首页 安全仓库 shiyu-coder/Kronos shiyu-coder/Kronos GitHub: shiyu-coder/Kronos
Kronos 是一款专为金融市场 K 线序列设计的基础大模型,通过独特的离散化分词与 Transformer 架构,解决高噪声金融数据的量化预测任务。
Stars: 32247 | Forks: 5545
Kronos: A Foundation Model for the Language of Financial Markets
## 📜 简介
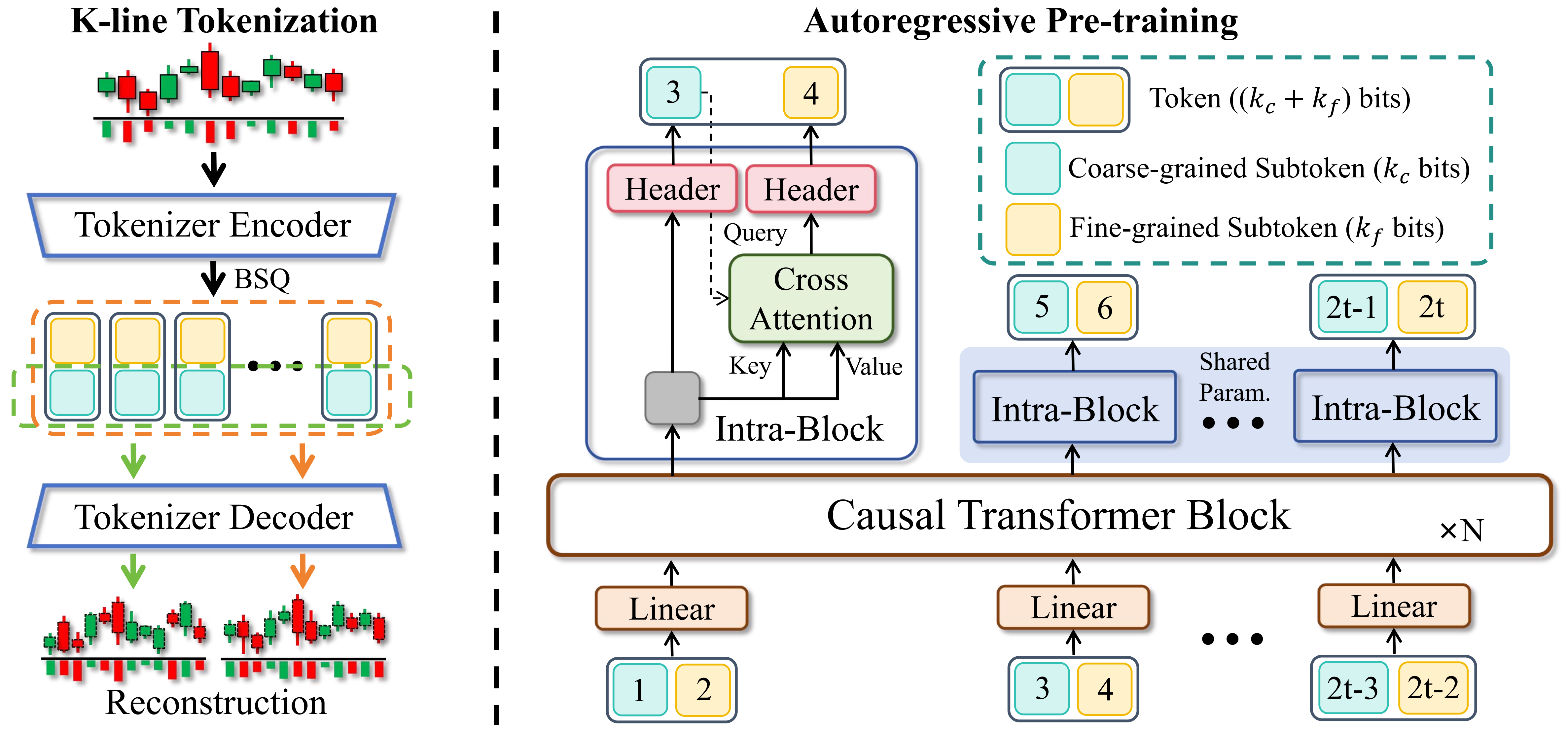
**Kronos** 是一系列仅解码器 的基础模型,专为金融市场的“语言”——K 线序列——而预训练。与通用的 TSFM 不同,Kronos 旨在处理金融数据独特的、高噪声特性。它利用了一种新颖的两阶段框架:
1. 一个专门的分词器首先将连续的多维 K 线数据 (OHLCV) 量化为**分层离散 Token**。
2. 然后,一个大型自回归 Transformer 在这些 Token 上进行预训练,使其能够作为多样化量化任务的统一模型。
## ✨ 在线演示
我们搭建了一个在线演示来可视化 Kronos 的预测结果。该网页展示了对未来 24 小时 **BTC/USDT** 交易对的预测。
**👉 [在此访问在线演示](https://shiyu-coder.github.io/Kronos-demo/)**
## 📦 模型库
我们发布了不同规模的预训练模型系列,以满足不同的计算和应用需求。所有模型均可从 Hugging Face Hub 获取。
| 模型 | Tokenizer | 上下文长度 | 参数量 | 开源 |
|--------------|----------------------------------------------------------------------------------| -------------- | ------ |-------------------------------------------------------------------------|
| Kronos-mini | [Kronos-Tokenizer-2k](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-2k) | 2048 | 4.1M | ✅ [NeoQuasar/Kronos-mini](https://huggingface.co/NeoQuasar/Kronos-mini) |
| Kronos-small | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 24.7M | ✅ [NeoQuasar/Kronos-small](https://huggingface.co/NeoQuasar/Kronos-small) |
