Asvithak07/fake-job-detector
GitHub: Asvithak07/fake-job-detector
基于NLP和线性SVM的虚假招聘信息检测系统,通过Streamlit Web应用帮助求职者和招聘平台自动识别欺诈性招聘广告。
Stars: 0 | Forks: 0
# 🕵️ 虚假招聘信息检测
这是一个基于机器学习和自然语言处理 (NLP) 的应用程序,用于检测招聘信息是**真实的**还是**欺诈性的**。该项目使用先进的文本预处理、TF-IDF 特征工程和线性支持向量机 (SVM) 模型来对招聘广告进行分类,帮助求职者识别潜在的骗局。
## 📌 概述
在线招聘门户网站已成为欺诈性招聘广告的常见目标,这些广告会误导求职者并收集敏感信息。手动验证招聘信息可能既耗时又不可靠。
该项目使用机器学习和 NLP 技术自动化了检测过程。用户可以通过交互式的 Streamlit Web 应用程序输入招聘信息详情,并立即收到预测结果,指示该信息可能是真实的还是虚假的。
## 🚀 功能
* 检测虚假和真实的招聘信息
* 交互式的 Streamlit Web 应用程序
* 基于 NLP 的文本预处理
* 实时预测
* 欺诈关键词检测
* 概率校准的分类模型
* 用户友好的界面
## 📊 数据集
该项目使用 **Fake Job Postings Dataset**,其中包含真实和欺诈性的招聘广告。
### 使用的特征
* 职位名称
* 职位描述
* 要求
* 欺诈标签(目标变量)
文本特征被组合并处理,以创建用于分类的统一表示。
## 🛠️ 技术栈
### 编程语言
* Python
### 机器学习
* Scikit-learn
* 线性支持向量机 (Linear SVC)
### 自然语言处理
* NLTK
* TF-IDF 向量化
### 数据处理
* Pandas
* NumPy
### 模型持久化
* Joblib
### Web 应用程序
* Streamlit
## ⚙️ 项目工作流
1. 加载招聘信息数据集
2. 处理缺失值
3. 合并职位名称、职位描述和要求字段
