sims718718/UnifiedThreatHunting
GitHub: sims718718/UnifiedThreatHunting
提供一套统一的威胁狩猎流程框架,解决如何系统化、可衡量地开展主动威胁探测与假设验证。
Stars: 0 | Forks: 0
# 统一威胁狩猎流程
作为威胁狩猎负责人,我被赋予从零开始构建威胁狩猎计划的任务。这涉及大量关于威胁狩猎本质的思考,以及如何将其转化为有意义的结果。无数小时用于阅读各种方法论,包括威胁狩猎、检测工程、威胁情报(CTI)、取证,甚至我在美国空军期间的经验。然而,通过构建一个计划,我意识到我需要一个统一的过程,一个**统一的威胁狩猎流程**,以提供结构化的方式来进行狩猎并最终为组织交付有意义的结果。
```
graph LR
Z[Step 0: Environment Context] --> A[Triggering Event]
A --> B[Hypothesis Development]
B --> C[Initial Assessment]
C --> D[Feasibility Assessment]
D --> E[Define Scope & Objectives]
E --> F[Formalize Hunt Plan]
F --> G[Execute Hunt]
G --> H[Document Outcomes]
H --> I[Report & Iterate]
I --> A
```
## 什么是威胁狩猎?
简单来说,威胁狩猎是主动搜索并识别绕过安全控制的威胁的行为。这个定义有一定的灵活性,但核心理念是它是**主动的**,旨在发现未知项。
现在,真正的问题是:**你如何实现有意义的威胁狩猎?**
市面上有许多框架,包括 PEAK、TaHiTI、OTHF、AIMOD2 等,很可能还有更多我遗漏的。然而,这引出了关键问题:在构建计划和定义流程时:
* 一种框架比其他更正确吗?
* 我只需选择一个吗?
* 哪一种更适合我们组织的需求?
* 我们的利益相关者真正想要什么?
这些问题以及更多问题引导我构建了一个适合我们组织的流程,在我看来,它忠于威胁狩猎的本质。
这个**统一的威胁狩猎流程**是多种框架的融合。实质上,每种框架都遵循相似的思维方式,但采取了略有不同的方法。通过比较每种框架的关键概念,我能够定义一个帮助成熟化计划的方法论。
## 威胁狩猎类型
有多种方法被描述用于执行狩猎操作:结构化、非结构化、TTP 聚焦、情报聚焦、数据驱动等。虽然这个统一的威胁狩猎流程可能看似结构化,但这并不意味着你的假设不能以非结构化的方式由数据驱动。这个流程旨在融合各种类型的威胁狩猎,采用模块化方法。我们会使用所有这些技术来确保我们彻底测试假设。
目标是采用模块化的威胁狩猎方法,没有一刀切的方案。使用你所能利用的所有技术。
实际上,你选择的狩猎类型取决于你在 **DAIKI 链**(数据 → 信息 → 知识 → 洞察)中的起点:
| 狩猎类型 | 起点 | 特点 |
| --- | --- | --- |
| **探索性(EDA)** | 原始数据 | 基线化、理解数据形态、无先验假设 |
| **基于假设(HBO)** | 情境感知 | 基于团队知识测试可信的攻击场景 |
| **威胁指导(TIO)** | 可操作的情报 | 以情报驱动,聚焦已知行为者或 TTP |
| **紫色行动(DPO)** | 红队洞察 | 进攻/防御联合验证 |
遵循数据科学原则,无论狩猎类型如何,你都应探索并理解与狩猎相关的数据源。本仓库的 [/Data_Analysis](https://github.com/sims718718/UnifiedThreatHunting/tree/main/Data_Analysis) 文件夹包含用于该探索阶段的辅助技术和笔记本。
## 第 0 步:环境上下文
在任何狩猎开始之前,捕获环境上下文,以便每个下游工件(查询、字段名称、范围决策)都针对你实际工作的环境进行定制,而不是通用编写。我将此作为一个显式步骤,因为我不断看到引用不存在的数据源或完全错误方言的狩猎计划。花几分钟时间可以节省后续数小时。
至少,记录以下信息:
| 上下文 | 重要性 |
| --- | --- |
| **SIEM / 数据平台** | Splunk SPL、KQL、Elastic DSL、Chronicle 等都会塑造你编写的每个查询 |
