English | [简体中文](README_cn.md)
一个更易用、全面且高效的大模型压缩工具包。
✒️ 技术报告 | 📖 文档 | 🤗 Hugging Face | 🤖 ModelScope
💬 微信 | 🫨 Discord
## 📣 最新消息
- [26/04/29] 我们发布了腾讯 Hy-MT1.5-1.8B 翻译模型的 2-bit 和 1.25-bit 版本:[Hy-MT1.5-1.8B-2bit](https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-2bit) 和 [Hy-MT1.5-1.8B-1.25bit](https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit)。此外,我们还提供了一个[离线翻译演示](https://huggingface.co/AngelSlim/Hy-MT1.5-1.8B-1.25bit/blob/main/Hy-MT-demo.apk)供您试用。欢迎大家体验!🔥🔥🔥
- [26/04/23] 我们现已支持 **Hy3-preview** (MoE A20B) 的 FP8-Static 量化。
- [26/03/25] 我们发布了 **DAQ**,这是一种在后训练更新参数相对较小的情况下,能够保留已获取知识的量化算法。[[论文]](https://arxiv.org/abs/2603.22324) | [[文档]](docs/source/features/quantization/daq.md)
- [26/02/09] 我们发布了 HY-1.8B-2Bit,一款 2-bit 的端侧大语言模型,[[Huggingface]](https://huggingface.co/AngelSlim/HY-1.8B-2Bit)。
- [26/01/13] 我们发布了 v0.3 版本。我们支持所有规模 LLM/VLM/音频模型的 Eagle3 训练与部署,详情请参阅[指引文档](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/eagle/index.html)。同时,我们发布了 **Sherry**,一种硬件高效的 1.25 bit 量化算法 [[论文]](https://arxiv.org/abs/2601.07892) | [[代码]](https://github.com/Tencent/AngelSlim/tree/sherry/Sherry)🔥🔥🔥
历史消息
- [25/11/05] 我们发布了 v0.2 版本。新增对 `GLM-4.6`、`Qwen3-VL` 和 `Qwen3-Omni` 等新模型的量化支持,开源了 Eagle3 推测解码训练框架,并更新了 Diffusion 模型量化工具。
- [25/09/30] 我们发布了 **SpecExit**,一种推理提前退出算法:[[论文]](http://arxiv.org/abs/2509.24248) | [[文档]](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/spec_exit.html) | [[vLLM 代码]](https://github.com/vllm-project/vllm/pull/27192)
- [25/09/26] 我们发布了 **TEQUILA**,一种三值量化算法 [[论文]](https://arxiv.org/abs/2509.23809) | [[代码]](https://github.com/Tencent/AngelSlim/tree/tequila/TernaryQuant)
- [25/09/24] 我们现已支持 Qwen3 系列模型的 NVFP4 PTQ 量化。同时我们也开源了 [Qwen3-32B-NVFP4](https://huggingface.co/AngelSlim/Qwen3-32B_nvfp4) 和 [Qwen3-235B-A22B-NVFP4](https://huggingface.co/AngelSlim/Qwen3-235B-A22B_nvfp4) 权重。
- [25/09/01] 我们现已支持 [Hunyuan-MT-7B](https://huggingface.co/tencent/Hunyuan-MT-7B-fp8) 翻译模型的 FP8 量化。并为 Eagle3 启用了 Torch 推理和 Benchmark 评估。同时实现了对 [FLUX](https://github.com/Tencent/AngelSlim/tree/main/configs/flux) 的量化和 Cache 支持。并支持对 [Seed-OSS](https://github.com/Tencent/AngelSlim/tree/main/configs/seed_oss) 的量化。
- [25/08/06] 我们现已支持 `Hunyuan 0.5B/1.8B/4B/7B` 和多模态模型 `Qwen2.5VL 3B/7B/32B/72B` 的量化,包括 `FP8/INT4` 算法,以及 `DeepSeek-R1/V3` 和 `Kimi-K2` 的量化,包括 `FP8-Static` 和 `W4A8-FP8` 算法。我们也开源了 `Hunyuan 1.8B/4B/7B` 系列 Eagle3 模型权重。
