XdlSecZJU/CAMA
GitHub: XdlSecZJU/CAMA
CAMA 是一个系统评估代码大语言模型在 Android 恶意软件分析中有效性的基准测试框架,解决了缺乏标准化指标和数据集来衡量 LLM 恶意代码理解能力的问题。
Stars: 6 | Forks: 1
# CAMA 基准测试框架
## 关于 Android 恶意软件分析中代码大语言模型的基准测试
本文已被第 34 届 ACM SIGSOFT ISSTA Companion(LLMSC Workshop 2025)收录。
论文:https://dl.acm.org/doi/10.1145/3713081.3731745
数据集:https://zenodo.org/records/15155917
## 概述
大型语言模型(LLM)在各种代码智能任务中展现出了强大的能力。然而,它们在 Android 恶意软件分析方面的有效性仍有待深入探索。反编译的 Android 恶意软件代码给分析带来了独特的挑战,因为其恶意逻辑通常深藏于大量函数之中,且经常缺乏有意义的函数名。
本文提出了 CAMA,这是一个旨在系统性地评估 **C**ode LLM 在 **A**ndroid **M**alware **A**nalysis 中有效性的基准测试框架。CAMA 规范了结构化的模型输出,以支持关键的恶意软件分析任务,包括恶意函数识别和恶意软件用途总结。在此基础上,它集成了三个特定领域的评估指标(一致性、保真度和语义相关性),从而能够进行严格的稳定性与有效性评估及跨模型比较。