| **EDR 平台** | CrowdStrike、SentinelOne、Defender for Endpoint 等使用不同的遥测字段名称 |
| **环境类型** | 本地部署、云原生(AWS/Azure/GCP)或混合会改变哪些日志存在 |
| **行业垂直领域** | 决定哪些威胁行为者在现实中相关 |
| **日志保留窗口** | 决定哪些时间范围实际上可以查询 |
| **狩猎成熟度** | 初学者需要脚手架;经验丰富的团队需要骨架 |
在 Epic 顶部将其记录为 `Environment Profile`。如果你行动迅速,最低要求是 **SIEM 平台** 和 **环境类型**,少于这些你的查询将过于通用。
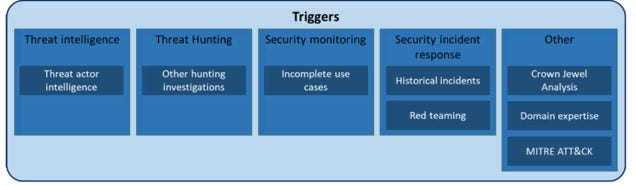
## 触发器
借鉴 TaHiTI 框架,威胁狩猎始于一个触发事件。这些事件证明启动狩猎的合理性。根据 TaHiTI,触发器可以包括:
* CTI(网络威胁情报)
* 不完整的用例
* 过去的事件
* 红队演练
* MITRE TTPs
* 等等
对于我们组织,我们结合这些以及一些额外触发器,例如利益相关者的直接需求和影响环境的安全漏洞披露。
一些框架从初始 **假设**(这里的第 2 步)开始狩猎,但我问:你怎么首先得出那个假设?
很可能有一个触发事件导致了初始假设。正如牛顿观察苹果落地后才思考什么力将其拉下一样,*那个苹果是导致关于重力的假设的触发事件*。同样,我们应该有一个触发器,然后再进入假设阶段。
 ## 假设开发
接下来,也许是**最重要**的一步,是构建狩猎假设。这一步虽然关键,但也可能是最模糊的。你的假设可能带你找到宝藏,也可能让你陷入无休止的兔子洞。
根据数据科学原则,你的假设是关于创建可测试的陈述来指导分析。不仅如此,你还应该使你的假设 **SMART**:
* **具体(Specific)**:清晰明确,没有歧义。不要试图一次性狩猎所有 TTP。
* **可衡量(Measurable)**:必须有可量化的标准来跟踪进度。(我们之后会使用 Jira。)
* **可实现(Achievable)**:现实且在你的团队能力范围内。不要瞄准你没有的遥测数据。
* **相关性(Relevant)**:应与组织目标对齐。使之对任务有意义。
* **有时限(Time-bound)**:设定截止日期。没有永无止境的狩猎。
### SMART 假设示例
一个有用的模板:
**示例 1(CTI 驱动,TIO):**
**示例 2(行为驱动,HBO):**
在构建假设时,你可能会开发多个相互竞争的假设。关于这一点值得一读的书是 Richards J. Heuer 的《心理情报分析》,由 CIA 情报研究中心出版。他描述了**竞争假设**,这对你的狩猎工作非常有益。
该过程包括定义多个假设并确定其中最有效的,提供严谨性以帮助定义狩猎基础。7 步过程描述如下:
1. 列举所有假设
2. 为每个假设寻找支持证据
3. 通过矩阵比较证据与假设,Heuer 构建了一个矩阵来做到这一点
4. 通过矩阵移除诊断价值低的证据
5. 按可能性对假设进行优先级排序
6. 确定哪些结论依赖证据不足,并考虑该证据是否可能错误
7. 记录假设之间的比较
接下来的两个阶段深入到基于假设来决定是否执行狩猎的过程中。
此外,来自 AIMOD2 框架的一个关键概念是**假设的默认违规**,我们专注于在假设违规下识别未知,即假设对手已经绕过了我们的控制。
### 初步评估
在**初步评估**阶段,我们收集和研究数据以支持假设。这包括内部和外部来源:
* **内部来源**:之前的狩猎、经验教训、内部应用程序文档、网络和应用程序架构图、代码仓库、内部威胁情报。
* **外部来源**:OSINT、供应商博客、信息请求(RFI)给可信的外部组织。
此步骤的一个子部分是识别和(必要时)采访业务或技术负责人。根据你的狩猎,你可能需要与 SME 互动以获得更深入的理解。这并非总是必需;你可能已经凭经验或过往狩猎了解系统、日志记录和应用程序。
目标不是成为某个系统的专家,而是对环境有充分的理解。
### 可行性评估
在规划狩猎活动之前,我们需要评估可行性。这包括:
* 约束和限制
* 数据可用性
* 数据质量
* 团队技能
* 时间线
* 工具可用性
本质上,我们问:**“果汁值得挤压吗?”**
如果遥测数据不可用,问:可以使其可用吗?需要多少努力?