- [25/07/04] 我们现已支持 `Hunyuan/Qwen2.5/Qwen3/DeepSeek-R1-Distill-Qwen` 等模型的量化,包括 `INT8/FP8/INT4` 算法。我们也开源了 `Qwen3` 系列 Eagle3 模型权重。
## 🌟 核心特性
- **高度集成**:该工具包将主流的压缩算法集成到统一的框架中,为开发者提供一键式访问,具有极佳的易用性。
- **持续创新**:除了集成业界广泛使用的算法外,我们还在不断研究更好的压缩算法,并将在未来逐步开源。
- **性能驱动**:我们持续优化模型压缩工作流和算法部署的端到端性能,例如实现在单张 GPU 上对 Qwen3-235B 和 DeepSeek-R1 等模型进行量化。
## 💼 技术概览
| 场景 |
模型 |
压缩策略 |
| 量化 |
推测解码 |
其他技术 |
| 大语言模型 |
|
|
|
|
| 视觉语言模型 |
|
|
|
|
| Diffusion 模型 |
|
|
- |
|
| 语音模型 (TTS/ASR) |
|
|
|
|
## 🛎️ 如何使用
### 1. 安装 AngelSlim
我们推荐使用 `pip` 来安装最新稳定版的 `AngelSlim`:
```
pip install angelslim
```
或者,您可以克隆仓库并以可编辑模式从源码安装:
```
cd AngelSlim && python setup.py install
```
有关更详细的安装说明和特定平台的指导,请参阅[安装文档](https://angelslim.readthedocs.io/zh-cn/latest/getting_started/installation.html)。
### 2. 快速开始
#### 2.1 推测解码
安装 AngelSlim 后,您可以使用以下脚本快速启动 Eagle3 训练:
```
# 启动 vLLM 服务器
bash scripts/speculative/run_vllm_server.sh
# 生成训练数据
bash scripts/speculative/generate_data_for_target_model.sh
# 对 Eagle3 模型进行在线训练
bash scripts/speculative/train_eagle3_online.sh
```
Eagle3 的训练和部署指南:[LLM](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/eagle/eagle.html) | [VLM](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/eagle/vlm_eagle.html) | [音频 (ASR)](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/eagle/audio_asr_eagle.html) | [音频 (TTS)](https://angelslim.readthedocs.io/zh-cn/latest/features/speculative_decoding/eagle/audio_tts_eagle.html)。
#### 2.2 LLM/VLM/音频模型量化
安装 `AngelSlim` 后,您可以通过以下单行脚本对 Qwen3-1.7B 模型启动静态 FP8 量化:
```
python3 tools/run.py -c configs/qwen3/fp8_static/qwen3-1_7b_fp8_static.yaml
```
此示例通过对从 HuggingFace 加载的模型执行 PTQ 校准来生成量化模型权重。
对于 **Hy3-preview** (MoE A20B) FP8-Static 量化:
```
python tools/run.py -c configs/hunyuan/fp8_static/hunyuanv3_a20b_fp8_static_c8.yaml
```
基于代码的启动
要对 `Qwen3-1.7B` 执行动态 `FP8` 量化:
```
from angelslim.engine import Engine
slim_engine = Engine()
# 准备模型
slim_engine.prepare_model(model_name="Qwen", model_path="Qwen/Qwen3-1.7B",)
# 初始化 Compressor
slim_engine.prepare_compressor("PTQ", default_method="fp8_dynamic")
# 压缩模型
slim_engine.run()
# 保存压缩后的模型
slim_engine.save("./output")
```
获取更多细节,请参阅[快速开始文档](https://angelslim.readthedocs.io/zh-cn/latest/getting_started/quickstrat.html)。