| Kronos-base | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 102.3M | ✅ [NeoQuasar/Kronos-base](https://huggingface.co/NeoQuasar/Kronos-base) |
| Kronos-large | [Kronos-Tokenizer-base](https://huggingface.co/NeoQuasar/Kronos-Tokenizer-base) | 512 | 499.2M | ❌ |
## 🚀 快速开始
### 安装
1. 安装 Python 3.10+,然后安装依赖:
```
pip install -r requirements.txt
```
### 📈 进行预测
使用 `KronosPredictor` 类进行预测非常简单。它处理数据预处理、归一化、预测和反归一化,让您只需几行代码即可从原始数据获得预测结果。
**重要提示**:`Kronos-small` 和 `Kronos-base` 的 `max_context` 为 **512**。这是模型可以处理的最大序列长度。为了获得最佳性能,建议输入数据长度(即 `lookback`)不要超过此限制。`KronosPredictor` 将自动处理较长上下文的截断。
以下是进行首次预测的分步指南。
#### 1. 加载 Tokenizer 和模型
首先,从 Hugging Face Hub 加载预训练的 Kronos 模型及其对应的分词器。
```
from model import Kronos, KronosTokenizer, KronosPredictor
# 从 Hugging Face Hub 加载
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")
```
#### 2. 实例化预测器
创建 `KronosPredictor` 的实例,传入模型、分词器和所需的设备。
```
# 初始化 predictor
predictor = KronosPredictor(model, tokenizer, max_context=512)
```
#### 3. 准备输入数据
`predict` 方法需要三个主要输入:
- `df`:包含历史 K 线数据的 pandas DataFrame。它必须包含 `['open', 'high', 'low', 'close']` 列。`volume` 和 `amount` 是可选的。
- `x_timestamp`:与 `df` 中历史数据对应的时间戳 pandas Series。
- `y_timestamp`:您想要预测的未来时间段的时间戳 pandas Series。
```
