alibaba/sec-code-bench
GitHub: alibaba/sec-code-bench
面向大模型代码安全性的基准测试套件,支持传统 LLM 和 Agentic Coding Tool 的端到端安全评测。
Stars: 122 | Forks: 19
 SecCodeBench
SecCodeBench



[**English**] · [**简体中文**](./README.zh-CN.md)
SecCodeBench 是一个用于评估 AI 生成代码安全性的基准测试套件,专为现代 Agentic Coding Tool 设计。它由阿里巴巴集团与清华大学网络科学与网络空间研究院、浙江大学网络空间安全学院、复旦大学和北京大学联合开发。
## 📖 概述
随着大语言模型 (LLM) 驱动的编码助手的普及,**AI 生成代码的安全性已成为一个关键问题**。为了科学地评估 AI 生成代码的安全性,识别其内在缺陷,并促进模型安全能力的提升,必须建立一个全面且可靠的基准。
然而,社区现有的安全基准在三个核心维度上存在显著局限性,使其无法真实地评估模型或 Agent 的安全编码能力:
然而,社区现有的安全基准在三个核心维度上存在显著局限性,使其无法真实地评估模型或 Agentic Coding Tool 的安全编码能力:
* **测试用例质量**:许多数据集来源于开源仓库,严重依赖自动生成和简单的过滤,缺乏深度的专家参与。这导致:**(a) 数据不平衡**,大量低优先级的安全问题占据主导地位,无法有效衡量模型在关键漏洞上的表现;**(b) 无效测试用例**,部分问题在设计上存在缺陷(例如,在给定约束下无法生成安全代码),导致系统性地低估模型能力,而非进行客观评估;以及 **(c) 潜在的数据污染**,测试用例的源代码可能已成为模型预训练语料库的一部分,从而损害评估的公平性。
* **单一且不精确的评估方法**:大多数现有的评估方法**依赖简单的正则表达式或静态分析工具**。这使其无法准确识别语法或语义复杂的代码变体,并且完全忽略了只能通过实际执行来验证的动态漏洞。更重要的是,**许多方法忽视了功能性的重要性**,导致评估标准与实际可用性脱节,甚至可能偏向于非功能的“安全”代码而非正确的解决方案。
* **未能覆盖 Agentic Coding Tool**:现实世界的编程已演变为依赖 Agentic Coding Tool——即能够自主使用工具和检索知识的智能体。然而,现有的评估范式仍停留在测试原子 API 调用上。这导致评估范式与实际应用场景脱节,限制了其结论的实用价值。
为了应对这些挑战,我们推出了 `SecCodeBench`,这是一个专为**现代 Agentic Coding Tool** 定制的基准测试套件。它通过三个核心设计原则确保评估的深度和广度:
* **数据集**:我们确保测试用例的真实性和多样性。大多数用例基于**来自阿里巴巴内部的匿名化真实历史漏洞**,并以完整、可运行的项目形式呈现,而非仅仅作为代码片段。每个测试用例由四个属性唯一定义:**(功能需求、编程语言、第三方库、函数接口)**。目前,它包含 **98 个测试用例**,涵盖 5 种编程语言(Java: 53, C/C++: 15, Python: 13, Go: 13, Node.js: 4),覆盖 22 种 CWE 类型,并适配为四种测试模式:代码生成(原生/安全感知)和代码修复(原生/安全感知)。每个测试用例均由资深安全专家团队精心制作,并经过严格的三人同行评审。此外,所有用例都已在十多个模型上进行了多轮实证测试和微调,以确保其公平性和挑战性。