#### 2.3 Diffusion 模型量化
使用 `scripts/diffusion/run_diffusion.py` 进行量化和推理:
```
# 在线量化和推理
python scripts/diffusion/run_diffusion.py \
--model-name-or-path black-forest-labs/FLUX.1-schnell \
--quant-type fp8-per-tensor \
--prompt "A cat holding a sign that says hello world" \
--height 1024 --width 1024 --steps 4 --guidance 0.0 --seed 0
```
获取更多量化推理方法,请参阅 [Diffusion 模型量化文档](https://angelslim.readthedocs.io/zh-cn/latest/features/diffusion/quantization.html)。
#### 2.4 Token 压缩
AngelSlim 为视觉 Token 剪枝和合并提供了一个通用的元数据驱动框架。您可以通过冒烟测试快速验证压缩策略(例如,**VisionZip**):
```
python tools/test_universal_pruning.py \
--model_path "Qwen/Qwen2.5-VL-3B-Instruct" \
--config "configs/qwen2_5_vl/pruning/visionzip_r0.9.yaml"
```
获取更多实现新策略的细节,请参阅 [Token Compressor 文档](https://angelslim.readthedocs.io/zh-cn/latest/features/token_compressor/index.html)。
### 3. 部署与测试
#### 3.1 离线推理
测试使用通过 `transformers` 加载的量化模型进行离线推理。
运行脚本详情
```
python scripts/deploy/offline.py $MODEL_PATH "Hello, my name is"
```
其中 `MODEL_PATH` 是输出的量化模型路径。
#### 3.2 API 服务部署
指定量化模型路径 `MODEL_PATH` 后,您可以使用 **vLLM** 和 **SGLang** 推理框架部署兼容 OpenAI 的 API 服务。
运行脚本详情
- **vLLM**
使用以下脚本启动 [vLLM](https://github.com/vllm-project/vllm) 服务器,推荐版本为 `vllm>=0.8.5.post1`。对于 MOE INT8 量化模型,需要 vllm>=0.9.0。
bash scripts/deploy/run_vllm.sh --model-path $MODEL_PATH --port 8080 -d 0,1,2,3 -t 4 -p 1 -g 0.8 --max-model-len 4096
其中 `-d` 是可见设备,`-t` 是张量并行大小,`-p` 是流水线并行大小,`-g` 是 GPU 显存利用率。
- **SGLang**
使用以下脚本启动 [SGLang](https://github.com/sgl-project/sglang) 服务器,推荐版本为 `sglang>=0.4.6.post1`。
bash scripts/deploy/run_sglang.sh --model-path $MODEL_PATH --port 8080 -d 0,1,2,3 -t 4 -g 0.8
#### 3.3 服务调用
通过 [OpenAI API 格式](https://platform.openai.com/docs/api-reference/introduction) 调用请求。
运行脚本详情
```
bash scripts/deploy/openai.sh -m $MODEL_PATH -p "Hello, my name is" --port 8080 --max-tokens 4096 --temperature 0.7 --top-p 0.8 --top-k 20 --repetition-penalty 1.05 --system-prompt "You are a helpful assistant."
```
其中 `-p` 是输入 prompt。
#### 3.4 性能评估
使用 [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) 评估量化模型的性能,推荐版本为 `lm-eval>=0.4.8`。
运行脚本详情
```
bash scripts/deploy/lm_eval.sh -d 0,1 -t 2 -g 0.8 -r $RESULT_PATH -b "auto" --tasks ceval-valid,mmlu,gsm8k,humaneval -n 0 $MODEL_PATH
```
其中 `RESULT_PATH` 是保存测试结果的目录,`-b` 是 batch size,`--tasks` 指定评估任务,`-n` 是 few-shot 示例的数量。
