intel/llm-scaler
GitHub: intel/llm-scaler
面向 Intel Arc Pro B60 GPU 的一站式 GenAI 部署方案,整合 vLLM、ComfyUI 等主流框架,以 Docker 镜像形式提供文本、图像、视频、音频等多模态生成式 AI 服务的开箱即用体验。
Stars: 430 | Forks: 57
# LLM Scaler
LLM Scaler 是一个运行在 [Intel® Arc™ Pro B60 GPUs](https://www.intel.com/content/www/us/en/products/docs/discrete-gpus/arc/workstations/b-series/overview.html) 上的 GenAI 解决方案,可用于文本生成、图像生成、视频生成等。LLM Scaler 利用 vLLM、ComfyUI、SGLang Diffusion、Xinference 等标准框架,并确保最先进的 GenAI 模型在 Arc Pro B60 GPU 上运行时具有最佳性能。
## 最新更新
- 🔥 [2026.03] 我们发布了 `intel/llm-scaler-vllm:0.14.0-b8.1`,以支持 Qwen3.5-27B、Qwen3.5-35B-A3B 和 Qwen3.5-122B-A10B(FP8/INT4 在线量化,GPTQ)
- 🔥 [2026.03] 我们发布了 `intel/llm-scaler-omni:0.1.0-b6` 用于 ComfyUI,支持 CacheDiT 和 torch.compile()、ComfyUI-GGUF 以及更多模型工作流,并支持 SGLang Diffusion 的 FP8。
- 🔥 [2026.03] 我们发布了 `intel/llm-scaler-vllm:0.14.0-b8`,以支持 vLLM 0.14.0 和 PyTorch 2.10,以及对多种新模型的支持和性能改进。
- [2026.01] 我们发布了 `intel/llm-scaler-vllm:1.3`(或 `intel/llm-scaler-vllm:0.11.1-b7`),以支持 vLLM 0.11.1 和 PyTorch 2.9,以及对多种新模型的支持和性能改进。
- [2026.01] 我们发布了 `intel/llm-scaler-omni:0.1.0-b5`,以支持 Python 3.12 和 PyTorch 2.9,包含多种 ComfyUI 工作流和更多的 SGLang Diffusion 支持。
- [2025.12] 我们发布了 `intel/llm-scaler-vllm:1.2`,与 `intel/llm-scaler-vllm:0.10.2-b6` 镜像相同。
- [2025.12] 我们发布了 `intel/llm-scaler-omni:0.1.0-b4`,以支持多 XPU 的 Z-Image-Turbo、Hunyuan-Video-1.5 T2V/I2V ComfyUI 工作流,并实验性地支持 SGLang Diffusion。
- [2025.11] 我们发布了 `intel/llm-scaler-vllm:0.10.2-b6`,以支持 Qwen3-VL (Dense/MoE)、Qwen3-Omni、Qwen3-30B-A3B (MoE Int4)、MinerU 2.5、ERNIE-4.5-vl 等模型。
- [2025.11] 我们发布了 `intel/llm-scaler-vllm:0.10.2-b5` 以支持 gpt-oss 模型,并发布了 `intel/llm-scaler-omni:0.1.0-b3` 以支持更多的 ComfyUI 工作流和 Windows 安装。
- [2025.10] 我们发布了 `intel/llm-scaler-omni:0.1.0-b2`,以支持更多使用 ComfyUI 工作流和 Xinference 的模型。
