Kim-Hammar/llm_incident_response_ndss26
GitHub: Kim-Hammar/llm_incident_response_ndss26
利用轻量级大型语言模型实现应急响应规划。
Stars: 18 | Forks: 1
# 使用轻量级大型语言模型降低幻觉的应急响应规划
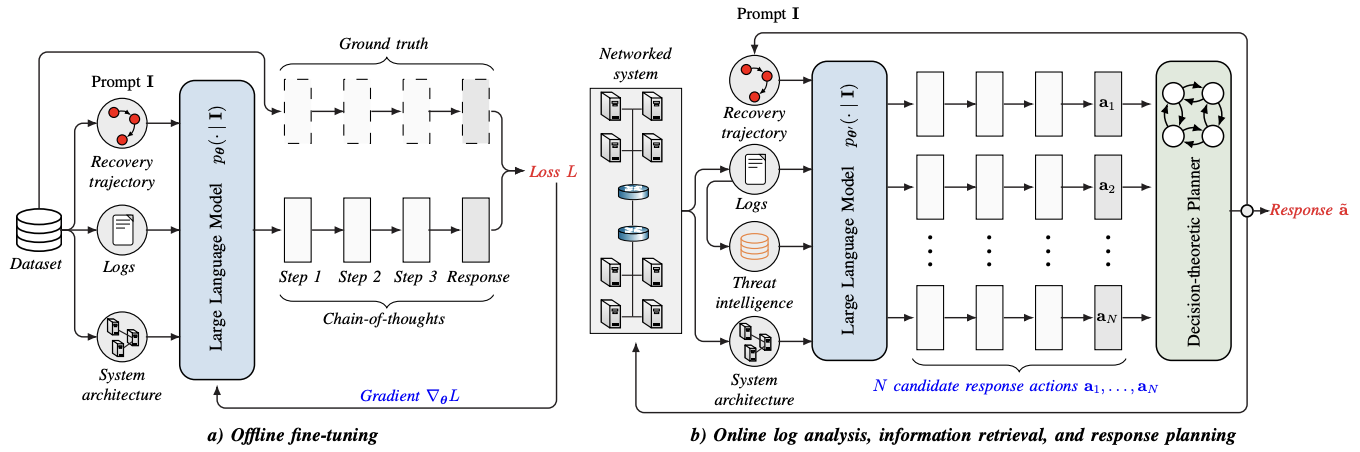
本存储库包含与论文 *"使用轻量级大型语言模型降低幻觉的应急响应规划"* 相关的工件,该论文已被 The Network and Distributed System Security (NDSS) Symposium 2026 接受。
我们介绍了一种新颖的方法,该方法使大型语言模型 (LLM) 能够有效地用于为应急响应规划提供决策支持。我们的方法使用 LLM 将系统日志转换为有效的响应计划,并通过微调、信息检索和决策理论规划来解决其局限性。与以往依赖于前沿模型提示工程的工作不同,我们的方法轻量级且可在通用硬件上运行。
Creative Commons (C) 2025, Kim Hammar, Tansu Alpcan 和 Emil Lupu
Made with ❤
at
 and
and

标签:Apex, Hugging Face, IaC 扫描, NDSS, Python, 人工智能, 代码示例, 信息检索, 决策支持, 凭据扫描, 大型语言模型, 安全事件, 库, 应急响应, 开源, 技术栈, 数据分析, 无后门, 机器学习, 模型微调, 模型权重, 用户模式Hook绕过, 网络安全, 视频演示, 逆向工具, 隐私保护