
# 🎬 LongLive 2.0:面向长视频生成的 NVFP4 并行基础设施
[](https://arxiv.org/abs/2605.18739)
[](https://github.com/NVlabs/LongLive)
[](https://www.youtube.com/watch?v=7oQALy32fiU)
[](https://huggingface.co/Efficient-Large-Model/LongLive-2.0-5B)
[](https://huggingface.co/Efficient-Large-Model/LongLive-2.0-5B-NVFP4-S4)
[](https://nvlabs.github.io/LongLive/LongLive2/)
[](https://nvlabs.github.io/LongLive/LongLive2/docs/)
[](https://www.youtube.com/watch?v=7oQALy32fiU)
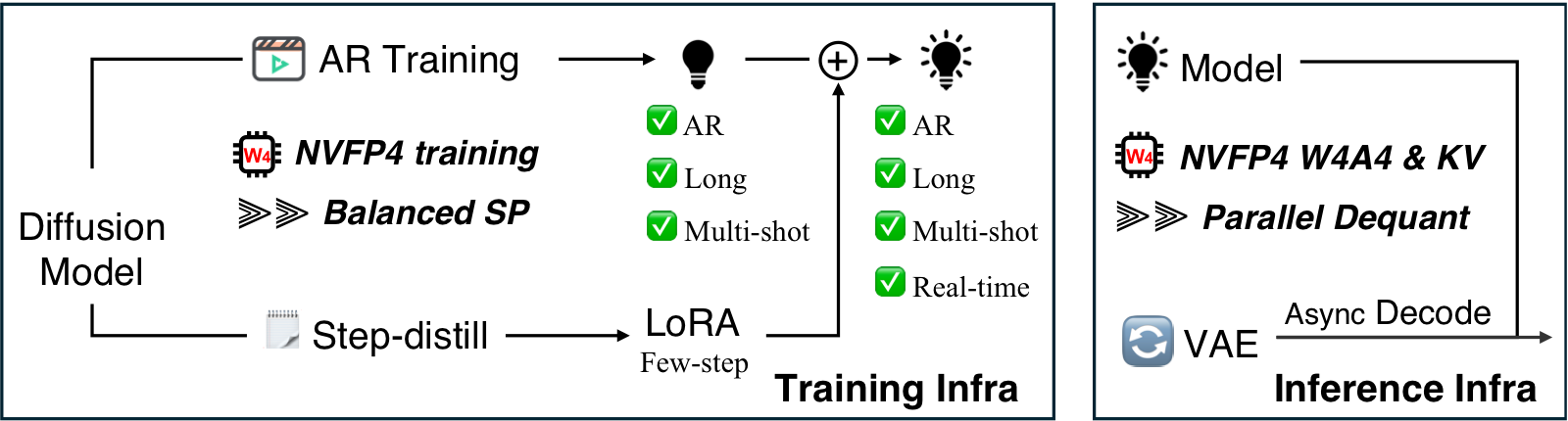
## 💡 TLDR:结合 NVFP4 与并行化的训练和推理基础设施

## 新闻
- 🔥 [2026.05.30] LongLive2.0 现已支持 Wan2.2-TI2V-5B 的 I2V AR 教师强制训练和 I2V DMD 蒸馏。
- ⚡ [2026.05.25] 我们优化了 NVFP4 推理路径,使用融合的 Triton RoPE/adaLN 内核、减少了 KV-cache 同步开销、实现了就地量化 KV-cache 更新、更快的 FP4 KV 反量化、固定 VAE 传输以及更安全的 LoRA-先-量化配置,使整体吞吐量提升了 **18.6%**。
- 🔥 [2026.05.13] 我们发布了 **LongLive 2.0**,这是一个面向 AR 训练、DMD 蒸馏和推理(⚡45.7 FPS)的基础设施,具备 NVFP4、并行化和多镜头能力。原始的 LongLive 1.0 现在位于 [v1.0](https://github.com/NVlabs/LongLive/tree/v1.0) 分支。
- 🔥 [2026.04.12] LongLive 支持通过 [TriAttention](https://github.com/WeianMao/triattention) 进行 KV cache 压缩,KV 压缩率 50%,且质量不下降。点击[此处](https://github.com/WeianMao/triattention/tree/main/longlive)查看。
- 🎉 [2026.1.27] LongLive 被 **ICLR-2026** 接收。
- 🔥 [2026.1.11] LongLive 支持将原始的 LongLive RoPE 适配为 KV-cache 相对 RoPE,从而生成无限长的视频!