4. 清理和预处理文本数据
5. 移除停用词,同时保留与欺诈相关的重要关键词
6. 生成词级 TF-IDF 特征
7. 生成字符级 TF-IDF 特征
8. 合并特征向量
9. 训练 Linear SVM 分类器
10. 校准预测概率
11. 优化分类阈值
12. 使用 Streamlit 部署模型
## 🧠 机器学习方法
### 文本预处理
应用了以下预处理步骤:
* 将文本转换为小写
* 移除特殊字符和标点符号
* 移除不必要的停用词
* 保留特定领域的欺诈指标,例如:
* Visa
* Deposit
* Fee
* Sponsorship
* WhatsApp
* Telegram
### 特征工程
使用了两种 TF-IDF 表示来提高检测性能:
#### 词级 TF-IDF
* N-grams:1–2
* 最大特征数:20,000
#### 字符级 TF-IDF
* 字符 N-grams:3–5
* 最大特征数:10,000
组合后的特征表示能够捕捉有意义的单词以及欺诈性招聘信息中常见的可疑文本模式。
### 分类模型
* 线性支持向量机 (Linear SVC)
* 启用类别平衡
* 使用 Sigmoid Calibration 进行概率校准
* 用于改进欺诈检测的阈值优化
## 🔍 欺诈检测增强功能
除了机器学习预测之外,系统还使用了可疑招聘广告中常见的与欺诈相关的指标,包括:
* Registration Fee
* Processing Fee
* Security Deposit
* Application Fee
* Training Fee
* Pay First
* Earn Daily
* WhatsApp
* Telegram
* Visa Sponsorship Guaranteed
这些指标有助于增强模型识别潜在欺诈性信息的能力。
## 📂 项目结构
```
Fake-Job-Detector/
│
├── data/
│ └── fake_job_postings.csv
│
├── outputs/