import pandas as pd
# 加载您的数据
df = pd.read_csv("./data/XSHG_5min_600977.csv")
df['timestamps'] = pd.to_datetime(df['timestamps'])
# 定义上下文窗口和预测长度
lookback = 400
pred_len = 120
# 为 predictor 准备输入
x_df = df.loc[:lookback-1, ['open', 'high', 'low', 'close', 'volume', 'amount']]
x_timestamp = df.loc[:lookback-1, 'timestamps']
y_timestamp = df.loc[lookback:lookback+pred_len-1, 'timestamps']
```
#### 4. 生成预测
调用 `predict` 方法生成预测。您可以使用 `T`、`top_p` 和 `sample_count` 等参数控制采样过程,以进行概率预测。
```
# 生成预测
pred_df = predictor.predict(
df=x_df,
x_timestamp=x_timestamp,
y_timestamp=y_timestamp,
pred_len=pred_len,
T=1.0, # Temperature for sampling
top_p=0.9, # Nucleus sampling probability
sample_count=1 # Number of forecast paths to generate and average
)
print("Forecasted Data Head:")
print(pred_df.head())
```
`predict` 方法返回一个 pandas DataFrame,其中包含 `open`、`high`、`low`、`close`、`volume` 和 `amount` 的预测值,并以您提供的 `y_timestamp` 为索引。
为了高效处理多个时间序列,Kronos 提供了 `predict_batch` 方法,能够同时对多个数据集进行并行预测。当您需要一次预测多个资产或时间段时,这特别有用。
```
# 为批量预测准备多个数据集
df_list = [df1, df2, df3] # List of DataFrames
x_timestamp_list = [x_ts1, x_ts2, x_ts3] # List of historical timestamps
y_timestamp_list = [y_ts1, y_ts2, y_ts3] # List of future timestamps
# 生成批量预测
pred_df_list = predictor.predict_batch(
