每个分区。此步骤不等待作业完成,需在 EMR Serverless 应用中跟踪运行状态。
5. **Gather Map Results**:收集映射步骤结果。若 Glue 成功,进入通过步骤;若 EMR-Serverless 成功,发送 SNS 成功通知。
6. **SNS Job Submission Alert Step**:向订阅者发送 SNS 通知,提示“EMR Serverless Job 已提交,请通过 EMR Serverless 控制台跟踪状态”。
7. **Capture Errors Step**:捕获检查点 Lambda、Glue 映射或 EMR Serverless 映射步骤中的错误。
8. **Choice Step (Success or Failed)**:判断是否有步骤失败并记录错误。
9. **SNS Notification for Failure**:若 Choice 捕获到错误,发送失败通知。
10. **Fail step**:若存在错误,将步骤函数标记为失败。
11. **Pass step**:若无错误,标记步骤函数执行成功。
12. **End**:结束步骤函数执行。
## 告警与监控
1. 若任务失败,会向 SNS 配置中的邮箱发送告警。
2. 若需重启任务,需手动从 EventBridge 触发。
3. 若为历史加载且 `full_load` 设为 `true`,将加载全部数据。
4. 若执行引擎为 `emr-serverless`,也会发送任务提交通知。
## Dynamo DB 表详情
1. **asl-etl-framework-ddb-table-details**:查找表,存储所有 DynamoDB 表及其键信息。
2. **asl-etl-framework-ocsf-attribute-mapping**:存储 OCSF 映射详情。
3. **asl-etl-framework-ocsf-reference**:存储参考数据(如枚举值),由 Lambda 从 OCSF API 提取并导入。
4. **asl-etl-framework-ocsf-run-status**:检查点表,维护任务运行状态。任务完成后,`load_completed` 列设为 `true`。
5. **asl-etl-framework-source-ocsf-metadata**:存储用户 CSV 输入的元数据。
# 常见问题与故障排除
## 加载历史数据
历史加载可按月处理。用户可提供 `load_start_date` 和 `load_end_date`,或提供 `days_to_process`。基于这些日期,框架计算需要处理的月份,并行执行每个月的转换。
以下为示例场景:
**场景 1:用户提供 `days_to_process` 且 `full_load` 为 false**
* EventBridge 输入:
{
“source_type”:“s3-access-log”,
“load_type“:”historical“,
“full_load”:“false”
}
* 元数据 CSV 内容:
1. `days_to_process`:“35”
2. `historical_load_start_date`:空
3. `historical_load_end_date`:空
此时 `historical_load_start_date` 和 `historical_load_end_date` 可留空。框架会回溯 `days_to_process` 指定的天数计算起始日期,结束日期为当前日期,并计算两者之间的月份数,然后并行触发 Glue/EMR 作业。
例如,若计算出 5 个月的数据,则会触发 5 个并行的 Glue/EMR 作业。
**场景 2:用户提供 `days_to_process` 且 `full_load` 为 true**
与场景 1 类似,但 `full_load` 标志不同。框架会维护已处理月份的检查点。失败时仅重试未处理的月份。
若需强制从开始加载全部数据,可在 EventBridge JSON 负载中将 `full_load` 设为 `true`,这将忽略检查点并重新加载所有月份。
**场景 3:用户提供 `historical_load_start_date` 和 `historical_load_end_date` 且 `full_load` 为 false**
* EventBridge 输入:
{
“source_type”:“s3-access-log”,
“load_type“:”historical“,
“full_load”:“false”
}
* 元数据 CSV 内容:
1. `days_to_process`:空
2. `historical_load_start_date`:“2023-05-22”
3. `historical_load_end_date`:“2023-06-22”
此时 `days_to_process` 可留空。框架计算两日期之间的月份数并并行处理。
例如,框架会触发两个 Glue/EMR 作业,输入分别为 “2023-05” 和 “2023-06”。
**场景 4:用户提供 `historical_load_start_date` 和 `historical_load_end_date` 且 `full_load` 为 true**
与场景 3 类似,但 `full_load` 标志不同。框架维护检查点,失败时仅重试未处理月份。
若需强制从开始加载全部数据,可将 `full_load` 设为 ``,忽略检查点并重新加载所有月份。
**场景 5:用户同时提供 `days_to_process`、`historical_load_start_date` 和 `historical_load_end_date`**
此时忽略 `historical_load_start_date` 和 `historical_load_end_date`,按场景 1 处理。
## 什么是 Enrichment,我如何使用它?
Enrichment 是使用 JDBC 数据源(本地/AWS)的数据来丰富最终 OCSF Parquet 数据集的过程。用户需在元数据 CSV 中提供以下字段:
1. **is_enrichment_required**:设为 `"true"`。
2. **enrichment_column**:需要 Enrichment 的源列。
3. **enrichment_col_db**:JDBC 数据源中的对应列。
4. **enrichment_db**:JDBC 数据库名称。
5. **enrichment_table**:源表名称。
6. **enrichment_identifier**:Secrets Manager 中包含数据库用户名、密码及 JDBC 信息的字符串。
还需预先配置 VPC 和安全组,其中安全组需包含自引用入站规则。当前框架要求所有资源在同一 VPC 中运行;若数据库位于 AWS VPC,Glue 或 EMR 作业也应在同一 VPC 中。
## 如何更改 Spark Submit 配置?
1. 对于 `glue` 执行引擎,可在 CDK 代码中修改或添加 Glue 参数以调整 Spark 配置。
2. 对于 `emr-serverless`,Spark 提交参数存储在 `config.py`(CDK 根目录),修改后重新部署 CDK。
3. 可根据用例调整 EMR Serverless 应用的“预初始化容量”以优化性能。
## 建议
1. 在典型 ETL 用例中,建议将大量小文件合并为更少的大文件。可参考 [aws-glue-blueprint-libs 中的压缩示例](https://github.com/awslabs/aws-glue-blueprint-libs/tree/master/samples/compaction) 使用自定义压缩脚本。
2. 历史加载推荐使用 EMR 以获得更好性能。
3. 对于 EMR,可基于数据量和用例调整 Spark 配置,具体步骤参见“如何更改 Spark 提交配置?”一节。
## 限制与变通方案
1. 框架当前每个源仅支持单一 OCSF 类映射。若单个源涉及多个 OCSF 类映射,可将每个映射的数据存储在存储桶的不同前缀下,并分别为每个前缀使用框架作为独立源。
2. 若日志为 gzip 压缩格式,Spark 并行处理可能受影响导致性能下降。建议在使用本框架前解压文件。可参考以下工具进行解压:https://gitlab.aws.dev/prtkumar/gzip-decompression-utility
标签:AMSI绕过, AWS CDK, CloudFormation, DynamoDB, EMR, ETL框架, Glue, Lambda, OCSF, S3, SNS, Spark, VPC, 丰富化, 企业安全, 历史数据, 威胁检测, 安全合规, 安全日志, 安全湖, 安全组, 弹性IP, 批处理, 数据加载, 数据转换, 无服务器, 日志聚合, 日志转换, 步骤函数, 漏洞探索, 特权提升, 监控告警, 网络代理, 网络资产管理, 网络隔离, 自动化部署, 逆向工具, 配置驱动