│ └── fake_job_detector_bundle.joblib
│
├── app.py
├── main.py
├── requirements.txt
├── README.md
├── Screenshot1.png
└── Screenshot2.png
```
## ▶️ 安装说明
### 克隆仓库
```
git clone https://github.com/your-username/fake-job-detector.git
cd fake-job-detector
```
### 安装依赖项
```
pip install -r requirements.txt
```
### 运行应用程序
```
streamlit run app.py
```
应用程序将在您的浏览器中打开,地址为:
```
http://localhost:8501
```
## 🌐 在线演示
🔗 https://fake-job-detector-07.streamlit.app/
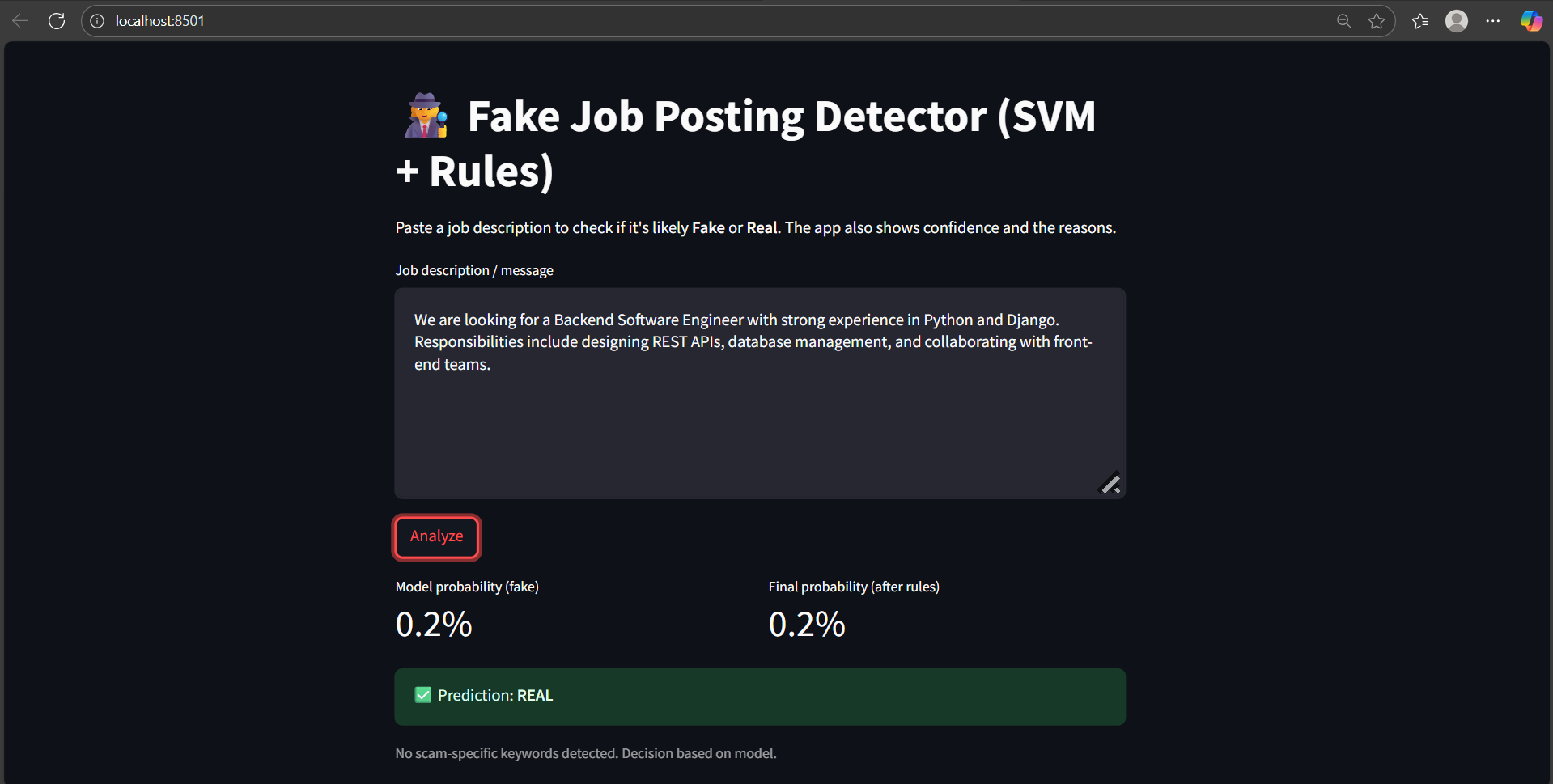
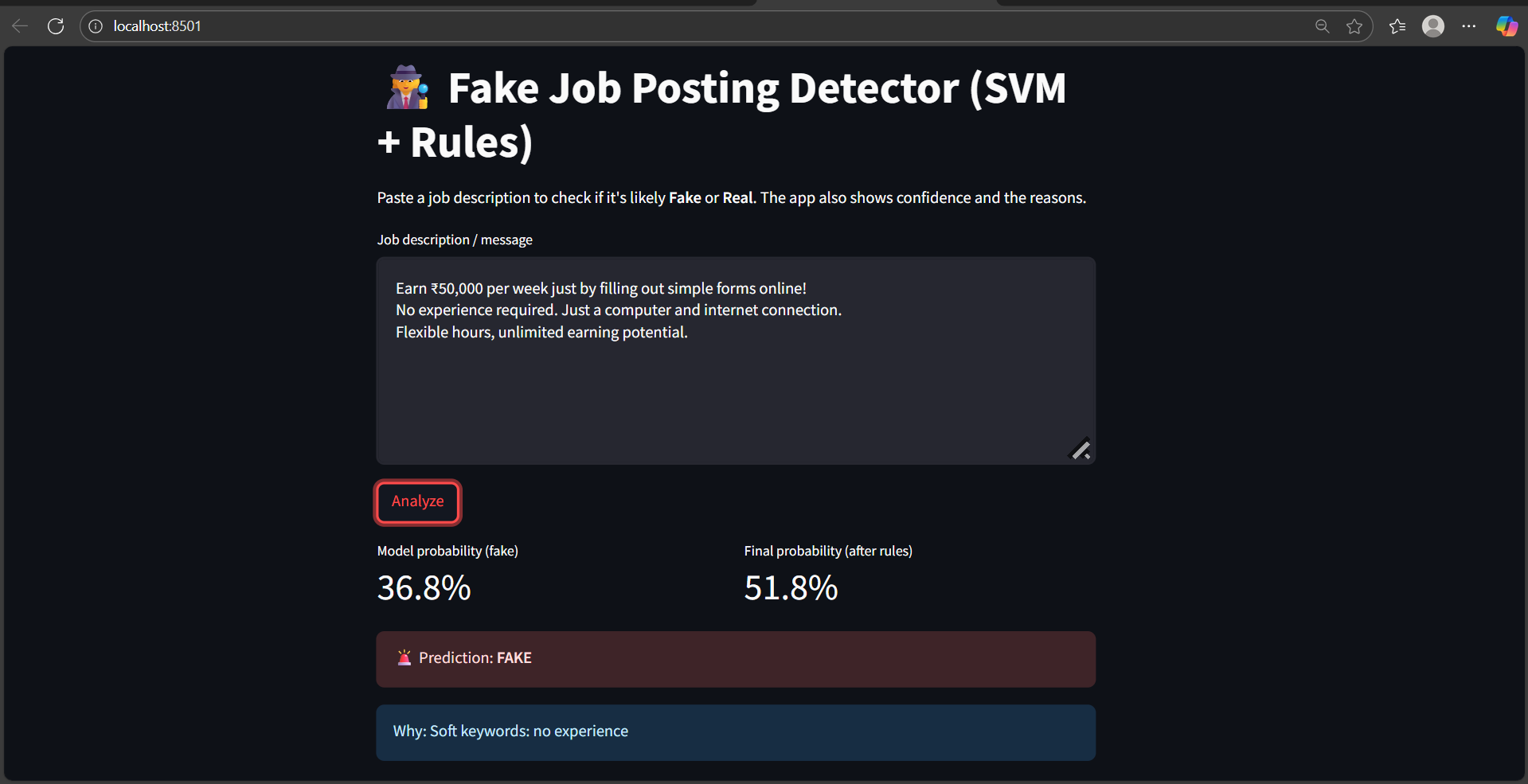
## 📸 应用程序截图
### 预测结果 1
### 预测结果 2
## 🎯 未来改进
* 使用更大的数据集提高模型性能
* 支持多语言招聘信息
* 实现基于深度学习的 NLP 模型
* 添加可解释 AI (XAI) 功能
* 使用 Docker 进行容器化
* 部署到云平台
* 添加置信度分数可视化
## 💡 现实世界的应用场景
* 在线招聘门户网站
* 招聘平台
* HR 筛选系统
* 就业欺诈检测
* 职业指导平台
## 👩💻 作者
**Asvithaa K**
有抱负的数据科学家 | 机器学习爱好者 | NLP 探索者
## ⭐ 支持
如果您觉得这个项目有用,请考虑在 GitHub 上给它点个 Star。
标签:Apex, Kubernetes, Streamlit, TF-IDF, 支持向量机, 文本分类, 机器学习, 欺诈检测, 访问控制, 逆向工具