每次可行性评估应产生明确决策:
| 决策 | 含义 |
| --- | --- |
| ✅ **GO** | 所有标准满足,继续规划 |
| ❌ **NO-GO** | 存在关键阻塞项,列入待办并制定修复计划 |
| ⚠️ **有条件(CONDITIONAL)** | 存在小缺口,记录假设并继续 |
#### 实际可行性示例
使用上述 AS-REP Roasting 假设:
| 标准 | 状态 | 备注 |
| --- | --- | --- |
| 数据可用性 | ✅ GO | Windows Security 4768 事件已采集到所有 DC 的 Splunk |
| 数据质量 | ⚠️ 有条件 | 4768 中的预认证类型字段在 5 个 DC 中解析了 4 个,1 个 DC 的 sourcetype 损坏
| 技能 | ✅ GO | 团队具备 SPL 和 Active Directory 经验 |
| 时间线 | ✅ GO | 预计 3 天,符合当前迭代 |
| 工具 | ✅ GO | Splunk Enterprise Security 加上内部 AD 清单 |
| **总体** | ⚠️ **有条件** | 继续执行,并记录一个 DC 解析存在缺口。打开一个并行工单,在重新运行狩猎前修复 sourcetype 以实现全覆盖。 |
如果限制因素阻碍进展,将想法列入待办事项,并制定计划以在处理新假设或狩猎的同时获取所需遥测数据。
## 定义范围和目标
在这里,我们定义狩猎的**目标**。这些代表我们的狩猎目标以及实现目标所需完成的任务。由于我们的狩猎是 SMART 的,我们必须明确定义如何**衡量和管理**它们。这包括指定目标环境段、分析时间窗口、范围内的系统和资产,以及任何明确的排除项。
## 正式化行动计划(狩猎计划)
现在到了有趣的阶段,构建狩猎计划。
任何狩猎的一个关键原则是记录你的行动和发现。这使报告更容易,允许我们保留工件,并确保结果可重复。
我们的团队使用 **Jira**,但任何文档工具都适用。关键是:**只需记录**。
我们使用 **Epics(史诗)**、**Stories(故事)** 和 **Tasks(任务)** 来组织计划:
### Epics(启动)
代表狩猎的总体假设或主题。我们包括:
* 环境配置文件(来自第 0 步)
* 支持文档
* 初始研究(例如 CTI、内部文档)
* 狩猎的相关性和理由
* MITRE ATT&CK 技术映射
* 所需数据源及字段级细节
### Stories(狩猎)
这些是与 Epic 假设对齐的离散调查或测试。你可以针对一个假设开发一个或多个故事,最终**证明或推翻**它。每个故事应反映单一思维过程并作为一个测试。开发多个测试的想法不仅是为了彻底调查假设,也是为了挑战初始假设。我们应该**挑战已知的一切**。记住,威胁狩猎是关于追逐未知的,虽然你应该覆盖简单的测试(例如针对编码命令的字符串搜索),但我们应该努力更深入地思考,如果我们真的想发现未知。我相信狩猎过程中应有一定程度的挣扎;否则你可能没有学习到东西,并且可能正在实现已经存在的东西。如果是这种情况,问问自己:意义何在?
