facebookincubator/MCGrad
GitHub: facebookincubator/MCGrad
MCGrad 是一个多重校准工具,用于确保机器学习模型预测在全局和细分群体上都准确校准。
Stars: 38 | Forks: 5
生产就绪的多重校准
[](https://github.com/facebookincubator/MCGrad/actions)
[](https://codecov.io/gh/facebookincubator/MCGrad)
[](https://mcgrad.dev)
[](https://pypi.org/project/mcgrad/)
[](https://pypi.org/project/mcgrad/)
[](https://pepy.tech/project/mcgrad)
[](https://opensource.org/licenses/MIT)
[](https://colab.research.google.com/github/facebookincubator/MCGrad/blob/main/tutorials/01_mcgrad_core.ipynb)
## 什么是 MCGrad?
**MCGrad** 是一个可扩展且易于使用的**多重校准**工具。它确保您的 ML 模型预测不仅在全局(跨所有数据)上校准良好,而且在您通过特征定义的几乎任何细分群体上(例如,按国家、内容类型或任何组合)也是如此。
传统的校准方法,如等渗回归或 Platt 缩放,只能确保全局校准——这意味着预测概率*平均*在所有数据上与观测结果匹配——但您的模型仍然可能对特定群体系统地过度自信或信心不足。MCGrad 能自动识别并修正这些隐藏的校准差距,而无需您手动指定受保护群体。

A globally well-calibrated model: predictions match observed outcomes on average.
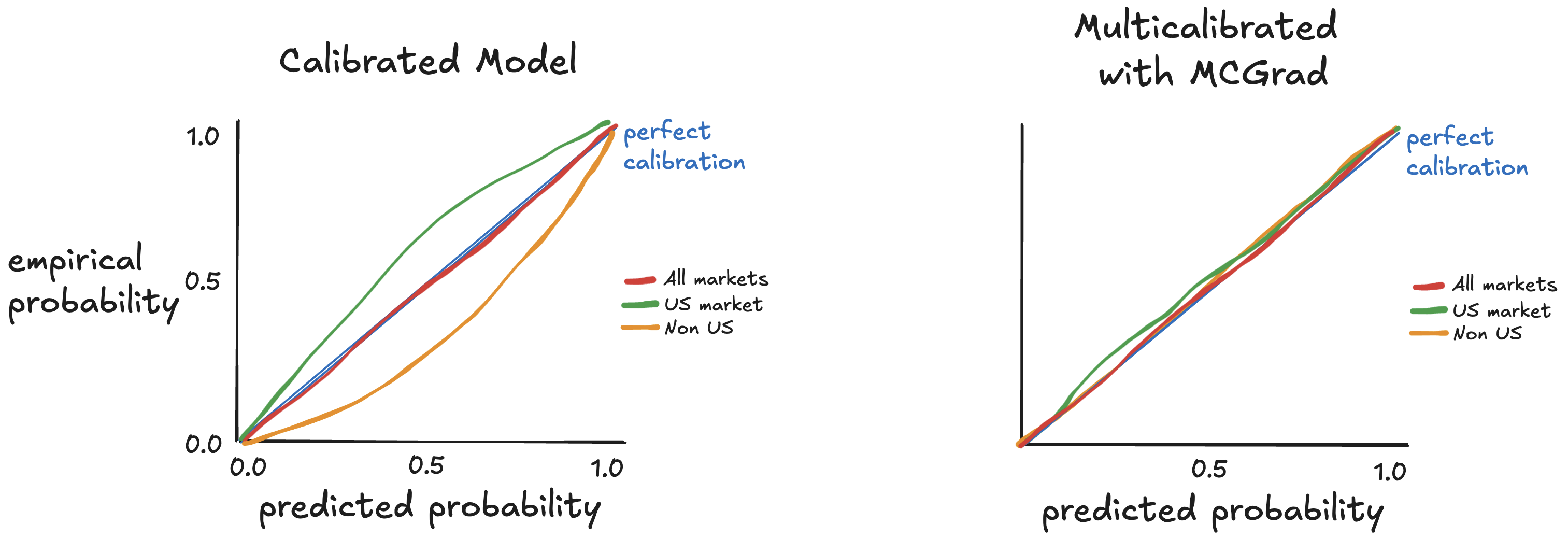
The same model showing hidden miscalibration when broken down by segment. MCGrad fixes this.