获取更多细节,请参阅[部署文档](https://angelslim.readthedocs.io/zh-cn/latest/deployment/deploy.html)。
## 📈 基准测试
### 1. 推测解码
我们在 vLLM 上评估了由 AngelSlim 训练的 Eagle3 模型,评估任务包括代码生成、数学推理、指令跟随、文本生成和多模态理解。我们在 num_speculative_tokens = 2 或 4 的设置下展示了训练模型的推理加速和上下文长度性能,其接受长度为 1.8–3.5,最大加速比达 1.4–1.9×。
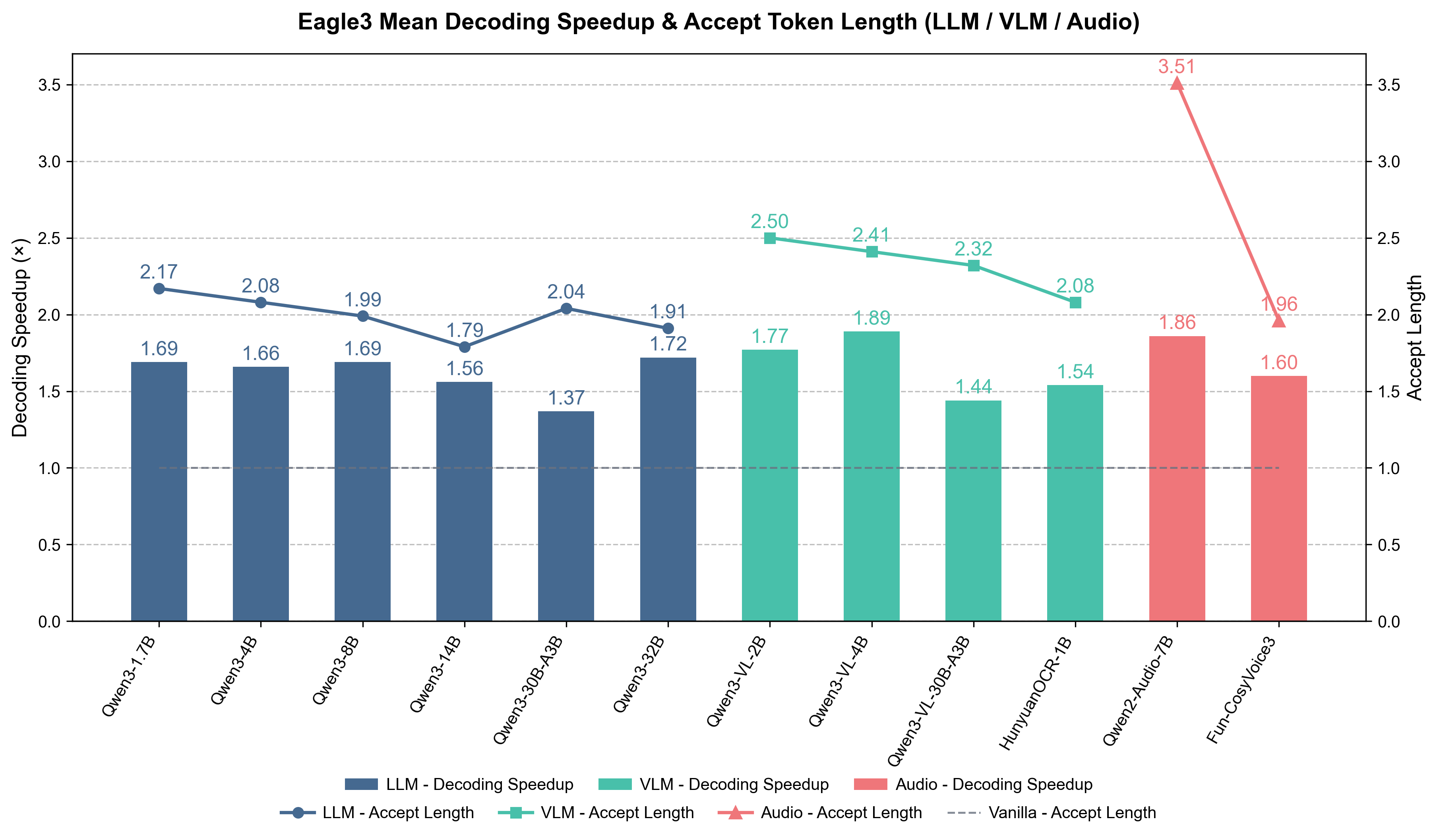
#### 1.1 Qwen3 系列模型
Qwen3 系列模型在 vLLM (v0.11.2) 上使用 Eagle3 推测解码在 **MT-bench**、**HumanEval**、**GSM8K** 和 **Alpaca** 数据集上的基准测试结果,使用单张 GPU (**tp=1, ep=1, num_speculative_tokens=2, batch_size=1, output_len=1024**)。
| 模型 |
方法 |
GSM8K |
Alpaca |
HumanEval |
MT-bench |
平均值 |
| |
吞吐量 (tokens/s) | 接受长度 |
吞吐量 (tokens/s) | 接受长度 |
吞吐量 (tokens/s) | 接受长度 |
吞吐量 (tokens/s) | 接受长度 |
吞吐量 (tokens/s) | 接受长度 |
| Qwen3-1.7B |
Vanilla |
376.42 | 1 |
378.86 | 1 |
378.38 | 1 |
390.53 | 1 |
381.05 | 1 |
| Eagle3 |
616.9 | 2.13 |
653.29 | 2.19 |
680.1 | 2.2 |
621.44 | 2.17 |
642.93 | 2.17 |
| Qwen3-4B |
Vanilla |
229.05 | 1 |
235.29 | 1 |
234.66 | 1 |
234.04 | 1 |
233.26 | 1 |
| Eagle3 |
389.35 | 2.07 |
395.97 | 2.1 |
377.84 | 2.08 |
384.6 | 2.07 |
386.94 | 2.08 |
| Qwen3-8B |
Vanilla |
149.63 | 1 |
149.93 | 1 |
153.85 | 1 |
153.81 | 1 |
151.81 | 1 |
| Eagle3 |
257.32 | 2 |
266.69 | 2.02 |
244.89 | 1.97 |
258.2 | 1.97 |
257.52 | 1.99 |
| Qwen3-14B |
Vanilla |
92.97 | 1 |
92.66 | 1 |
92.94 | 1 |
94.46 | 1 |
93.26 | 1 |
| Eagle3 |
153.72 | 1.87 |
140.46 | 1.78 |
144.68 | 1.76 |
142.45 | 1.74 |
145.33 | 1.79 |
| Qwen3-32B |
Vanilla |
43.49 | 1 |
43.38 | 1 |
43.19 | 1 |
43.3 | 1 |
43.32 | 1 |
| Eagle3 |
80.43 | 2.01 |
72.49 | 1.9 |
71.57 | 1.86 |
74.1 | 1.86 |
74.1 | 1.91 |
| Qwen3-30B-A3B |
Vanilla |
311.84 | 1 |
320.43 | 1 |
325.77 | 1 |
325.42 | 1 |
320.87 | 1 |
| Eagle3 |
453.97 | 2.1 |
432.45 | 2.04 |
428.81 | 2.02 |
437.06 | 2.01 |
438.07 | 2.04 |
#### 1.2 VLM 模型
##### 1.2.1 Qwen3-VL 系列模型
Qwen3-VL 系列模型在 vLLM (v0.12.0) 上使用 Eagle3 推测解码在语言和多模态任务上的基准测试结果,使用单张 GPU (**tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024**)。
| 模型 |
方法 |
GSM8K |
Alpaca |
HumanEval |
MT-bench |
MATH-500 |
MMMU |
MMStar |
平均值 |
|
|
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
吞吐量 (tokens/s) |
接受长度 |
| Qwen3-VL-2B-Instruct |
Vanilla |
348.55 |
1 |
350.9 |
1 |
346.07 |
1 |
346.31 |
1 |
82.96 |
1 |
83.27 |
1 |
81.63 |
1 |
234.24 |
1 |
| Eagle3 |
511.52 |
2.11 |
560.55 |
2.26 |
826.01 |
3.39 |
555.22 |
2.29 |
