cotab-org/cotab
GitHub: cotab-org/cotab
一款完全本地运行的 VS Code AI 代码补全插件,在保护代码隐私的同时提供智能多行补全、自动注释和翻译功能。
Stars: 1 | Forks: 0
# Cotab
[English](README.md) | [日本語](README.ja.md)
此 VS Code 扩展是一款 AI 驱动的多行自动补全插件,设计时充分考虑了最大程度的隐私和安全性。它完全在本地 LLM 上运行,并专为在消费级 PC 上工作而开发。
Cotab 专注于考虑编辑意图的自动补全。除了整个文件的上下文外,它还考虑外部符号、错误和先前的编辑,使用 AI 生成多行代码建议并作为自动补全呈现。
**只需单击一下即可完成设置,并立即可以使用。** 此外,您可以单击一下切换要使用的模型,Qwen3-Coder-30B-A3B 可以在 VRAM 4GB 或 8GB 环境中运行。
[入门指南](#getting-started) | [问题 / 想法 / 反馈](https://github.com/cotab-org/cotab/discussions) (English / 日本語OK)
## 自动补全
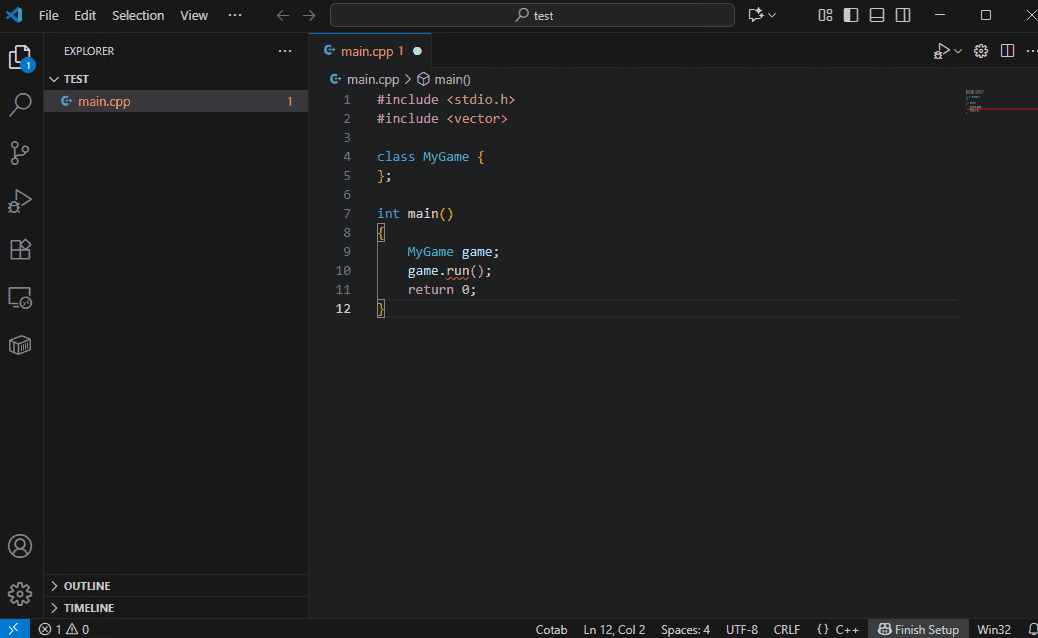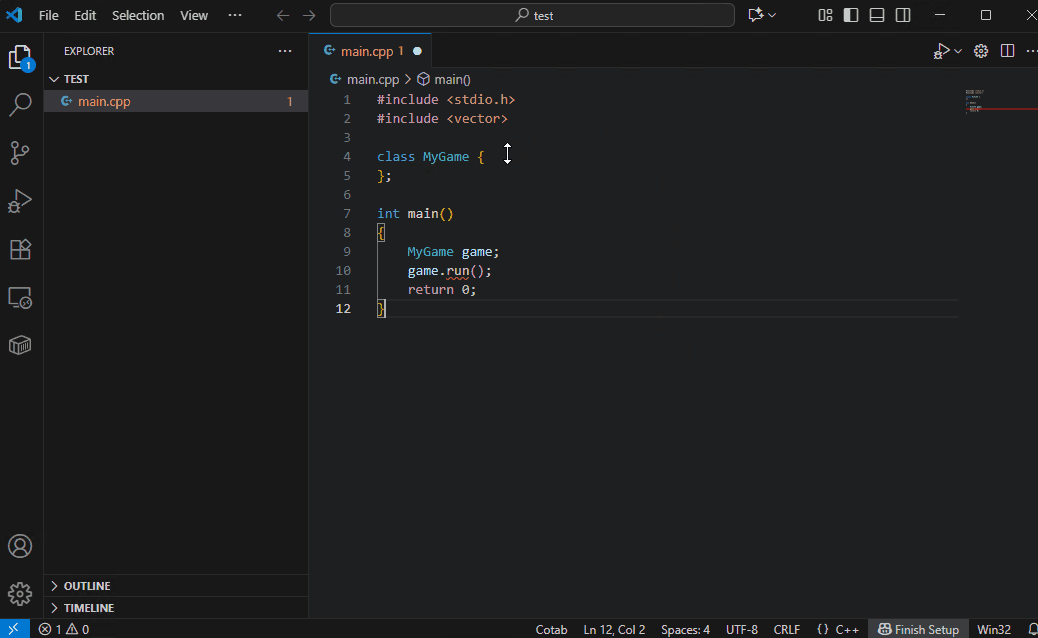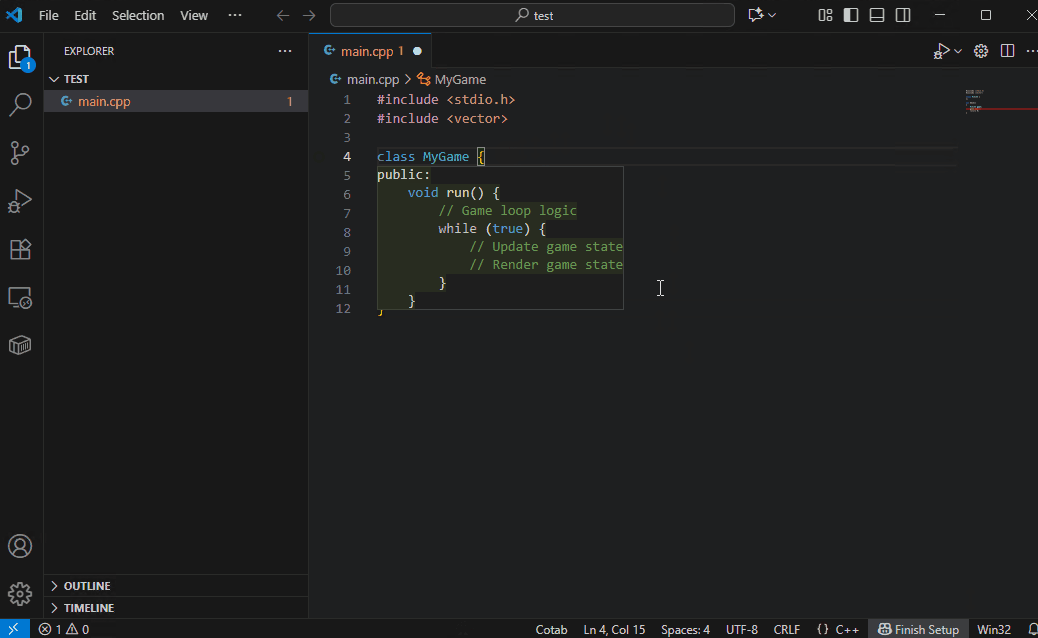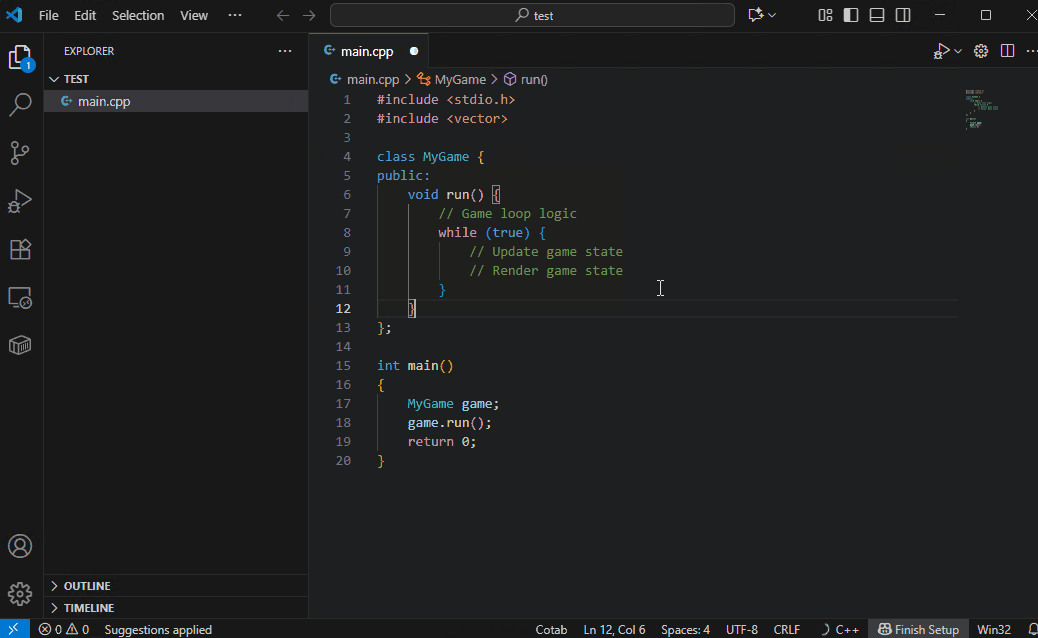
支持的编程语言取决于 AI 模型。尽管体积小巧,默认模型 Qwen3-4B-Instruct-2507 支持多种语言。