## 🌟 为什么选择 MCGrad? - **最先进的多重校准** — 在大量细分群体上提供同类最佳的校准质量。 - **易于使用** — 界面熟悉。传递特征,而非细分。 - **高度可扩展** — 训练快速,推理开销低,即使在网络规模数据上也是如此。 - **设计安全** — 通过基于验证的提前停止进行似然提升更新。 ## 🏭 生产验证 MCGrad 已在 **Meta** 部署了数百个生产模型。详细实验结果请参阅[研究论文](https://arxiv.org/abs/2509.19884)。 ## 📦 安装 **要求:** Python 3.10+ 稳定版本: ``` pip install mcgrad ``` 或通过 conda / mamba: ``` conda install mcgrad # or mamba install mcgrad ``` 最新开发版本: ``` pip install git+https://github.com/facebookincubator/MCGrad.git ``` ## 🚀 快速入门 ``` from mcgrad import methods import numpy as np import pandas as pd # Prepare your data in a DataFrame df = pd.DataFrame({ 'prediction': np.array([0.1, 0.3, 0.7, 0.9, 0.5, 0.2]), # Your model's predictions 'label': np.array([0, 0, 1, 1, 1, 0]), # Ground truth labels 'country': ['US', 'UK', 'US', 'UK', 'US', 'UK'], # Categorical feature 'content_type': ['photo', 'video', 'photo', 'video', 'photo', 'video'], # Categorical feature }) # Apply MCGrad mcgrad = methods.MCGrad() mcgrad.fit( df_train=df, prediction_column_name='prediction', label_column_name='label', categorical_feature_column_names=['country', 'content_type'] ) # Get calibrated predictions calibrated_predictions = mcgrad.predict( df=df, prediction_column_name='prediction', categorical_feature_column_names=['country', 'content_type'] ) # Returns: numpy array of calibrated probabilities, e.g., [0.12, 0.28, 0.72, ...] ``` ## 📚 文档 - **网站与指南:** [mcgrad.dev](https://mcgrad.dev/) - [为什么选择 MCGrad?](https://mcgrad.dev/docs/why-mcgrad) — 了解 MCGrad 解决的挑战 - [快速入门](https://mcgrad.dev/docs/quickstart) — 快速开始使用 - [方法论](https://mcgrad.dev/docs/methodology) — 深入了解 MCGrad 的工作原理 - [API 参考](https://mcgrad.readthedocs.io/en/latest/) — 完整的 API 文档 ## 📖 引用 如果您在研究中使用了 MCGrad,请引用[我们的论文](https://arxiv.org/abs/2509.19884)。 [](https://doi.org/10.1145/3770854.3783954) ``` @inproceedings{tax2026mcgrad, title={{MCGrad: Multicalibration at Web Scale}}, author={Tax, Niek and Perini, Lorenzo and Linder, Fridolin and Haimovich, Daniel and Karamshuk, Dima and Okati, Nastaran and Vojnovic, Milan and Apostolopoulos, Pavlos Athanasios}, booktitle={Proceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1 (KDD 2026)}, year={2026}, doi={10.1145/3770854.3783954} } ``` ### 相关出版物 我们团队在多重校准方面的部分其他工作: - **一种测量多重校准的新指标:** Guy, I., Haimovich, D., Linder, F., Okati, N., Perini, L., Tax, N., & Tygert, M. (2025). [测量多重校准](https://arxiv.org/abs/2506.11251). arXiv:2506.11251. - **关于多重校准价值的理论结果:** Baldeschi, R. C., Di Gregorio, S., Fioravanti, S., Fusco, F., Guy, I., Haimovich, D., Leonardi, S., et al. (2025). [多重校准产生更好的匹配](https://arxiv.org/abs/2511.11413). arXiv:2511.11413.标签:Apex, Python, 人工智能, 代码示例, 偏差校正, 公平性, 多校准, 工具, 数据分析, 数据科学, 无后门, 易用, 普拉特缩放, 机器学习, 校准误差, 概率校准, 模型校准, 模型评估, 特征工程, 生产就绪, 用户模式Hook绕过, 等距回归, 细分校准, 统计学, 资源验证, 逆向工具, 预测校准