163.09 |
2.57 |
154.18 |
2.55 |
139.73 |
2.31 |
415.76 |
2.5 |
| Qwen3-VL-4B-Instruct |
Vanilla |
212.87 |
1 |
213.24 |
1 |
211.69 |
1 |
212.1 |
1 |
67.96 |
1 |
65.88 |
1 |
67.75 |
1 |
150.21 |
1 |
| Eagle3 |
415.29 |
2.57 |
372.89 |
2.26 |
459.37 |
2.82 |
382.33 |
2.34 |
141.87 |
2.72 |
104.44 |
2.05 |
107.07 |
2.1 |
283.32 |
2.41 |
| Qwen3-VL-30B-A3B-Instruct |
Vanilla |
179.94 |
1 |
184.6 |
1 |
168.68 |
1 |
180.57 |
1 |
31.08 |
1 |
31.51 |
1 |
30.93 |
1 |
115.33 |
1 |
| Eagle3 |
281.93 |
2.82 |
241.42 |
2.13 |
223.05 |
2.57 |
240.47 |
2.19 |
75.31 |
2.79 |
48.47 |
1.78 |
52.57 |
1.94 |
166.17 |
2.32 |
##### 1.2.2 HunyuanOCR 模型
HunyuanOCR 模型在 vLLM (v0.13.0) 上使用 Eagle3 推测解码在 **[OmniDocBench](https://huggingface.co/datasets/opendatalab/OmniDocBench)** 数据集上的基准测试结果,使用单张 GPU (**tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024**)。
| 模型 |
方法 |
OmniDocBench |
|
|
吞吐量 (tokens/s) |
接受长度 |
| Hunyuan-OCR |
Vanilla |
70.12 |
1 |
| Eagle3 |
108.1 |
2.08 |
#### 1.3 音频模型
##### 1.3.1 Qwen2-Audio 模型
Qwen2-Audio 模型在 vLLM (v0.12.0) 上使用 Eagle3 推测解码在 **[LibriSpeech](https://www.openslr.org/12)** 数据集上的基准测试结果,使用单张 GPU (**tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024**)。
| 模型 |
方法 |
LibriSpeech |
|
|
吞吐量 (tokens/s) |
接受长度 |
| Qwen2-Audio |
Vanilla |
78.76 |
1 |
| Eagle3 |
146.66 |
3.51 |
##### 1.3.2 Fun-CosyVoice3 模型
Fun-CosyVoice3 模型使用 Eagle3 推测解码在 **[LibriTTS](https://www.openslr.org/60/)** 数据集上的基准测试结果,使用单张 GPU (**tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024**)。
| 模型 |
方法 |
LibriTTS |
|
|
吞吐量 (tokens/s) |
接受长度 |
| Fun-CosyVoice3 |
Vanilla |
- |
1 |
| Eagle3 |
- |
1.96 |
### 2. 量化
部分模型的性能测试结果如下所示。有关完整的基准测试,请参阅 [Benchmark 文档](https://angelslim.readthedocs.io/zh-cn/latest/performance/quantization/benchmarks.html)
#### 2.1 Hunyuan 系列模型
`Hunyuan-Instruct` 模型在 `OlympiadBench`、`AIME 2024` 和 `DROP` 数据集上使用 `FP8`、`INT4-AWQ` 和 `INT4-GPTQ` 量化算法的基准测试结果:
| 模型 | 量化 | OlympiadBench | AIME 2024 | DROP | GPQA-Diamond |
|---|
| Hunyuan-A13B-Instruct |
BF16 | 82.7 | 87.30 | 91.1 | 71.2 |
| FP8-Static | 83.0 | 86.7 | 91.1 | - |
| Int4-GPTQ | 82.7 | 86.7 | 91.1 | - |
| Int4-AWQ | 82.6 | 85.6 | 91.0 | - |
| Hunyuan-7B-Instruct |
BF16 | 76.5 | 81.1 | 85.9 | 60.1 |
| FP8-Static | 76.6 | 80.9 | 86.0 | 60.1 |
| Int4-GPTQ | 76.2 | 81.0 | 85.7 | 60.0 |