Qwen3-Coder-30B-A3B 支持更多语言,并且像魔法一样,准确建议您即将输入的代码。
## 自动注释模式
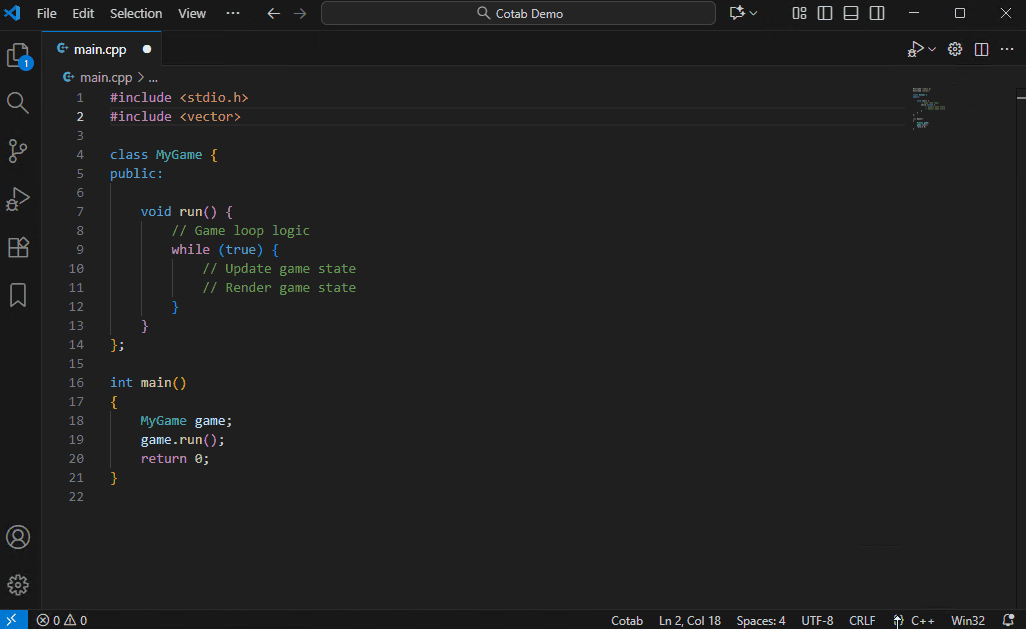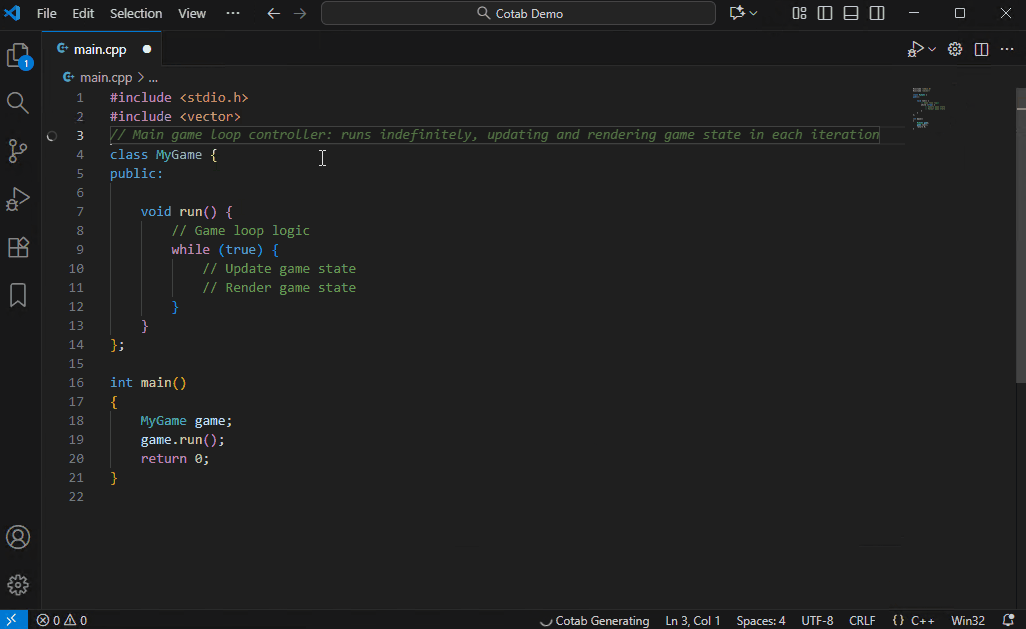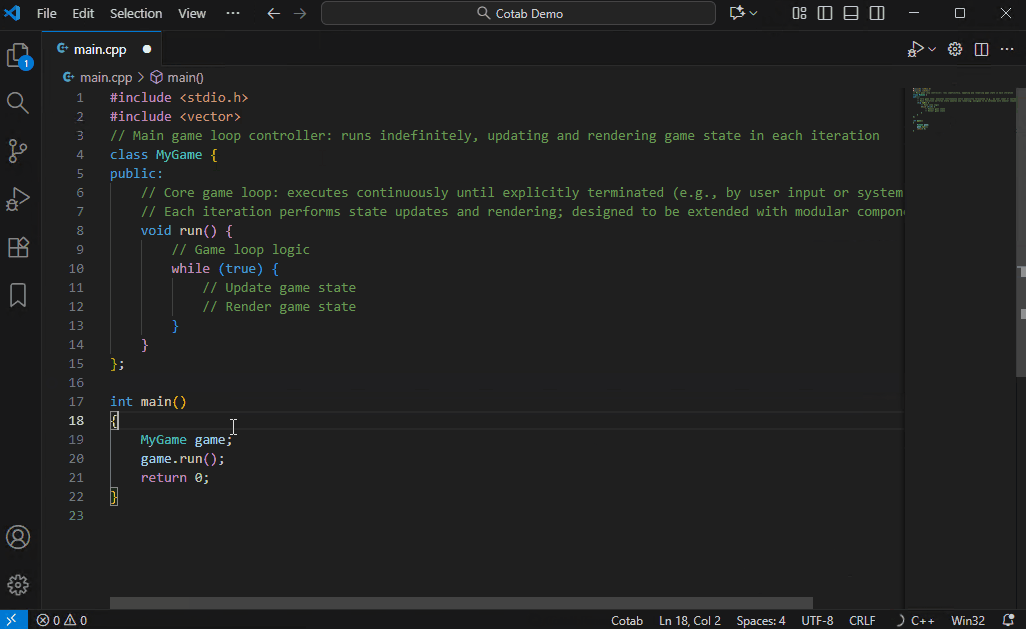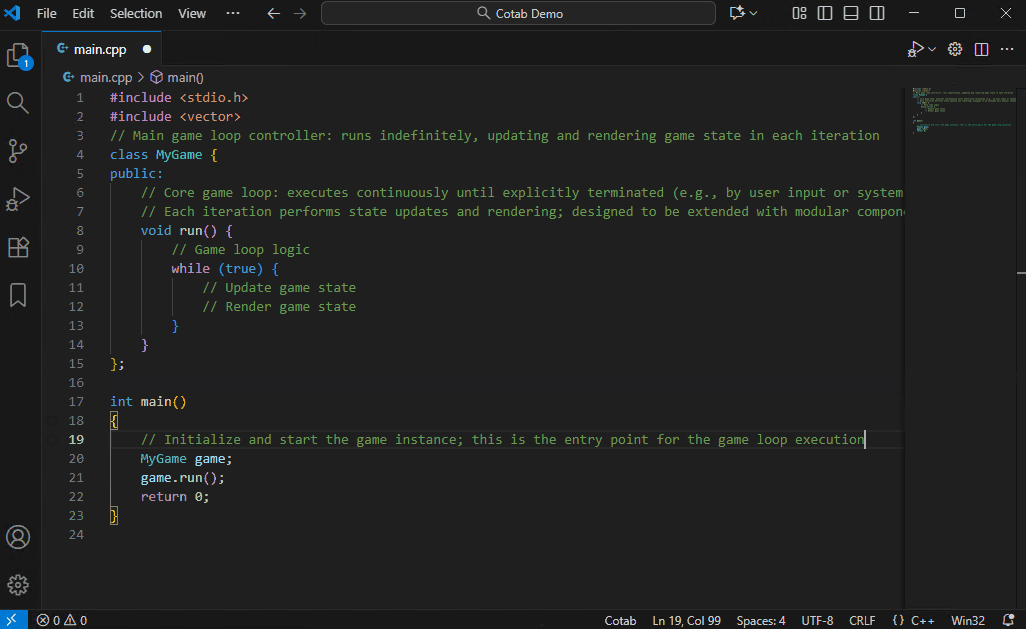
一种用于添加代码注释的专用模式。它比普通模式更深入地分析代码,理解算法意图,并自动添加详细注释。
Qwen3-4B-Instruct-2507 已经能提供不错的注释,但由于此用例可以容忍速度变慢,我们推荐使用 Qwen3-Coder-30B-A3B 以获得最佳效果。
