karpathy/nanochat
GitHub: karpathy/nanochat
一个极简的 LLM 端到端训练框架,以不到100美元的成本完成从预训练到聊天部署的全流程。
Stars: 55070 | Forks: 7507
# nanochat
nanochat 是用于训练 LLM 的最简单的实验框架。它设计为在单个 GPU 节点上运行,代码极简且易于修改,涵盖了所有主要的 LLM 阶段,包括 tokenization、pretraining、finetuning、evaluation、inference 和聊天 UI。例如,你只需花费约 $48(约 2 小时的 8XH100 GPU 节点时间)即可训练出具有 GPT-2 能力的 LLM(2019 年训练成本约为 $43,000),然后在熟悉的类 ChatGPT Web UI 中与它对话。在 spot instance 上,总成本可能更接近 ~$15。更一般地说,nanochat 开箱即配置,只需设置一个复杂度旋钮即可训练整个计算优化模型系列:`--depth`,即 GPT transformer 模型中的层数(GPT-2 能力大约对应 depth 26)。所有其他超参数(transformer 的宽度、head 数量、learning rate 调整、训练时长、weight decay 等)都会以最优方式自动计算。
关于此仓库的问题,我推荐使用 Devin/Cognition 的 [DeepWiki](https://deepwiki.com/karpathy/nanochat) 询问关于该仓库的问题,或者使用 [Discussions tab](https://github.com/karpathy/nanochat/discussions),或者来 Discord 的 [#nanochat](https://discord.com/channels/1020383067459821711/1427295580895314031) 频道。
## Time-to-GPT-2 排行榜
目前,开发的主要重点是调整 pretraining 阶段,这需要最多的计算量。受 modded-nanogpt 仓库启发,为了激励进步和社区协作,nanochat 维护了一个 "GPT-2 speedrun" 排行榜,即训练 nanochat 模型达到 GPT-2 级别能力所需的墙上时钟时间,由 DCLM CORE 分数衡量。[runs/speedrun.sh](runs/speedrun.sh) 脚本始终代表训练 GPT-2 级别模型并与它对话的参考方法。当前的排行榜如下:
| # | time | val_bpb | CORE | Description | Date | Commit | Contributors |
|---|-------------|---------|------|-------------|------|--------|--------------|
| 0 | 168 hours | - | 0.2565 | Original OpenAI GPT-2 checkpoint | 2019 | - | OpenAI |
| 1 | 3.04 | 0.74833 | 0.2585 | d24 baseline, slightly overtrained | Jan 29 2026 | 348fbb3 | @karpathy |
| 2 | 2.91 | 0.74504 | 0.2578 | d26 slightly undertrained **+fp8** | Feb 2 2026 | a67eba3 | @karpathy |
| 3 | 2.76 | 0.74645 | 0.2602 | bump total batch size to 1M tokens | Feb 5 2026 | 2c062aa | @karpathy |
| 4 | 2.02 | 0.71854 | 0.2571 | change dataset to NVIDIA ClimbMix | Mar 4 2026 | 324e69c | @ddudek @karpathy |
我们关注的主要指标是 "time to GPT-2" —— 在 8XH100 GPU 节点上超越 GPT-2 (1.6B) CORE 指标所需的墙上时钟时间。GPT-2 CORE 分数是 0.256525。2019 年,GPT-2 的训练成本约为 $43,000,令人惊叹的是,由于 7 年来全栈的许多进步,我们现在可以快得多地完成,且成本远低于 $100(例如,按目前约 $3/GPU/hr 计算,8XH100 节点约为 ~$24/hr,所以 2 小时约为 ~$48)。
有关如何解读和贡献排行榜的更多文档,请参阅 [dev/LEADERBOARD.md](dev/LEADERBOARD.md)。
