p-e-w/heretic
GitHub: p-e-w/heretic
一款全自动的大语言模型去审查工具,通过定向消融与参数优化在保持模型能力的同时移除安全对齐限制。
Stars: 24765 | Forks: 2651
 # Heretic:语言模型的完全自动去审查工具
# Heretic:语言模型的完全自动去审查工具[](https://discord.gg/gdXc48gSyT) [](https://huggingface.co/heretic-org) [](https://trendshift.io/repositories/20538) Heretic 是一款无需昂贵的后训练即可从基于 transformer 的语言模型中移除审查(即“安全对齐/safety alignment”)的工具。 它结合了定向消融(directional ablation)的高级实现(也称为“abliteration”)([Arditi et al. 2024](https://arxiv.org/abs/2406.11717), Lai 2025 ([1](https://huggingface.co/blog/grimjim/projected-abliteration), [2](https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration))),以及由 [Optuna](https://optuna.org/) 驱动的基于 TPE 的参数优化器。 这种方法使 Heretic 能够**完全自动**运行。Heretic 通过共同最小化拒绝次数和与原始模型的 KL 散度来寻找高质量的 abliteration 参数。这使得去审查后的模型能够尽可能多地保留原始模型的智能。使用 Heretic 无需理解 transformer 内部机制。事实上,任何知道如何运行命令行程序的人都可以使用 Heretic 对语言模型进行去审查。
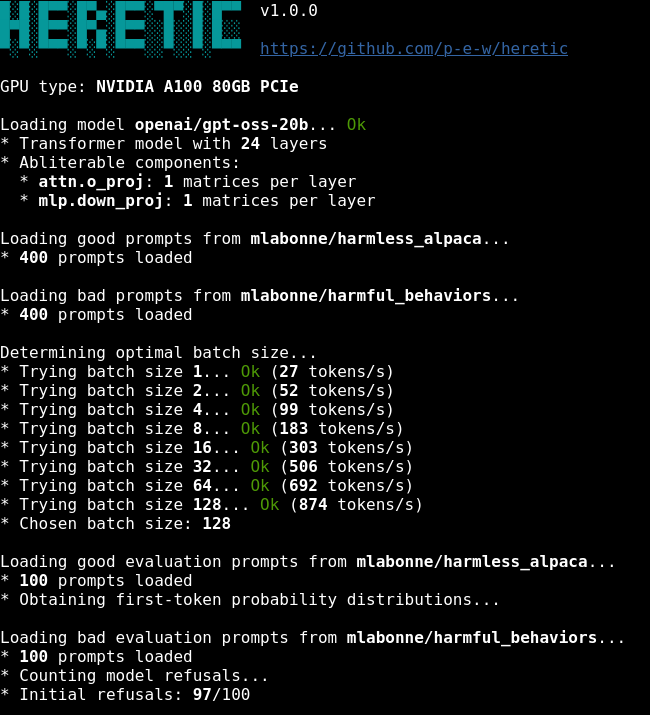 使用默认配置进行无监督运行时,Heretic 生成的去审查模型在质量上可媲美人类专家手动创建的 abliteration:
| 模型 | “有害”提示的拒绝次数 | “无害”提示相对于原始模型的 KL 散度 |
| :--- | ---: | ---: |
| [google/gemma-3-12b-it](https://huggingface.co/google/gemma-3-12b-it) (原始) | 97/100 | 0 *(定义如此)* |
| [mlabonne/gemma-3-12b-it-abliterated-v2](https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated-v2) | 3/100 | 1.04 |
| [huihui-ai/gemma-3-12b-it-abliterated](https://huggingface.co/huihui-ai/gemma-3-12b-it-abliterated) | 3/100 | 0.45 |
| **[p-e-w/gemma-3-12b-it-heretic](https://huggingface.co/p-e-w/gemma-3-12b-it-heretic) ( ours)** | **3/100** | **0.16** |
Heretic 版本在无需任何人工努力的情况下生成,达到了与其他 abliteration 相同的拒绝抑制水平,但 KL 散度要低得多,这表明对原始模型能力的损害较小。
*(您可以使用 Heretic 的内置评估功能重现这些数字,例如 `heretic --model google/gemma-3-12b-it --evaluate-model p-e-w/gemma-3-12b-it-heretic`。请注意,确切的数值可能取决于平台和硬件。上表是在 RTX 5090 上使用 PyTorch 2.8 编译的。)*
当然,数学指标和自动化基准测试永远不能说明全部情况,也不能替代人工评估。Heretic 生成的模型受到了用户的好评(已添加链接和强调):
Heretic 支持大多数稠密模型,包括许多多模态模型,以及几种不同的 MoE 架构。它尚不支持 SSM/混合模型、具有非均匀层的模型以及某些新型注意力系统。
您可以在 [Hugging Face 上](https://huggingface.co/collections/p-e-w/the-bestiary) 找到一小部分使用 Heretic 进行去审查的模型,并且除了这些之外,社区还创建并发布了 [超过 1,000 个](https://huggingface.co/models?other=heretic) Heretic 模型。
## 用法
准备一个安装了 PyTorch 2.2+ 的 Python 3.10+ 环境,并根据您的硬件进行适当配置。然后运行:
```
pip install -U heretic-llm
heretic Qwen/Qwen3-4B-Instruct-2507
```
将 `Qwen/Qwen3-4B-Instruct-2507` 替换为您想要去审查的任何模型。
