OpenBMB/VoxCPM
GitHub: OpenBMB/VoxCPM
VoxCPM2 是一个基于免分词器扩散自回归架构的多语种 TTS 系统,支持通过自然语言描述进行创意声音设计、高保真声音克隆及 48kHz 录音室级音频生成。
Stars: 33783 | Forks: 3861
VoxCPM2:免分词器的多语种语音生成、创意声音设计与高保真克隆 TTS
English | 中文

👋 Join our community for discussion and support!
![]() Feishu
|
Feishu
|
![]() Discord
Discord
Arabic, Burmese, Chinese, Danish, Dutch, English, Finnish, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Khmer, Korean, Lao, Malay, Norwegian, Polish, Portuguese, Russian, Spanish, Swahili, Swedish, Tagalog, Thai, Turkish, Vietnamese 中文方言:四川话, 粤语, 吴语, 东北话, 河南话, 陕西话, 山东话, 天津话, 闽南话 ### 新闻动态 * **[2026.04]** 🔥 我们发布了 **VoxCPM2** —— 2B 参数、30 种语言、声音设计与可控声音克隆、48kHz 音频输出 | [文档](https://voxcpm.readthedocs.io/en/latest/) | [Playground](https://huggingface.co/spaces/OpenBMB/VoxCPM-Demo) * **[2025.12]** 🎉 开源 **VoxCPM1.5** [权重](https://huggingface.co/openbmb/VoxCPM1.5),支持 SFT & LoRA 微调。(**🏆 #1 GitHub Trending**) * **[2025.09]** 🔥 发布 VoxCPM [技术报告](https://arxiv.org/abs/2509.24650)。 * **[2025.09]** 🎉 开源 **VoxCPM-0.5B** [权重](https://huggingface.co/openbmb/VoxCPM-0.5B)(**🏆 #1 HuggingFace Trending**) ## 目录 - [快速开始](#-quick-start) - [安装](#installation) - [Python API](#python-api) - [CLI 使用](#cli-usage) - [Web 演示](#web-demo) - [生产部署](#-production-deployment-nano-vllm) - [模型与版本](#-models--versions) - [性能](#-performance) - [微调](#%EF%B8%8F-fine-tuning) - [文档](#-documentation) - [生态与社区](#-ecosystem--community) - [风险与限制](#%EF%B8%8F-risks-and-limitations) - [引用](#-citation) ## 🚀 快速开始 ### 安装 ``` pip install voxcpm ``` ### Python API #### 🗣️ Text-to-Speech ``` from voxcpm import VoxCPM import soundfile as sf model = VoxCPM.from_pretrained( "openbmb/VoxCPM2", load_denoiser=False, ) wav = model.generate( text="VoxCPM2 is the current recommended release for realistic multilingual speech synthesis.", cfg_value=2.0, inference_timesteps=10, ) sf.write("demo.wav", wav, model.tts_model.sample_rate) print("saved: demo.wav") ``` 如果您更倾向于先从 ModelScope 下载,可以使用: ``` pip install modelscope ``` ``` from modelscope import snapshot_download snapshot_download("OpenBMB/VoxCPM2", local_dir='./pretrained_models/VoxCPM2') # specify the local directory to save the model from voxcpm import VoxCPM import soundfile as sf model = VoxCPM.from_pretrained("./pretrained_models/VoxCPM2", load_denoiser=False) wav = model.generate( text="VoxCPM2 is the current recommended release for realistic multilingual speech synthesis.", cfg_value=2.0, inference_timesteps=10, ) sf.write("demo.wav", wav, model.tts_model.sample_rate) ``` #### 🎨 声音设计 通过自然语言描述创造声音 —— 无需参考音频。