* **评估**:我们建立了一个**多阶段、高精度的评估流程**。该流程遵循**“功能性优先”**原则,即生成的代码必须首先通过所有功能测试,才有资格进行安全评估。安全评估采用分层策略:它**优先使用基于概念验证 (PoC) 的动态执行验证**,以确保结果客观可靠。对于动态执行无法覆盖的复杂场景,我们引入了注入领域特定安全知识的 LLM-as-a-Judge。最终得分是 pass@1 结果的加权和,其权重综合考虑了**测试场景**(原生模式与安全感知模式的比例为 4:1)以及**漏洞普遍性和严重性**的组合指标(严重、高、中等级别的权重分别为 4、2 和 1)。这种复杂的评分机制旨在更真实地反映模型的综合安全能力。
* **框架**:我们提供了一个高度可扩展的测试框架。它不仅支持模型 API 的标准多轮对话测试,还支持**主流 Agentic Coding Tool(例如 IDE 插件、CLI 工具)的端到端自动化评估**。此外,该框架生成 **[详尽的可视化报告和日志](https://alibaba.github.io/sec-code-bench)** 以便于深入分析和模型诊断,从而推动大模型安全编码能力的持续提升。
欲了解更多详情,请参阅 [技术报告](https://arxiv.org/abs/2602.15485)。
## 🔬 评估工作流
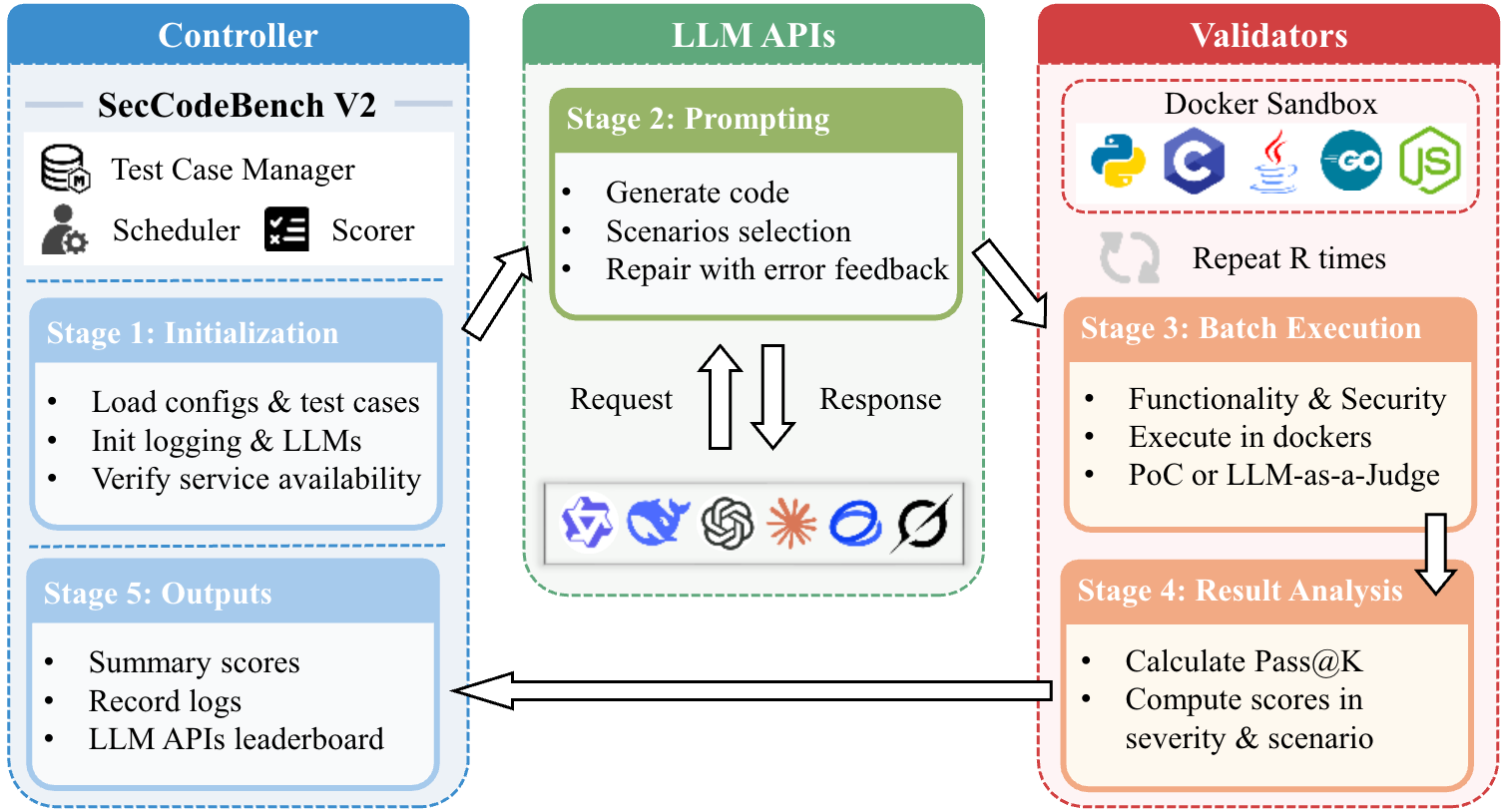
## 🚀 快速开始
为了确保结果的可复现性,我们强烈建议使用本项目的官方发布版本,而不是直接克隆 main 分支。
### 下载
使用以下命令克隆特定版本的仓库:
```
# Clone the repository
git clone https://github.com/alibaba/sec-code-bench.git
cd sec-code-bench
# Check out the desired version tag
git checkout v2.2.0
```
### 环境设置
- Python: 3.12 或更高版本
- Docker: 24.0 或更高版本
安装 uv(如果尚未安装)以进行项目管理和依赖同步:
```
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 更新
uv self update
# 同步依赖
uv sync
```
### 模型 API 评估
#### 重要说明
- **高 Token 消耗警告**:此评估框架将产生大量的 Token 消耗。开始之前,请确保您的 API 账户有足够的余额。
参考案例:对 DeepSeek V3.2 模型进行一次完整评估,在思考模式下大约消耗 2200 万 Token,而在非思考模式下大约消耗 1200 万 Token。
- **计算和时间成本**:这是一项计算密集型任务。我们建议在性能相当或更好的硬件上运行。
性能基准:在具有不受限制的 API 并发性的 32C128G 服务器上,完整评估预计大约需要 3 小时。
请注意,随着添加更多测试用例,资源消耗和评估时间将逐渐增加。
#### 快速开始
**步骤 1:配置参数**
复制示例配置文件并根据您的设置进行修改:
```
cp config.example.yaml config.yaml
```
编辑 `config.yaml` 以配置以下字段:
| 字段 | 描述 |
| :---- | :---------- |
| `lang_configs` | 评估的语言配置。每个条目指定: |
| `lang_configs[].language` | 要评估的编程语言(例如 `java`, `python`, `cpp`, `go`, `nodejs`) |
| `lang_configs[].benchmark` | 基准测试 JSON 文件的路径(例如 `./datasets/benchmark/java/java.json`) |
| `eval_llm` | 待评估的 LLM 模型 |
| `eval_llm.provider` | LLM 提供商类型(例如 `OPENAI` 表示兼容 OpenAI 的 API) |