**示例:**
如果我的假设是关于管理账户的异常登录事件,我可能会有两个故事:
1. 一个使用事件代码 4624/4672 并应用已知环境上下文建立基线的方法。
2. 另一个使用机器学习建模异常的方法。
不同的方法,相同的假设。可能需要不同的测试来完全完成狩猎。
### 狩猎执行步骤
* **收集和分析数据**
+ 从指定源检索数据
+ 理解数据形态和覆盖范围
+ 数据清理、转换和建模
* **调查和验证威胁**
+ 在数据上测试假设并根据需要调整
+ 过滤和查询
+ 时间趋势和数据分析
+ 高级分析(聚类、统计方法、机器学习)
+ 已知 TTP 作为参考锚点
* **记录观察和洞察**
+ 出现的异常和洞察
+ 狩猎期间假设的变更
+ 使用的技术
+ 访问的数据源
+ 验证的 TTP 覆盖范围
通过使用 Jira 等工具,文档成为轻量级手册。我们的团队自然开始开发类似于
## 假设开发
接下来,也许是**最重要**的一步,是构建狩猎假设。这一步虽然关键,但也可能是最模糊的。你的假设可能带你找到宝藏,也可能让你陷入无休止的兔子洞。
根据数据科学原则,你的假设是关于创建可测试的陈述来指导分析。不仅如此,你还应该使你的假设 **SMART**:
* **具体(Specific)**:清晰明确,没有歧义。不要试图一次性狩猎所有 TTP。
* **可衡量(Measurable)**:必须有可量化的标准来跟踪进度。(我们之后会使用 Jira。)
* **可实现(Achievable)**:现实且在你的团队能力范围内。不要瞄准你没有的遥测数据。
* **相关性(Relevant)**:应与组织目标对齐。使之对任务有意义。
* **有时限(Time-bound)**:设定截止日期。没有永无止境的狩猎。
### SMART 假设示例
一个有用的模板:
**示例 1(CTI 驱动,TIO):**
**示例 2(行为驱动,HBO):**
在构建假设时,你可能会开发多个相互竞争的假设。关于这一点值得一读的书是 Richards J. Heuer 的《心理情报分析》,由 CIA 情报研究中心出版。他描述了**竞争假设**,这对你的狩猎工作非常有益。
该过程包括定义多个假设并确定其中最有效的,提供严谨性以帮助定义狩猎基础。7 步过程描述如下:
1. 列举所有假设
2. 为每个假设寻找支持证据
3. 通过矩阵比较证据与假设,Heuer 构建了一个矩阵来做到这一点
4. 通过矩阵移除诊断价值低的证据
5. 按可能性对假设进行优先级排序
6. 确定哪些结论依赖证据不足,并考虑该证据是否可能错误
7. 记录假设之间的比较
接下来的两个阶段深入到基于假设来决定是否执行狩猎的过程中。
此外,来自 AIMOD2 框架的一个关键概念是**假设的默认违规**,我们专注于在假设违规下识别未知,即假设对手已经绕过了我们的控制。
### 初步评估
在**初步评估**阶段,我们收集和研究数据以支持假设。这包括内部和外部来源:
* **内部来源**:之前的狩猎、经验教训、内部应用程序文档、网络和应用程序架构图、代码仓库、内部威胁情报。
* **外部来源**:OSINT、供应商博客、信息请求(RFI)给可信的外部组织。
此步骤的一个子部分是识别和(必要时)采访业务或技术负责人。根据你的狩猎,你可能需要与 SME 互动以获得更深入的理解。这并非总是必需;你可能已经凭经验或过往狩猎了解系统、日志记录和应用程序。
目标不是成为某个系统的专家,而是对环境有充分的理解。
### 可行性评估
在规划狩猎活动之前,我们需要评估可行性。这包括:
* 约束和限制
* 数据可用性
* 数据质量
* 团队技能
* 时间线
* 工具可用性
本质上,我们问:**“果汁值得挤压吗?”**
如果遥测数据不可用,问:可以使其可用吗?需要多少努力?
