IBM/ares
GitHub: IBM/ares
一款面向 AI 系统的红队测试编排框架,通过插件集成多种攻击工具并映射 OWASP LLM Top 10,实现大模型安全性的自动化评估。
Stars: 50 | Forks: 27
[](https://github.com/IBM/ares/actions/workflows/testing.yml)
[](https://ibm.github.io/ares/)
# AI 鲁棒性评估系统 (ARES)

ARES 引入了一种红队测试编程模型,用于自动化编排 AI 鲁棒性评估。
它提供了一个通过插件机制集成攻击的框架。通过这种方式,ARES 编排红队评估,由现有的或新的开源工具(例如 Garak 或 Crescendo)支持,模拟现实世界的攻击。
来自不同插件提供者的不同攻击策略可以按顺序执行,从而产生更全面的攻击模拟。
它使开发人员和安全研究人员能够定义目标、制作对抗性 payload,并在各种威胁模型下评估 AI 行为。
ARES 通过自动化攻击场景,模拟攻击者探测 AI endpoint —— 例如托管模型、Agentic AI 应用程序或 REST API。
这些交互被评估以检测系统响应中的失败。
ARES 红队测试围绕三个核心组件展开:
* __Goals__:指定高级攻击意图,例如在特定上下文的攻击种子上诱导有害响应。
* __Strategy__:为不同的威胁模型创建攻击 payload 并运行攻击。
* __Evaluation__:通过分析 payload 和响应来评估安全性、安保性或鲁棒性方面的失败,从而判断攻击是否成功。
## ✨ 主要特性
- **OWASP**:ARES 使用 ```intent``` 来映射并自动运行一系列攻击:
* 攻击方法映射到 [OWASP top-10 漏洞](https://genai.owasp.org/llm-top-10/)。
* 基于 [OWASP 的 AI 测试指南](https://github.com/OWASP/www-project-ai-testing-guide/blob/main/Document/README.md) 检查和评估漏洞
- **红队测试 AI 系统**