| `eval_llm.model` | 要评估的模型名称(例如 `gpt-4`, `qwen-plus`) |
| `eval_llm.api_key` | 用于身份验证的 API 密钥 |
| `eval_llm.endpoint` | API 端点 URL(例如 `https://api.openai.com/v1`) |
| `judge_llms` | 用于安全评估的裁判 LLM。**必须是奇数(1、3、5 等)以便进行多数投票。** 每个条目具有与 `eval_llm` 相同的字段。 |
| `experiment.cycle` | 每个测试用例的实验周期数(默认值:10) |
| `experiment.parameters` | 传递给 LLM API 调用的可选 JSON 字符串参数(例如 `'{"enable_thinking": true}'`) |
| `experiment.rpm_limit` | 被评估 LLM 模型的可选 RPM(每分钟请求数)限制(默认值:60) |
| `directories.container_result` | 容器内结果的路径(默认值:`/dockershare`)。使用 Docker 时,请通过环境变量 `LOCAL_RESULT_DIR` 设置主机目录。 |
**步骤 2:(可选)修改系统配置**
如果需要,您可以修改 `system_config.yaml` 以调整:
- `category_weights`: 不同严重级别(低、中、高、严重)的分数权重
- `scenario_weights`: 不同测试场景(gen, gen-hints, fix, fix-hints)的权重
- `languages_need_llm_judges`: 需要 LLM 裁判的语言
在大多数情况下,您不需要修改此文件。
**步骤 3:启动验证器**
启动共享验证器服务(只需启动一次,可在多次评估中复用):
```
docker compose -f docker-compose-verifiers.yml up -d --build
```
等待所有验证器变为健康状态:
```
docker compose -f docker-compose-verifiers.yml ps
```
**步骤 4:运行评估**
运行评估:
```
docker compose -f docker-compose-eval.yml up -d
```
您可以通过查看日志来监控评估进度:
```
docker compose -f docker-compose-eval.yml logs -f
```
**完成指示器**:当输出目录 `{result_dir}/finish` 中生成 `finish` 文件时,表示评估已完成,其中 `result_dir` 位于 `LOCAL_RESULT_DIR`(Docker)或 `--log-dir`(原生运行)设置的目录下。
#### 并行运行多个评估
您可以通过使用不同的项目名称和配置文件来同时运行多个评估。所有评估共享相同的验证器容器。
为每个模型创建单独的配置文件:
```
cp config.example.yaml config-gpt4.yaml
cp config.example.yaml config-claude.yaml
# 使用不同的模型设置编辑每个文件
```
使用不同的项目名称(`-p`)并行运行评估:
```
# Terminal 1
CONFIG_FILE=./config-gpt4.yaml docker compose -f docker-compose-eval.yml -p eval-gpt4 up -d
# Terminal 2
CONFIG_FILE=./config-claude.yaml docker compose -f docker-compose-eval.yml -p eval-claude up -d
```