## 开始使用
### 复现并与 GPT-2 对话
最有趣的事情是训练你自己的 GPT-2 并与它对话。这样做的整个 pipeline 包含在单个文件 [runs/speedrun.sh](runs/speedrun.sh) 中,该文件设计为在 8XH100 GPU 节点上运行。从你喜欢的提供商那里启动一个新的 8XH100 GPU 机器(例如我使用并喜欢 [Lambda](https://lambda.ai/service/gpu-cloud)),然后启动训练脚本:
```
bash runs/speedrun.sh
```
你可能希望在 screen session 中执行此操作,因为运行大约需要 ~3 小时。完成后,你可以通过类 ChatGPT Web UI 与它对话。再次确保你的本地 uv 虚拟环境处于活动状态(运行 `source .venv/bin/activate`),然后提供服务:
```
python -m scripts.chat_web
```
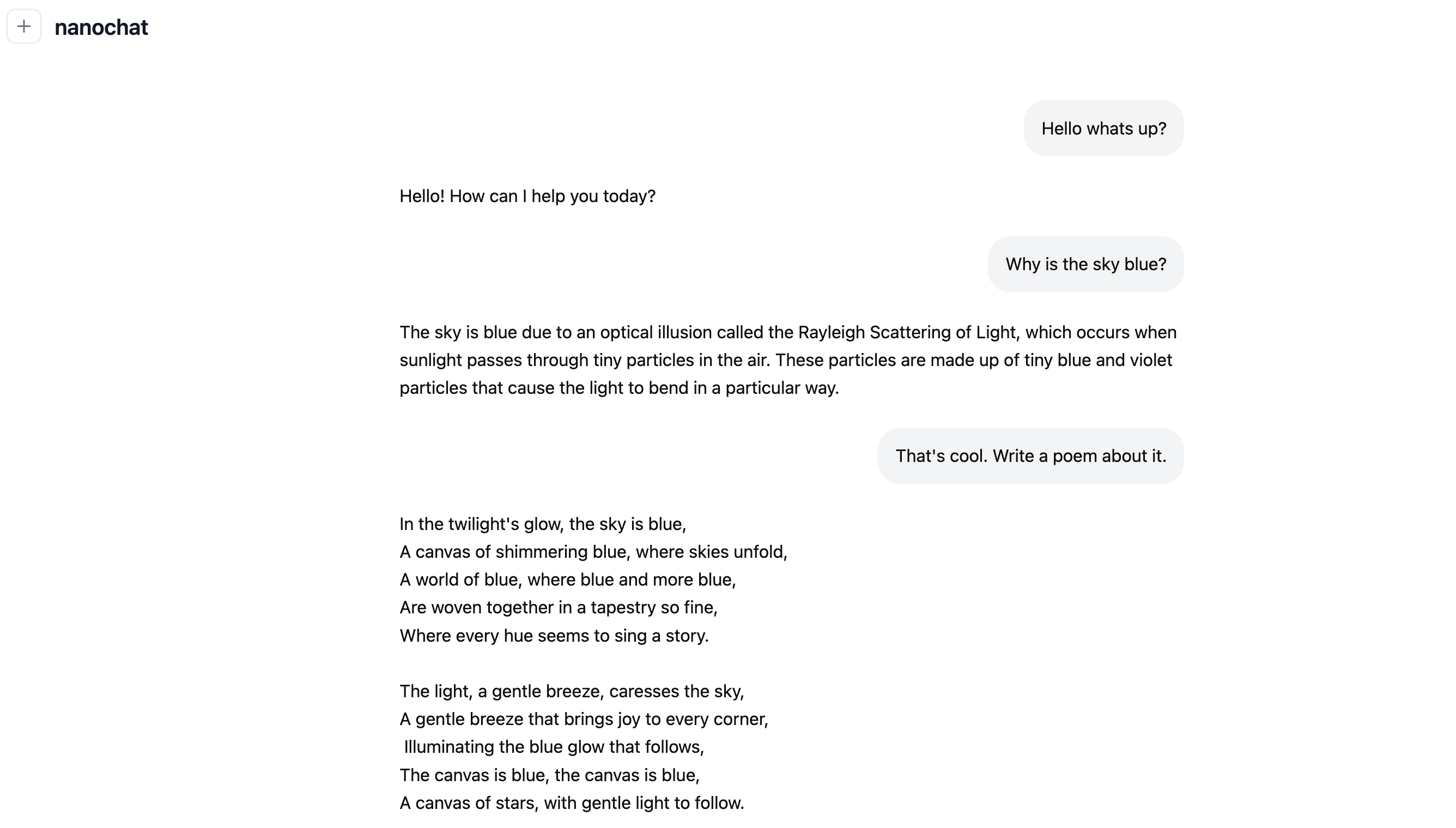
然后访问显示的 URL。确保正确访问它,例如在 Lambda 上使用你所在节点的 public IP,后跟端口,例如 [http://209.20.xxx.xxx:8000/](http://209.20.xxx.xxx:8000/) 等。然后像平时与 ChatGPT 对话一样与你的 LLM 对话!让它写故事或诗歌。让它告诉你你是谁以观察幻觉。问它为什么天空是蓝色的。或者为什么它是绿色的。Speedrun 是一个 4e19 FLOPs 能力的模型,所以有点像在和一个幼儿园小朋友说话 :)。
 还有一些说明:
- 代码在 Ampere 8XA100 GPU 节点上也能正常运行,但会慢一些。
- 即使在单个 GPU 上,所有代码也能正常运行,只需省略 `torchrun`,并会产生 ~相同的结果(代码会自动切换到 gradient accumulation),但你必须等待 8 倍的时间。
- 如果你的 GPU 显存少于 80GB,你将需要调整一些超参数,否则你会 OOM / VRAM 耗尽。在脚本中查找 `--device_batch_size` 并减小它直到适合。例如从 32(默认)到 16、8、4、2,甚至 1。如果比这更小,你需要更了解自己在做什么并更有创意。
- 大多数代码都是相当原生的 PyTorch,因此它应该在支持它的任何平台上运行 —— xpu、mps 等,但我个人没有测试所有这些代码路径,所以可能存在一些尖锐的边缘。
## 研究
如果你是研究人员并希望帮助改进 nanochat,两个感兴趣的脚本是 [runs/scaling_laws.sh](runs/scaling_laws.sh) 和 [runs/miniseries.sh](runs/miniseries.sh)。有关相关文档,请参阅 [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420)。对于快速实验(~5 分钟 pretraining 运行),我最喜欢的规模是训练一个 12 层模型(GPT-1 大小),例如像这样:
```
OMP_NUM_THREADS=1 torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- \
--depth=12 \
--run="d12" \
--model-tag="d12" \
--core-metric-every=999999 \
--sample-every=-1 \
--save-every=-1 \
```
这使用 wandb(运行名称 "d12"),只在最后一步运行 CORE 指标,并且不采样和保存中间 checkpoint。我喜欢在代码中更改某些内容,重新运行 d12(或 d16 等),看看是否有帮助,在一个迭代循环中。要查看运行是否有帮助,我喜欢监控 wandb 图表:
1. `val_bpb`(以 vocab-size-invariant 单位 bits per byte 表示的验证损失)作为 `step`、`total_training_time` 和 `total_training_flops` 的函数。
2. `core_metric`(DCLM CORE 分数)
3. VRAM 利用率、`train/mfu`(Model FLOPS utilization)、`train/tok_per_sec`(训练吞吐量)
在此处查看示例 [here](https://github.com/karpathy/nanochat/pull/498#issuecomment-3850720044)。
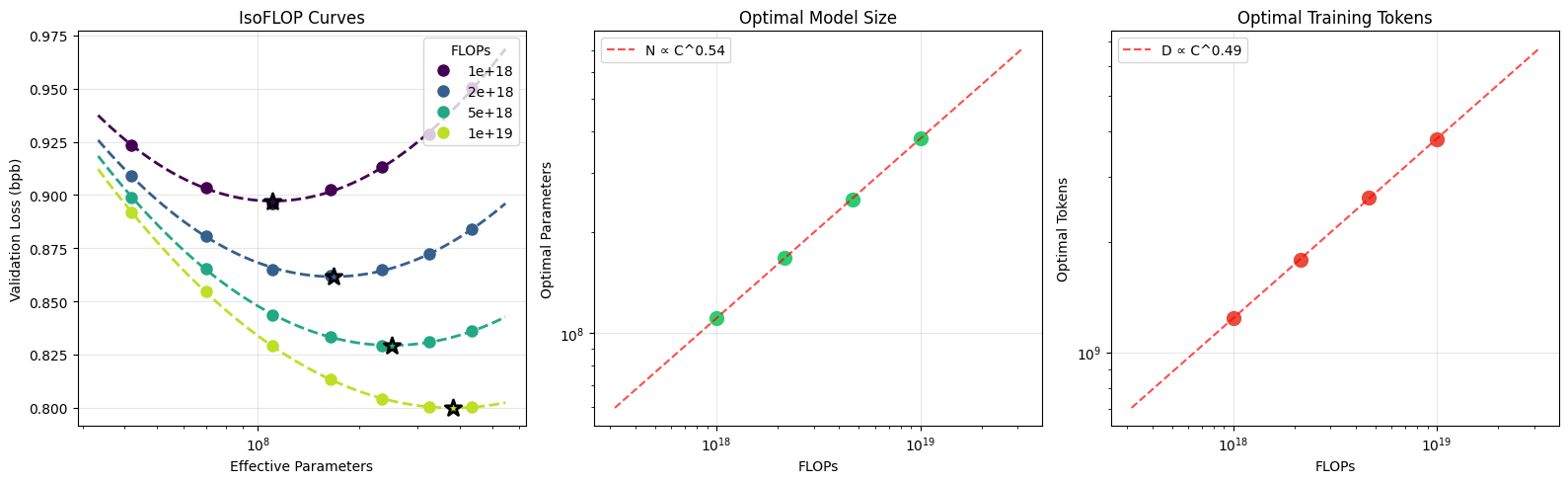