## 自动翻译模式
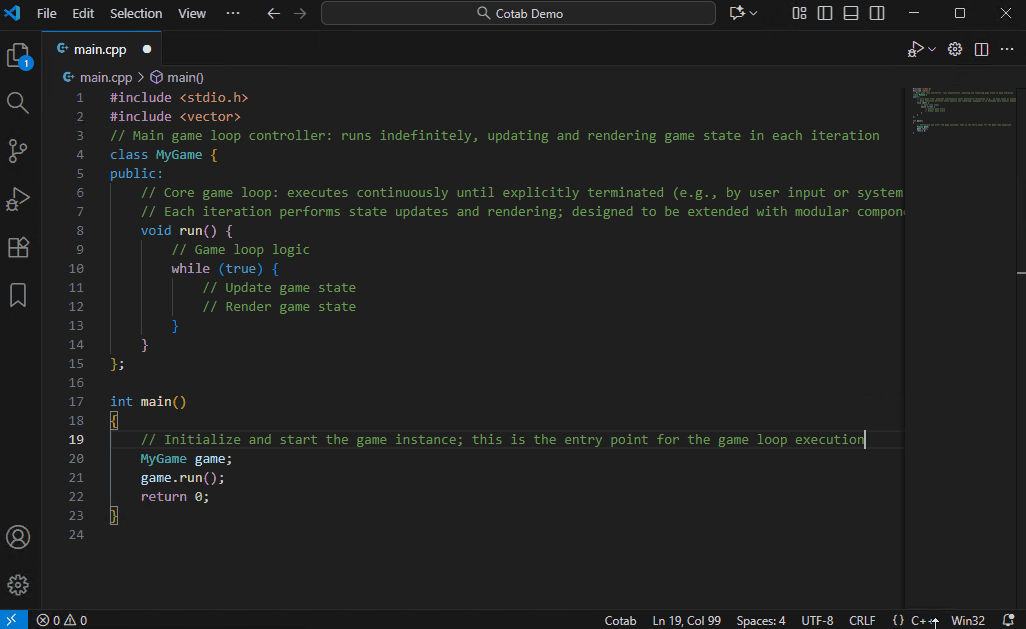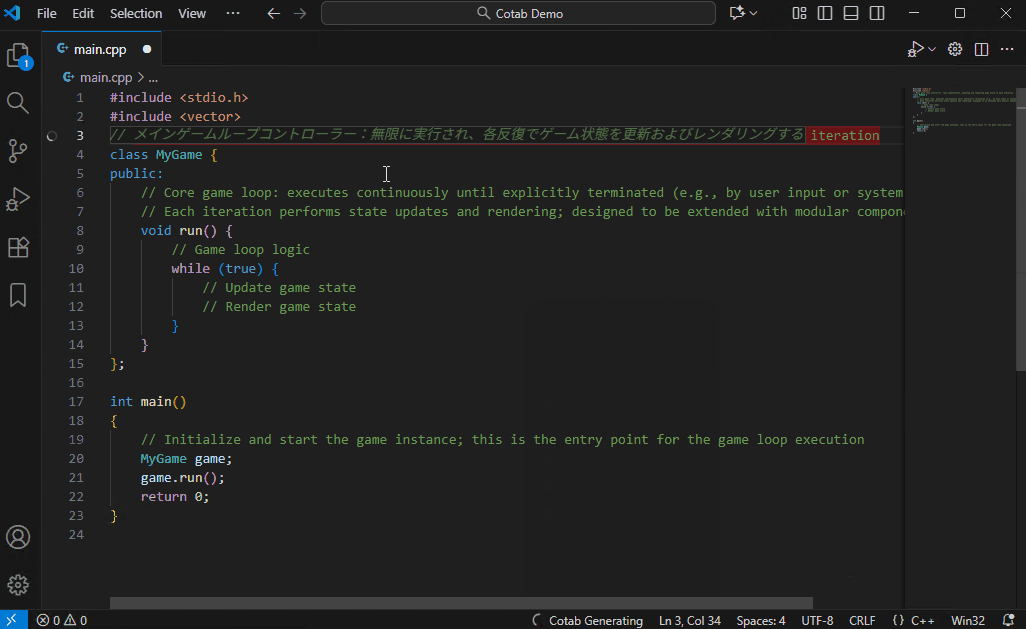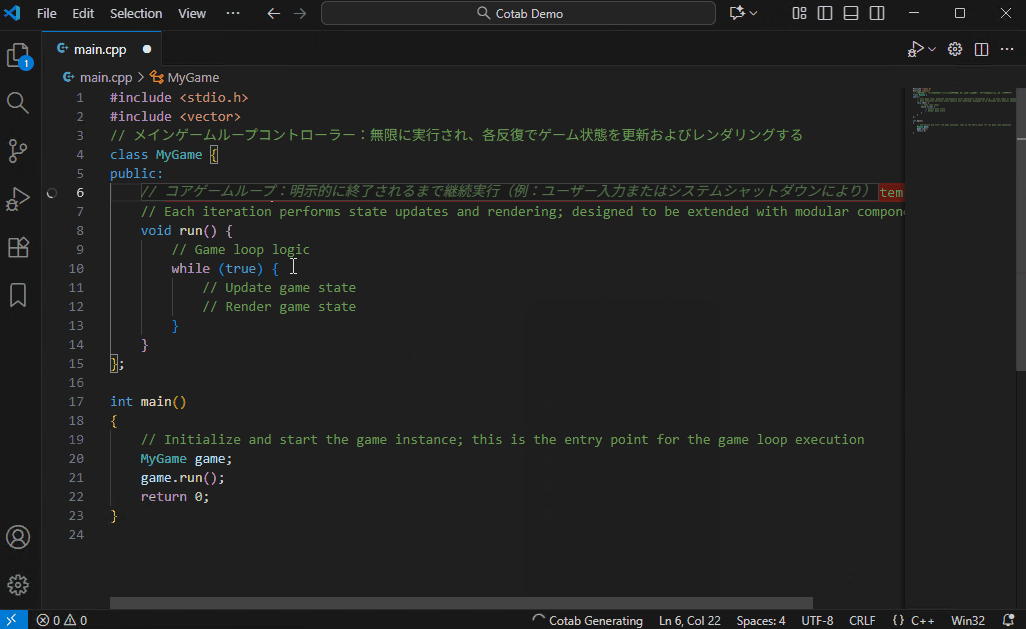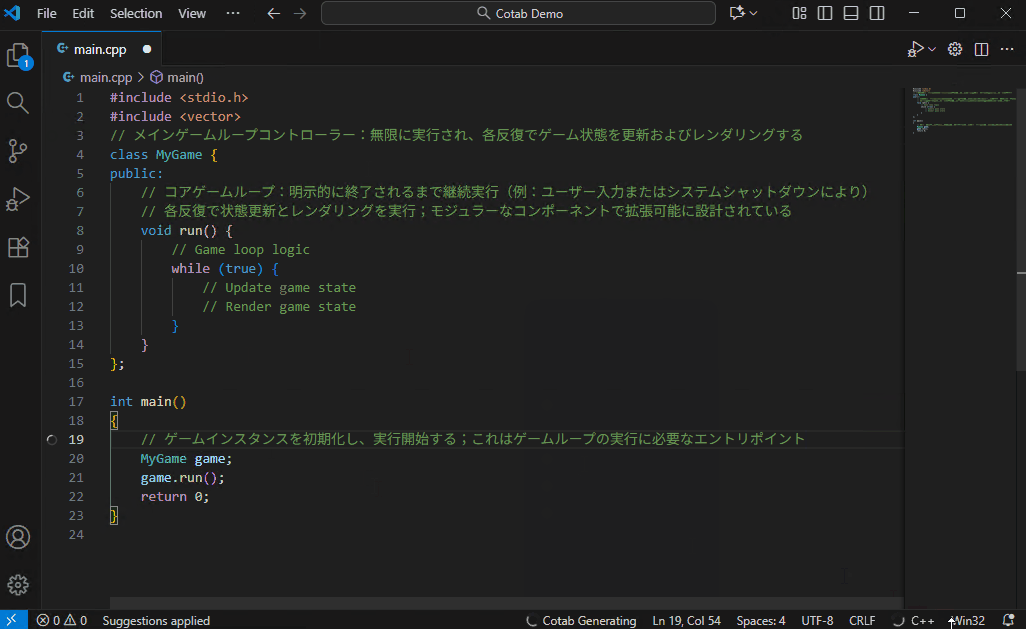
一种仅用于翻译的模式。它不仅可以翻译代码注释,还可以翻译常规文本文件。
Qwen3-4B-Instruct-2507 也能提供高质量的翻译,但在这种用例中,由于可以容忍性能下降,建议使用 Qwen3-Coder-30B-A3B 以获得最佳效果。
## 功能特性
- 优先考虑隐私,使用本地 LLM 完全离线运行
- 提供专注于内联建议的功能
- 不仅建议从光标位置开始的内联补全,还建议多行编辑
- 根据目标文件的全部内容、其他文件的符号和编辑历史提供 suggestions