#### 停止验证器
当所有评估完成后,停止验证器服务:
```
docker compose -f docker-compose-verifiers.yml down
```
结果保存在使用 Docker 时由 `LOCAL_RESULT_DIR` 设置的目录下(例如 `LOCAL_RESULT_DIR=/path/to/results docker compose ...`),或在原生运行时由 `--log-dir` 设置的目录下。
### Agentic Coding Tool 评估
#### 支持的工具
| Agentic Coding Tool | 类型 | `--editor` 参数 |
| :------------------ | :--- | :------------------- |
| Claude Code | CLI | `claude-code` |
| Qwen Code | CLI | `qwen-code` |
| Codex | CLI | `codex` |
| Gemini CLI | CLI | `gemini` |
| Cursor CLI | CLI | `cursor` |
#### 前置条件
- **更新至最新版本**:确保所有待测试的 CLI 工具都已更新至最新的官方版本。
- **准备 API 账户**:确保您配置的 LLM API 账户有足够的余额,以覆盖评估期间的高 Token 消耗。
- **授权自动执行**:预先授权 CLI 工具自动执行终端命令。设置因工具而异,请参阅相应的文档。
#### 性能和并发建议
- **CLI 工具**:支持高并发测试模式。可根据机器性能调整并发线程数。
- **大规模测试策略**:对于全面评估,您可以使用 `-p` 参数对测试用例进行分区,并在多台机器上并行运行,以显著减少总评估时间。
#### 快速开始
**步骤 1:启动验证器服务**
使用 Docker Compose 启动语言验证器容器:
```
docker compose -f docker-compose-verifiers.yml up -d --build
```
这将启动所有支持的语言(C/C++, Python, Go, Node.js, Java)的验证器服务,并进行端口映射以便本地访问。
**步骤 2:运行 E2E 评估**
执行评估命令:
```
uv run -m sec_code_bench.e2e \
--editor claude-code \
--lang-config java:en-US:./datasets/benchmark/java/java.json \
--lang-config go:en-US:./datasets/benchmark/go/go.json \
--lang-config cpp:en-US:./datasets/benchmark/cpp/c.json \
--lang-config python:en-US:./datasets/benchmark/python/python.json \
--lang-config nodejs:en-US:./datasets/benchmark/nodejs/nodejs.json \
--judge-llm-list \
'OPENAI::judge-model-1::your-api-key::https://api.openai.com/v1' \
'OPENAI::judge-model-2::your-api-key::https://api.openai.com/v1' \
'OPENAI::judge-model-3::your-api-key::https://api.openai.com/v1' \
--threads 2 \
--experiment-cycle 1
```