需要注意的重要一点是,nanochat 是围绕一个单一的复杂度旋钮编写的 —— transformer 的深度。这个单一的整数自动确定所有其他超参数(transformer 的宽度、head 数量、learning rate 调整、训练时长、weight decay 等),以便训练出的模型是计算最优的。其想法是用户不必考虑或设置任何这些,他们只是使用 `--depth` 要求一个更小或更大的模型,一切 "正常工作"。通过扫描 depth,你可以获得各种尺寸的 nanochat 计算最优模型 miniseries。GPT-2 能力模型(目前最感兴趣的)恰好处于当前代码的 d24-d26 范围内。但是,对仓库的任何候选更改都必须有原则,以便它们适用于所有 depth 设置。
## 在 CPU / MPS 上运行
脚本 [runs/runcpu.sh](runs/runcpu.sh) 展示了在 CPU 或 Apple Silicon 上运行的一个非常简单的示例。它大幅缩减了正在训练的 LLM,以便在几十分钟的训练时间内完成。你不会通过这种方式获得强大的结果。
## 精度 / dtype
nanochat 不使用 `torch.amp.autocast`。相反,precision 通过单个全局 `COMPUTE_DTYPE`(在 `nanochat/common.py` 中定义)显式管理。默认情况下,这是根据你的硬件自动检测的:
| Hardware | Default dtype | Why |
|----------|--------------|-----|
| CUDA SM 80+ (A100, H100, ...) | `bfloat16` | Native bf16 tensor cores |
| CUDA SM < 80 (V100, T4, ...) | `float32` | No bf16; fp16 available via `NANOCHAT_DTYPE=float16` (uses GradScaler) |
| CPU / MPS | `float32` | No reduced-precision tensor cores |
你可以使用 `NANOCHAT_DTYPE` 环境变量覆盖默认值:
```
NANOCHAT_DTYPE=float32 python -m scripts.chat_cli -p "hello" # force fp32
NANOCHAT_DTYPE=bfloat16 torchrun --nproc_per_node=8 -m scripts.base_train # force bf16
```
工作原理:模型权重以 fp32 存储(为了 optimizer precision),但我们的自定义 `Linear` 层在前向传递期间将它们转换为 `COMPUTE_DTYPE`。Embedding 直接以 `COMPUTE_DTYPE` 存储以节省内存。这为我们提供了与 autocast 相同的 mixed-precision 好处,但对以哪种 precision 运行什么拥有完全的显式控制。
注意:`float16` 训练在 `base_train.py` 中自动启用 `GradScaler` 以防止 gradient underflow。SFT 也支持这一点,但 RL 目前不支持。fp16 中的 inference 在任何地方都可以正常工作。
## 指南
我发布了一些可能包含有用信息的指南,从最近到最旧:
- [Feb 1 2026: Beating GPT-2 for <<$100: the nanochat journey](https://github.com/karpathy/nanochat/discussions/481)
- [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420) 记录了第一个 nanochat 模型 miniseries。
- 要向 nanochat 添加新能力,请参阅 [Guide: counting r in strawberry (and how to add abilities generally)](https://github.com/karpathy/nanochat/discussions/164)。
- 要自定义你的 nanochat,请参阅 Discussions 中的 [Guide: infusing identity to your nanochat](https://github.com/karpathy/nanochat/discussions/139),其中描述了如何通过合成数据生成调整 nanochat 的个性,并将该数据混合到 SFT 阶段中。
- [Oct 13 2025: original nanochat post](https://github.com/karpathy/nanochat/discussions/1) 介绍了 nanochat,但现在它包含一些已弃用的信息,并且模型比当前的 master 旧得多(结果也更差)。
## 文件结构
```
.