- [2025.09] 我们发布了 `intel/llm-scaler-vllm:0.10.0-b3` 以支持更多模型(MinerU、MiniCPM-v-4.5 等),并发布了 `intel/llm-scaler-omni:0.1.0-b1`,首次实现在 Arc Pro B60 GPU 上使用 ComfyUI 和 Xinference 的全能 GenAI 模型。
- [2025.08] 我们发布了 `intel/llm-scaler-vllm:1.0`。
## LLM Scaler vLLM
`llm-scaler-vllm` 支持使用 vLLM 运行文本生成模型,主要特性包括:
- ***CCL*** 支持 (P2P 或 USM)
- ***INT4*** 和 ***FP8*** 在线量化服务
- ***Embedding*** 和 ***Reranker*** 模型支持
- ***Multi-Modal*** 模型支持
- ***Omni*** 模型支持
- ***Tensor Parallel***、***Pipeline Parallel*** 和 ***Data Parallel***
- 查找最大 Context Length
- Multi-Modal WebUI
- BPE-Qwen tokenizer
请按照 [入门指南](vllm/README.md/#1-getting-started-and-usage) 中的说明使用 `llm-scaler-vllm`。
### 支持的模型
| 类别 | 模型名称 | FP16 | 动态在线 FP8 | 动态在线 Int4 | MXFP4 | 备注 |
|----------------------|--------------------------------------------|------|--------------------|----------------------|-------|---------------------------|
| Language Model | openai/gpt-oss-20b | | | | ✅ | |
| Language Model | openai/gpt-oss-120b | | | | ✅ | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Llama-8B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-Distill-Llama-70B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-R1-0528-Qwen3-8B | ✅ | ✅ | ✅ | | |
| Language Model | deepseek-ai/DeepSeek-V2-Lite | ✅ | ✅ | | | export VLLM_MLA_DISABLE=1 |
| Language Model | deepseek-ai/deepseek-coder-33b-instruct | ✅ | ✅ | ✅ | | |
| Language Model | Qwen/Qwen3-8B | ✅ | ✅ | ✅ | | |
| Language Model | Qwen/Qwen3-14B | ✅ | ✅ | ✅ | | |
| Language Model | Qwen/Qwen3-32B | ✅ | ✅ | ✅ | | |
| Language Model | Qwen/Qwen3.5-27B | ✅ | ✅ | ✅ | | |
| Language MOE Model | Qwen/Qwen3-30B-A3B | ✅ | ✅ | ✅ | | |