df_list=df_list,
x_timestamp_list=x_timestamp_list,
y_timestamp_list=y_timestamp_list,
pred_len=pred_len,
T=1.0,
top_p=0.9,
sample_count=1,
verbose=True
)
# pred_df_list 包含与输入顺序相同的预测结果
for i, pred_df in enumerate(pred_df_list):
print(f"Predictions for series {i}:")
print(pred_df.head())
```
**批量预测的重要要求:**
- 所有序列必须具有相同的历史长度(回溯窗口)
- 所有序列必须具有相同的预测长度 (`pred_len`)
- 每个 DataFrame 必须包含所需列:`['open', 'high', 'low', 'close']`
- `volume` 和 `amount` 列是可选的,如果缺失将填充为零
`predict_batch` 方法利用 GPU 并行性进行高效处理,并自动独立处理每个序列的归一化和反归一化。
#### 5. 示例与可视化
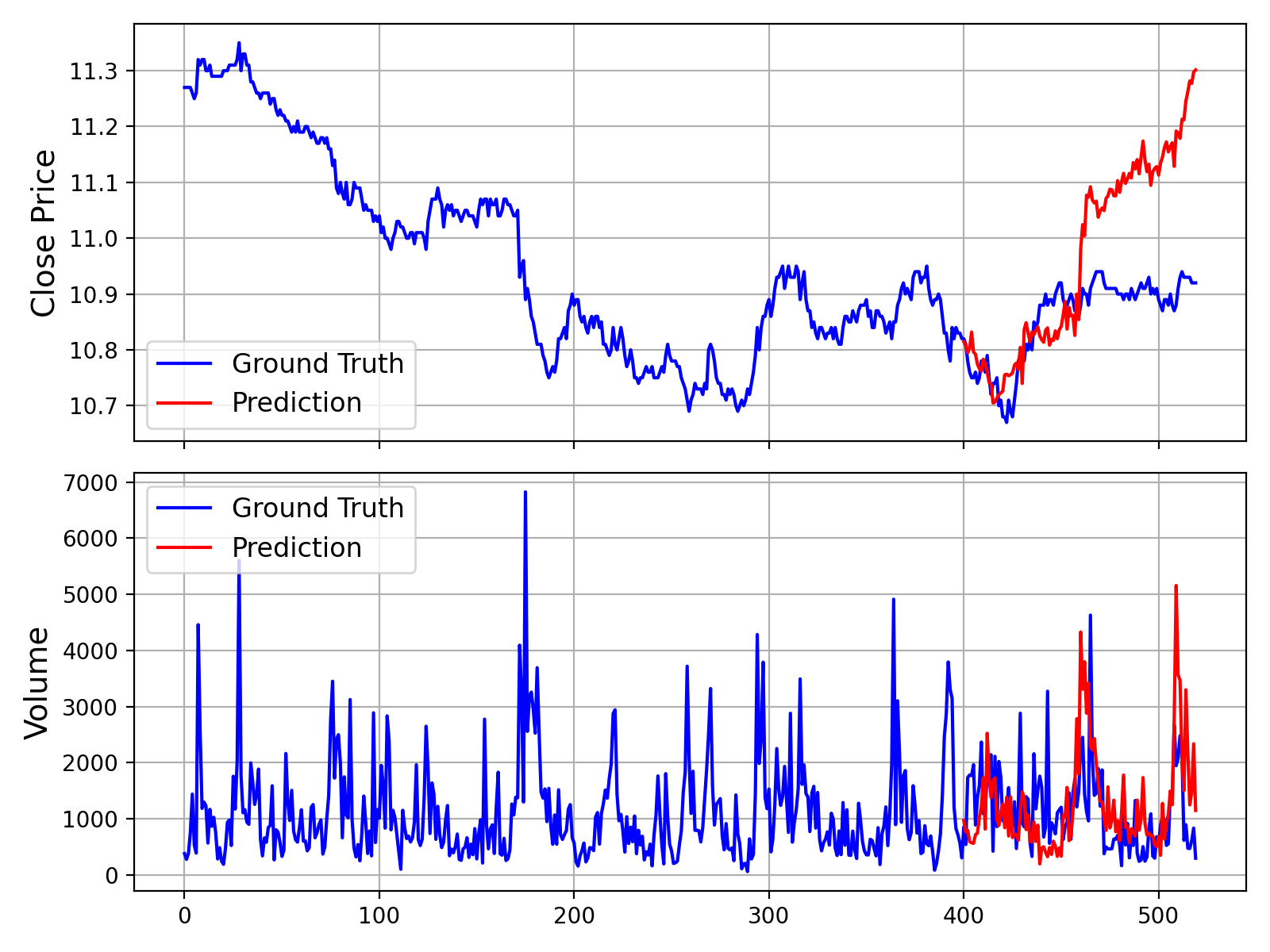
有关包含数据加载、预测和绘图的完整可运行脚本,请参阅 [`examples/prediction_example.py`](examples/prediction_example.py)。
运行此脚本将生成一个图表,将真实数据与模型的预测进行比较,类似于下图所示:
此外,我们提供了一个在无 Volume 和 Amount 数据情况下进行预测的脚本,该脚本位于 [`examples/prediction_wo_vol_example.py`](examples/prediction_wo_vol_example.py)。
## 🔧 在您自己的数据上进行微调(A 股市场示例)
我们提供了完整的流水线,用于在您自己的数据集上微调 Kronos。作为一个示例,我们演示如何使用 [Qlib](https://github.com/microsoft/qlib) 准备来自中国 A 股市场的数据并进行简单的回测。
微调过程分为四个主要步骤:
1. **配置**:设置路径和超参数。
2. **数据准备**:使用 Qlib 处理并拆分您的数据。
3. **模型微调**:微调 Tokenizer 和 Predictor 模型。
4. **回测**:评估微调后模型的性能。
### 前置条件
1. 首先,确保您已安装 `requirements.txt` 中的所有依赖项。
2. 此流水线依赖于 `qlib`。请安装它:
pip install pyqlib
3. 您需要准备您的 Qlib 数据。遵循 [官方 Qlib 指南](https://github.com/microsoft/qlib) 下载并在本地设置您的数据。示例脚本假定您使用的是日线频率数据。