├── LICENSE
├── README.md
├── dev
│ ├── gen_synthetic_data.py # Example synthetic data for identity
│ ├── generate_logo.html
│ ├── nanochat.png
│ └── repackage_data_reference.py # Pretraining data shard generation
├── nanochat
│ ├── __init__.py # empty
│ ├── checkpoint_manager.py # Save/Load model checkpoints
│ ├── common.py # Misc small utilities, quality of life
│ ├── core_eval.py # Evaluates base model CORE score (DCLM paper)
│ ├── dataloader.py # Tokenizing Distributed Data Loader
│ ├── dataset.py # Download/read utils for pretraining data
│ ├── engine.py # Efficient model inference with KV Cache
│ ├── execution.py # Allows the LLM to execute Python code as tool
│ ├── gpt.py # The GPT nn.Module Transformer
│ ├── logo.svg
│ ├── loss_eval.py # Evaluate bits per byte (instead of loss)
│ ├── optim.py # AdamW + Muon optimizer, 1GPU and distributed
│ ├── report.py # Utilities for writing the nanochat Report
│ ├── tokenizer.py # BPE Tokenizer wrapper in style of GPT-4
│ └── ui.html # HTML/CSS/JS for nanochat frontend
├── pyproject.toml
├── runs
│ ├── miniseries.sh # Miniseries training script
│ ├── runcpu.sh # Small example of how to run on CPU/MPS
│ ├── scaling_laws.sh # Scaling laws experiments
│ └── speedrun.sh # Train the ~$100 nanochat d20
├── scripts
│ ├── base_eval.py # Base model: CORE score, bits per byte, samples
│ ├── base_train.py # Base model: train
│ ├── chat_cli.py # Chat model: talk to over CLI
│ ├── chat_eval.py # Chat model: eval tasks
│ ├── chat_rl.py # Chat model: reinforcement learning
│ ├── chat_sft.py # Chat model: train SFT
│ ├── chat_web.py # Chat model: talk to over WebUI
│ ├── tok_eval.py # Tokenizer: evaluate compression rate
│ └── tok_train.py # Tokenizer: train it
├── tasks
│ ├── arc.py # Multiple choice science questions
│ ├── common.py # TaskMixture | TaskSequence
│ ├── customjson.py # Make Task from arbitrary jsonl convos
│ ├── gsm8k.py # 8K Grade School Math questions
│ ├── humaneval.py # Misnomer; Simple Python coding task
│ ├── mmlu.py # Multiple choice questions, broad topics
│ ├── smoltalk.py # Conglomerate dataset of SmolTalk from HF
│ └── spellingbee.py # Task teaching model to spell/count letters
├── tests
│ └── test_engine.py
└── uv.lock
```
## 贡献
nanochat 的目标是改进 micro models 的最新技术,这些模型可以在 < $1000 的预算下端到端地工作。可访问性既关乎总体成本,也关乎认知复杂性 —— nanochat 不是一个可详尽配置的 LLM "framework";代码库中没有巨大的配置对象、model factory 或 if-then-else 巨兽。它是一个单一、内聚、极简、可读、可修改、可最大程度 fork 的 "strong baseline" 代码库,旨在从头到尾运行并生成你可以与之对话的 ChatGPT 模型。目前,个人最有趣的部分是加快 latency to GPT-2(即获得高于 0.256525 的 CORE 分数)。目前这大约需要 ~3 小时,但通过改进 pretraining 阶段,我们可以进一步改善这一点。
当前 AI 政策:披露。提交 PR 时,请声明任何有大量 LLM 贡献且你未编写或你不完全理解的部分。
## 致谢
- 这个名字 来自我之前的项目 [nanoGPT](https://github.com/karpathy/nanoGPT),它只涵盖了 pretraining。
- nanochat 也受到 [modded-nanoGPT](https://github.com/KellerJordan/modded-nanogpt) 的启发,该项目用明确的指标和排行榜将 nanoGPT 仓库游戏化,并借鉴了其许多想法和一些 pretraining 实现。
- 感谢 [HuggingFace](https://huggingface.co/) 提供 fineweb 和 smoltalk。
- 感谢 [Lambda](https://lambda.ai/service/gpu-cloud) 提供用于开发此项目的计算资源。
- 感谢首席 LLM whisperer 🧙♂️ Alec Radford 的建议/指导。
- 感谢仓库主管 Sofie [@svlandeg](https://github.com/svlandeg) 帮助管理 nanochat 的 issues、pull requests 和 discussions。
## 引用
如果你发现 nanochat 对你的研究有帮助,请简单引用为:
```
@misc{nanochat,
author = {Andrej Karpathy},
title = {nanochat: The best ChatGPT that \$100 can buy},
year = {2025},
publisher = {GitHub},
url = {https://github.com/karpathy/nanochat}
}
```
## 许可证
MIT
还有一些说明:
- 代码在 Ampere 8XA100 GPU 节点上也能正常运行,但会慢一些。