| Language MOE Model | Qwen/Qwen3-235B-A22B | | ✅ | | | |
| Language MOE Model | Qwen/Qwen3-Coder-30B-A3B-Instruct | ✅ | ✅ | ✅ | | |
| Language MOE Model | Qwen/Qwen3-Coder-Next | ✅ | ✅ | ✅ | | |
| Language MOE Model | Qwen/Qwen3.5-35B-A3B | ✅ | ✅ | ✅ | | |
| Language MOE Model | Qwen/Qwen3.5-122B-A10B | | ✅ | ✅ | | |
| Language Model | Qwen/QwQ-32B | ✅ | ✅ | ✅ | | |
| Language Model | mistralai/Ministral-8B-Instruct-2410 | ✅ | ✅ | ✅ | | |
| Language Model | mistralai/Mixtral-8x7B-Instruct-v0.1 | ✅ | ✅ | ✅ | | |
| Language Model | meta-llama/Llama-3.1-8B | ✅ | ✅ | ✅ | | |
| Language Model | meta-llama/Llama-3.1-70B | ✅ | ✅ | ✅ | | |
| Language Model | baichuan-inc/Baichuan2-7B-Chat | ✅ | ✅ | ✅ | | with chat_template |
| Language Model | baichuan-inc/Baichuan2-13B-Chat | ✅ | ✅ | ✅ | | with chat_template |
| Language Model | THUDM/CodeGeex4-All-9B | ✅ | ✅ | ✅ | | with chat_template |
| Language Model | zai-org/GLM-4-9B-0414 | | ✅ | | | use bfloat16 |
| Language Model | zai-org/GLM-4-32B-0414 | | ✅ | | | use bfloat16 |
| Language MOE Model | zai-org/GLM-4.5-Air | ✅ | ✅ | | | |
| Language MOE Model | zai-org/GLM-4.7-Flash | ✅ | ✅ | | | |
| Language Model | ByteDance-Seed/Seed-OSS-36B-Instruct | ✅ | ✅ | ✅ | | |
| Language Model | miromind-ai/MiroThinker-v1.5-30B | ✅ | ✅ | ✅ | | |
| Language Model | tencent/Hunyuan-0.5B-Instruct | ✅ | ✅ | ✅ | | 遵循[此处](./vllm/README.md#31-how-to-use-hunyuan-7b-instruct)的指南 |
| Language Model | tencent/Hunyuan-7B-Instruct | ✅ | ✅ | ✅ | | 遵循[此处](./vllm/README.md#31-how-to-use-hunyuan-7b-instruct)的指南 |