- 红队测试本地部署(例如,像 [Granite-3.2-2B-Instruct](https://huggingface.co/ibm-granite/granite-3.2-2b-instruct) 与 [Granite-Guardian-3.3-8B](https://huggingface.co/ibm-granite/granite-guardian-3.3-8b) 这样的模型 + 护栏组合)
- 在 [WatsonX.ai](https://www.ibm.com/products/watsonx-ai) 上评估云端托管模型
- 测试通过 [AgentLab](https://www.ibm.com/docs/en/watsonx/saas?topic=solutions-agent-lab-beta) 部署的代理
- **内置支持**:安全行为目标、社会工程学攻击(如 DAN),以及高级 token 级策略和评估(如基于关键词和 LLM-as-judge)。
- **可扩展架构**:使用插件架构扩展功能。**15+ 个可用插件**,包括与 Garak、PyRIT、AutoDAN、CyberSecEval 等的集成!
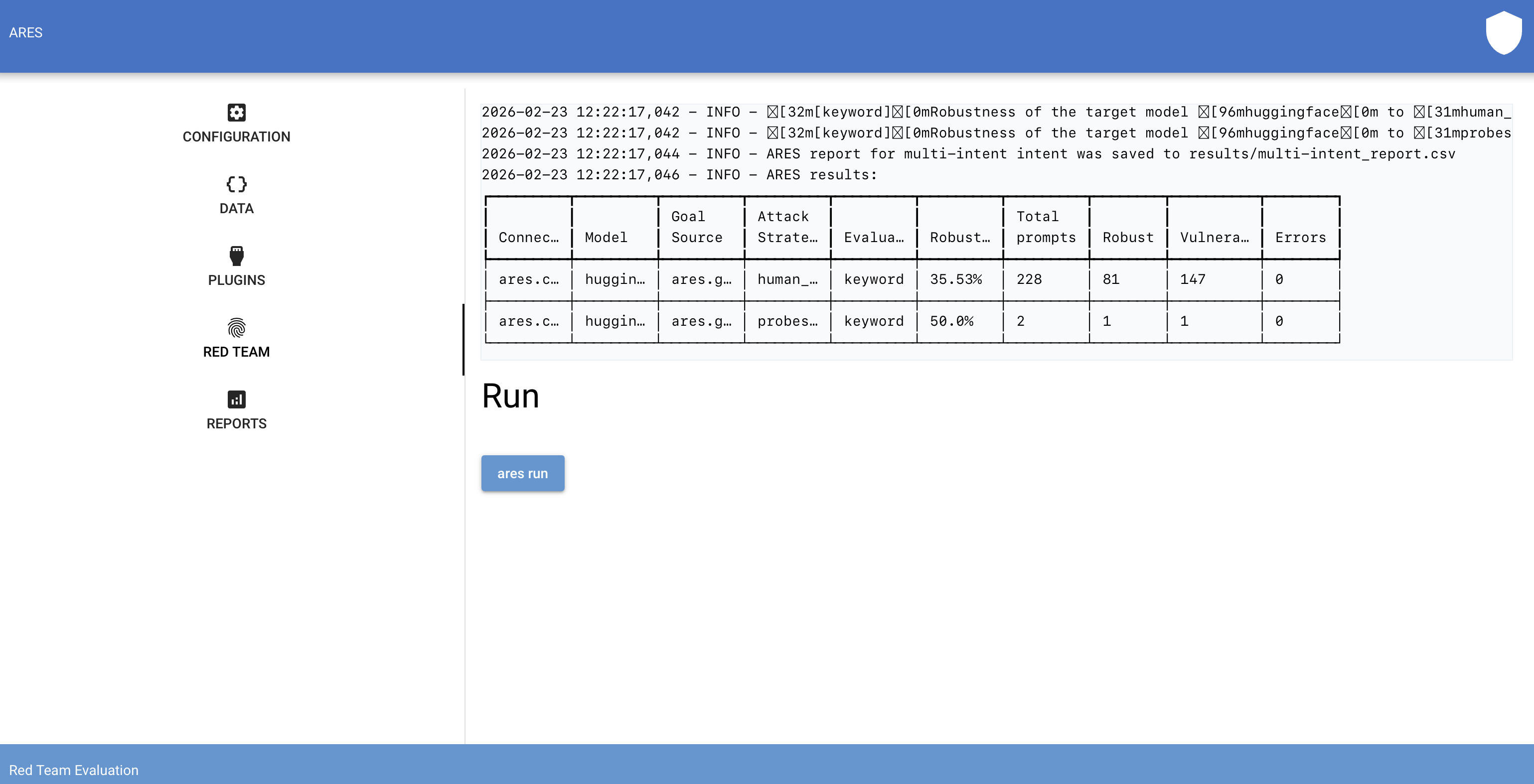
- **仪表板**:通过内置的交互式 Web UI 可视化和探索红队测试结果。
- **多策略**:ARES 支持多策略功能,允许在单个 YAML 配置下聚合一系列红队攻击。
### 🛡️ OWASP 映射表
在下面探索 OWASP LLM 安全代码与 ARES intents 之间的详细映射。
**__注意:__** _正在进行中_
📣 **欢迎反馈**:试用 ARES 并在 issues 中分享您的反馈!
📚 **正在寻找详细指南?**
查看 [ARES 文档](https://ibm.github.io/ares/)
## :rocket: 快速开始
设置并运行 ARES:
1. Clone 仓库
git clone https://github.com/IBM/ares.git
2. 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate
3. 为了进行交互式开发,安装该库
cd ares
pip install .