- 提供针对 llama-server 优化的快速响应
- 还有自动注释和自动翻译模式。
- 开源,确保透明度
## 入门指南
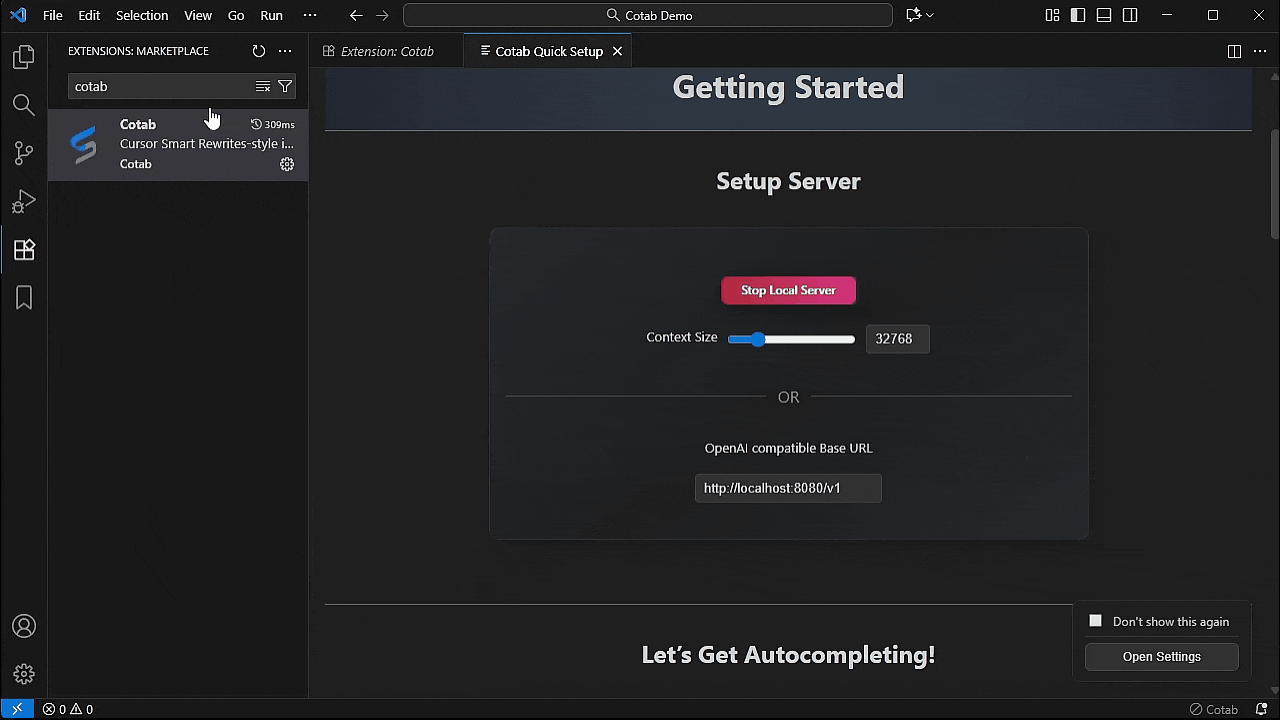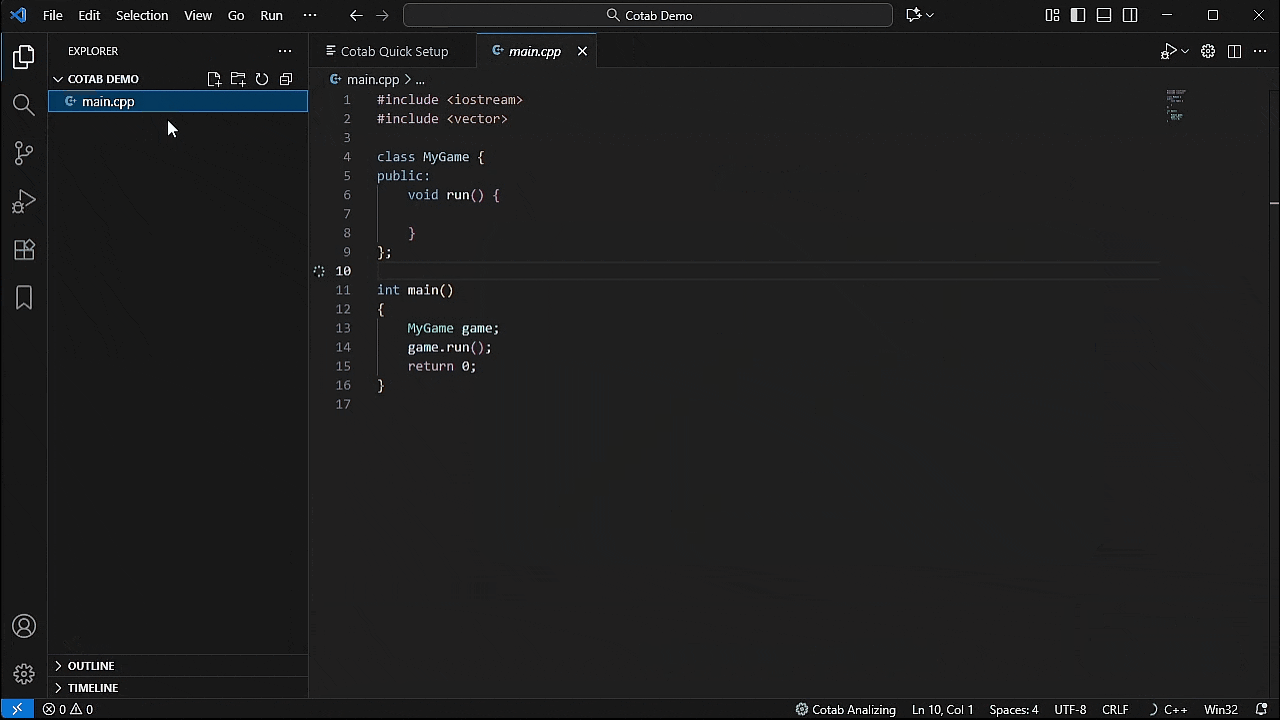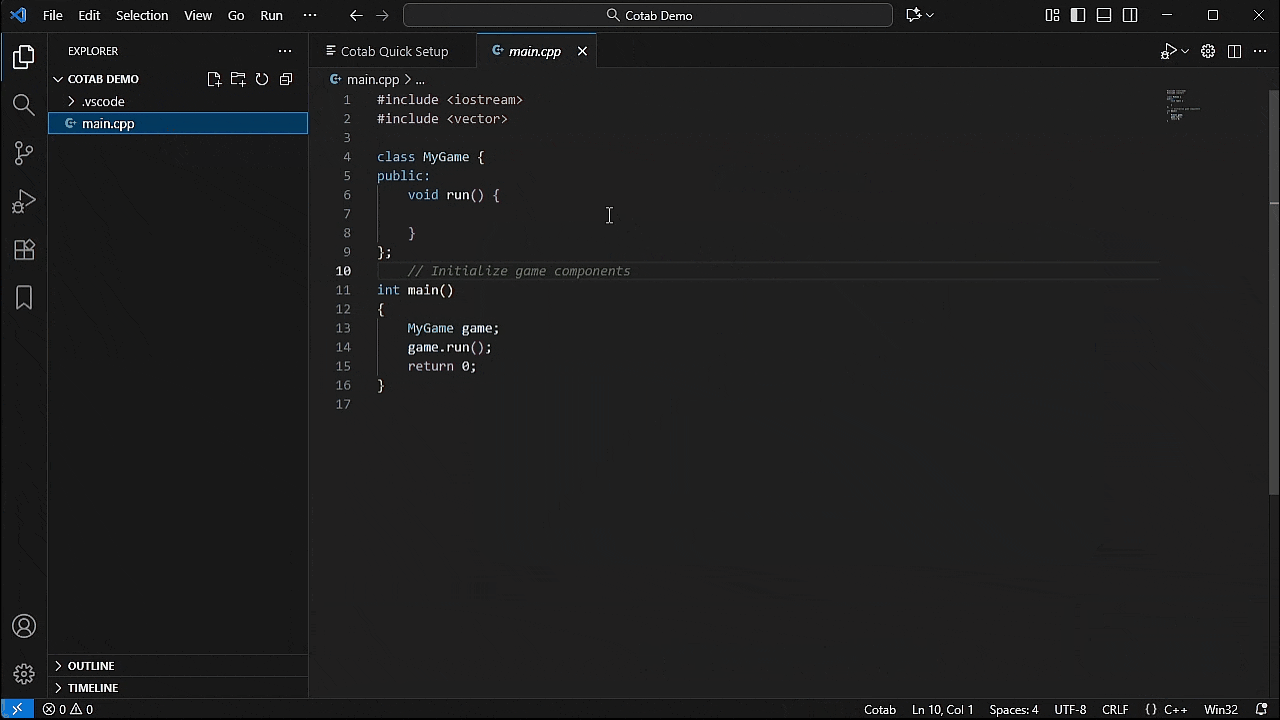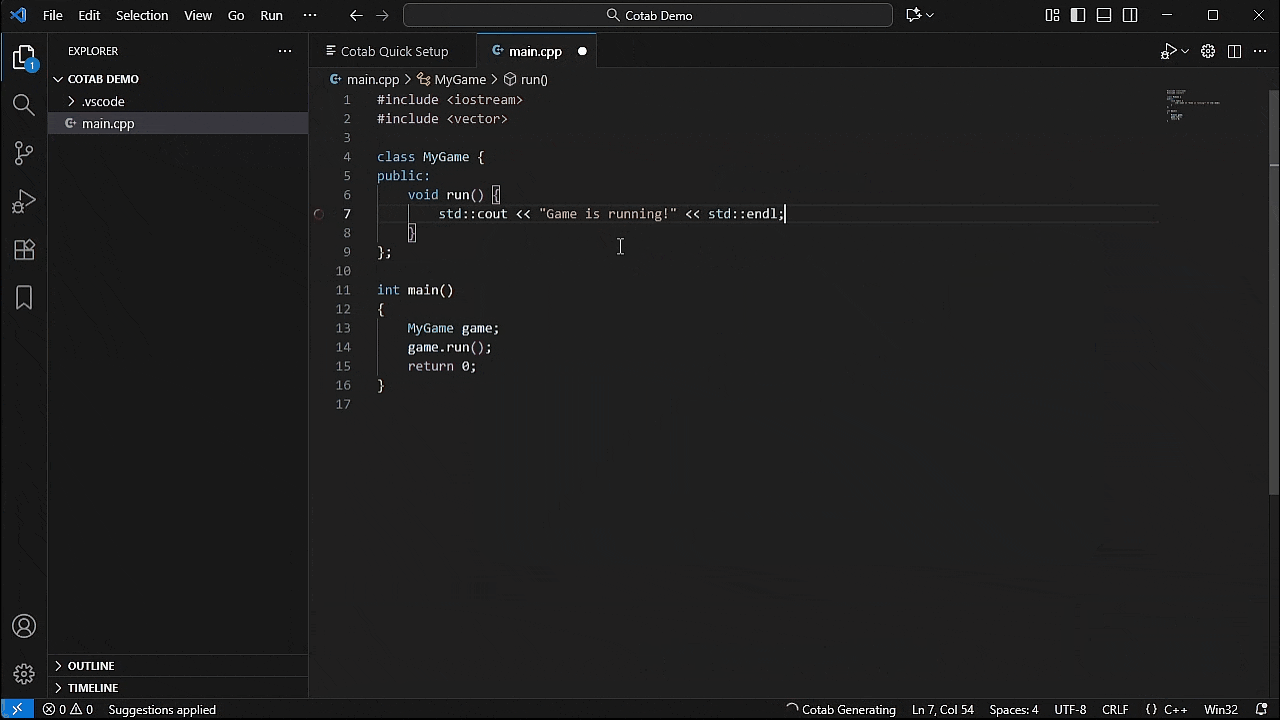
1. 通过 [VS Code 市场](https://marketplace.visualstudio.com/items?itemName=cotab.cotab)安装 Cotab
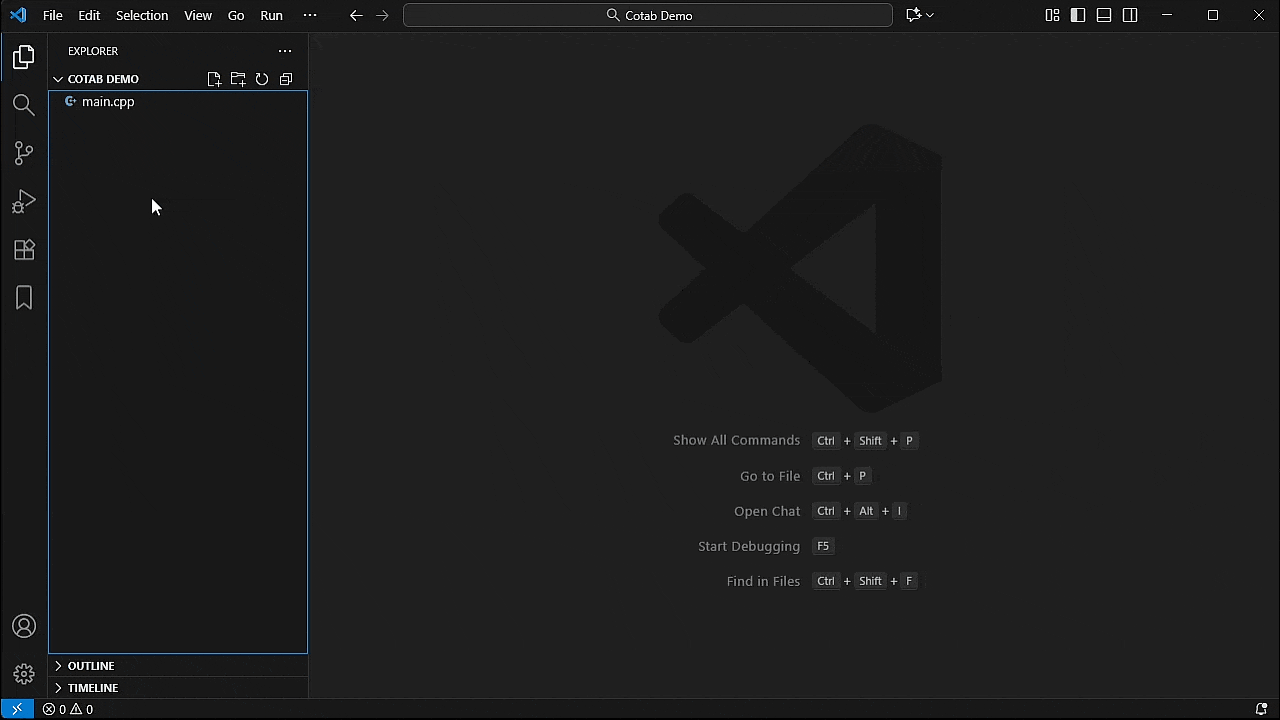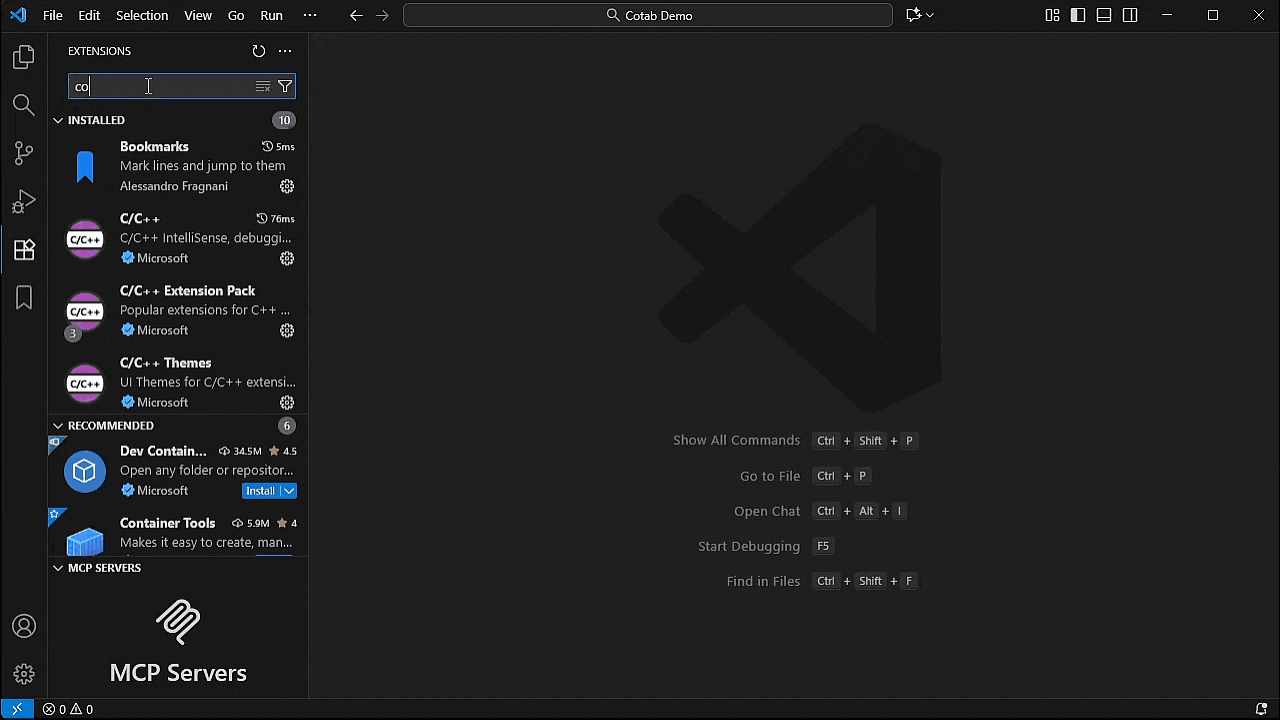