我们构建了一个包含近年来收集的 13 个家族的 118 个 Android 恶意软件样本的基准数据集,涵盖了超过 750 万个不同的函数,并使用 CAMA 评估了四种流行的开源 Code LLM。我们的实验深入揭示了 Code LLM 如何解释反编译代码,并量化了其对函数重命名的敏感度,突出了它们在恶意软件分析中的潜力以及当前的局限性。
### 流程
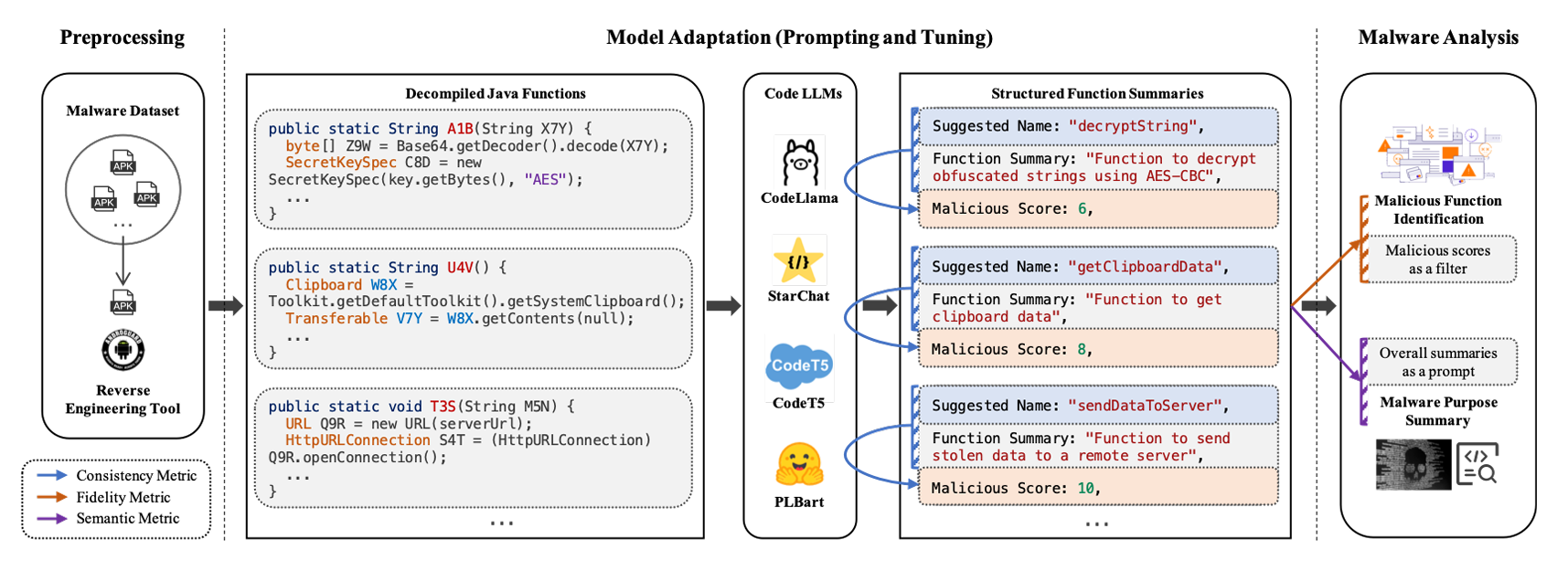
### 结果
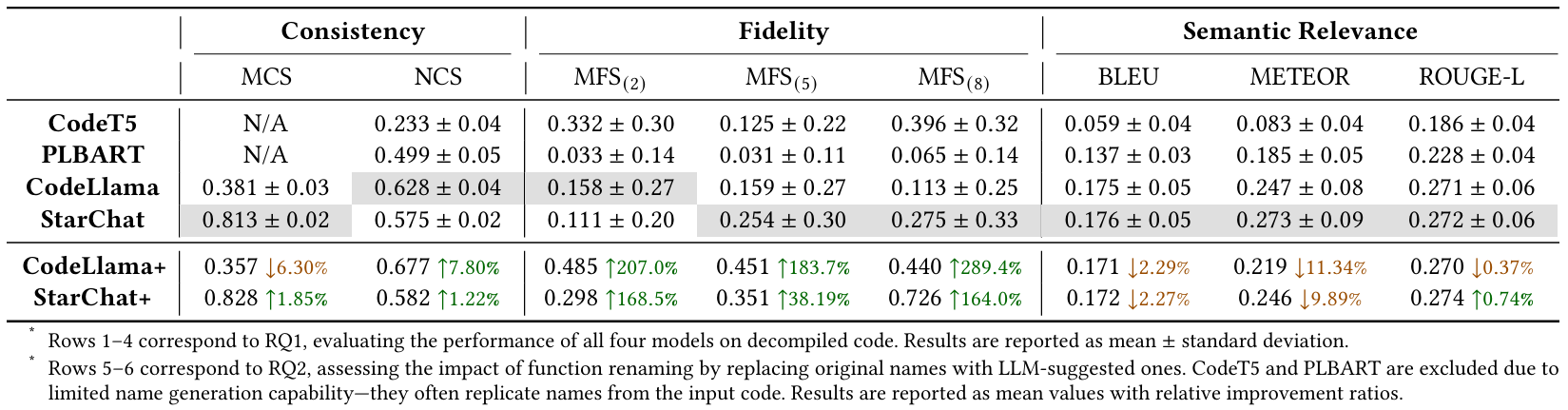
## 许可证
本项目采用 Apache 2.0 许可证授权 - 详情请参阅 [LICENSE](LICENSE) 文件。
## 引用
如果您发现此项研究对您的出版物有所帮助,请引用:
```
@inproceedings{he2025benchmarking,
title={On benchmarking code llms for android malware analysis},
author={He, Yiling and She, Hongyu and Qian, Xingzhi and Zheng, Xinran and Chen, Zhuo and Qin, Zhan and Cavallaro, Lorenzo},
booktitle={Proceedings of the 34th ACM SIGSOFT International Symposium on Software Testing and Analysis},
pages={153--160},
year={2025}
}
```
标签:C2, DLL 劫持, 代码分析, 凭证管理, 反取证, 大语言模型, 学术研究, 安全评估, 安卓恶意软件, 逆向工具