该过程是完全自动的,不需要配置;但是,Heretic 有各种配置参数,可以对其进行更改以实现更好的控制。运行 `heretic --help` 以查看可用的命令行选项,或者如果您更喜欢使用配置文件,请查看 [`config.default.toml`](config.default.toml)。
在程序运行开始时,Heretic 会对系统进行基准测试,以确定最佳批次大小,从而充分利用可用的硬件。在 RTX 3090 上,使用默认配置,对 Llama-3.1-8B-Instruct 进行去审查大约需要 45 分钟。请注意,Heretic 支持使用 bitsandbytes 进行模型量化,这可以大幅减少处理模型所需的 VRAM 量。将 `quantization` 选项设置为 `bnb_4bit` 以启用量化。
在 Heretic 完成对模型的去审查后,您可以选择保存模型、将其上传到 Hugging Face、与其聊天以测试其效果,或者执行这些操作的任意组合。
## 研究功能
除了移除模型审查这一主要功能外,Heretic 还提供了旨在支持模型内部语义(可解释性)研究的功能。要使用这些功能,您需要安装带有可选 `research` 扩展的 Heretic:
```
pip install -U heretic-llm[research]
```
这使您能够访问以下功能:
### 通过传递 `--plot-residuals` 生成残差向量图
使用此标志运行时,Heretic 将:
1. 针对“有害”和“无害”提示,计算每个 transformer 层的第一个输出 token 的残差向量(隐藏状态)。
2. 执行 [PaCMAP 投影](https://github.com/YingfanWang/PaCMAP),将残差空间映射到 2D 空间。
3. 通过几何中位数对“有害”/“无害”残差的投影进行左右对齐,使连续层的投影更加相似。此外,PaCMAP 在每一新层初始化时使用上一层的投影,从而最大限度地减少突兀的过渡。
4. 散点绘制投影,为每一层生成一个 PNG 图像。
5. 生成一个动画,以动画 GIF 的形式展示残差在各层之间的变换。
使用默认配置进行无监督运行时,Heretic 生成的去审查模型在质量上可媲美人类专家手动创建的 abliteration:
| 模型 | “有害”提示的拒绝次数 | “无害”提示相对于原始模型的 KL 散度 |
| :--- | ---: | ---: |
| [google/gemma-3-12b-it](https://huggingface.co/google/gemma-3-12b-it) (原始) | 97/100 | 0 *(定义如此)* |
| [mlabonne/gemma-3-12b-it-abliterated-v2](https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated-v2) | 3/100 | 1.04 |
| [huihui-ai/gemma-3-12b-it-abliterated](https://huggingface.co/huihui-ai/gemma-3-12b-it-abliterated) | 3/100 | 0.45 |
| **[p-e-w/gemma-3-12b-it-heretic](https://huggingface.co/p-e-w/gemma-3-12b-it-heretic) ( ours)** | **3/100** | **0.16** |
Heretic 版本在无需任何人工努力的情况下生成,达到了与其他 abliteration 相同的拒绝抑制水平,但 KL 散度要低得多,这表明对原始模型能力的损害较小。
*(您可以使用 Heretic 的内置评估功能重现这些数字,例如 `heretic --model google/gemma-3-12b-it --evaluate-model p-e-w/gemma-3-12b-it-heretic`。请注意,确切的数值可能取决于平台和硬件。上表是在 RTX 5090 上使用 PyTorch 2.8 编译的。)*
当然,数学指标和自动化基准测试永远不能说明全部情况,也不能替代人工评估。Heretic 生成的模型受到了用户的好评(已添加链接和强调):
Heretic 支持大多数稠密模型,包括许多多模态模型,以及几种不同的 MoE 架构。它尚不支持 SSM/混合模型、具有非均匀层的模型以及某些新型注意力系统。
您可以在 [Hugging Face 上](https://huggingface.co/collections/p-e-w/the-bestiary) 找到一小部分使用 Heretic 进行去审查的模型,并且除了这些之外,社区还创建并发布了 [超过 1,000 个](https://huggingface.co/models?other=heretic) Heretic 模型。
## 用法
准备一个安装了 PyTorch 2.2+ 的 Python 3.10+ 环境,并根据您的硬件进行适当配置。然后运行:
```
pip install -U heretic-llm