- 即使在单个 GPU 上,所有代码也能正常运行,只需省略 `torchrun`,并会产生 ~相同的结果(代码会自动切换到 gradient accumulation),但你必须等待 8 倍的时间。
- 如果你的 GPU 显存少于 80GB,你将需要调整一些超参数,否则你会 OOM / VRAM 耗尽。在脚本中查找 `--device_batch_size` 并减小它直到适合。例如从 32(默认)到 16、8、4、2,甚至 1。如果比这更小,你需要更了解自己在做什么并更有创意。
- 大多数代码都是相当原生的 PyTorch,因此它应该在支持它的任何平台上运行 —— xpu、mps 等,但我个人没有测试所有这些代码路径,所以可能存在一些尖锐的边缘。
## 研究
如果你是研究人员并希望帮助改进 nanochat,两个感兴趣的脚本是 [runs/scaling_laws.sh](runs/scaling_laws.sh) 和 [runs/miniseries.sh](runs/miniseries.sh)。有关相关文档,请参阅 [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420)。对于快速实验(~5 分钟 pretraining 运行),我最喜欢的规模是训练一个 12 层模型(GPT-1 大小),例如像这样:
```
OMP_NUM_THREADS=1 torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- \
--depth=12 \
--run="d12" \
--model-tag="d12" \
--core-metric-every=999999 \
--sample-every=-1 \
--save-every=-1 \
```
这使用 wandb(运行名称 "d12"),只在最后一步运行 CORE 指标,并且不采样和保存中间 checkpoint。我喜欢在代码中更改某些内容,重新运行 d12(或 d16 等),看看是否有帮助,在一个迭代循环中。要查看运行是否有帮助,我喜欢监控 wandb 图表:
1. `val_bpb`(以 vocab-size-invariant 单位 bits per byte 表示的验证损失)作为 `step`、`total_training_time` 和 `total_training_flops` 的函数。
2. `core_metric`(DCLM CORE 分数)
3. VRAM 利用率、`train/mfu`(Model FLOPS utilization)、`train/tok_per_sec`(训练吞吐量)
在此处查看示例 [here](https://github.com/karpathy/nanochat/pull/498#issuecomment-3850720044)。
需要注意的重要一点是,nanochat 是围绕一个单一的复杂度旋钮编写的 —— transformer 的深度。这个单一的整数自动确定所有其他超参数(transformer 的宽度、head 数量、learning rate 调整、训练时长、weight decay 等),以便训练出的模型是计算最优的。其想法是用户不必考虑或设置任何这些,他们只是使用 `--depth` 要求一个更小或更大的模型,一切 "正常工作"。通过扫描 depth,你可以获得各种尺寸的 nanochat 计算最优模型 miniseries。GPT-2 能力模型(目前最感兴趣的)恰好处于当前代码的 d24-d26 范围内。但是,对仓库的任何候选更改都必须有原则,以便它们适用于所有 depth 设置。
## 在 CPU / MPS 上运行
脚本 [runs/runcpu.sh](runs/runcpu.sh) 展示了在 CPU 或 Apple Silicon 上运行的一个非常简单的示例。它大幅缩减了正在训练的 LLM,以便在几十分钟的训练时间内完成。你不会通过这种方式获得强大的结果。
## 精度 / dtype
nanochat 不使用 `torch.amp.autocast`。相反,precision 通过单个全局 `COMPUTE_DTYPE`(在 `nanochat/common.py` 中定义)显式管理。默认情况下,这是根据你的硬件自动检测的:
| Hardware | Default dtype | Why |
|----------|--------------|-----|
| CUDA SM 80+ (A100, H100, ...) | `bfloat16` | Native bf16 tensor cores |
| CUDA SM < 80 (V100, T4, ...) | `float32` | No bf16; fp16 available via `NANOCHAT_DTYPE=float16` (uses GradScaler) |
| CPU / MPS | `float32` | No reduced-precision tensor cores |
你可以使用 `NANOCHAT_DTYPE` 环境变量覆盖默认值:
```
NANOCHAT_DTYPE=float32 python -m scripts.chat_cli -p "hello" # force fp32
NANOCHAT_DTYPE=bfloat16 torchrun --nproc_per_node=8 -m scripts.base_train # force bf16
```
工作原理:模型权重以 fp32 存储(为了 optimizer precision),但我们的自定义 `Linear` 层在前向传递期间将它们转换为 `COMPUTE_DTYPE`。Embedding 直接以 `COMPUTE_DTYPE` 存储以节省内存。这为我们提供了与 autocast 相同的 mixed-precision 好处,但对以哪种 precision 运行什么拥有完全的显式控制。
注意:`float16` 训练在 `base_train.py` 中自动启用 `GradScaler` 以防止 gradient underflow。SFT 也支持这一点,但 RL 目前不支持。fp16 中的 inference 在任何地方都可以正常工作。
## 指南
我发布了一些可能包含有用信息的指南,从最近到最旧:
- [Feb 1 2026: Beating GPT-2 for <<$100: the nanochat journey](https://github.com/karpathy/nanochat/discussions/481)
- [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420) 记录了第一个 nanochat 模型 miniseries。
- 要向 nanochat 添加新能力,请参阅 [Guide: counting r in strawberry (and how to add abilities generally)](https://github.com/karpathy/nanochat/discussions/164)。
- 要自定义你的 nanochat,请参阅 Discussions 中的 [Guide: infusing identity to your nanochat](https://github.com/karpathy/nanochat/discussions/139),其中描述了如何通过合成数据生成调整 nanochat 的个性,并将该数据混合到 SFT 阶段中。
- [Oct 13 2025: original nanochat post](https://github.com/karpathy/nanochat/discussions/1) 介绍了 nanochat,但现在它包含一些已弃用的信息,并且模型比当前的 master 旧得多(结果也更差)。
## 文件结构
```
.