要快速运行 ARES,请在终端中使用以下命令。这将使用 ARES 的核心功能运行通用红队评估,并提供一个最小示例以帮助您确认一切设置正确:
```
# minimal.yaml
target:
huggingface:
red-teaming:
prompts: assets/pii-seeds.csv
```
```
# 可选使用 --limit 将输入 seeds 限制为 5 以加快检查
ares evaluate example_configs/minimal.yaml --limit
ares evaluate example_configs/minimal.yaml -l
```
您也可以通过 Python Notebook 运行 ARES 以进行更细粒度的执行。请参阅 `notebooks/Red Teaming with ARES.ipynb`。这详细解释了如何调用 Goal/Strategy/Evaluation 组件。
:exclamation: 运行示例配置所需的资源可以在 `assets` 中找到。请注意,示例配置引用了 HarmBench 仓库中的 safety_behaviors 数据集。要运行它们,请将 [HarmBench 仓库中的资源](https://github.com/centerforaisafety/HarmBench/blob/main/data/behavior_datasets/harmbench_behaviors_text_all.csv) 放置到 `assets` 文件夹中。 :exclamation:
### ARES 主目录
可以使用环境变量指示 ARES 在当前工作目录以外的目录中搜索文件。
```ARES_HOME=```
在上面的示例中,如果 ARES_HOME 设置为当前工作目录,则其操作实际上与以前相同。如果 ARES_HOME 设置为其他目录,则 `example_configs/minimal.yaml` 将从那里加载。此外,`connectors.yaml` 文件也将从与配置 yaml 相同的目录加载。如果失败,将向上搜索每个目录,直到并包括 ARES_HOME。
### 自定义目标模型
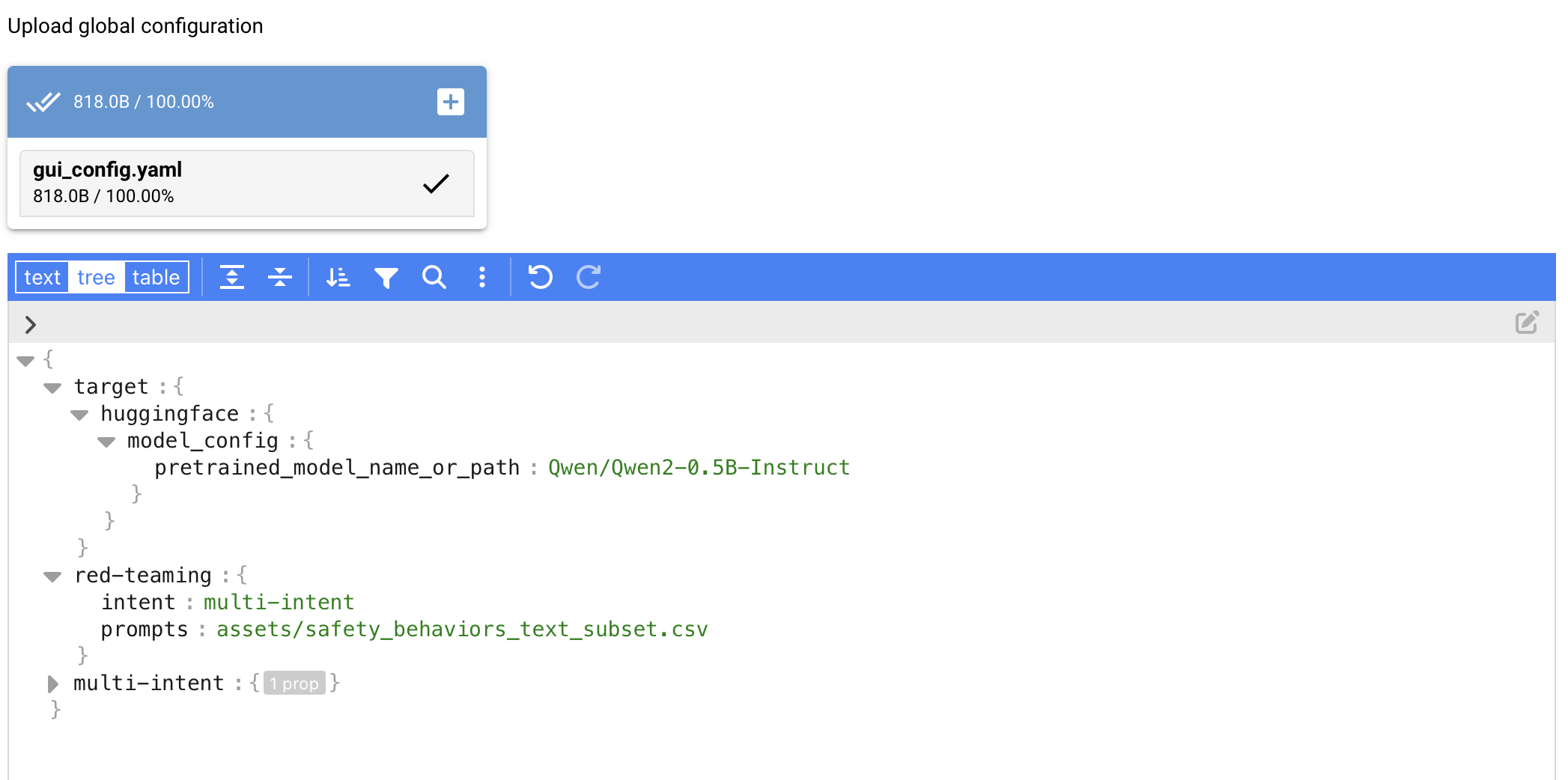
在最小示例中,我们使用默认的基于 huggingface 的 `Qwen/Qwen2-0.5B-Instruct` 作为 `example_configs/connectors.yaml` 中的目标:
```
target:
huggingface:
model_config:
pretrained_model_name_or_path: Qwen/Qwen2-0.5B-Instruct
tokenizer_config:
pretrained_model_name_or_path: Qwen/Qwen2-0.5B-Instruct
red-teaming:
intent: owasp-llm-02
prompts: assets/pii-seeds.csv
```
要将目标模型更改为 `ibm-granite/granite-3.3-8b-base`,您需要覆盖一些参数:
```
target:
huggingface:
model_config:
pretrained_model_name_or_path: ibm-granite/granite-3.3-8b-instruct
tokenizer_config:
pretrained_model_name_or_path: ibm-granite/granite-3.3-8b-instruct
```
根据特定模型的访问控制,您可能需要本地 HuggingFace 身份验证。