每次可行性评估应产生明确决策:
| 决策 | 含义 |
| --- | --- |
| ✅ **GO** | 所有标准满足,继续规划 |
| ❌ **NO-GO** | 存在关键阻塞项,列入待办并制定修复计划 |
| ⚠️ **有条件(CONDITIONAL)** | 存在小缺口,记录假设并继续 |
#### 实际可行性示例
使用上述 AS-REP Roasting 假设:
| 标准 | 状态 | 备注 |
| --- | --- | --- |
| 数据可用性 | ✅ GO | Windows Security 4768 事件已采集到所有 DC 的 Splunk |
| 数据质量 | ⚠️ 有条件 | 4768 中的预认证类型字段在 5 个 DC 中解析了 4 个,1 个 DC 的 sourcetype 损坏
| 技能 | ✅ GO | 团队具备 SPL 和 Active Directory 经验 |
| 时间线 | ✅ GO | 预计 3 天,符合当前迭代 |
| 工具 | ✅ GO | Splunk Enterprise Security 加上内部 AD 清单 |
| **总体** | ⚠️ **有条件** | 继续执行,并记录一个 DC 解析存在缺口。打开一个并行工单,在重新运行狩猎前修复 sourcetype 以实现全覆盖。 |
如果限制因素阻碍进展,将想法列入待办事项,并制定计划以在处理新假设或狩猎的同时获取所需遥测数据。
## 定义范围和目标
在这里,我们定义狩猎的**目标**。这些代表我们的狩猎目标以及实现目标所需完成的任务。由于我们的狩猎是 SMART 的,我们必须明确定义如何**衡量和管理**它们。这包括指定目标环境段、分析时间窗口、范围内的系统和资产,以及任何明确的排除项。
## 正式化行动计划(狩猎计划)
现在到了有趣的阶段,构建狩猎计划。
任何狩猎的一个关键原则是记录你的行动和发现。这使报告更容易,允许我们保留工件,并确保结果可重复。
我们的团队使用 **Jira**,但任何文档工具都适用。关键是:**只需记录**。
我们使用 **Epics(史诗)**、**Stories(故事)** 和 **Tasks(任务)** 来组织计划:
### Epics(启动)
代表狩猎的总体假设或主题。我们包括:
* 环境配置文件(来自第 0 步)
* 支持文档
* 初始研究(例如 CTI、内部文档)
* 狩猎的相关性和理由
* MITRE ATT&CK 技术映射
* 所需数据源及字段级细节
### Stories(狩猎)
这些是与 Epic 假设对齐的离散调查或测试。你可以针对一个假设开发一个或多个故事,最终**证明或推翻**它。每个故事应反映单一思维过程并作为一个测试。开发多个测试的想法不仅是为了彻底调查假设,也是为了挑战初始假设。我们应该**挑战已知的一切**。记住,威胁狩猎是关于追逐未知的,虽然你应该覆盖简单的测试(例如针对编码命令的字符串搜索),但我们应该努力更深入地思考,如果我们真的想发现未知。我相信狩猎过程中应有一定程度的挣扎;否则你可能没有学习到东西,并且可能正在实现已经存在的东西。如果是这种情况,问问自己:意义何在?
**示例:**
如果我的假设是关于管理账户的异常登录事件,我可能会有两个故事:
1. 一个使用事件代码 4624/4672 并应用已知环境上下文建立基线的方法。
2. 另一个使用机器学习建模异常的方法。
不同的方法,相同的假设。可能需要不同的测试来完全完成狩猎。
### 狩猎执行步骤
* **收集和分析数据**
+ 从指定源检索数据
+ 理解数据形态和覆盖范围
+ 数据清理、转换和建模
* **调查和验证威胁**
+ 在数据上测试假设并根据需要调整
+ 过滤和查询
+ 时间趋势和数据分析
+ 高级分析(聚类、统计方法、机器学习)
+ 已知 TTP 作为参考锚点
* **记录观察和洞察**
+ 出现的异常和洞察
+ 狩猎期间假设的变更
+ 使用的技术
+ 访问的数据源
+ 验证的 TTP 覆盖范围
通过使用 Jira 等工具,文档成为轻量级手册。我们的团队自然开始开发类似于 的结构化手册,便于参考,并使报告更高效。这些故事和手册也充当了狩猎仓库,我们可以引用之前的狩猎。
### 任务(结果)
任务记录狩猎的**结果**,并与父 Epic 关联以便跟踪。它们包含结果,例如(主要来自 PEAK 和 AIMOD2 框架):
* **新的狩猎想法**,未来的假设或用例
* **分析/检测**,创建的规则、仪表板或签名
* **安全事件**,升级到事件响应和/或打开事件
* **书面报告**,最终狩猎报告
* **可见性缺口**,识别的缺失遥测
* **安全控制问题**,发现的现有防御中的缺口
指标对狩猎计划至关重要,因为管理层通常以数字思考。可衡量的指标对于衡量努力的有效性和展示计划成熟度至关重要。我们还必须考虑什么指标真正重要,什么可能是无效指标。我们应该避免仅跟踪活动指标(花费时间、执行的狩猎数量),而应关注更有影响力的内容。指标应帮助回答“所以呢?”这个问题。
```
graph TD
A[Hunt Epic - Hypothesis]
A --> B1[Story - Hunt 1: Logon Baseline]
A --> B2[Story - Hunt 2: ML Model]
B1 --> C1[Task - Analytics / Detection]
B1 --> C2[Task - Written Report]
B2 --> C3[Task - Visibility Gap Identified]
B2 --> C4[Task - New Hunt Idea]
```
## 实际示例:端到端狩猎
为了使流程具体化,以下是一个从触发到结果的完整走查。字段名称和工具基于上述环境配置文件。
### 环境配置文件
* **SIEM**:Splunk Enterprise Security