- 🔥 [2025.11.3] 我们在线性注意力模型 [SANA-Video](https://nvlabs.github.io/Sana/Video/) 上实现了 LongLive!现在 SANA-Video 可以实时生成 60 秒的交互式视频。
- 🔥 [2025.9.29] 我们发布了[论文](https://arxiv.org/abs/2509.22622)、包含所有训练和推理代码的 GitHub 仓库 [LongLive](https://github.com/NVlabs/LongLive)、模型权重 [LongLive-1.3B](https://huggingface.co/Efficient-Large-Model/LongLive-1.3B) 以及演示页面[网站](https://nvlabs.github.io/LongLive)。
## 简介
**LongLive 1.0**:实时交互式长视频生成。[你可以在 V1.0 分支中找到它](https://github.com/NVlabs/LongLive/tree/v1.0)。
**LongLive 2.0**:面向长视频生成的 NVFP4 并行基础设施。
- 训练方面,支持
- [x] 用于 T2V/I2V AR 训练(教师强制)的平衡序列并行。
- [x] 在多镜头(或单镜头)视频上进行 T2V/I2V AR 训练。
- [x] 在 AR 训练和少步蒸馏中支持 NVFP4(或 BF16)。
- 推理方面,支持
- [x] NVFP4 推理(W4A4)和 NVFP4 KV Cache。
- [x] 多镜头注意力汇聚(multi-shot attention sink)。
- [x] 序列并行推理。
- [x] 异步解码。
**LongLive 1.0**:实时交互式长视频生成。它接收连续的用户提示,并实时生成对应的视频,实现用户引导的长视频生成。核心思想包括注意力汇聚(attention sink)、KV 重缓存(KV-recache)和流式长视频微调(streaming long tuning)。

## 快速上手
- [完整文档](https://nvlabs.github.io/LongLive/LongLive2/docs/)
- [安装](https://nvlabs.github.io/LongLive/LongLive2/docs/#installation)
- [NVFP4 设置](https://nvlabs.github.io/LongLive/LongLive2/docs/#nvfp4-installation)
- [训练模式](https://nvlabs.github.io/LongLive/LongLive2/docs/#training)
- [推理](https://nvlabs.github.io/LongLive/LongLive2/docs/#inference)
- [数据组织](https://nvlabs.github.io/LongLive/LongLive2/docs/#training-data)
### 快速开始
#### BF16
```
import torch
from omegaconf import OmegaConf
from pipeline import CausalDiffusionInferencePipeline
from utils.config import normalize_config
from utils.inference_utils import (
load_generator_checkpoint,
place_vae_for_streaming,
prepare_single_prompt_inputs,
save_video,
)
prompt = "A compact silver robot walks through a clean robotics lab."
merged_checkpoint_path = "LongLive-2.0-5B/model_bf16.pt"
config = normalize_config(OmegaConf.load("configs/inference.yaml"))
device = torch.device("cuda")
torch.set_grad_enabled(False)
pipe = CausalDiffusionInferencePipeline(config, device=device)
load_generator_checkpoint(pipe.generator, merged_checkpoint_path)
pipe = pipe.to(device=device, dtype=torch.bfloat16)
place_vae_for_streaming(pipe, config) # honor streaming_vae + vae_device when set
pipe.generator.model.eval().requires_grad_(False)
noise, prompts = prepare_single_prompt_inputs(config, prompt, device)
video = pipe.inference(noise=noise, text_prompts=prompts)
save_video(video[0], "videos/quickstart/sample.mp4", fps=24)
```
`place_vae_for_streaming` 仅在 `inference.streaming_vae` 为 true 且设置了 `inference.vae_device` 时才生效,因此在你的 yaml 中切换流式管线解码即可——脚本无需改动。
#### NVFP4
将 `configs/nvfp4/inference_nvfp4.yaml` 中的 `checkpoints.generator_ckpt` 指向下载的检查点,并根据所使用的后端设置 `model_quant_use_transformer_engine`:
- TransformerEngine 检查点(`model_te.pt`):`model_quant_use_transformer_engine: true`
- FourOverSix 检查点(`model_4o6.pt`):`model_quant_use_transformer_engine: false`
`setup_nvfp4_pipeline` 处理两个后端的检查点加载、NVFP4 模块封装、权重具体化、dtype/设备放置以及流式管线 VAE 重定位——bf16 的 `pipe.to(...)` 快捷方式在此处不安全,因为它会强制转换量化缓冲区。
```
import torch
from omegaconf import OmegaConf
from pipeline import CausalDiffusionInferencePipeline
from utils.config import normalize_config
from utils.inference_utils import prepare_single_prompt_inputs, save_video, setup_nvfp4_pipeline
prompt = "A compact silver robot walks through a clean robotics lab."