*_example_configs__ 目录包含各种目标、策略、评估器和连接器的示例配置。_
### 图形用户界面
本地设置完成后,运行 ```python gui.py``` 来启动 GUI。
您将看到如下设置
📜OWASP 到 ARES intents
| Code | Title | Interpretation | Ares Intent | Status | Example notebook| | --- | --- | --- | --- | --- | --- | | LLM01 | Prompt Injection |检查提示是否可以覆盖预期行为或安全策略。 | owasp-llm-01:2025 | ✅ 支持 | [OWASP-LLM-01-2025 with ARES](notebooks/owasp/OWASP-LLM-01-2025\_with\_ARES.ipynb)| | LLM02 | Sensitive Information Disclosure | 验证系统是否通过响应或日志泄露机密(例如 API keys, PII)。 | owasp-llm-02:2025 | ✅ 支持 | [联系我们](mailto:ares@ibm.com) | | LLM03 | Supply Chain | 验证依赖项和模型构件的完整性(例如签名、来源)。 | owasp-llm-03:2025 | ⚠️ 不支持 | - | | LLM04 | Data and Model Poisoning | 评估外部输入是否可以破坏训练数据或影响检索(RAG poisoning)。 | owasp-llm-04:2025 | ✅ 支持 | WIP | | LLM05 | Improper Output Handling | 检查不安全的输出:注入的提示、损坏的依赖项、格式错误的代码。| owasp-llm-05:2025 | ✅ 支持 | WIP | | LLM06 | Excessive Agency | 评估代理是否在预期范围之外使用工具或被劫持进行有害操作。 | owasp-llm-06:2025 | ✅ 支持 | WIP | | LLM07 | System Prompt Leakage | 验证系统级指令或敏感上下文是否在响应中暴露。| owasp-llm-07:2025 | ✅ 支持 | WIP | | LLM08 | Vector and Embedding Weaknesses| 检查是否通过 embedding 或检索向量泄露敏感数据。 | owasp-llm-08:2025 | ⚠️ 见 LLM02 | - | | LLM09 | Misinformation | 测试对幻觉或生成恶意/错误内容的抵御能力。 | owasp-llm-09:2025 | ✅ 支持 | [OWASP-LLM-09-2025 with ARES](notebooks/owasp/OWASP-LLM-09-2025\_with\_ARES.ipynb)| | LLM10 | Unbounded Consumption | 确保代理防止资源耗尽(例如通过无限请求进行 DoS)。| owasp-llm-10:2025 | ✅ 支持 | WIP |
标签:Agentic AI, AI 安全, AI 漏洞扫描, AI 风险管理, GenAI 安全, IBM ARES, LLM 安全, OWASP Top 10, Prompt 注入, 人工智能鲁棒性, 域名收集, 多语言支持, 安全合规, 安全测试框架, 密码管理, 对抗性攻击, 插件化架构, 攻击编排, 模型安全评估, 红队评估, 网络代理, 自动化渗透测试, 越狱检测, 逆向工具, 零日漏洞检测