vllm-project/vllm-omni
GitHub: vllm-project/vllm-omni
一个高效的全模态模型推理和服务框架,在 vLLM 基础上扩展支持图像、视频、音频等多模态输入输出及 Diffusion 等非自回归架构。
Stars: 5195 | Forks: 1134

Easy, fast, and cheap omni-modality model serving for everyone
| 文档 | 用户论坛 | 开发者 Slack | 微信 | 论文 | 幻灯片 |
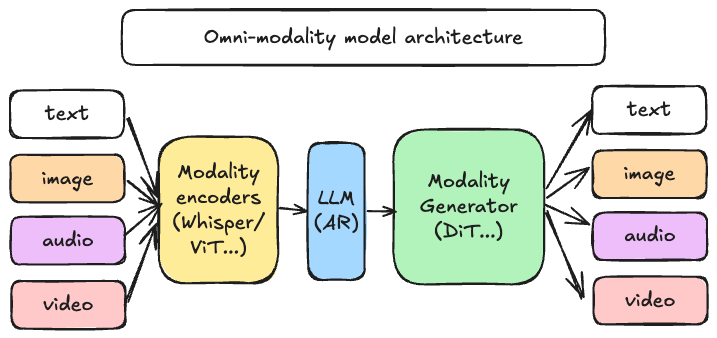
*最新动态* 🔥 - [2026/03] 查看我们在 vLLM 香港聚会上的首次公开[项目深入解析](https://youtu.be/sgwNfsNnR9I)! - [2026/03] **[vllm-omni-skills](https://github.com/hsliuustc0106/vllm-omni-skills)** 是一个社区驱动的 AI 助手技能集合,旨在帮助开发者更高效地使用 vLLM-Omni。这些技能可用于 **Cursor IDE**、**Claude**、**Codex** 等流行的智能体 AI 编程助手。 - [2026/02] 我们发布了 [0.16.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.16.0) —— 这是一个重大的对齐与能力更新版本,基于 **upstream vLLM v0.16.0** 进行了变基,并显著扩展了 **Qwen3-Omni / Qwen3-TTS**、**Bagel**、**MiMo-Audio**、**GLM-Image** 和 **Diffusion (DiT) 图像/视频技术栈**的性能、分布式执行和生产就绪性——同时还改进了平台覆盖范围 (CUDA / ROCm / NPU / XPU)、CI 质量和文档。 - [2026/02] 我们发布了 [0.14.0](https://github.com/vllm-project/vllm-omni/releases/tag/v0.14.0) —— 这是 vLLM-Omni 的首个**稳定版本**,扩展了 Omni 的扩散 / 图像-视频生成和音频 / TTS 技术栈,改进了分布式执行和内存效率,并拓宽了平台/后端覆盖范围 (GPU/ROCm/NPU/XPU)。它还对服务 API、性能分析与基准测试以及整体稳定性带来了实质性升级。请查看我们最新的[论文](https://arxiv.org/abs/2602.02204)以了解架构设计和性能结果。 - [2026/01] 我们发布了 [0.12.0rc1](https://github.com/vllm-project/vllm-omni/releases/tag/v0.12.0rc1) —— 一个主要的 RC 里程碑,专注于完善 Diffusion 技术栈、加强 OpenAI 兼容的服务、扩展全才模型覆盖范围,并提升跨平台 (GPU/NPU/ROCm) 的稳定性。 - [2025/11] vLLM 社区正式发布了 [vllm-project/vllm-omni](https://github.com/vllm-project/vllm-omni),旨在支持全才模型服务。 ## 关于 [vLLM](https://github.com/vllm-project/vllm) 最初旨在支持基于文本的自回归生成任务的大型语言模型。vLLM-Omni 是一个框架,扩展了其对全才模型推理和服务的支持: - **全才模型**:文本、图像、视频和音频数据处理 - **非自回归架构**:将 vLLM 的 AR 支持扩展到 Diffusion Transformers (DiT) 和其他并行生成模型 - **异构输出**:从传统的文本生成到多模态输出{kind=link}
标签:AI推理加速, CUDA, Diffusion Transformer, DiT, LLM推理引擎, Omni-modality, Petitpotam, Qwen3-Omni, ROCm, Spyse API, Vectored Exception Handling, vLLM, 全模态模型, 凭据扫描, 分布式执行, 多模态大模型, 大模型服务, 模型推理框架, 模型服务化, 深度学习部署, 视频生成, 语音合成TTS, 逆向工具, 高性能推理