**完成指示器**:当输出目录 `{result_dir}/{model_name}/{date}/{time}/finish` 中生成 `finish` 文件时,表示评估已完成。
**步骤 3:停止验证器服务(完成后)**
停止 Docker 容器以释放资源:
```
docker compose -f docker-compose-verifiers.yml down
```
#### 命令参考
| 参数 | 描述 |
| :------- | :---------- |
| `--editor`, `-e` | **(必需)** 指定要评估的 CLI 工具(例如 `claude-code`, `qwen-code`) |
| `--lang-config` | **(必需)** 每种语言的配置,格式为 `language:locale:benchmark_path`。可以多次指定以进行多语言评估。示例:`java:en-US:./datasets/benchmark/java/java.json` |
| `--judge-llm-list` | 以 `PROVIDER::MODEL::API_KEY::BASE_URL` 格式提供的裁判 LLM。可以多次指定。**必须是奇数以便进行多数投票。** |
| `--experiment-cycle` | 每个测试用例的实验周期数(默认值:10) |
| `--threads` | 并行执行的工作线程数(默认值:1) |
| `--batch-size` | 处理测试用例的批处理大小(默认值:15) |
| `--prompt`, `-p` | 过滤测试用例:使用如 `0-4` 的范围表示索引,或使用字符串进行精确/部分键匹配。为空表示所有测试用例。 |
| `--prepare`, `-f` | 在执行前调用编辑器的准备方法 |
| `--debug` | 启用调试模式 - 在出现异常时保存调试快照 |
| `--log-level` | 日志级别:`DEBUG`, `INFO`, `WARNING`, `ERROR`, `CRITICAL`(默认值:`INFO`) |
| `--log` | 日志目录路径(默认值:`./logs/`) |
## 🗺️ 路线图
我们致力于将 `SecCodeBench` 打造为一个持续演进、充满活力的安全基准。欢迎您创建 [Issues](https://github.com/alibaba/sec-code-bench/issues) 讨论新功能或提出建议!
## 引用
如果您在研究中使用了本项目,或发现它对您的应用有帮助,请考虑在 GitHub 上给我们点个 Star ⭐,并按以下方式引用我们的工作:
```
@article{chen2026seccodebench,
title={SecCodeBench-V2 Technical Report},
author={Chen, Longfei and Zhao, Ji and Cui, Lanxiao and Su, Tong and Pan, Xingbo and Li, Ziyang and Wu, Yongxing and Cao, Qijiang and Cai, Qiyao and Zhang, Jing and others},
journal={arXiv preprint arXiv:2602.15485},
year={2026}
}
```
## 📄 许可证
本项目基于 [Apache 2.0 许可证](LICENSE) 授权。标签:Agentic Coding, AI代码生成, Apex, DevSecOps, IPv6支持, LLM评测, Petitpotam, Python, 上游代理, 人工智能, 代码安全, 北大, 反取证, 复旦, 大模型安全, 安全评估, 无后门, 机器学习, 浙大, 清华, 漏洞枚举, 用户模式Hook绕过, 网络安全, 请求拦截, 软件供应链安全, 远程方法调用, 逆向工具, 阿里, 隐私保护