| Int4-AWQ | 76.4 | 80.9 | 85.9 | 60.1 |
| Hunyuan-4B-Instruct |
BF16 | 73.1 | 78.3 | 78.2 | 61.1 |
| FP8-Static | 73.1 | 76.6 | 78.3 | 60.2 |
| Int4-GPTQ | 72.9 | - | 78.1 | 58.1 |
| Int4-AWQ | 72.8 | - | 78.2 | - |
| Hunyuan-1.8B-Instruct |
BF16 | 63.4 | 56.7 | 76.7 | 47.2 |
| FP8-Static | 62.5 | 55.2 | 75.1 | 47.7 |
| Int4-GPTQ | 60.9 | - | 73.0 | 44.4 |
| Int4-AWQ | 61.7 | - | 71.7 | 43.6 |
| Hunyuan-0.5B-Instruct |
BF16 | 29.6 | 17.2 | 52.8 | 23.3 |
| FP8-Static | 29.6 | 17.2 | 51.6 | 22.5 |
| Int4-GPTQ | 26.8 | - | 50.9 | 23.3 |
| Int4-AWQ | 26.3 | - | 48.9 | 23.3 |
#### 2.2 Qwen3 系列模型
Qwen3 系列模型在 `CEVAL`、`MMLU`、`GSM8K` 和 `HUMANEVAL` 数据集上使用 `FP8-Static`、`FP8-Dynamic`、`INT4-GPTQ` 和 `INT4-AWQ` 量化算法的基准测试结果:
| 模型 | 量化 | CEVAL | MMLU | GSM8K | HUMANEVAL |
|---|
| Qwen3-0.6B | BF16 | 45.84 | 47.21 | 42.99 | 19.51 |
| FP8-Static | 45.99 | 46.87 | 38.06 | 18.90 |
| FP8-Dynamic | 45.99 | 46.93 | 38.29 | 20.73 |
| INT8-Dynamic | 45.17 | 46.95 | 41.17 | 21.34 |
| Qwen3-8B | BF16 | 79.27 | 74.78 | 87.79 | 63.41 |
| FP8-Static | 78.23 | 74.79 | 86.96 | 62.20 |
| FP8-Dynamic | 78.45 | 74.75 | 87.64 | 62.80 |
| INT8-Dynamic | 78.01 | 74.84 | 86.96 | 67.07 |
| INT4-GPTQ | 77.19 | 73.26 | 86.43 | 62.20 |
| INT4-AWQ | 76.15 | 73.59 | 86.96 | 63.41 |
| Qwen3-14B | BF16 | 83.06 | 78.90 | 88.40 | 55.49 |
| FP8-Static | 82.62 | 78.57 | 89.46 | 57.32 |
| FP8-Dynamic | 82.24 | 78.92 | 88.32 | 52.44 |
| INT8-Dynamic | 81.87 | 78.13 | 86.28 | 56.10 |
| INT4-GPTQ | 81.05 | 78.02 | 87.34 | 57.93 |
| INT4-AWQ | 82.02 | 77.68 | 84.23 | 61.59 |
| Qwen3-32B | BF16 | 86.55 | 82.00 | 74.53 | 37.80 |
| FP8-Static | 86.92 | 81.78 | 70.20 | 39.63 |
| FP8-Dynamic | 86.55 | 81.89 | 70.43 | 38.41 |
| INT4-GPTQ | 86.18 | 81.01 | - | 43.29 |
| INT4-AWQ | 86.18 | 81.54 | - | 36.59 |
| Qwen3-30B-A3B | BF16 | 83.66 | 79.36 | 89.99 | 31.71 |
| FP8-Static | 83.95 | 79.47 | 89.01 | 31.10 |
| FP8-Dynamic | 84.10 | 79.40 | 89.16 | 32.93 |
| INT8-Dynamic | 83.36 | 79.48 | 89.16 | 34.15 |
| Qwen3-235B-A22B | BF16 | 89.60 | 86.28 | 85.29 | 27.44 |
| FP8-Static | 89.67 | 86.19 | 86.96 | 27.44 |
| FP8-Dynamic | 89.67 | 86.18 | 85.22 | 28.05 |
| INT8-Dynamic | 88.93 | 86.20 | 86.20 | 23.78 |
#### 2.3 DeepSeek 系列模型
DeepSeek-R1-0528 系列模型在 `GPQA Diamond`、`IME 2024`、`SimpleQA` 和 `LiveCodeBench` 数据集上使用 `FP8-Block-Wise` 和 `W4A8-FP8` 量化算法的基准测试结果:
| 模型 | 量化 | GPQA Diamond | AIME 2024 | SimpleQA | LiveCodeBench |
|---|
| DeepSeek-R1-0528 | FP8-Block-Wise | 78.28 | 88.67 | 27.8 | 77.1 |
| W4A8-FP8 | 77.37 | 88.67 | 26.83 | 78.86 |
注
#### 2.4 Qwen-VL 系列模型
**Qwen3-VL 基准测试**
Qwen3-VL 系列模型在 `MMMU_VAL`、`DocVQA_VAL` 和 `ChartQA_TEST` 数据集上使用 `BF16`、`FP8-Static` 和 `FP8-Dynamic` 量化算法的基准测试结果:
| 模型 | 量化 | MMMU_VAL | DocVQA_VAL | ChartQA_TEST |
|---|
| Qwen3-VL-32B-Instruct | BF16 | 60.11 | 96.08 | 94.64 |
| FP8-Static | 61.22 | 96.00 | 94.64 |
| FP8-Dynamic | 60.78 | 96.19 | 94.72 |
| Qwen3-VL-30B-A3B-Instruct | BF16 | 50.44 | 95.28 | 95.36 |
| FP8-Dynamic | 50.67 | 95.25 | 95.20 |
Qwen2.5VL 基准测试
Qwen2.5VL 系列模型在 `MMMU_VAL`、`DocVQA_VAL` 和 `ChartQA_TEST` 数据集上使用 `BF16`、`FP8-Static`、`FP8-Dynamic`、`INT4-GPTQ`、`INT4-AWQ` 量化算法的基准测试结果:
| 模型 | 量化 | MMMU_VAL | MMLDocVQA_VALU | ChartQA_TEST |
|---|
| Qwen2.5VL-3B | BF16 | 47.11 | 78.57 | 80.32 |
| FP8-Static | 47.33 | 79.34 | 79.68 |
| FP8-Dynamic | 45.99 | 46.93 | 38.29 |
| INT4-GPTQ | 46.56 | 77.20 | 78.96 |
| INT4-AWQ | 45.78 | - | 79.60 |
| Qwen2.5VL-7B | BF16 | 45.44 | 89.71 | 84.64 |
| FP8-Static | 47.00 | 89.83 | 85.92 |
| FP8-Dynamic | 47.22 | 89.80 | 88.64 |
| INT4-GPTQ | 46.67 | 90.45 | - |
| INT4-AWQ | 45.67 | 89.28 | - |
| Qwen2.5VL-32B | BF16 | 57.00 | 90.03 | - |
| FP8-Static | 57.00 | 89.88 | - |
| FP8-Dynamic | 56.44 | 89.88 | - |
| INT4-GPTQ | 55.22 | 89.80 | - |
| INT4-AWQ | 55.22 | 90.30 | - |
| Qwen2.5VL-72B | BF16 | 58.78 | 94.39 | 85.60 |
| FP8-Static | 57.89 | 94.41 | 85.84 |
| FP8-Dynamic | 58.67 | 94.38 | 85.60 |
| INT4-GPTQ | 57.56 | 94.46 | 86.48 |
| INT4-AWQ | 58.78 | 94.19 | 87.28 |
#### 2.5 Qwen-Omni 系列模型
**Qwen3-Omni 文本到文本基准测试**
Qwen3-Omni 系列模型在 BF16、FP8-Static 和 FP8-Dynamic 下针对 aime25、gpqa_diamond 和 mmlu_redux 的基准测试结果如下:
| 模型 | 量化 | aime25 | gpqa_diamond | mmlu_redux |
|---|
| Qwen3-Omni-30B-A3B-Instruct | BF16 | 73.32 | 56.77 | 88.09 |
| FP8-Static | 71.33 | 56.57 | 87.91 |
| FP8-Dynamic | 73.33 | 55.15 | 88.07 |
注
#### 2.6 其他模型
GLM-4.6、Qwen2.5 和 Seed-OSS 等其他模型已在 `CEVAL`、`MMLU` 和 `GSM8K` 等基准测试中,使用包括 `FP8-Static`、`FP8-Dynamic`、`INT4-GPTQ` 和 `INT4-AWQ` 在内的量化策略进行了评估。
基准测试实验详情
| 模型 | 量化 | CEVAL | MMLU | GSM8K |
|---|
| Qwen2.5-1.5B-Instruct | BF16 | 67.01 | 60.05 | 54.28 |
| FP8-Static | 66.27 | 60.23 | - |