| Multimodal Model | Qwen/Qwen2-VL-7B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal Model | Qwen/Qwen2.5-VL-7B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal Model | Qwen/Qwen2.5-VL-32B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal Model | Qwen/Qwen2.5-VL-72B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal Model | Qwen/Qwen3-VL-4B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal Model | Qwen/Qwen3-VL-8B-Instruct | ✅ | ✅ | ✅ | | |
| Multimodal MOE Model | Qwen/Qwen3-VL-30B-A3B-Instruct | ✅ | ✅ | ✅ | | | Multimodal Model | openbmb/MiniCPM-V-2_6 | ✅ | ✅ | ✅ | | |
| Multimodal Model | openbmb/MiniCPM-V-4 | ✅ | ✅ | ✅ | | |
| Multimodal Model | openbmb/MiniCPM-V-4_5 | ✅ | ✅ | ✅ | | |
| Multimodal Model | OpenGVLab/InternVL2-8B | ✅ | ✅ | ✅ | | |
| Multimodal Model | OpenGVLab/InternVL3-8B | ✅ | ✅ | ✅ | | |
| Multimodal Model | OpenGVLab/InternVL3_5-8B | ✅ | ✅ | ✅ | | |
| Multimodal MOE Model | OpenGVLab/InternVL3_5-30B-A3B | ✅ | ✅ | ✅ | | |
| Multimodal Model | rednote-hilab/dots.ocr | ✅ | ✅ | ✅ | | |
| Multimodal Model | ByteDance-Seed/UI-TARS-7B-DPO | ✅ | ✅ | ✅ | | |
| Multimodal Model | google/gemma-3-12b-it | | ✅ | | | use bfloat16 |
| Multimodal Model | google/gemma-3-27b-it | | ✅ | | | use bfloat16 |
| Multimodal Model | THUDM/GLM-4v-9B | ✅ | ✅ | ✅ | | with --hf-overrides and chat_template |
| Multimodal Model | zai-org/GLM-4.1V-9B-Base | ✅ | ✅ | ✅ | | |
| Multimodal Model | zai-org/GLM-4.1V-9B-Thinking | ✅ | ✅ | ✅ | | |
| Multimodal Model | zai-org/Glyph | ✅ | ✅ | ✅ | | |
| Multimodal Model | opendatalab/MinerU2.5-2509-1.2B | ✅ | ✅ | ✅ | | |
| Multimodal Model | baidu/ERNIE-4.5-VL-28B-A3B-Thinking | ✅ | ✅ | ✅ | | |
| Multimodal Model | zai-org/GLM-4.6V-Flash | ✅ | ✅ | ✅ | | 需先执行 pip install transformers==5.0.0rc0 |
| Multimodal Model | PaddlePaddle/PaddleOCR-VL | ✅ | ✅ | ✅ | | 遵循[此处](./vllm/README.md#32-how-to-use-paddleocr)的指南 |