├── LICENSE
├── README.md
├── dev
│ ├── gen_synthetic_data.py # Example synthetic data for identity
│ ├── generate_logo.html
│ ├── nanochat.png
│ └── repackage_data_reference.py # Pretraining data shard generation
├── nanochat
│ ├── __init__.py # empty
│ ├── checkpoint_manager.py # Save/Load model checkpoints
│ ├── common.py # Misc small utilities, quality of life
│ ├── core_eval.py # Evaluates base model CORE score (DCLM paper)
│ ├── dataloader.py # Tokenizing Distributed Data Loader
│ ├── dataset.py # Download/read utils for pretraining data
│ ├── engine.py # Efficient model inference with KV Cache
│ ├── execution.py # Allows the LLM to execute Python code as tool
│ ├── gpt.py # The GPT nn.Module Transformer
│ ├── logo.svg
│ ├── loss_eval.py # Evaluate bits per byte (instead of loss)
│ ├── optim.py # AdamW + Muon optimizer, 1GPU and distributed
│ ├── report.py # Utilities for writing the nanochat Report
│ ├── tokenizer.py # BPE Tokenizer wrapper in style of GPT-4
│ └── ui.html # HTML/CSS/JS for nanochat frontend
├── pyproject.toml
├── runs
│ ├── miniseries.sh # Miniseries training script
│ ├── runcpu.sh # Small example of how to run on CPU/MPS
│ ├── scaling_laws.sh # Scaling laws experiments
│ └── speedrun.sh # Train the ~$100 nanochat d20
├── scripts
│ ├── base_eval.py # Base model: CORE score, bits per byte, samples
│ ├── base_train.py # Base model: train
│ ├── chat_cli.py # Chat model: talk to over CLI
│ ├── chat_eval.py # Chat model: eval tasks
│ ├── chat_rl.py # Chat model: reinforcement learning
│ ├── chat_sft.py # Chat model: train SFT
│ ├── chat_web.py # Chat model: talk to over WebUI
│ ├── tok_eval.py # Tokenizer: evaluate compression rate
│ └── tok_train.py # Tokenizer: train it
├── tasks
│ ├── arc.py # Multiple choice science questions
│ ├── common.py # TaskMixture | TaskSequence
│ ├── customjson.py # Make Task from arbitrary jsonl convos
│ ├── gsm8k.py # 8K Grade School Math questions
│ ├── humaneval.py # Misnomer; Simple Python coding task
│ ├── mmlu.py # Multiple choice questions, broad topics
│ ├── smoltalk.py # Conglomerate dataset of SmolTalk from HF
│ └── spellingbee.py # Task teaching model to spell/count letters
├── tests
│ └── test_engine.py
└── uv.lock
```
## 贡献
nanochat 的目标是改进 micro models 的最新技术,这些模型可以在 < $1000 的预算下端到端地工作。可访问性既关乎总体成本,也关乎认知复杂性 —— nanochat 不是一个可详尽配置的 LLM "framework";代码库中没有巨大的配置对象、model factory 或 if-then-else 巨兽。它是一个单一、内聚、极简、可读、可修改、可最大程度 fork 的 "strong baseline" 代码库,旨在从头到尾运行并生成你可以与之对话的 ChatGPT 模型。目前,个人最有趣的部分是加快 latency to GPT-2(即获得高于 0.256525 的 CORE 分数)。目前这大约需要 ~3 小时,但通过改进 pretraining 阶段,我们可以进一步改善这一点。
当前 AI 政策:披露。提交 PR 时,请声明任何有大量 LLM 贡献且你未编写或你不完全理解的部分。
## 致谢
- 这个名字 来自我之前的项目 [nanoGPT](https://github.com/karpathy/nanoGPT),它只涵盖了 pretraining。
- nanochat 也受到 [modded-nanoGPT](https://github.com/KellerJordan/modded-nanogpt) 的启发,该项目用明确的指标和排行榜将 nanoGPT 仓库游戏化,并借鉴了其许多想法和一些 pretraining 实现。
- 感谢 [HuggingFace](https://huggingface.co/) 提供 fineweb 和 smoltalk。
- 感谢 [Lambda](https://lambda.ai/service/gpu-cloud) 提供用于开发此项目的计算资源。
- 感谢首席 LLM whisperer 🧙♂️ Alec Radford 的建议/指导。
- 感谢仓库主管 Sofie [@svlandeg](https://github.com/svlandeg) 帮助管理 nanochat 的 issues、pull requests 和 discussions。
## 引用
如果你发现 nanochat 对你的研究有帮助,请简单引用为:
```
@misc{nanochat,
author = {Andrej Karpathy},
title = {nanochat: The best ChatGPT that \$100 can buy},
year = {2025},
publisher = {GitHub},
url = {https://github.com/karpathy/nanochat}
}
```
## 许可证
MIT
还有一些说明:
- 代码在 Ampere 8XA100 GPU 节点上也能正常运行,但会慢一些。