* **EDR**:CrowdStrike Falcon
* **环境**:混合(本地 AD 加上 Azure AD)
* **垂直领域**:金融服务
* **保留策略**:热数据 90 天,冷数据 1 年
* **成熟度**:中级
### 第 1 步:触发器
CISA 公告关于一个利用 AS-REP Roasting 针对服务账户的财务动机攻击者。来自 CTI 订阅源接收,鉴于匹配的垂直领域,相关性高。
### 第 2 步:假设(SMART)
### 第 3 步:初步评估
* **内部**:提取具有 `DONT_REQ_PREAUTH` 设置的账户列表。审查最近的 AD 审计以了解服务账户健康状况。
* **外部**:MITRE ATT&CK T1558.004、CISA 公告、Sigma 规则 `win_susp_rasp_roasting`。
* **SME**:身份团队确认三个遗留服务账户故意禁用了预认证,应被排除为已知良好账户。
### 第 4 步:可行性
**有条件通过**:一个 DC 的 sourcetype 损坏(条件性依赖解析修复,见实际可行性示例)。继续执行并标记。
### 第 5 步:范围
* **范围内**:所有本地 Windows 域控制器,所有零级和一级服务账户。
* **时间窗口**:最近 30 天。
* **排除项**:由身份团队确定的三个文档化遗留账户。
* **主要目标**:确定是否发生 AS-REP Roasting 活动。
* **次要目标**:识别应启用预认证的待修复服务账户。
### 第 6 步:Jira 计划
**Epic**:`HUNT-042 AS-REP Roasting Detection Hunt`
* 链接:CISA 公告、MITRE T1558.004、Sigma 规则引用
* 数据源:`wineventlog:security` (4768)、AD 清单查找
* MITRE:T1558.004(凭据访问)
**故事 `HUNT-042-S1`**:基准 4768 预认证类型 0 事件
* 方法:SPL 查询针对 30 天数据,按 `src_host`、`account_name` 分组,排除已知良好列表,按频率排序。
* 预期结果(恶意):来自非域控主机发起的请求,目标为多个可烘烤账户。
* 预期结果(良性):仅出现已知良好遗留账户,且均来自预期服务主机。
**故事 `HUNT-042-S2`**:将可烘烤账户与当前 AD 状态交叉引用
* 方法:将狩猎结果与当前 `DONT_REQ_PREAUTH` 标志进行比较,识别无论是否发现活动都应修复的账户。
**任务(结果占位符):**
* `HUNT-042-T1` 分析/检测:将验证后的查询转换为计划 Splunk ES 相关规则。
* `HUNT-042-T2` 可见性缺口:`DC05` 上 sourcetype 解析损坏,已向平台团队提交工单。
* `HUNT-042-T3` 安全控制问题:发现两个预认证被禁用的服务账户应修复,已移交身份团队。
* `HUNT-042-T4` 书面报告:最终狩猎报告附加到 Epic。
* `HUNT-042-T5` 新的狩猎想法:对同一服务账户集合进行 Kerberoasting(T1558.003)后续狩猎。
这展示了从触发到结果的完整狩猎过程。相同结构可通过添加更多故事扩展到更大的活动。
## 自动化/AI:使狩猎可重复
现在我们可以讨论自动化。这不是要自动化狩猎本身,狩猎始终需要人类驱动的假设测试和分析。相反,我们专注于自动化**输出**和可重复组件。
狩猎最有价值的结果之一是检测或分析。检测是直接的,可以传递给检测工程流程 SOC 中落地。但并非每个分析都会成为检测。有些需要人工审查、上下文或更深入分析。借鉴 Google SecOps 的理念(分析师应花更少时间收集数据,更多时间分析),我们可以自动化狩猎中重复或数据密集的部分。
自动化和 AI 应聚焦于:
* 自动化重复查询和计划狩猎
* 自动用威胁情报丰富数据
* 在新时间范围内重新运行验证过的假设
* 生成结构化报告或 Jira 工单
* 告警基线偏差或可见性缺口
* **开发和质疑**初始假设
我通过开发一个**威胁狩猎规划器技能**帮助自动化狩猎规划过程。这不会自动执行狩猎本身,但能基于这个统一的狩猎流程提供初始计划。目标是让分析师更快投入狩猎,同时使流程更可重复。该技能应被视为草稿,挑战它以确保其符合你设定的目标。→ [威胁狩猎规划器用户指南](https://github.com/sims718718/UnifiedThreatHunting/blob/main/Theat_Hunt_Planner_Skill/threat_hunt_planner_user_guide.md)
对于数据探索技术,用于支持执行阶段,请参阅 [/Data_Analysis](https://github.com/sims718718/UnifiedThreatHunting/tree/main/Data_Analysis)。
最终,狩猎不应是一次性事件。它们应该是**可重复、可衡量、可改进**的(参见[基于信号的威胁狩猎](https://github.com/sims718718/UnifiedThreatHunting/blob/main/Detection_Engineering_Meets_ThreatHunting/Signal-Based_Threat_Hunting.md))。随着狩猎成熟,我们应该将其编成自动化包,以在扩展工作量的同时不丢失深度。这确保了威胁狩猎产生的价值随时间累积,使我们专注于思考而非获取。
使用自动化来节省狩猎过程中多个步骤的时间。使用 AI 来帮助构建狩猎计划甚至初始假设。然而,永远不要全盘接受。挑战它,研究它,理解它。
最后,感谢阅读,并向所有为此过程提供参考的作者致敬。狩猎愉快!