**格式**:将描述放在 `text` 的开头括号内(例如 `"(your voice description)The text to synthesize."`): ``` wav = model.generate( text="(A young woman, gentle and sweet voice)Hello, welcome to VoxCPM2!", cfg_value=2.0, inference_timesteps=10, ) sf.write("voice_design.wav", wav, model.tts_model.sample_rate) ``` #### 🎛️ 可控声音克隆 上传一段参考音频。模型将克隆音色,您仍可使用控制指令调整语速、情感或风格。 ``` wav = model.generate( text="This is a cloned voice generated by VoxCPM2.", reference_wav_path="path/to/voice.wav", ) sf.write("clone.wav", wav, model.tts_model.sample_rate) wav = model.generate( text="(slightly faster, cheerful tone)This is a cloned voice with style control.", reference_wav_path="path/to/voice.wav", cfg_value=2.0, inference_timesteps=10, ) sf.write("controllable_clone.wav", wav, model.tts_model.sample_rate) ``` #### 🎙️ 极致克隆 同时提供参考音频及其准确转录文本,进行基于音频延续的克隆,重现每一个声音细节。为最大化克隆相似度,请将同一段参考片段同时传入 `reference_wav_path` 和 `prompt_wav_path`,如下所示: ``` wav = model.generate( text="This is an ultimate cloning demonstration using VoxCPM2.", prompt_wav_path="path/to/voice.wav", prompt_text="The transcript of the reference audio.", reference_wav_path="path/to/voice.wav", # optional, for better simliarity ) sf.write("hifi_clone.wav", wav, model.tts_model.sample_rate) ```
🔄 流式 API
``` import numpy as np chunks = [] for chunk in model.generate_streaming( text="Streaming text to speech is easy with VoxCPM!", ): chunks.append(chunk) wav = np.concatenate(chunks) sf.write("streaming.wav", wav, model.tts_model.sample_rate) ```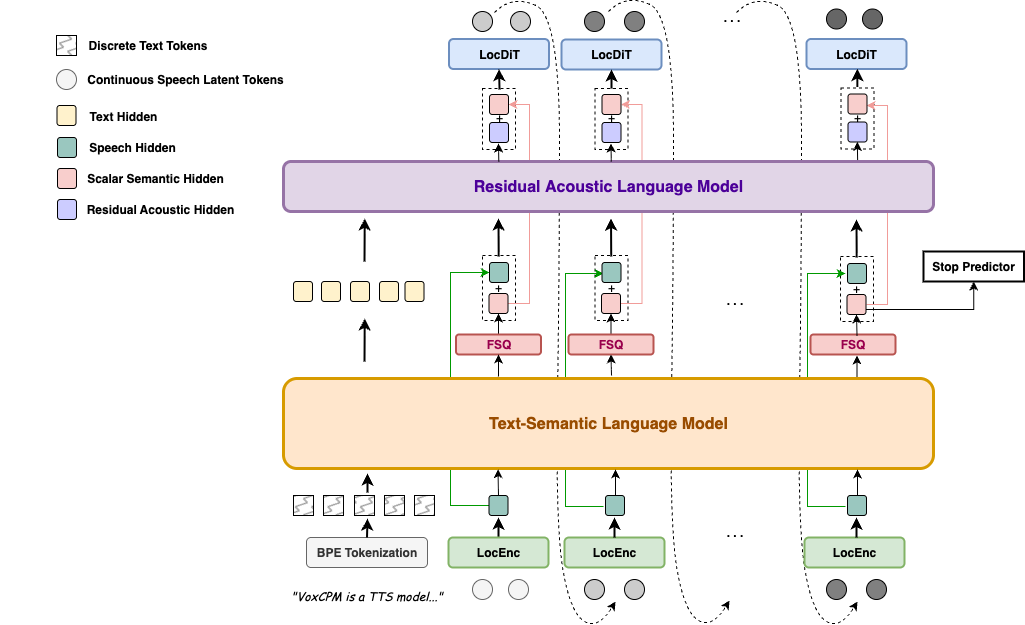
Seed-TTS-eval WER(⬇)&SIM(⬆) 结果(点击展开)
| Model | Parameters | Open-Source | test-EN | | test-ZH | | test-Hard | | |------|------|------|:------------:|:--:|:------------:|:--:|:-------------:|:--:| | | | | WER/%⬇ | SIM/%⬆| CER/%⬇| SIM/%⬆ | CER/%⬇ | SIM/%⬆ | | MegaTTS3 | 0.5B | ❌ | 2.79 | 77.1 | 1.52 | 79.0 | - | - | | DiTAR | 0.6B | ❌ | 1.69 | 73.5 | 1.02 | 75.3 | - | - | | CosyVoice3 | 0.5B | ❌ | 2.02 | 71.8 | 1.16 | 78.0 | 6.08 | 75.8 | | CosyVoice3 | 1.5B | ❌ | 2.22 | 72.0 | 1.12 | 78.1 | 5.83 | 75.8 | | Seed-TTS | - | ❌ | 2.25 | 76.2 | 1.12 | 79.6 | 7.59 | 77.6 | | MiniMax-Speech | - | ❌ | 