config = normalize_config(OmegaConf.load("configs/nvfp4/inference_nvfp4.yaml"))
device = torch.device("cuda")
torch.set_grad_enabled(False)
pipe = CausalDiffusionInferencePipeline(config, device=device)
setup_nvfp4_pipeline(pipe, config, device)
pipe.generator.model.eval().requires_grad_(False)
noise, prompts = prepare_single_prompt_inputs(config, prompt, device)
video = pipe.inference(noise=noise, text_prompts=prompts)
save_video(video[0], "videos/quickstart/sample_nvfp4.mp4", fps=24)
```
## 训练模式
LongLive2.0 同时支持 T2V 和 I2V 训练。每种模态遵循相同的两阶段方案:先进行 AR 教师强制训练,然后从 AR 检查点进行 DMD 蒸馏。
###2V 训练
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 train.py \
--config_path configs/train_ar.yaml \
--logdir logs/train_ar \
--wandb-save-dir wandb \
--disable-wandb
torchrun --standalone --nnodes=1 --nproc_per_node=8 train.py \
--config_path configs/train_dmd.yaml \
--logdir logs/train_dmd \
--wandb-save-dir wandb \
--disable-wandb
```
### I2V 训练
```
torchrun --standalone --nnodes=1 --nproc_per_node=8 train.py \
--config_path configs/train_i2v_ar.yaml \
--logdir logs/train_i2v_ar \
--wandb-save-dir wandb \
--disable-wandb
torchrun --standalone --nnodes=1 --nproc_per_node=8 train.py \
--config_path configs/train_i2v_dmd.yaml \
--logdir logs/train_i2v_dmd \
--wandb-save-dir wandb \
--disable-wandb
```
对于 I2V 配置,设置 `algorithm.i2v: true` 和 `algorithm.independent_first_frame: true`。`data.image_or_video_shape[1]` 是完整的潜变量序列长度,例如 `96`,而不是 `96 + 1`:在去噪过程中,干净的图像潜变量会替换第一个潜变量,并且该第一帧潜变量会被掩码,从而不参与训练损失。对于 I2V DMD,将 `checkpoints.generator_ckpt` 设置为用于初始化学生模型的 I2V AR 检查点。
## 模型
| 模型 | FPS ↑ | 参数量 | VBench ↑ | 多镜头 |
| --- | ---: | ---: | ---: | :---: |
| [LongLive-1.3B](https://huggingface.co/Efficient-Large-Model/LongLive-1.3B) | 20.7 | 1.3B | 84.87 | |
| [LongLive-2.0-5B](https://huggingface.co/Efficient-Large-Model/LongLive-2.0-5B) | 24.8 | 5B | 85.06 | ✅ |
| [LongLive-2.0-5B-NVFP4-4Step](https://huggingface.co/Efficient-Large-Model/LongLive-2.0-5B-NVFP4-S4) | 29.7 | 5B | 84.51 | ✅ |
| [LongLive-2.0-5B-NVFP4-2Step](https://huggingface.co/Efficient-Large-Model/LongLive-2.0-5B-NVFP4-S2) | 45.7 | 5B | 83.14 | ✅ |
## 许可协议
本仓库采用 Apache 2.0 许可证发布。详情请参见 [LICENSE](LICENSE)。
## 引用
如果你觉得我们的工作有帮助,请考虑引用:
```
@article{longlive_2.0,
title={LongLive2.0: An NVFP4 Parallel Infrastructure for Long Video Generation},
author={Chen, Yukang and Wang, Luozhou and Huang, Wei and Yang, Shuai and Zhang, Bohan and Xiao, Yicheng and Chu, Ruihang and Mao, Weian and Hu, Qixin and Liu, Shaoteng and Zhao, Yuyang and Mao, Huizi and Chen, Ying-Cong and Xie, Enze and Qi, Xiaojuan and Han, Song},
journal={arXiv preprint arXiv},
year={2026}
}
```
```
@inproceedings{longlive,
title={Longlive: Real-time interactive long video generation},
author={Yang, Shuai and Huang, Wei and Chu, Ruihang and Xiao, Yicheng and Zhao, Yuyang and Wang, Xianbang and Li, Muyang and Xie, Enze and Chen, Yingcong and Lu, Yao and others},
booktitle={ICLR},
year={2026},
}
```
## 致谢
- [Self-Forcing](https://github.com/guandeh17/Self-Forcing):我们基于其 AR 训练代码库和公式的工作。
- [Wan2.2](https://github.com/Wan-Video/Wan2.2):本版本中使用的基础视频扩散模型组件。