- 即使在单个 GPU 上,所有代码也能正常运行,只需省略 `torchrun`,并会产生 ~相同的结果(代码会自动切换到 gradient accumulation),但你必须等待 8 倍的时间。
- 如果你的 GPU 显存少于 80GB,你将需要调整一些超参数,否则你会 OOM / VRAM 耗尽。在脚本中查找 `--device_batch_size` 并减小它直到适合。例如从 32(默认)到 16、8、4、2,甚至 1。如果比这更小,你需要更了解自己在做什么并更有创意。
- 大多数代码都是相当原生的 PyTorch,因此它应该在支持它的任何平台上运行 —— xpu、mps 等,但我个人没有测试所有这些代码路径,所以可能存在一些尖锐的边缘。
## 研究
如果你是研究人员并希望帮助改进 nanochat,两个感兴趣的脚本是 [runs/scaling_laws.sh](runs/scaling_laws.sh) 和 [runs/miniseries.sh](runs/miniseries.sh)。有关相关文档,请参阅 [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420)。对于快速实验(~5 分钟 pretraining 运行),我最喜欢的规模是训练一个 12 层模型(GPT-1 大小),例如像这样:
```
OMP_NUM_THREADS=1 torchrun --standalone --nproc_per_node=8 -m scripts.base_train -- \
--depth=12 \
--run="d12" \
--model-tag="d12" \
--core-metric-every=999999 \
--sample-every=-1 \
--save-every=-1 \
```
这使用 wandb(运行名称 "d12"),只在最后一步运行 CORE 指标,并且不采样和保存中间 checkpoint。我喜欢在代码中更改某些内容,重新运行 d12(或 d16 等),看看是否有帮助,在一个迭代循环中。要查看运行是否有帮助,我喜欢监控 wandb 图表:
1. `val_bpb`(以 vocab-size-invariant 单位 bits per byte 表示的验证损失)作为 `step`、`total_training_time` 和 `total_training_flops` 的函数。
2. `core_metric`(DCLM CORE 分数)
3. VRAM 利用率、`train/mfu`(Model FLOPS utilization)、`train/tok_per_sec`(训练吞吐量)
在此处查看示例 [here](https://github.com/karpathy/nanochat/pull/498#issuecomment-3850720044)。
需要注意的重要一点是,nanochat 是围绕一个单一的复杂度旋钮编写的 —— transformer 的深度。这个单一的整数自动确定所有其他超参数(transformer 的宽度、head 数量、learning rate 调整、训练时长、weight decay 等),以便训练出的模型是计算最优的。其想法是用户不必考虑或设置任何这些,他们只是使用 `--depth` 要求一个更小或更大的模型,一切 "正常工作"。通过扫描 depth,你可以获得各种尺寸的 nanochat 计算最优模型 miniseries。GPT-2 能力模型(目前最感兴趣的)恰好处于当前代码的 d24-d26 范围内。但是,对仓库的任何候选更改都必须有原则,以便它们适用于所有 depth 设置。
## 在 CPU / MPS 上运行
脚本 [runs/runcpu.sh](runs/runcpu.sh) 展示了在 CPU 或 Apple Silicon 上运行的一个非常简单的示例。它大幅缩减了正在训练的 LLM,以便在几十分钟的训练时间内完成。你不会通过这种方式获得强大的结果。
## 精度 / dtype
nanochat 不使用 `torch.amp.autocast`。相反,precision 通过单个全局 `COMPUTE_DTYPE`(在 `nanochat/common.py` 中定义)显式管理。默认情况下,这是根据你的硬件自动检测的:
| Hardware | Default dtype | Why |
|----------|--------------|-----|
| CUDA SM 80+ (A100, H100, ...) | `bfloat16` | Native bf16 tensor cores |
| CUDA SM < 80 (V100, T4, ...) | `float32` | No bf16; fp16 available via `NANOCHAT_DTYPE=float16` (uses GradScaler) |
| CPU / MPS | `float32` | No reduced-precision tensor cores |
你可以使用 `NANOCHAT_DTYPE` 环境变量覆盖默认值:
```
NANOCHAT_DTYPE=float32 python -m scripts.chat_cli -p "hello" # force fp32
NANOCHAT_DTYPE=bfloat16 torchrun --nproc_per_node=8 -m scripts.base_train # force bf16
```
工作原理:模型权重以 fp32 存储(为了 optimizer precision),但我们的自定义 `Linear` 层在前向传递期间将它们转换为 `COMPUTE_DTYPE`。Embedding 直接以 `COMPUTE_DTYPE` 存储以节省内存。这为我们提供了与 autocast 相同的 mixed-precision 好处,但对以哪种 precision 运行什么拥有完全的显式控制。
注意:`float16` 训练在 `base_train.py` 中自动启用 `GradScaler` 以防止 gradient underflow。SFT 也支持这一点,但 RL 目前不支持。fp16 中的 inference 在任何地方都可以正常工作。
## 指南
我发布了一些可能包含有用信息的指南,从最近到最旧:
- [Feb 1 2026: Beating GPT-2 for <<$100: the nanochat journey](https://github.com/karpathy/nanochat/discussions/481)
- [Jan 7 miniseries v1](https://github.com/karpathy/nanochat/discussions/420) 记录了第一个 nanochat 模型 miniseries。
- 要向 nanochat 添加新能力,请参阅 [Guide: counting r in strawberry (and how to add abilities generally)](https://github.com/karpathy/nanochat/discussions/164)。
- 要自定义你的 nanochat,请参阅 Discussions 中的 [Guide: infusing identity to your nanochat](https://github.com/karpathy/nanochat/discussions/139),其中描述了如何通过合成数据生成调整 nanochat 的个性,并将该数据混合到 SFT 阶段中。
- [Oct 13 2025: original nanochat post](https://github.com/karpathy/nanochat/discussions/1) 介绍了 nanochat,但现在它包含一些已弃用的信息,并且模型比当前的 master 旧得多(结果也更差)。
## 文件结构
```
.