| FP8-Dynamic | 66.79 | 60.08 | 51.71 |
| Qwen2.5-7B-Instruct | BF16 | 81.20 | 74.55 | 79.98 |
| FP8-Static | 81.13 | 74.03 | 79.30 |
| FP8-Dynamic | 80.31 | 74.07 | 79.00 |
| INT4-GPTQ | 79.05 | 73.05 | 74.75 |
| INT4-AWQ | 79.35 | 73.22 | 79.38 |
| Qwen2.5-32B-Instruct | BF16 | 87.30 | 83.21 | 81.73 |
| FP8-Static | 87.59 | 83.08 | 81.58 |
| FP8-Dynamic | 87.30 | 83.04 | 81.58 |
| INT4-GPTQ | 86.70 | 82.45 | 82.03 |
| INT4-AWQ | 87.00 | 82.64 | - |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | 53.49 | 53.80 | 75.74 |
| FP8-Static | 53.57 | 54.17 | 76.19 |
| FP8-Dynamic | 52.97 | 54.13 | 74.15 |
| INT4-GPTQ | 51.86 | 52.44 | 75.89 |
| INT4-AWQ | 53.49 | 53.70 | - |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | 77.71 | 74.28 | 85.67 |
| FP8-Static | 77.56 | 74.66 | 86.73 |
| FP8-Dynamic | 76.82 | 74.63 | 87.11 |
| INT4-GPTQ | 74.29 | 72.37 | 84.61 |
| INT4-AWQ | 74.81 | 73.00 | 86.05 |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | 84.18 | 80.89 | 87.41 |
| FP8-Static | 83.43 | 80.90 | 87.57 |
| FP8-Dynamic | 83.73 | 81.10 | 86.43 |
| INT4-GPTQ | 84.10 | 79.80 | 86.73 |
INT4-AWQ82.84 | 80.15 | 87.19 |
### 3. Token 压缩
我们在多个多模态基准测试上评估了 **Qwen2.5-VL-3B-Instruct** 模型的各种视觉 Token 压缩策略。您可以使用以下命令复现这些结果:
```
python tools/run_pruning_eval.py \
--model_path "Qwen/Qwen2.5-VL-3B-Instruct" \
--configs "configs/qwen2_5_vl/pruning/visionzip_r0.9.yaml" \
--tasks "textvqa" \
--output_dir "./results/visionzip_test"
```
详细基准测试结果 (Qwen2.5-VL-3B-Instruct)
| 方法 |
AI2D |
ChartQA |
DocVQA |
MMBCN |
MMB |
MME |
MMStar |
OCRBench |
POPE |
SQA |
VQAText |
平均值 |
| Baseline |
79.11 |
83.56 |
92.48 |
73.28 |
77.32 |
1517 |
56.05 |
80.10 |
87.41 |
80.81 |
78.79 |
100.0% |
| 保留 25% Tokens (75% 压缩率) |
| FastV | 72.70 | 70.04 | 75.98 | 63.40 | 66.92 | 1437 | 47.39 | 36.60 | 86.42 | 79.33 | 73.51 | 86.02% |
| VisionZip | 74.19 | 71.32 | 70.11 | 67.35 | 71.22 | 1452 | 49.37 | 42.50 | 85.51 | 81.36 | 68.12 | 87.34% |
| HiPrune | 73.83 | 72.76 | 72.10 | 67.27 | 72.34 | 1449 | 48.93 | 41 标签:1.25比特量化, 2比特量化, AngelSlim, Apex, DLL 劫持, FP8, Hugging Face, LLM, ModelScope, MoE, Unmanaged PE, Vectored Exception Handling, 人工智能, 低比特量化, 凭据扫描, 大语言模型, 推理加速, 机器学习, 模型优化, 模型压缩, 模型压缩工具包, 深度学习, 用户模式Hook绕过, 知识蒸馏, 神经网络压缩, 离线翻译, 移动端AI, 稀疏化, 端侧大模型, 端侧部署, 系统调用监控, 逆向工具, 量化
|

{kind=link}