chensuzeyu/SpotOcc
GitHub: chensuzeyu/SpotOcc
SPOT-Occ 是一个稀疏原型引导Transformer,用于基于相机的3D占用预测,解决了传统解码器在稀疏表示下的计算瓶颈。
Stars: 17 | Forks: 0
# SPOT-Occ:用于基于相机的3D占用预测的稀疏原型引导Transformer
[](https://arxiv.org/abs/2602.04240)
## 摘要
从相机实现高精度且实时的3D占用预测是自动驾驶车辆安全实用部署的关键要求。虽然转向稀疏3D表示解决了编码瓶颈,但也给解码器带来了新的挑战:如何高效聚合来自稀疏、非均匀分布的体素特征集的信息,同时避免使用计算开销巨大的密集注意力。在本文中,我们提出了一种新颖的基于原型的稀疏Transformer解码器,它用高效的两阶段引导特征选择和聚焦聚合过程取代了这种昂贵的交互。我们的核心思想是让解码器的注意力受原型引导。我们通过稀疏原型选择机制实现这一点,每个查询自适应地识别一组紧凑的最显著体素特征(称为原型),用于聚焦特征聚合。为确保这种动态选择稳定有效,我们引入了一种互补的去噪范式。该方法利用真值掩码提供显式引导,确保跨解码器层的一致查询-原型关联。我们的模型SPOT-Occ在速度上以显著优势超越了先前的方法,同时也提高了准确性。
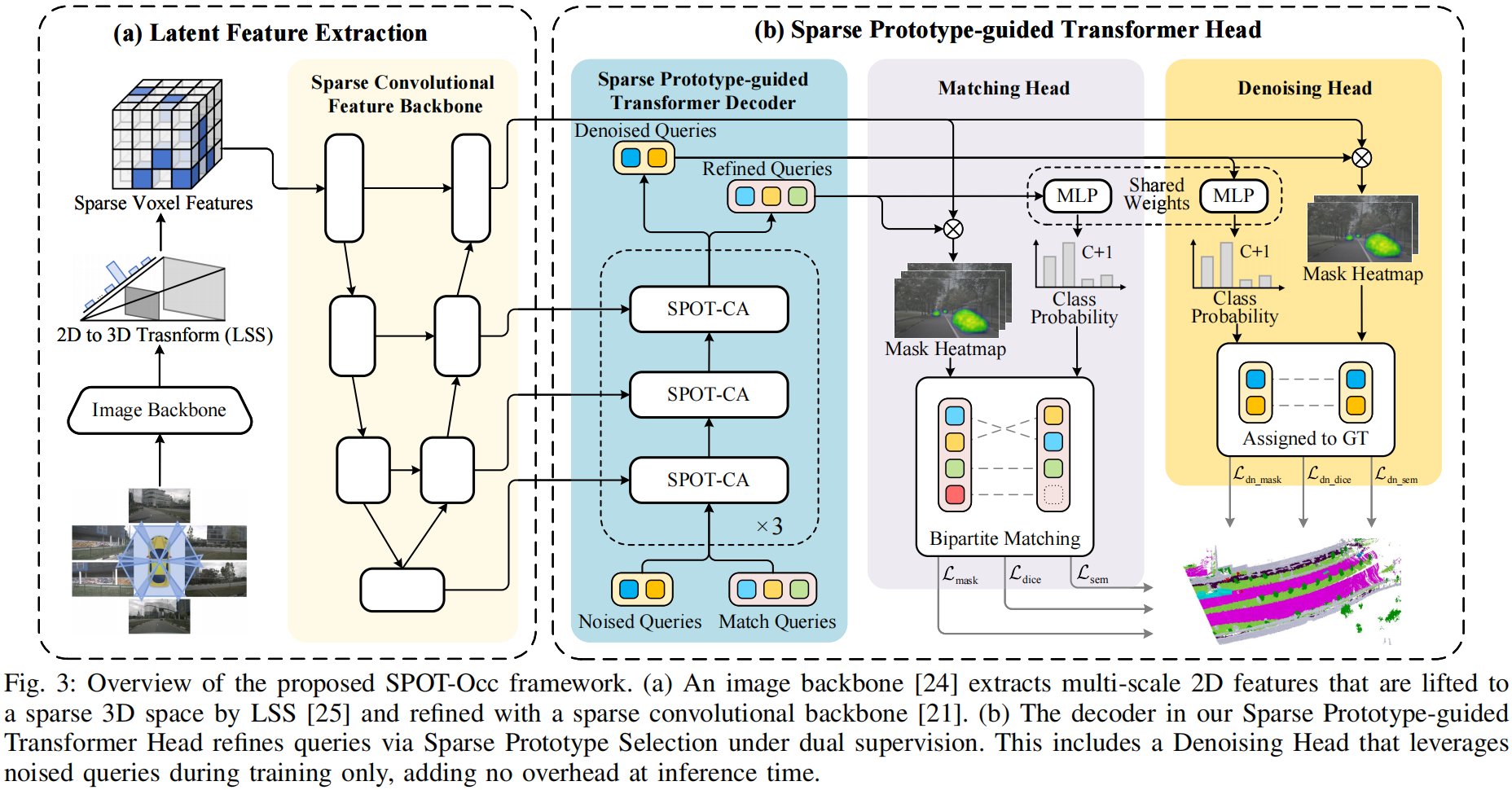
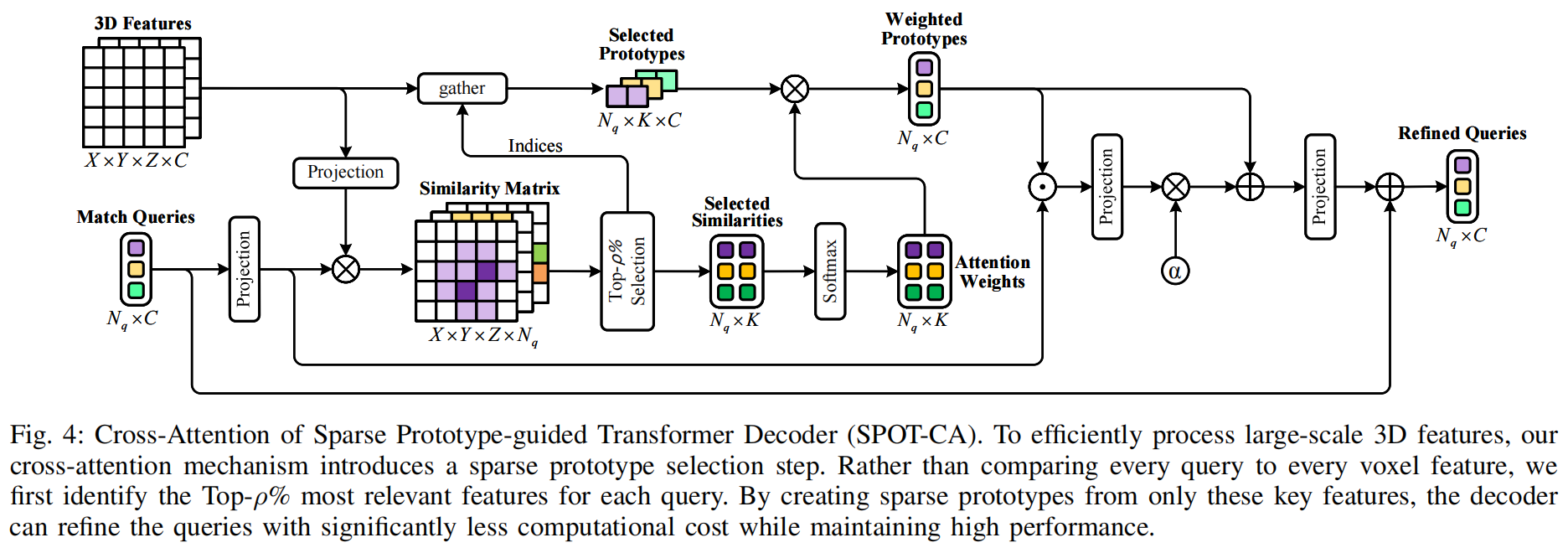
## 演示

## 基准测试结果
在OpenOccupancy验证集上的占用预测:
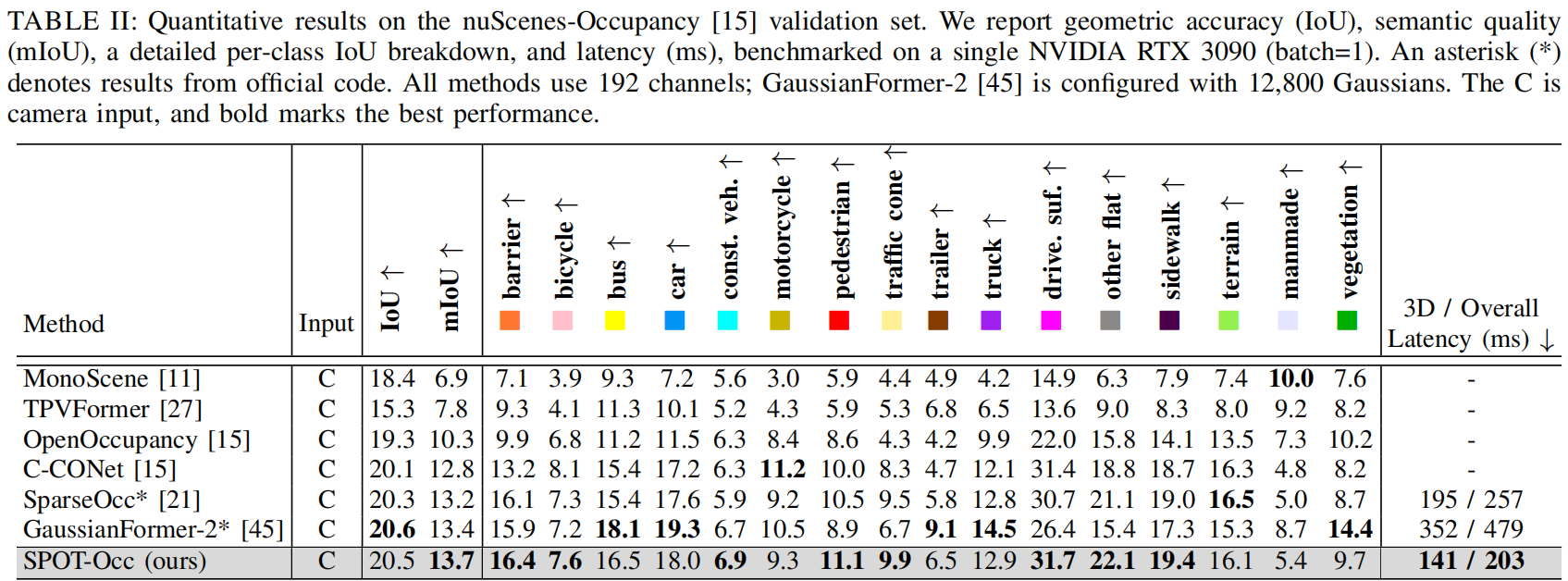
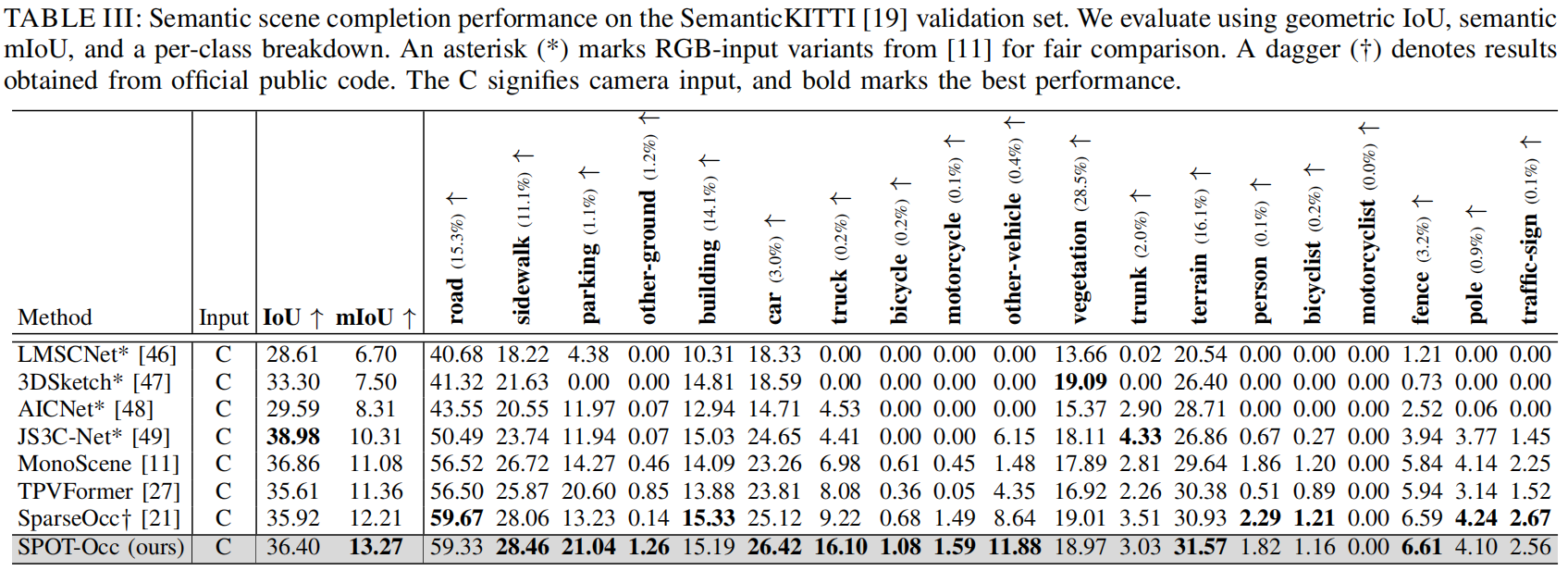
在SemanticKITTI验证集上的语义场景补全:
## 模型库
我们提供了在SemanticKITTI和nuScenes数据集上的预训练权重。
| 模型 | 数据集 | 主干网络 | SSC mIoU | 模型权重 | 训练日志 | 推理日志 |
| :--- | :--- | :--- | :---: | :---: | :---: | :---: |
| [SparseOcc(基线)](projects/configs/baseline/sparseocc_nusc_256.py) | nuScenes | ResNet50 | 13.2 | [链接](https://pan.baidu.com/s/1Baydxdv1CaGSpSeXmy9i2Q?pwd=96rg) | [链接](log/training/nusc_origin_tr.log) | [链接](log/inference/nusc_origin_in.log) |
| [SpotOcc(我们的方法)](projects/configs/spotocc/spotocc_nusc_256.py) | nuScenes | ResNet50 | 13.7 | [链接](https://pan.baidu.com/s/1rkY-oBFtxntrNWSI5bZM0A?pwd=spot) | [链接](log/training/nusc_spot_tr.log) | [链接](log/inference/nusc_spot_in.log) |