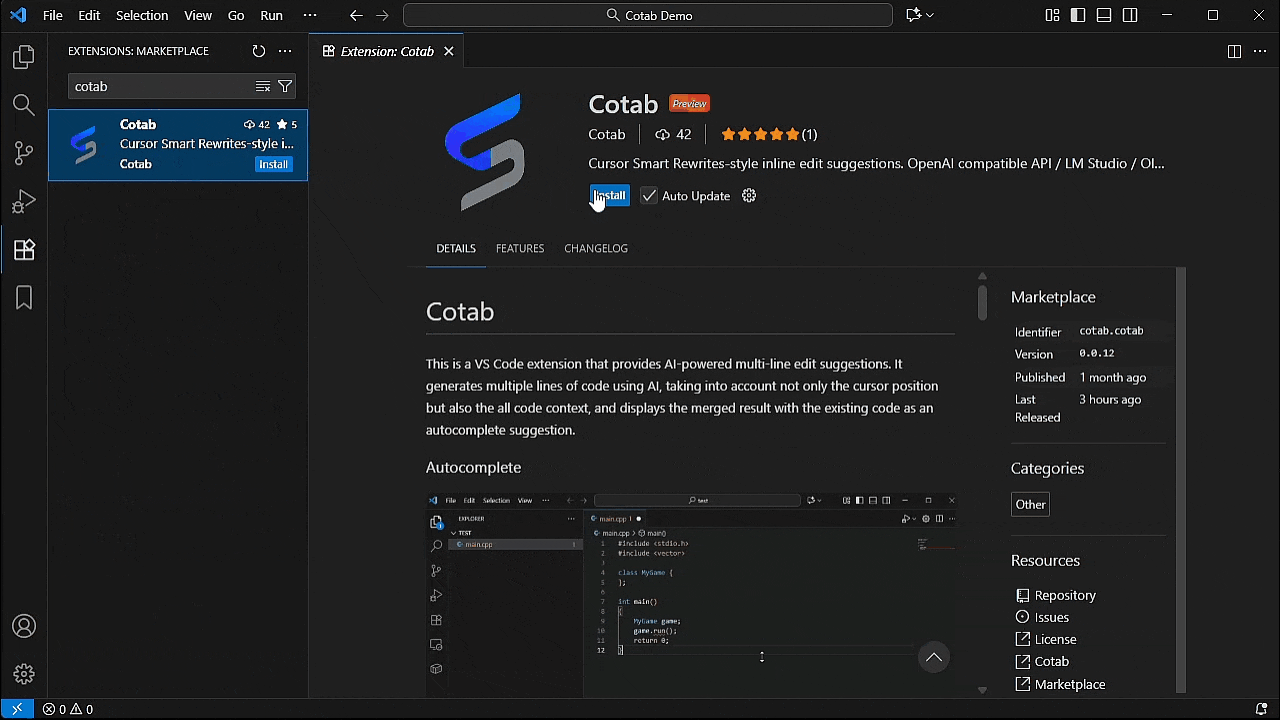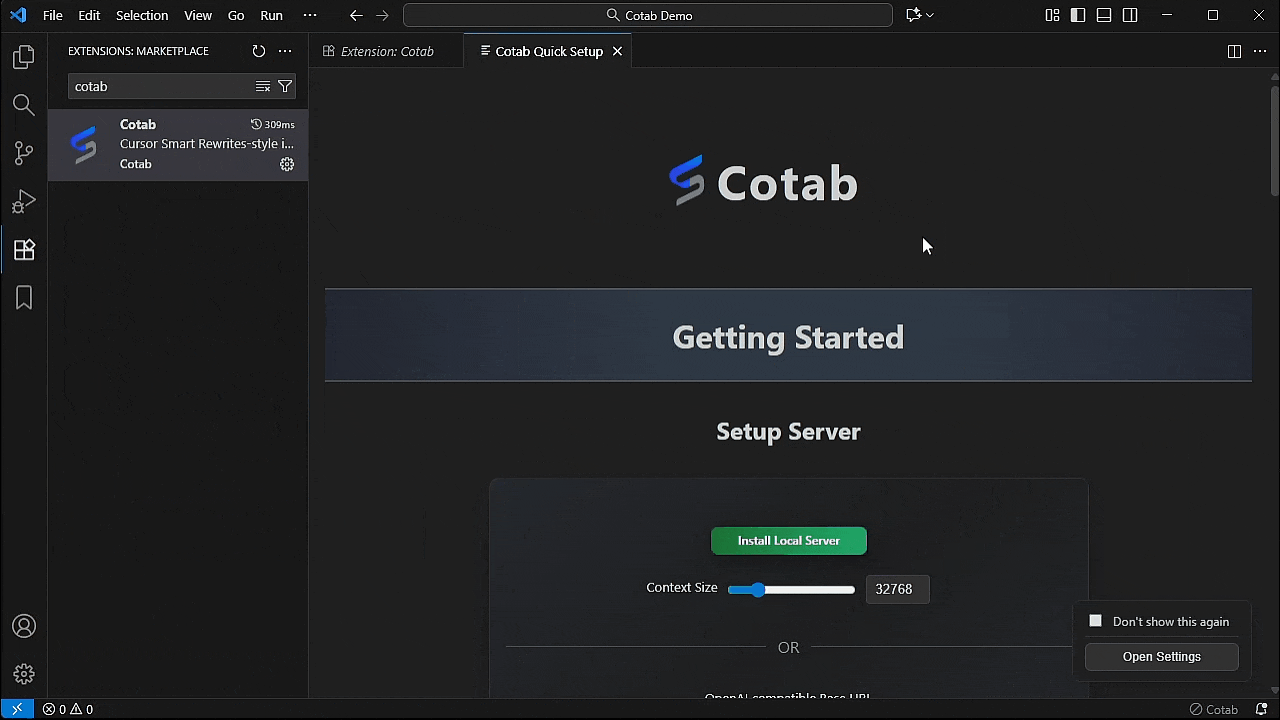
2. 点击 "Install Local Server" 按钮或配置您的 api。
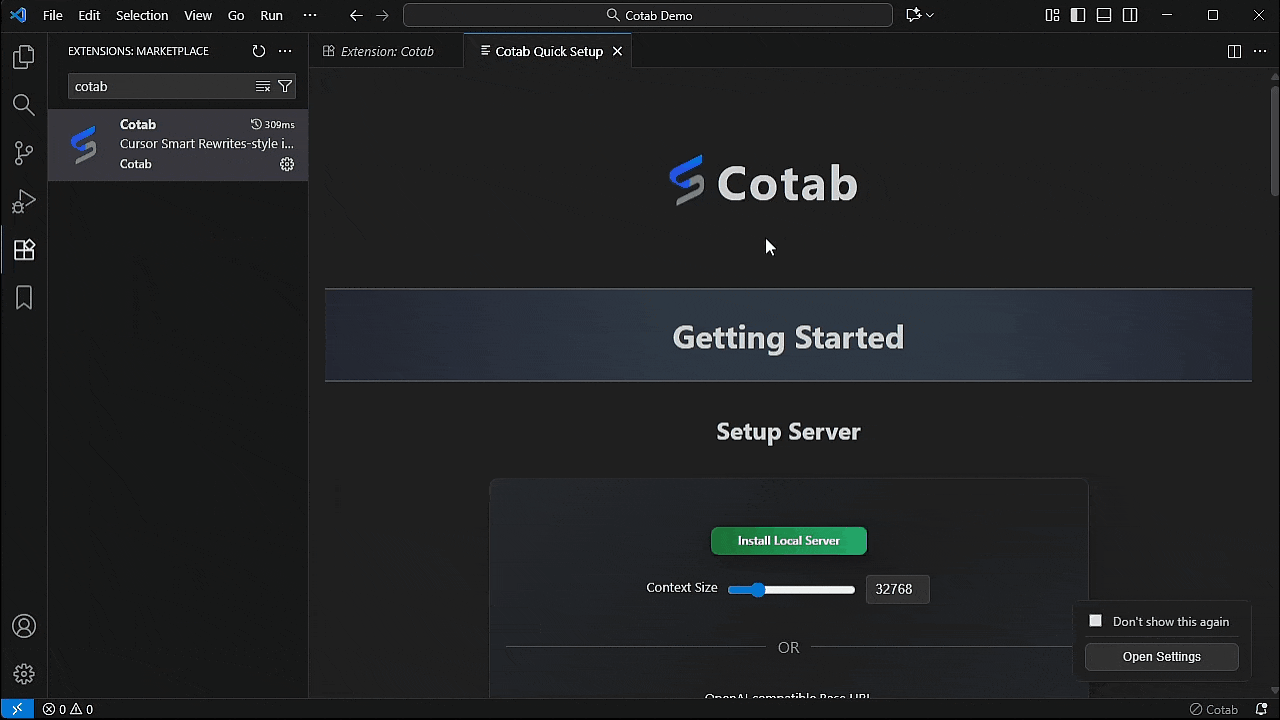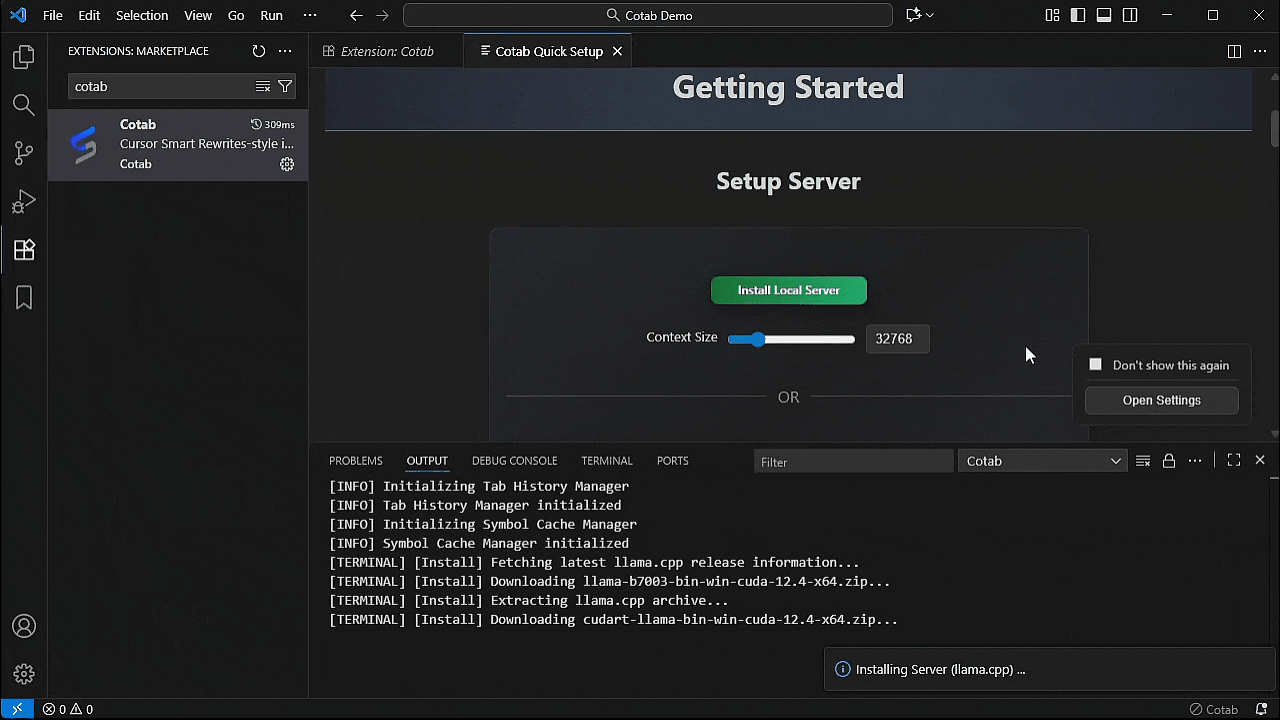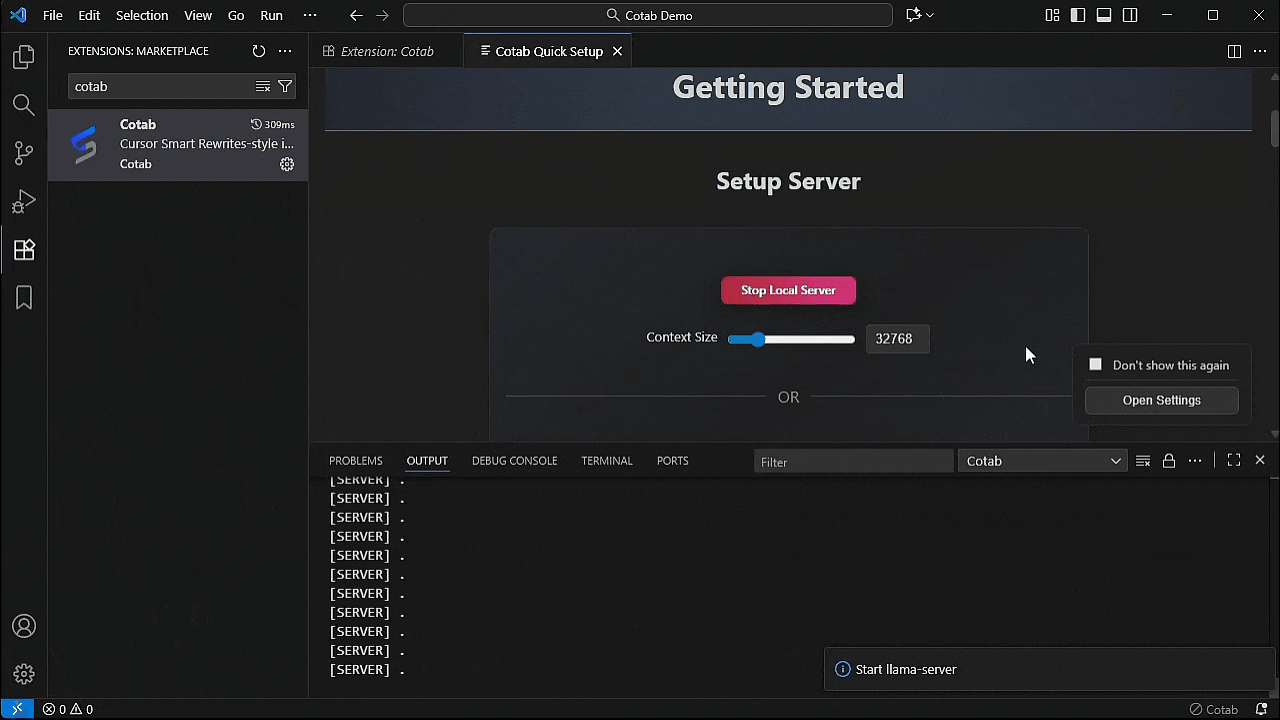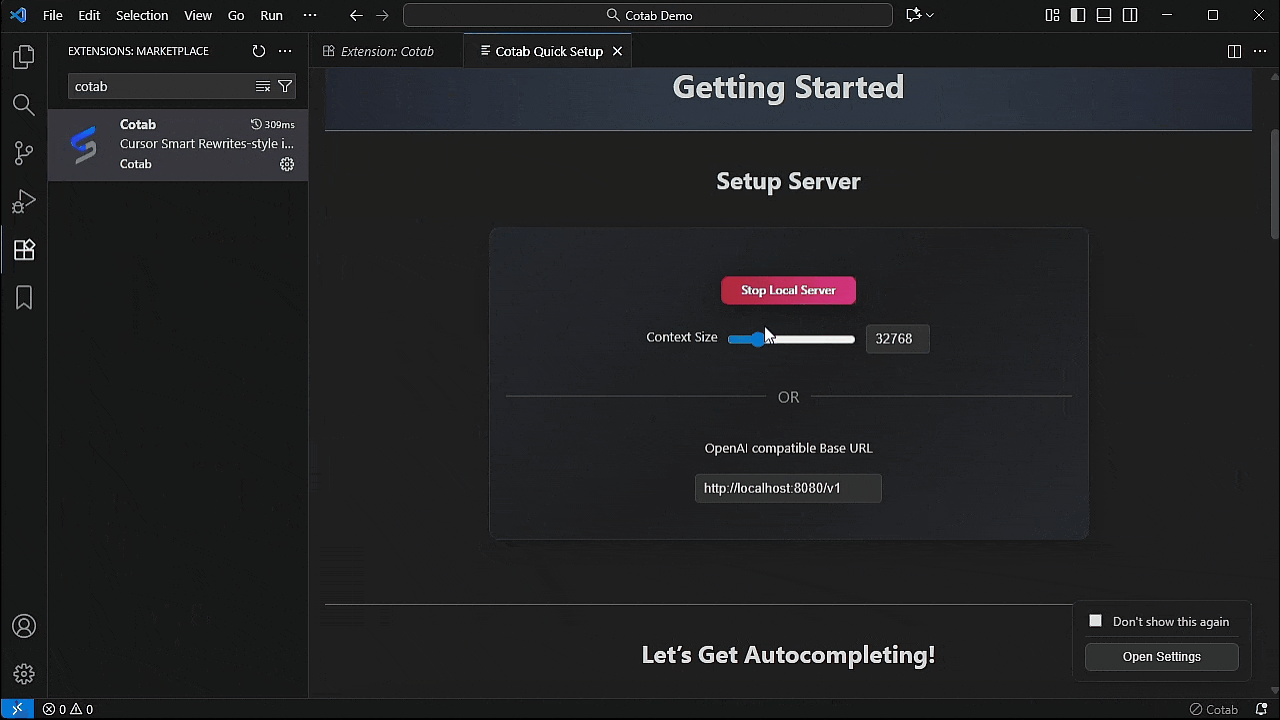
注意:
- 第一次可能需要一些时间,因为它会下载 2.5GB 的模型。
- 服务器在安装后自动启动。
- 支持的安装平台 Windows/MacOS/Ubuntu
3. 开始输入!