1.65 | 69.2 | 0.83 | 78.3 | - | - | | F5-TTS | 0.3B | ✅ | 2.00 | 67.0 | 1.53 | 76.0 | 8.67 | 71.3 | | MaskGCT | 1B | ✅ | 2.62 | 71.7 | 2.27 | 77.4 | - | - | | CosyVoice | 0.3B | ✅ | 4.29 | 60.9 | 3.63 | 72.3 | 11.75 | 70.9 | | CosyVoice2 | 0.5B | ✅ | 3.09 | 65.9 | 1.38 | 75.7 | 6.83 | 72.4 | | SparkTTS | 0.5B | ✅ | 3.14 | 57.3 | 1.54 | 66.0 | - | - | | FireRedTTS | 0.5B | ✅ | 3.82 | 46.0 | 1.51 | 63.5 | 17.45 | 62.1 | | FireRedTTS-2 | 1.5B | ✅ | 1.95 | 66.5 | 1.14 | 73.6 | - | - | | Qwen2.5-Omni | 7B | ✅ | 2.72 | 63.2 | 1.70 | 75.2 | 7.97 | 74.7 | | Qwen3-Omni | 30B-A3B | ✅ | 1.39 | - | 1.07 | - | - | - | | OpenAudio-s1-mini | 0.5B | ✅ | 1.94 | 55.0 | 1.18 | 68.5 | 23.37 | 64.3 | | IndexTTS2 | 1.5B | ✅ | 2.23 | 70.6 | 1.03 | 76.5 | 7.12 | 75.5 | | VibeVoice | 1.5B | ✅ | 3.04 | 68.9 | 1.16 | 74.4 | - | - | | HiggsAudio-v2 | 3B | ✅ | 2.44 | 67.7 | 1.50 | 74.0 | 55.07 | 65.6 | | VoxCPM-0.5B | 0.6B | ✅ | 1.85 | 72.9 | 0.93 | 77.2 | 8.87 | 73.0 | | VoxCPM1.5 | 0.8B | ✅ | 2.12 | 71. | 1.18 | 77.0 | 7.74 | 73.1 | | MOSS-TTS | | ✅ | 1.85 | 73.4 | 1.20 | 78.8 | - | - | | Qwen3-TTS | 1.7B | ✅ | 1.23 | 71.7 | 1.22 | 77.0 | 6.76 | 74.8 | | FishAudio S2 | 4B | ✅ | 0.99 | - | 0.54 | - | 5.99 | - | | LongCat-Audio-DiT | 3.5B | ✅ | 1.50 | 78.6 | 1.09 | 81.8 | 6.04 | 79.7 | | **VoxCPM2** | 2B | ✅ | 1.84 | 75.3 | 0.97| 79.5| 8.13 | 75.3 |CV3-eval 多语种 WER/CER(⬇) 结果(点击展开)
| Model | zh | en | hard-zh | hard-en | ja | ko | de | es | fr | it | ru | |-------|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:| | CosyVoice2 | 4.08 | 6.32 | 12.58| 11.96| 9.13 | 19.7 |- | - | - | - | - | | CosyVoice3-1.5B | 3.91 | 4.99 | 9.77 | 10.55 | 7.57 | 5.69 | 6.43 | 4.47 | 11.8 | 10.5 | 6.64 | | Fish Audio S2 | 2.65 | 2.43 | 9.10 | 4.40 | 3.96 | 2.76 | 2.22 | 2.00 | 6.26 | 2.04 | 2.78 | | **VoxCPM2** | 3.65 | 5.00 | 8.55 | 8.48 | 5.96 | 5.69 | 4.77 | 3.80 | 9.85 | 4.25 | 5.21 |Minimax-MLS-test WER(⬇) 结果(点击展开)
| Language | Minimax | ElevenLabs | Qwen3-TTS | FishAudio S2 | **VoxCPM2** | |----------|:-------:|:----------:|:--------------------:|:------------:|:-----------:| | Arabic | **1.665** | 1.666 | – | 3.500 | 13.046 | | Cantonese | 34.111 | 51.513 | – | **30.670** | 38.584 | | Chinese | 2.252 | 16.026 | 0.928 | **0.730** | 1.136 | | Czech | 3.875 | **2.108** | – | 2.840 | 24.132 | | Dutch | 1.143 | **0.803** | – | 0.990 | 0.913 | | English | 2.164 | 2.339 | **0.934** | 1.620 | 2.289 | | Finnish | 4.666 | 2.964 | – | 3.330 | **2.632** | | French | 4.099 | 5.216 | **2.858** | 3.050 | 4.534 | | German | 1.906 | 0.572 | 1.235 | **0.550** | 0.679 | | Greek | 2.016 | **0.991** | – | 5.740 | 2.844 | | Hindi | 6.962 | **5.827** | – | 14.640 | 19.699 | | Indonesian | 1.237 | **1.059** | – | 1.460 | 1.084 | | Italian | 1.543 | 1.743 | **0.948** | 1.270 | 1.563 | | Japanese | 3.519 | 10.646 | 3.823 | **2.760** | 4.628 | | Korean | 1.747 | 1.865 | 1.755 | **1.180** | 1.962 | | Polish | 1.415 | **0.766** | – | 1.260 | 1.141 | | Portuguese | 1.877 | 1.331 | 1.526 | **1.140** | 1.938 | | Romanian | 2.878 | **1.347** | – | 10.740 | 21.577 | | Russian | 4.281 | 3.878 | 3.212 | **2.400** | 3.634 | | Spanish | 1.029 | 1.084 | 1.126 | **0.910** | 1.438 | | Thai | 2.701 | 73.936 | – | 4.230 | 2.961 | | Turkish | 1.52 | 0.699 | – | 0.870 | 0.817 | | Ukrainian | 1.082 | **0.997** | – | 2.300 | 6.316 | | Vietnamese | **0.88** | 73.415 | – | 7.410 | 3.307 |Minimax-MLS-test SIM(⬆) 结果(点击展开)
| Language | Minimax | ElevenLabs | Qwen3-TTS | FishAudio S2 | **VoxCPM2** | |----------|:-------:|:----------:|:--------------------:|:------------:|:-----------:| | Arabic | 73.6 | 70.6 | – | 75.0 | **79.1** | | Cantonese | 77.8 | 67.0 | – | 80.5 | **83.5** | | Chinese | 78.0 | 67.7 | 79.9 | 81.6 | **82.5** | | Czech | 79.6 | 68.5 | – | **79.8** | 78.3 | | Dutch | 73.8 | 68.0 | – | 73.0 | **80.8** | | English | 75.6 | 61.3 | 77.5 | 79.7 | **85.4** | | Finnish | 83.5 | 75.9 | – | 81.9 | **89.0** | | French | 62.8 | 53.5 | 62.8 | 69.8 | **73.5** | | German | 73.3 | 61.4 | 77.5 | 76.7 | **80.3** | | Greek | 82.6 | 73.3 | – | 79.5 | **86.0** | | Hindi | 81.8 | 73.0 | – | 82.1 | **85.6** | | Indonesian | 72.9 | 66.0 | – | 76.3 | **80.0** | | Italian | 69.9 | 57.9 | 81.7 | 74.7 | **78.0** | | Japanese | 77.6 | 73.8 | 78.8 | 79.6 | **82.8** | | Korean | 77.6 | 70.0 | 79.9 | 81.7 | **83.3** | | Polish | 80.2 | 72.9 | – | 81.9 | **88.4** | | Portuguese | 80.5 | 71.1 | 81.7 | 78.1 | **83.7** | | Romanian | **80.9** | 69.9 | – | 73.3 | 79.7 | | Russian | 76.1 | 67.6 | 79.2 | 79.0 | **81.1** | | Spanish | 76.2 | 61.5 | 81.4 | 77.6 | **83.1** | | Thai | 80.0 | 58.8 | – | 78.6 | **84.0** | | Turkish | 77.9 | 59.6 | – | 83.5 | **87.1** | | Ukrainian | 73.0 | 64.7 | – | 74.7 | **79.8** | | Vietnamese | 74.3 | 36.9 | – | 74.0 | **80.6** |内部 30 语种 ASR 基准测试(点击展开)