heretic Qwen/Qwen3-4B-Instruct-2507
```
将 `Qwen/Qwen3-4B-Instruct-2507` 替换为您想要去审查的任何模型。
该过程是完全自动的,不需要配置;但是,Heretic 有各种配置参数,可以对其进行更改以实现更好的控制。运行 `heretic --help` 以查看可用的命令行选项,或者如果您更喜欢使用配置文件,请查看 [`config.default.toml`](config.default.toml)。
在程序运行开始时,Heretic 会对系统进行基准测试,以确定最佳批次大小,从而充分利用可用的硬件。在 RTX 3090 上,使用默认配置,对 Llama-3.1-8B-Instruct 进行去审查大约需要 45 分钟。请注意,Heretic 支持使用 bitsandbytes 进行模型量化,这可以大幅减少处理模型所需的 VRAM 量。将 `quantization` 选项设置为 `bnb_4bit` 以启用量化。
在 Heretic 完成对模型的去审查后,您可以选择保存模型、将其上传到 Hugging Face、与其聊天以测试其效果,或者执行这些操作的任意组合。
## 研究功能
除了移除模型审查这一主要功能外,Heretic 还提供了旨在支持模型内部语义(可解释性)研究的功能。要使用这些功能,您需要安装带有可选 `research` 扩展的 Heretic:
```
pip install -U heretic-llm[research]
```
这使您能够访问以下功能:
### 通过传递 `--plot-residuals` 生成残差向量图
使用此标志运行时,Heretic 将:
1. 针对“有害”和“无害”提示,计算每个 transformer 层的第一个输出 token 的残差向量(隐藏状态)。
2. 执行 [PaCMAP 投影](https://github.com/YingfanWang/PaCMAP),将残差空间映射到 2D 空间。
3. 通过几何中位数对“有害”/“无害”残差的投影进行左右对齐,使连续层的投影更加相似。此外,PaCMAP 在每一新层初始化时使用上一层的投影,从而最大限度地减少突兀的过渡。
4. 散点绘制投影,为每一层生成一个 PNG 图像。
5. 生成一个动画,以动画 GIF 的形式展示残差在各层之间的变换。
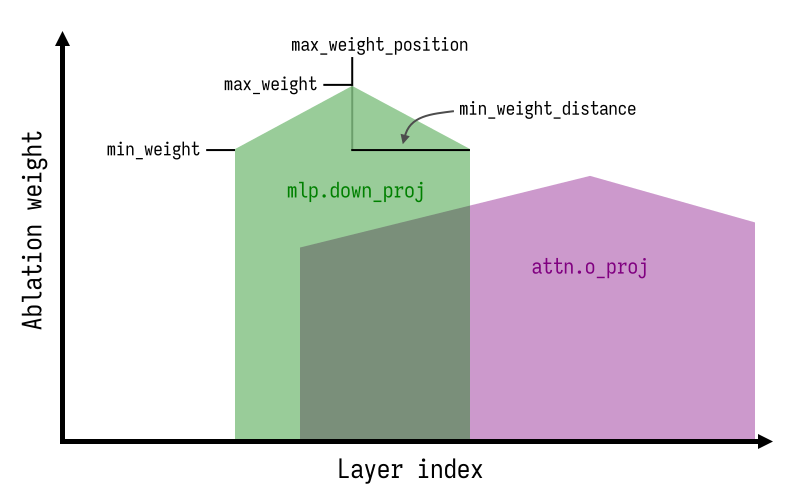 Heretic 相对于现有 abliteration 系统的主要创新在于:
* 消融权重核的形状非常灵活,结合自动参数优化,可以改善依从性/质量的权衡。Maxime Labonne 在 [gemma-3-12b-it-abliterated-v2](https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated-v2) 中先前探索了非常量消融权重。
* 拒绝方向索引是浮点数而不是整数。对于非整数值,将对两个最近的拒绝方向向量进行线性插值。这解锁了除均值差计算识别出的方向之外的广阔额外方向空间,通常使优化过程能够找到比属于任何单独层的方向更好的方向。
* 每个组件分别选择消融参数。我发现 MLP 干预往往比注意力干预对模型的损害更大,因此使用不同的消融权重可以挤出一些额外的性能。
## 先前技术
我知道以下公开可用的 abliteration 技术实现:
* [AutoAbliteration](https://huggingface.co/posts/mlabonne/714992455492422)
* [abliterator.py](https://github.com/FailSpy/abliterator)
* [wassname's Abliterator](https://github.com/wassname/abliterator)
* [ErisForge](https://github.com/Tsadoq/ErisForge)
* [Removing refusals with HF Transformers](https://github.com/Sumandora/remove-refusals-with-transformers)
* [deccp](https://github.com/AUGMXNT/deccp)
请注意,Heretic 是从头开始编写的,不重用任何这些项目的代码。
## 致谢
Heretic 的开发参考了:
* [原始 abliteration 论文 (Arditi et al. 2024)](https://arxiv.org/abs/2406.11717)
* [Maxime Labonne 关于 abliteration 的文章](https://huggingface.co/blog/mlabonne/abliteration),以及他自己 abliteration 模型的模型卡片中的一些细节(见上文)
* Jim Lai 描述 ["projected abliteration"](https://huggingface.co/blog/grimjim/projected-abliteration) 和 ["norm-preserving biprojected abliteration"](https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration) 的文章