#### 参考资料
*
*
*
*
## 假设开发
接下来,也许是**最重要**的一步,是构建狩猎假设。这一步虽然关键,但也可能是最模糊的。你的假设可能带你找到宝藏,也可能让你陷入无休止的兔子洞。
根据数据科学原则,你的假设是关于创建可测试的陈述来指导分析。不仅如此,你还应该使你的假设 **SMART**:
* **具体(Specific)**:清晰明确,没有歧义。不要试图一次性狩猎所有 TTP。
* **可衡量(Measurable)**:必须有可量化的标准来跟踪进度。(我们之后会使用 Jira。)
* **可实现(Achievable)**:现实且在你的团队能力范围内。不要瞄准你没有的遥测数据。
* **相关性(Relevant)**:应与组织目标对齐。使之对任务有意义。
* **有时限(Time-bound)**:设定截止日期。没有永无止境的狩猎。
### SMART 假设示例
一个有用的模板:
**示例 1(CTI 驱动,TIO):**
**示例 2(行为驱动,HBO):**
在构建假设时,你可能会开发多个相互竞争的假设。关于这一点值得一读的书是 Richards J. Heuer 的《心理情报分析》,由 CIA 情报研究中心出版。他描述了**竞争假设**,这对你的狩猎工作非常有益。
该过程包括定义多个假设并确定其中最有效的,提供严谨性以帮助定义狩猎基础。7 步过程描述如下:
1. 列举所有假设
2. 为每个假设寻找支持证据
3. 通过矩阵比较证据与假设,Heuer 构建了一个矩阵来做到这一点
4. 通过矩阵移除诊断价值低的证据
5. 按可能性对假设进行优先级排序
6. 确定哪些结论依赖证据不足,并考虑该证据是否可能错误
7. 记录假设之间的比较
接下来的两个阶段深入到基于假设来决定是否执行狩猎的过程中。
此外,来自 AIMOD2 框架的一个关键概念是**假设的默认违规**,我们专注于在假设违规下识别未知,即假设对手已经绕过了我们的控制。
### 初步评估
在**初步评估**阶段,我们收集和研究数据以支持假设。这包括内部和外部来源:
* **内部来源**:之前的狩猎、经验教训、内部应用程序文档、网络和应用程序架构图、代码仓库、内部威胁情报。
* **外部来源**:OSINT、供应商博客、信息请求(RFI)给可信的外部组织。
此步骤的一个子部分是识别和(必要时)采访业务或技术负责人。根据你的狩猎,你可能需要与 SME 互动以获得更深入的理解。这并非总是必需;你可能已经凭经验或过往狩猎了解系统、日志记录和应用程序。
目标不是成为某个系统的专家,而是对环境有充分的理解。
### 可行性评估
在规划狩猎活动之前,我们需要评估可行性。这包括:
* 约束和限制
* 数据可用性
* 数据质量
* 团队技能
* 时间线
* 工具可用性
本质上,我们问:**“果汁值得挤压吗?”**
如果遥测数据不可用,问:可以使其可用吗?需要多少努力?