|命令|键位绑定|
| ---- | ---- |
|Accept All|Tab|
|Accept First line|Shift + Tab|
|Reject|Esc|
注意:
- 通过拒绝,您可以更改下一个补全候选项。
- 斜体显示覆盖层意味着 AI 仍在输出结果,结果尚未确定。在大多数情况下,它与最终结果相同,但在斜体显示的情况下,合并结果可能存在问题。
## 重要提示
- 请求通常涉及超过 10,000 token 的提示。
- 针对 llama-server 进行了优化;我们强烈建议使用 llama-server
- **在使用按量付费 API 服务器时要特别小心,因为 token 消耗可能非常快**
- 使用本地服务器时,**我们强烈建议单用户使用**
本地服务器针对**单用户**进行了优化。
多用户同时使用将显著影响推理,并严重降低响应速度
## 使用技巧
- 先写注释
默认模型 (Qwen3-4B-Instruct-2507) 虽然体积小巧但功能强大,但它并非专为代码补全而设计。与许多现代云服务不同,它可能不会立即建议您想要编写的确切代码。在这种情况下,先写一段描述您想要代码的注释将有助于模型根据您的描述生成更精确的代码建议。
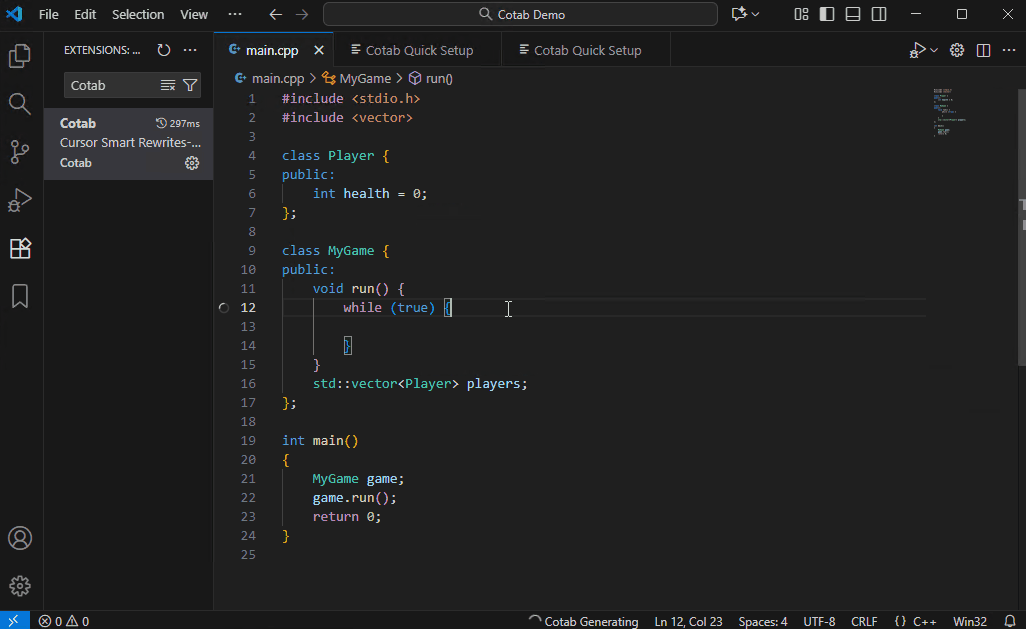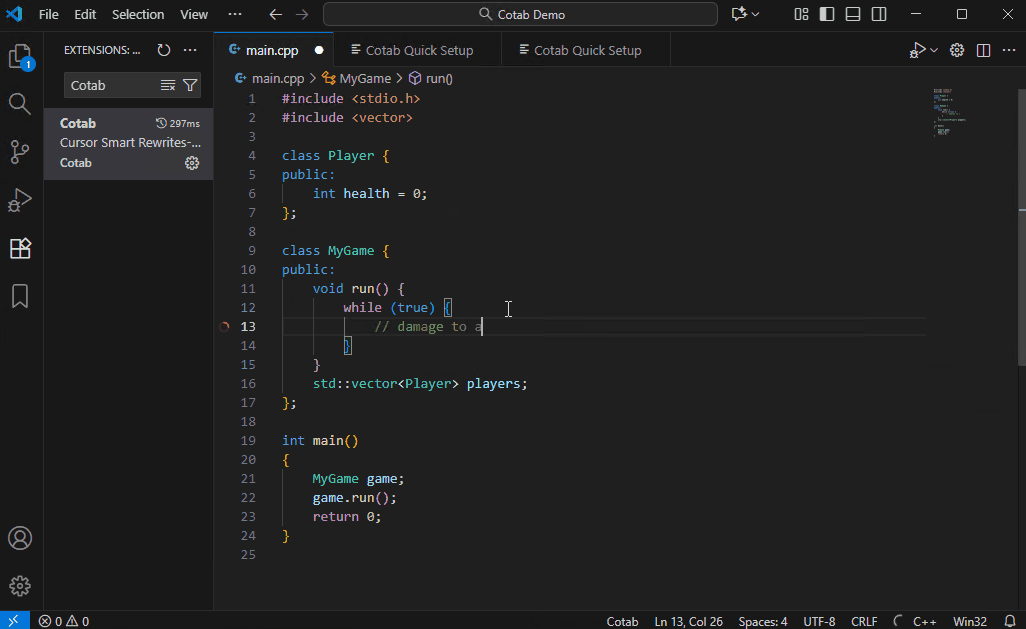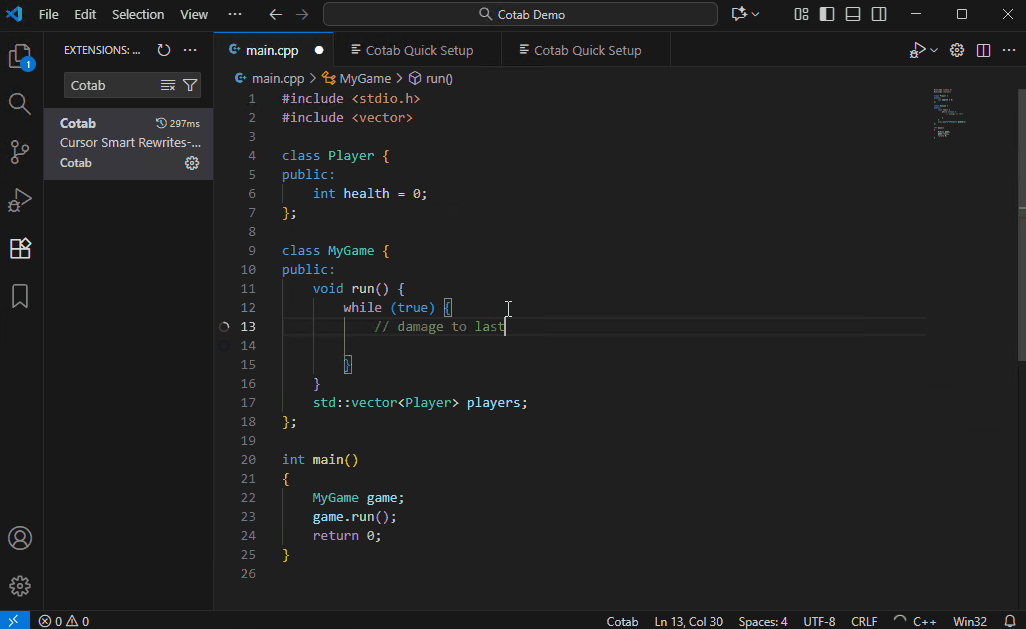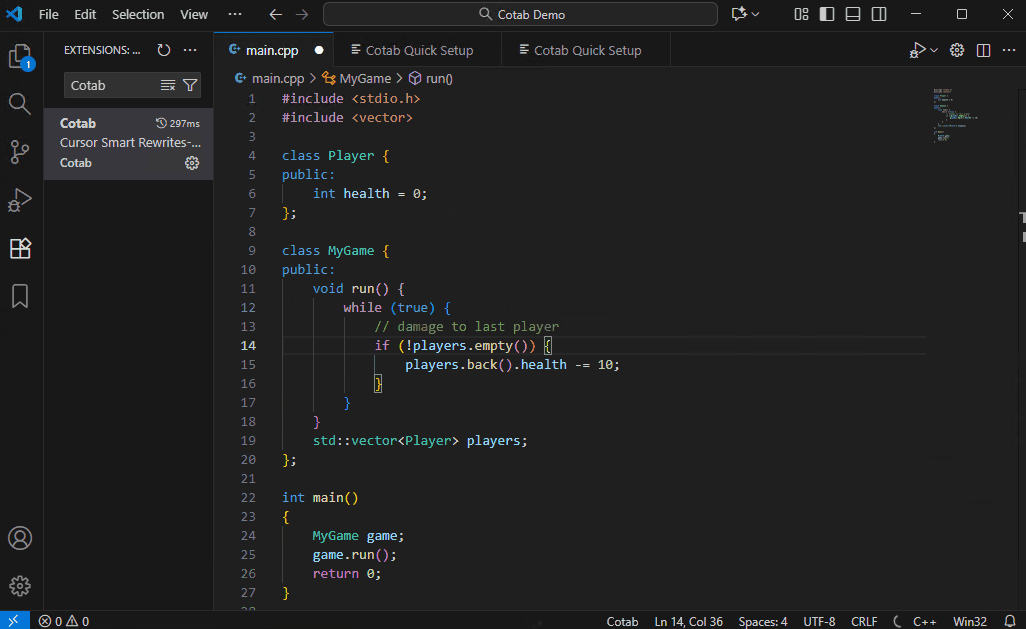
- 编辑 Prompt
虽然模型质量很重要,但补全准确性很大程度上取决于 prompt 内容。通过自定义 prompt,您可能可以进一步提高准确性。
此外,您可以创建自己的自定义模式。
要编辑 prompt,请从菜单中打开它。默认 prompt 已被注释掉。取消注释、编辑并保存,更改将立即反映在补全中。

## 性能
- **推荐:** GeForce RTX 3000 系列或更高版本 GPU(或同等产品)以获得最佳性能。
- Cotab 针对 llama-server 和 Qwen3-4B-Instruct-2507 进行了优化,旨在实现高速运行。在包含数百个外部引用符号、超过 1,000 行源代码的实际环境中,prompt 超过 15,000 token。即使在这种情况下,它也能理解整个上下文,并在 GeForce RTX 4070 上从第二个请求开始在大约 0.5 秒内显示补全。
- GeForce RTX 3000 系列及更高版本的 AI 处理显示出显著的性能提升。为了获得流畅的响应,我们推荐 GeForce RTX 3000 系列或更高版本的 GPU 或同等产品。
## 详情
- llama-server
您也可以使用 OpenAI 兼容 API,但我们强烈建议使用 llama-server。llama-server 开销低,在使用 llama.cpp 作为后端的服务器中运行速度高。[查看详情](#using-remote-servers)
- Prompt 优化
llama-server 有一种默认启用的机制,可以缓存先前请求的 prompt。Prompt 缓存在与先前 prompt 匹配的部分有效,从而允许跳过该部分之前的 prompt 处理。
为了充分利用此机制,prompt 中的原始源代码在用户输入时保持不变。相反,一个包含修改周围代码的最小块会附加到 prompt 的底部。
Prompt 是完全可定制的,您可以单击一下在准备好的模式之间切换。
这允许您针对每个目的使用最佳 prompt 执行补全。
- 编辑历史
记住用户刚才的编辑并在建议中使用它们。编辑分为添加、删除、编辑、重命名和复制,以提高预测准确性。
这使得刚才创建的函数更有可能被建议,从而更准确地反映用户意图。
- 来自其他文件的符号
使用可从 VSCode 语言提供程序获取的符号,并在建议中使用它们。这些符号允许 LLM 理解类结构并提高成员函数建议的准确性。
注意:符号按 VS Code 中查看文件的顺序输入。
- 错误问题
使用诊断错误作为输入来生成修复错误的代码。
即使使用小型 AI 模型,它也会学习纠正错误,因此建议的质量会进一步提高。
- 代码摘要
通过预先总结源代码并将结果合并到 prompt 中,我们可以实现更深层次的理解。
此功能默认禁用。因为即使没有摘要也能保证补全质量,因为会输入整个代码。
- 进度图标说明
|图标|说明|
| ---- | ---- |
||正在分析源代码|
||正在补全当前行|
||正在补全当前行之后|
## 关于可用模型
所有文本生成模型都可用,但本地代码生成需要强大的指令遵循(instruction-following)能力。(指令遵循性能是指严格遵守 prompt 规则并避免违规的能力。)
- Qwen3-Coder-30B-A3B
该模型 80% 用于代码学习,提供高质量的补全。由于实际计算量相当于 3B,它像小型模型一样高速运行。此模型可以在不显著降低性能的情况下调整 VRAM 使用量,因此 Cotab 提供了可在 4GB 或 8GB 环境中工作的预设。
- Qwen3-4B-Instruct-2507
尽管其 4B 的体积非常小,但它具有出色的指令遵循能力,并且在数学等领域具有高性能。在 Cotab 中,它提供了良好的补全,让您忘记它的小巧。
- Ministral-3-3B-Instruct-2512
尽管其 3B 的体积非常小,但它具有高性能,并且在使用 VRAM 5GB 的情况下高速运行。如果您的 VRAM 有限,请尝试一下。
- granite-4.0-micro
不建议使用,因为它在 Cotab 中经常生成损坏的补全。
- LFM2-2.6B
它的设计运行速度比 Qwen3-4B-Instruct-2507 快两倍以上,仅需使用 VRAM 3GB。
不建议使用,因为在 Cotab 的代码补全中观察到代码损坏的情况。
但是,当 VRAM 要求非常严格或用于翻译目的时,可以使用它。
## 使用远程服务器
您可以使用 OpenAI 兼容 API 服务器,但出于性能原因,我们强烈建议使用 **llama-server** 或 **llama-swap**。
特别是通过 **llama-swap** 使用 **llama-server** 允许在使用其他聊天插件时自动切换模型。
- **最重要**
- **使用 llama-server 时,请务必指定 "-np 1" 选项。**
在 llama-server 的 2025 年末更新中,已更改为默认运行 4 个并行进程。使用默认的 llama-server,由于 Cotab 高速频繁重复请求和取消,它们会被误认为是完全不同的请求,导致 prompt 缓存不起作用,从而导致性能显著下降。