### 第 1 步:配置您的实验
数据、训练和模型路径的所有设置都集中在 `finetune/config.py` 中。在运行任何脚本之前,请根据您的环境**修改以下路径**:
* `qlib_data_path`:您本地 Qlib 数据目录的路径。
* `dataset_path`:保存处理后的训练/验证/测试 pickle 文件的目录。
* `save_path`:保存模型检查点的基础目录。
* `backtest_result_path`:保存回测结果的目录。
* `pretrained_tokenizer_path` 和 `pretrained_predictor_path`:您想要从其开始的预训练模型的路径(可以是本地路径或 Hugging Face 模型名称)。
您还可以调整其他参数,如 `instrument`、`train_time_range`、`epochs` 和 `batch_size` 以适应您的特定任务。如果您不使用 [Comet.ml](https://www.comet.com/),请设置 `use_comet = False`。
### 第 2 步:准备数据集
运行数据预处理脚本。此脚本将从您的 Qlib 目录加载原始市场数据,对其进行处理,将其拆分为训练集、验证集和测试集,并将它们保存为 pickle 文件。
```
python finetune/qlib_data_preprocess.py
```
运行后,您将在配置中 `dataset_path` 指定的目录中找到 `train_data.pkl`、`val_data.pkl` 和 `test_data.pkl`。
### 第 3 步:运行微调
微调过程包含两个阶段:微调分词器,然后微调预测器。这两个训练脚本均设计为使用 `torchrun` 进行多 GPU 训练。
#### 3.1 微调 Tokenizer
此步骤将分词器调整到您特定领域的数据分布。
```
# 将 NUM_GPUS 替换为您想要使用的 GPU 数量(例如 2)
torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_tokenizer.py
```
最佳的分词器检查点将保存到 `config.py` 中配置的路径(派生自 `save_path` 和 `tokenizer_save_folder_name`)。
#### 3.2 微调预测器
此步骤针对预测任务微调主要的 Kronos 模型。
```
# 将 NUM_GPUS 替换为您想要使用的 GPU 数量(例如 2)
torchrun --standalone --nproc_per_node=NUM_GPUS finetune/train_predictor.py
```
最佳预测器检查点将保存到 `config.py` 中配置的路径。