每次可行性评估应产生明确决策:
| 决策 | 含义 |
| --- | --- |
| ✅ **GO** | 所有标准满足,继续规划 |
| ❌ **NO-GO** | 存在关键阻塞项,列入待办并制定修复计划 |
| ⚠️ **有条件(CONDITIONAL)** | 存在小缺口,记录假设并继续 |
#### 实际可行性示例
使用上述 AS-REP Roasting 假设:
| 标准 | 状态 | 备注 |
| --- | --- | --- |
| 数据可用性 | ✅ GO | Windows Security 4768 事件已采集到所有 DC 的 Splunk |
| 数据质量 | ⚠️ 有条件 | 4768 中的预认证类型字段在 5 个 DC 中解析了 4 个,1 个 DC 的 sourcetype 损坏
| 技能 | ✅ GO | 团队具备 SPL 和 Active Directory 经验 |
| 时间线 | ✅ GO | 预计 3 天,符合当前迭代 |
| 工具 | ✅ GO | Splunk Enterprise Security 加上内部 AD 清单 |
| **总体** | ⚠️ **有条件** | 继续执行,并记录一个 DC 解析存在缺口。打开一个并行工单,在重新运行狩猎前修复 sourcetype 以实现全覆盖。 |
如果限制因素阻碍进展,将想法列入待办事项,并制定计划以在处理新假设或狩猎的同时获取所需遥测数据。
## 定义范围和目标
在这里,我们定义狩猎的**目标**。这些代表我们的狩猎目标以及实现目标所需完成的任务。由于我们的狩猎是 SMART 的,我们必须明确定义如何**衡量和管理**它们。这包括指定目标环境段、分析时间窗口、范围内的系统和资产,以及任何明确的排除项。
## 正式化行动计划(狩猎计划)
现在到了有趣的阶段,构建狩猎计划。
任何狩猎的一个关键原则是记录你的行动和发现。这使报告更容易,允许我们保留工件,并确保结果可重复。
我们的团队使用 **Jira**,但任何文档工具都适用。关键是:**只需记录**。
我们使用 **Epics(史诗)**、**Stories(故事)** 和 **Tasks(任务)** 来组织计划:
### Epics(启动)
代表狩猎的总体假设或主题。我们包括:
* 环境配置文件(来自第 0 步)
* 支持文档
* 初始研究(例如 CTI、内部文档)
* 狩猎的相关性和理由
* MITRE ATT&CK 技术映射
* 所需数据源及字段级细节
### Stories(狩猎)
这些是与 Epic 假设对齐的离散调查或测试。你可以针对一个假设开发一个或多个故事,最终**证明或推翻**它。每个故事应反映单一思维过程并作为一个测试。开发多个测试的想法不仅是为了彻底调查假设,也是为了挑战初始假设。我们应该**挑战已知的一切**。记住,威胁狩猎是关于追逐未知的,虽然你应该覆盖简单的测试(例如针对编码命令的字符串搜索),但我们应该努力更深入地思考,如果我们真的想发现未知。我相信狩猎过程中应有一定程度的挣扎;否则你可能没有学习到东西,并且可能正在实现已经存在的东西。如果是这种情况,问问自己:意义何在?
**示例:**
如果我的假设是关于管理账户的异常登录事件,我可能会有两个故事:
1. 一个使用事件代码 4624/4672 并应用已知环境上下文建立基线的方法。
2. 另一个使用机器学习建模异常的方法。
不同的方法,相同的假设。可能需要不同的测试来完全完成狩猎。
### 狩猎执行步骤
* **收集和分析数据**
+ 从指定源检索数据
+ 理解数据形态和覆盖范围
+ 数据清理、转换和建模
* **调查和验证威胁**
+ 在数据上测试假设并根据需要调整
+ 过滤和查询
+ 时间趋势和数据分析
+ 高级分析(聚类、统计方法、机器学习)
+ 已知 TTP 作为参考锚点
* **记录观察和洞察**
+ 出现的异常和洞察
+ 狩猎期间假设的变更
+ 使用的技术
+ 访问的数据源
+ 验证的 TTP 覆盖范围
通过使用 Jira 等工具,文档成为轻量级手册。我们的团队自然开始开发类似于 标签:AIMOD2, Cyber Threat Hunting, Detection Engineering, Forensics, OTHF, PEAK, Python 实现, Stakeholder Requirements, TaHiTI, Threat Intelligence, 入侵防御系统, 威胁情报, 威胁猎捕, 安全流程, 安全运营, 开发者工具, 扫描框架, 组织流程, 统一威胁狩猎流程, 网络安全, 隐私保护