| [SparseOcc(基线)](projects/configs/baseline/sparseocc_kitti.py) | SemanticKITTI | EfficientNetB7 | 12.2 | [链接](https://pan.baidu.com/s/1g8xYs1xQWcD1xqmf7cX9HA?pwd=mgpj) | [链接](log/training/kitti_origin_tr.log) | [链接](log/inference/kitti_origin_in.log) |
| [SpotOcc(我们的方法)](projects/configs/spotocc/spotocc_kitti.py) | SemanticKITTI | EfficientNetB7 | 13.3 | [链接](https://pan.baidu.com/s/1HulqJSy01L_2Pi10ldwH_A?pwd=spot) | [链接](log/training/kitti_spot_tr.log) | [链接](log/inference/kitti_spot_in.log) |
## 快速入门
- [安装说明](docs/install.md)
- [数据准备](docs/prepare_dataset.md)
- [训练与评估](docs/train_and_eval.md)
## 引用
如果您觉得这项工作有用,请考虑引用:
```
@article{spotocc2026,
title={SPOT-Occ: Sparse Prototype-guided Transformer for Camera-based 3D Occupancy Prediction},
author={Chen, Suzeyu and Li, Leheng and Chen, Ying-Cong},
journal={arXiv preprint arXiv:2602.04240},
year={2026}
}
```
## 致谢
本项目基于以下开源项目开发:[BEVDet](https://github.com/HuangJunJie2017/BEVDet)、[BEVFormer](https://github.com/fundamentalvision/BEVFormer)、[Mask2Former](https://github.com/facebookresearch/Mask2Former)、[OccFormer](https://github.com/zhangyp15/OccFormer)、[OpenOccupancy](https://github.com/JeffWang987/OpenOccupancy)、[SparseOcc](https://github.com/VISION-SJTU/SparseOcc)。感谢他们的出色工作。
标签:3D占用预测, 3D场景理解, Apex, Transformer, Vectored Exception Handling, 准确性, 凭据扫描, 占用网格, 原型学习, 实时预测, 引导选择, 摄像头感知, 机器学习, 模型优化, 注意力机制, 深度学习, 特征聚合, 稀疏注意力, 稀疏表示, 聚焦聚合, 自动驾驶, 自动驾驶感知, 解码器, 计算机视觉, 逆向工具, 速度优化, 高效解码