- **同时指定 "-b 512" 选项。**
对于像 RTX 4070 这样的常见 NVIDIA 游戏 GPU,即使超过 512,性能也几乎不会改变。由于 llama-server 的取消请求在批处理期间不被接受,使用默认的 2048,可能需要几秒钟才能执行取消,从而导致意外的响应下降。
## 隐私和遥测
- Cotab 仅与默认端点 `"http://localhost:8080/v1"` 或用户指定的 LLM API 通信。不会联系任何其他外部服务或服务器。这确保了最大程度的隐私和安全性。
- 仅与配置的 API 进行通信
- 永远不会发送遥测或使用数据
- 用户代码或输入永远不会与第三方共享
- 不收集或存储任何个人信息
- 本项目是开源的,所有源代码均可在 GitHub 上获取
- 有了此政策,您可以完全放心地使用 Cotab。
- 注意:如果您安装本地服务器,它会访问 [llama.cpp github 仓库](https://github.com/ggml-org/llama.cpp/releases)。
## 社区与反馈
💬 欢迎在以下位置提出问题、想法和使用讨论
[GitHub Discussions](https://github.com/cotab-org/cotab/discussions)
(English / 日本語OK)
🐞 如果您发现了错误,请改为提交 Issue。
## 开发 / 贡献
- 欢迎贡献(问题、PR、改进建议)。
- 也欢迎错误修复、优化和分享基准测试结果。
## 如何构建
- 设置要求
请提前安装 VS Code。
- Windows
运行此命令将自动下载并执行设置脚本。不需要任何东西,包括 Git 或 Node.js —— 所有便携版本都会自动下载并设置在 ./workspace 中,项目将被克隆并启动 VS Code:
mkdir cotab
cd cotab
powershell -NoProfile -Command "$f='run-vscode.bat'; (New-Object Net.WebClient).DownloadString('https://github.com/cotab-org/cotab/raw/refs/heads/main/run-vscode.bat') -replace \"`r?`n\",\"`r`n\" | Set-Content $f -Encoding ASCII; cmd /c $f"
在 vscode 中按 F5 开始调试插件。
- Ubuntu
需要 Node.js(v22)。
例如,通过包管理器安装 Node.js v22。
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash -
sudo apt install -y nodejs
Cotab 克隆与配置。
git clone https://github.com/cotab-org/cotab.git
cd cotab
npm install
code .\
在 vscode 中按 F5 开始调试插件。
- MacOS
需要 Node.js(v22)。
例如,在 macos 上安装 Node.js v22。
# 安装 nvm
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# 激活 nvm
\. "$HOME/.nvm/nvm.sh"
# 安装 node.js v22
nvm install 22
node -v
Cotab 克隆与配置。
git clone https://github.com/cotab-org/cotab.git
cd cotab
npm install
code .\
在 vscode 中按 F5 开始调试插件。
- 创建安装包
npx vsce package
## 常见问题
### 为什么开始使用 Cotab 时窗口会短暂闪烁?
窗口短暂闪烁是因为 Cotab 在初始化期间计算字体大小。VS Code 不提供直接获取字符大小的 API,因此 Cotab 使用 Webview 来计算字体大小。这导致开始使用 Cotab 时出现短暂闪烁。
### 模型名称中的 4 和 30B 是什么意思?
它们代表参数数量。B 代表“Billion”(十亿)。例如,4B 表示 40 亿个参数,30B 表示 300 亿个参数。通常,参数越多,模型性能越好,但也会增加内存和计算资源需求。
### 模型名称中的 A3B 是什么意思?
它表示实际计算负载相当于 3B(30 亿参数)。A 代表“Active”。例如,Qwen3-Coder-30B-A3B 是一个 300 亿参数的模型,但推理时的实际计算负载被优化为相当于 3B。这使得模型既能保持 30B 模型的高质量性能,又能实现相当于 3B 模型的推理速度。
### 模型名称中的 Q4 和 Q2 是什么意思?
它们代表量化位数。量化是一种通过降低模型精度来减小文件大小和内存使用的技术。Q4 表示 4 位量化,Q2 表示 2 位量化。数字越小,文件大小和内存使用量越小,但模型质量也会降低。通常认为 Q4 模型在数据大小和质量之间具有最佳平衡。
### Qwen3-Coder-30B-A3B:Q2 会有多大的质量下降?
使用 Qwen3-Coder-30B-A3B:Q2,不会出现频繁语法错误等显著下降。鉴于其在低 VRAM 环境中的性能和准确性优势,我们建议在实践中尝试一下。
### 补全不能扩展到视图之外或避免覆盖现有代码吗?
VS Code 的公共 API 不允许像 Cursor 那样显示超出编辑器视图的内容。它也不允许在行之间添加任意块。GitHub Copilot 使用未公开的内部功能来实现这一点,因此普通插件无法实现与 GitHub Copilot 相当的用户体验。
### 什么是 token?
Token 是 LLM 用来处理文本的基本单位。例如,“Hello”大约是 1 个 token。对于代码,token 数量大约是字符数的三分之一。
## 许可证
Copyright (c) 2025-2026 cotab
Apache License 2.0
标签:LLM, Qwen, Unmanaged PE, VS Code 扩展, 人工智能, 代码生成, 代码翻译, 代码补全, 低显存, 多行补全, 威胁情报, 开发者工具, 本地大模型, 消费级显卡, 渗透测试工具, 用户模式Hook绕过, 离线AI, 端侧推理, 编程辅助, 网络安全, 自动化攻击, 自动注释, 隐私保护