├── LICENSE
├── README.md
├── dev
│ ├── gen_synthetic_data.py # Example synthetic data for identity
│ ├── generate_logo.html
│ ├── nanochat.png
│ └── repackage_data_reference.py # Pretraining data shard generation
├── nanochat
│ ├── __init__.py # empty
│ ├── checkpoint_manager.py # Save/Load model checkpoints
│ ├── common.py # Misc small utilities, quality of life
│ ├── core_eval.py # Evaluates base model CORE score (DCLM paper)
│ ├── dataloader.py # Tokenizing Distributed Data Loader
│ ├── dataset.py # Download/read utils for pretraining data
│ ├── engine.py # Efficient model inference with KV Cache
│ ├── execution.py # Allows the LLM to execute Python code as tool
│ ├── gpt.py # The GPT nn.Module Transformer
│ ├── logo.svg
│ ├── loss_eval.py # Evaluate bits per byte (instead of loss)
│ ├── optim.py # AdamW + Muon optimizer, 1GPU and distributed
│ ├── report.py # Utilities for writing the nanochat Report
│ ├── tokenizer.py # BPE Tokenizer wrapper in style of GPT-4
│ └── ui.html # HTML/CSS/JS for nanochat frontend
├── pyproject.toml
├── runs
│ ├── miniseries.sh # Miniseries training script
│ ├── runcpu.sh # Small example of how to run on CPU/MPS
│ ├── scaling_laws.sh # Scaling laws experiments
│ └── speedrun.sh # Train the ~$100 nanochat d20
├── scripts
│ ├── base_eval.py # Base model: CORE score, bits per byte, samples
│ ├── base_train.py # Base model: train
│ ├── chat_cli.py # Chat model: talk to over CLI
│ ├── chat_eval.py # Chat model: eval tasks
│ ├── chat_rl.py # Chat model: reinforcement learning
│ ├── chat_sft.py # Chat model: train SFT
│ ├── chat_web.py # Chat model: talk to over WebUI
│ ├── tok_eval.py # Tokenizer: evaluate compression rate
│ └── tok_train.py # Tokenizer: train it
├── tasks
│ ├── arc.py # Multiple choice science questions
│ ├── common.py # TaskMixture | TaskSequence
│ ├── customjson.py # Make Task from arbitrary jsonl convos
│ ├── gsm8k.py # 8K Grade School Math questions
│ ├── humaneval.py # Misnomer; Simple Python coding task
│ ├── mmlu.py # Multiple choice questions, broad topics
│ ├── smoltalk.py # Conglomerate dataset of SmolTalk from HF
│ └── spellingbee.py # Task teaching model to spell/count letters
├── tests
│ └── test_engine.py
└── uv.lock
```
## 贡献
nanochat 的目标是改进 micro models 的最新技术,这些模型可以在 < $1000 的预算下端到端地工作。可访问性既关乎总体成本,也关乎认知复杂性 —— nanochat 不是一个可详尽配置的 LLM "framework";代码库中没有巨大的配置对象、model factory 或 if-then-else 巨兽。它是一个单一、内聚、极简、可读、可修改、可最大程度 fork 的 "strong baseline" 代码库,旨在从头到尾运行并生成你可以与之对话的 ChatGPT 模型。目前,个人最有趣的部分是加快 latency to GPT-2(即获得高于 0.256525 的 CORE 分数)。目前这大约需要 ~3 小时,但通过改进 pretraining 阶段,我们可以进一步改善这一点。
当前 AI 政策:披露。提交 PR 时,请声明任何有大量 LLM 贡献且你未编写或你不完全理解的部分。
## 致谢
- 这个名字 来自我之前的项目 [nanoGPT](https://github.com/karpathy/nanoGPT),它只涵盖了 pretraining。
- nanochat 也受到 [modded-nanoGPT](https://github.com/KellerJordan/modded-nanogpt) 的启发,该项目用明确的指标和排行榜将 nanoGPT 仓库游戏化,并借鉴了其许多想法和一些 pretraining 实现。
- 感谢 [HuggingFace](https://huggingface.co/) 提供 fineweb 和 smoltalk。
- 感谢 [Lambda](https://lambda.ai/service/gpu-cloud) 提供用于开发此项目的计算资源。
- 感谢首席 LLM whisperer 🧙♂️ Alec Radford 的建议/指导。
- 感谢仓库主管 Sofie [@svlandeg](https://github.com/svlandeg) 帮助管理 nanochat 的 issues、pull requests 和 discussions。
## 引用
如果你发现 nanochat 对你的研究有帮助,请简单引用为:
```
@misc{nanochat,
author = {Andrej Karpathy},
title = {nanochat: The best ChatGPT that \$100 can buy},
year = {2025},
publisher = {GitHub},
url = {https://github.com/karpathy/nanochat}
}
```
## 许可证
MIT标签:AI开发工具, Apex, ChatGPT, Chat UI, DCLM, DLL 劫持, DNS解析, Finetuning, GPT, GPT-2, H100, Karpathy, LLM, NLP, Promptflow, Python, PyTorch, Scaling Laws, Tokenizer, Transformer, Unmanaged PE, Vectored Exception Handling, Web界面, 凭据扫描, 分词, 单GPU训练, 大语言模型, 实验框架, 开发工具包, 开源项目, 微调, 成本优化, 推理, 无后门, 机器学习, 模型训练, 模型评估, 深度学习, 漏洞管理, 计算最优, 逆向工具, 预训练