## 引用
如果您将 Heretic 用于您的研究,请使用以下 BibTeX 条目进行引用:
```
@misc{heretic,
author = {Weidmann, Philipp Emanuel},
title = {Heretic: Fully automatic censorship removal for language models},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/p-e-w/heretic}}
}
```
## 许可证
版权所有 © 2025-2026 Philipp Emanuel Weidmann (
Heretic 相对于现有 abliteration 系统的主要创新在于:
* 消融权重核的形状非常灵活,结合自动参数优化,可以改善依从性/质量的权衡。Maxime Labonne 在 [gemma-3-12b-it-abliterated-v2](https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated-v2) 中先前探索了非常量消融权重。
* 拒绝方向索引是浮点数而不是整数。对于非整数值,将对两个最近的拒绝方向向量进行线性插值。这解锁了除均值差计算识别出的方向之外的广阔额外方向空间,通常使优化过程能够找到比属于任何单独层的方向更好的方向。
* 每个组件分别选择消融参数。我发现 MLP 干预往往比注意力干预对模型的损害更大,因此使用不同的消融权重可以挤出一些额外的性能。
## 先前技术
我知道以下公开可用的 abliteration 技术实现:
* [AutoAbliteration](https://huggingface.co/posts/mlabonne/714992455492422)
* [abliterator.py](https://github.com/FailSpy/abliterator)
* [wassname's Abliterator](https://github.com/wassname/abliterator)
* [ErisForge](https://github.com/Tsadoq/ErisForge)
* [Removing refusals with HF Transformers](https://github.com/Sumandora/remove-refusals-with-transformers)
* [deccp](https://github.com/AUGMXNT/deccp)
请注意,Heretic 是从头开始编写的,不重用任何这些项目的代码。
## 致谢
Heretic 的开发参考了:
* [原始 abliteration 论文 (Arditi et al. 2024)](https://arxiv.org/abs/2406.11717)
* [Maxime Labonne 关于 abliteration 的文章](https://huggingface.co/blog/mlabonne/abliteration),以及他自己 abliteration 模型的模型卡片中的一些细节(见上文)
* Jim Lai 描述 ["projected abliteration"](https://huggingface.co/blog/grimjim/projected-abliteration) 和 ["norm-preserving biprojected abliteration"](https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration) 的文章
## 引用
如果您将 Heretic 用于您的研究,请使用以下 BibTeX 条目进行引用:
```
@misc{heretic,
author = {Weidmann, Philipp Emanuel},
title = {Heretic: Fully automatic censorship removal for language models},
year = {2025},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/p-e-w/heretic}}
}
```
## 许可证
版权所有 © 2025-2026 Philipp Emanuel Weidmann (标签:Abliteration, Anti-Censorship, Apex, DLL 劫持, Hugging Face, KL散度, LLM, Optuna, Transformer, Unmanaged PE, 二进制发布, 人工智能, 凭据扫描, 去审查, 大语言模型, 安全对齐移除, 开源工具, 数字取证, 方向消融, 机器学习, 模型修改, 模型微调, 用户模式Hook绕过, 系统调用监控, 网络安全, 自动化脚本, 超参数优化, 越狱, 逆向工具, 隐私保护