| Language | Metric | VoxCPM2 | Fish S2-Pro | |---|---:|---:|---:| | ar (Arabic) | CER | 1.23% | 0.30% | | da (Danish) | WER | 2.70% | 3.52% | | de (German) | WER | 0.96% | 0.64% | | el (Greek) | WER | 3.17% | 4.61% | | en (English) | WER | 0.42% | 1.03% | | es (Spanish) | WER | 1.33% | 0.64% | | fi (Finnish) | WER | 2.24% | 2.80% | | fr (French) | WER | 2.16% | 2.34% | | he (Hebrew) | CER | 2.98% | 15.27% | | hi (Hindi) | CER | 0.79% | 0.91% | | id (Indonesian) | WER | 1.36% | 1.68% | | it (Italian) | WER | 1.65% | 1.08% | | ja (Japanese) | CER | 2.40% | 1.82% | | km (Khmer) | CER | 2.05% | 75.15% | | ko (Korean) | CER | 0.95% | 0.29% | | lo (Lao) | CER | 1.90% | 87.40% | | ms (Malay) | WER | 1.75% | 1.41% | | my (Burmese) | CER | 1.42% | 85.27% | | nl (Dutch) | WER | 1.25% | 1.68% | | no (Norwegian) | WER | 2.49% | 3.76% | | pl (Polish) | WER | 1.90% | 1.65% | | pt (Portuguese) | WER | 1.48% | 1.49% | | ru (Russian) | WER | 0.90% | 0.86% | | sv (Swedish) | WER | 2.22% | 2.63% | | sw (Swahili) | CER | 1.07% | 2.02% | | th (Thai) | CER | 0.94% | 1.92% | | tl (Tagalog) | WER | 2.63% | 4.00% | | tr (Turkish) | WER | 1.65% | 1.65% | | vi (Vietnamese) | WER | 1.56% | 5.56% | | zh (Chinese) | CER | 0.92% | 1.02% | | Average (30 languages) | **1.68%** | - |指令引导的声音设计结果(点击展开)
| Model | InstructTTSEval-ZH | | | InstructTTSEval-EN | | | |-------|:---:|:----:|:----:|:----:|:----:|:----:| | | APS⬆| DSD⬆ | RP⬆| APS⬆ | DSD⬆ | RP⬆ | | Hume | – | – | – | 83.0 | 75.3 | 54.3 | | VoxInstruct | 47.5 | 52.3 | 42.6 | 54.9 | 57.0 | 39.3 | | Parler-tts-mini | – | – | – | 63.4 | 48.7 | 28.6 | | Parler-tts-large | – | – | – | 60.0 | 45.9 | 31.2 | | PromptTTS | – | – | – | 64.3 | 47.2 | 31.4 | | PromptStyle | – | – | – | 57.4 | 46.4 | 30.9 | | VoiceSculptor | 75.7 | 64.7 | 61.5 | – | – | – | | Mimo-Audio-7B-Instruct | 75.7 | 74.3 | 61.5 | 80.6 | 77.6 | 59.5 | | Qwen3TTS-12Hz-1.7B-VD | **85.2** | **81.1** | **65.1** | 82.9 | 82.4 | 68.4 | | **VoxCPM2** | **85.2** | 71.5 | 60.8 | **84.2** | **83.2** | **71.4** | ModelBest
ModelBest THUHCSI
THUHCSI标签:Hugging Face, ModelScope, OpenBMB, Tokenizer-Free, TTS, VoxCPM2, 人工智能, 凭据扫描, 创意语音设计, 声音复刻, 多语言, 无词元化器, 深度学习, 生成式模型, 用户模式Hook绕过, 语音克隆, 语音合成, 语音生成, 跨语言, 逆向工具, 音频处理