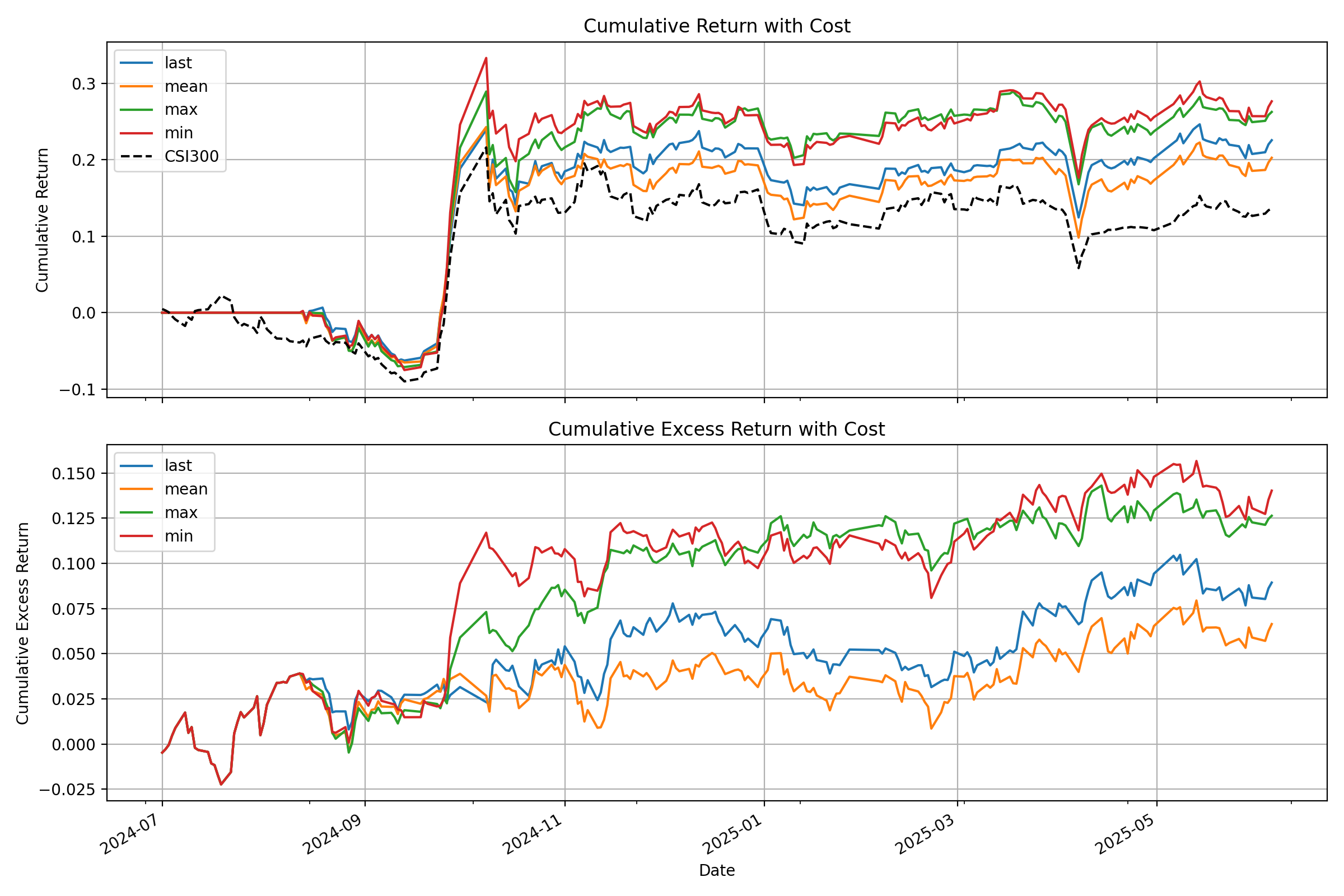
### 第 4 步:通过回测进行评估
最后,运行回测脚本来评估您的微调模型。该脚本加载模型,在测试集上执行推理,生成预测信号(例如预测价格变化),并运行一个简单的 top-K 策略回测。
```
# 指定用于推理的 GPU
python finetune/qlib_test.py --device cuda:0
```
该脚本将在您的控制台中输出详细的性能分析,并生成一个图表,显示您的策略与基准的累积收益曲线,类似于下图:
### 💡 从演示到生产环境:重要考虑因素
* **原始信号与纯 Alpha**:本演示中模型生成的信号是原始预测。在现实世界的量化工作流中,这些信号通常会输入到投资组合优化模型中。该模型将应用约束以中和对常见风险因子的敞口(例如市场 beta、规模和价值等风格因子),从而分离出 **"pure alpha"** 并提高策略的稳健性。
* **数据处理**:提供的 `QlibDataset` 是一个示例。对于不同的数据源或格式,您需要调整数据加载和预处理逻辑。
* **策略和回测复杂性**:此处使用的简单 top-K 策略是一个基本的起点。生产级策略通常包含更复杂的投资组合构建逻辑、动态仓位调整和风险管理(例如止损/止盈规则)。此外,高保真回测应精确模拟交易成本、滑点和市场影响,以提供对现实世界性能的更准确估计。
## 📖 引用
如果您在研究中使用了 Kronos,我们将不胜感激您引用我们的[论文](https://arxiv.org/abs/2508.02739):
```
@misc{shi2025kronos,
title={Kronos: A Foundation Model for the Language of Financial Markets},
author={Yu Shi and Zongliang Fu and Shuo Chen and Bohan Zhao and Wei Xu and Changshui Zhang and Jian Li},
year={2025},
eprint={2508.02739},
archivePrefix={arXiv},
primaryClass={q-fin.ST},
url={https://arxiv.org/abs/2508.02739},
}
```
## 📜 许可证
本项目基于 [MIT License](./LICENSE) 开源。标签: AAAI, Apex, DLL 劫持, DNS解析, Hugging Face, IaC 扫描, LLM, NLP, Unmanaged PE, 人工智能, 凭据扫描, 基础模型, 大语言模型, 开源项目, 时间序列预测, 机器学习, 深度学习, 用户模式Hook绕过, 逆向工具, 量化投资, 金融分析, 金融市场, 金融科技, 金融语言