| Multimodal Model | deepseek-ai/DeepSeek-OCR | ✅ | ✅ | ✅ | | |
| Multimodal Model | deepseek-ai/DeepSeek-OCR-2 | ✅ | ✅ | ✅ | | 使用 `--quantization fp8` 时可能存在精度问题 |
| Multimodal Model | moonshotai/Kimi-VL-A3B-Thinking-2506 | ✅ | ✅ | ✅ | | |
| omni | Qwen/Qwen2.5-Omni-7B | ✅ | ✅ | ✅ | | |
| omni | Qwen/Qwen3-Omni-30B-A3B-Instruct | ✅ | ✅ | ✅ | | |
| audio | openai/whisper-medium | ✅ | ✅ | ✅ | | |
| audio | openai/whisper-large-v3 | ✅ | ✅ | ✅ | | |
| Embedding Model | Qwen/Qwen3-Embedding-8B | ✅ | ✅ | ✅ | | |
| VL Embedding Model | Qwen3-VL-Embedding-2B/8B | ✅ | ✅ | ✅ | | 遵循[此处](https://github.com/vllm-project/vllm/blob/2f4226fe5280b60c47b4f6f01d9b18ac9cda2038/examples/pooling/embed/vision_embedding_online.py)的指南 |
| Embedding Model | BAAI/bge-m3 | ✅ | ✅ | ✅ | | |
| Embedding Model | BAAI/bge-large-en-v1.5 | ✅ | ✅ | ✅ | | |
| Reranker Model | Qwen/Qwen3-Reranker-8B | ✅ | ✅ | ✅ | | |
| VL Reranker Model | Qwen3-VL-Reranker-2B/8B | ✅ | ✅ | ✅ | | 遵循[此处](https://github.com/vllm-project/vllm/blob/2f4226fe5280b60c47b4f6f01d9b18ac9cda2038/examples/pooling/score/vision_rerank_api_online.py)的指南 |
| Reranker Model | BAAI/bge-reranker-large | ✅ | ✅ | ✅ | | |
| Reranker Model | BAAI/bge-reranker-v2-m3 | ✅ | ✅ | ✅ | | |
## LLM Scaler Omni (实验性)
`llm-scaler-omni` 支持运行图像/语音/视频生成等,主要特性包括 `Omni Studio` 模式(使用 ComfyUI)和 `Omni Serving` 模式(通过 SGLang Diffusion 或 Xinference)。
请按照 [入门指南](omni/README.md/#getting-started-with-omni-docker-image) 中的说明使用 `llm-scaler-omni`。
### Omni 演示
| Qwen-Image | Multi B60 Wan2.2-T2V-14B |
|------------|--------------------------|
| 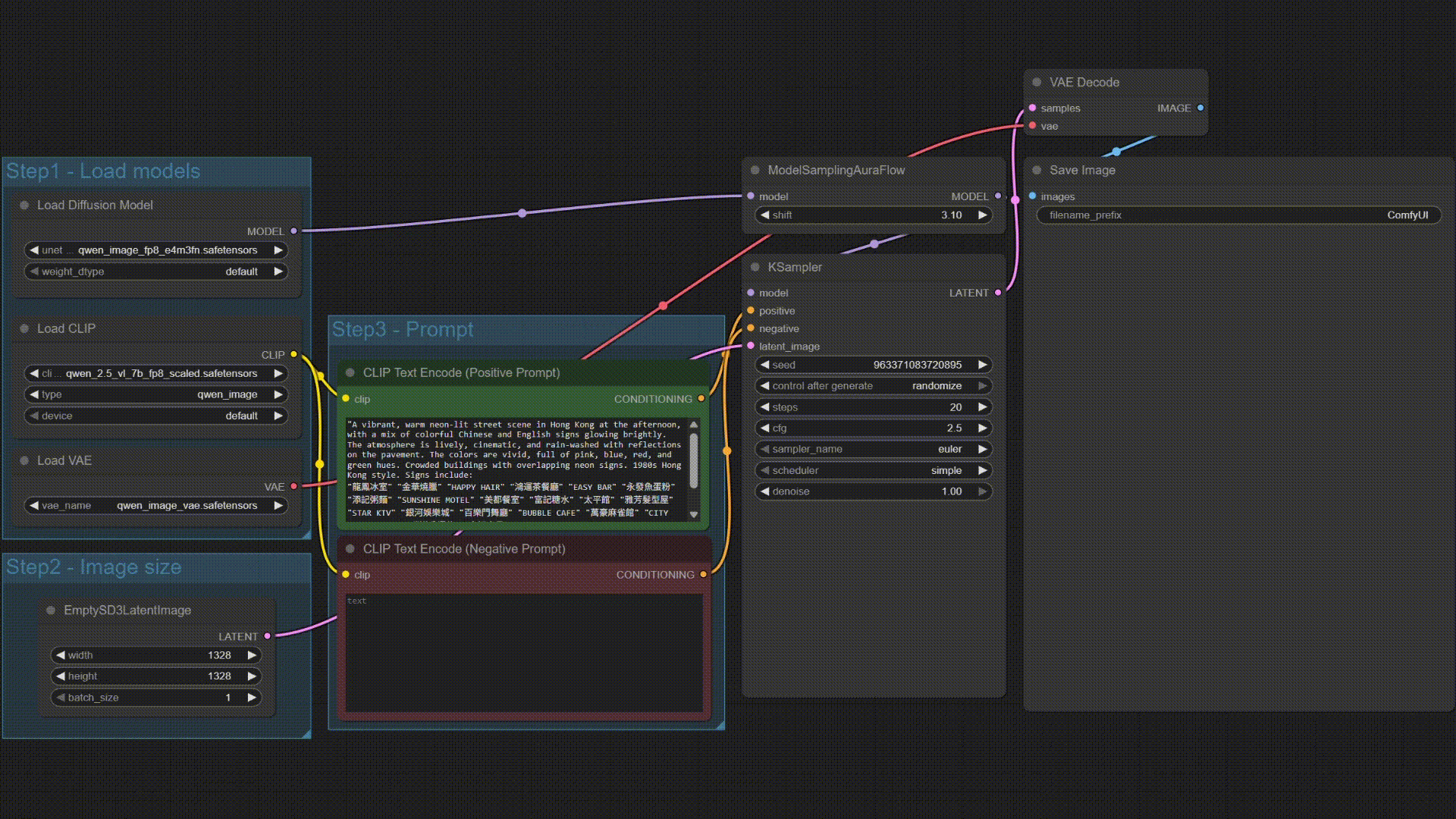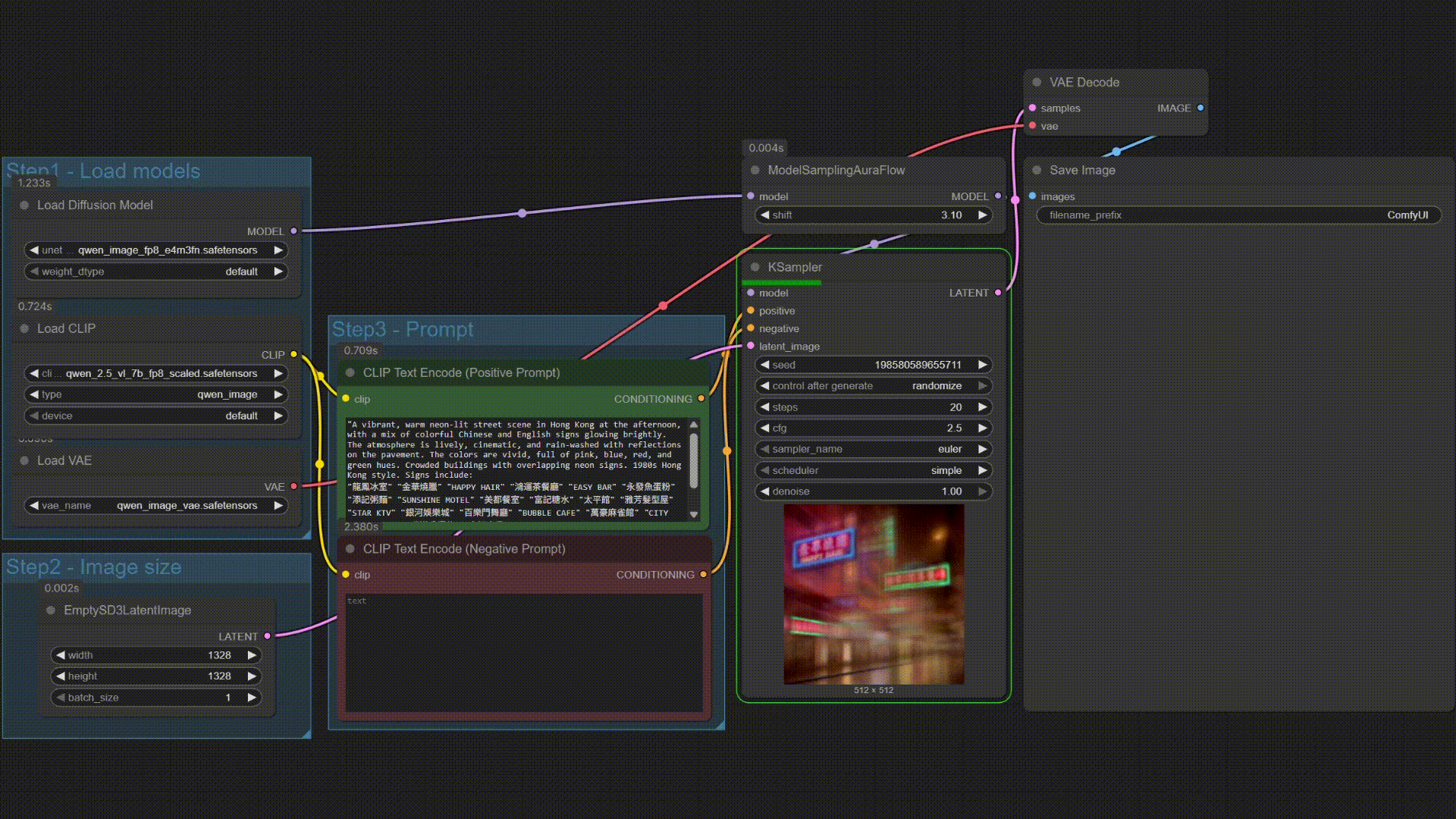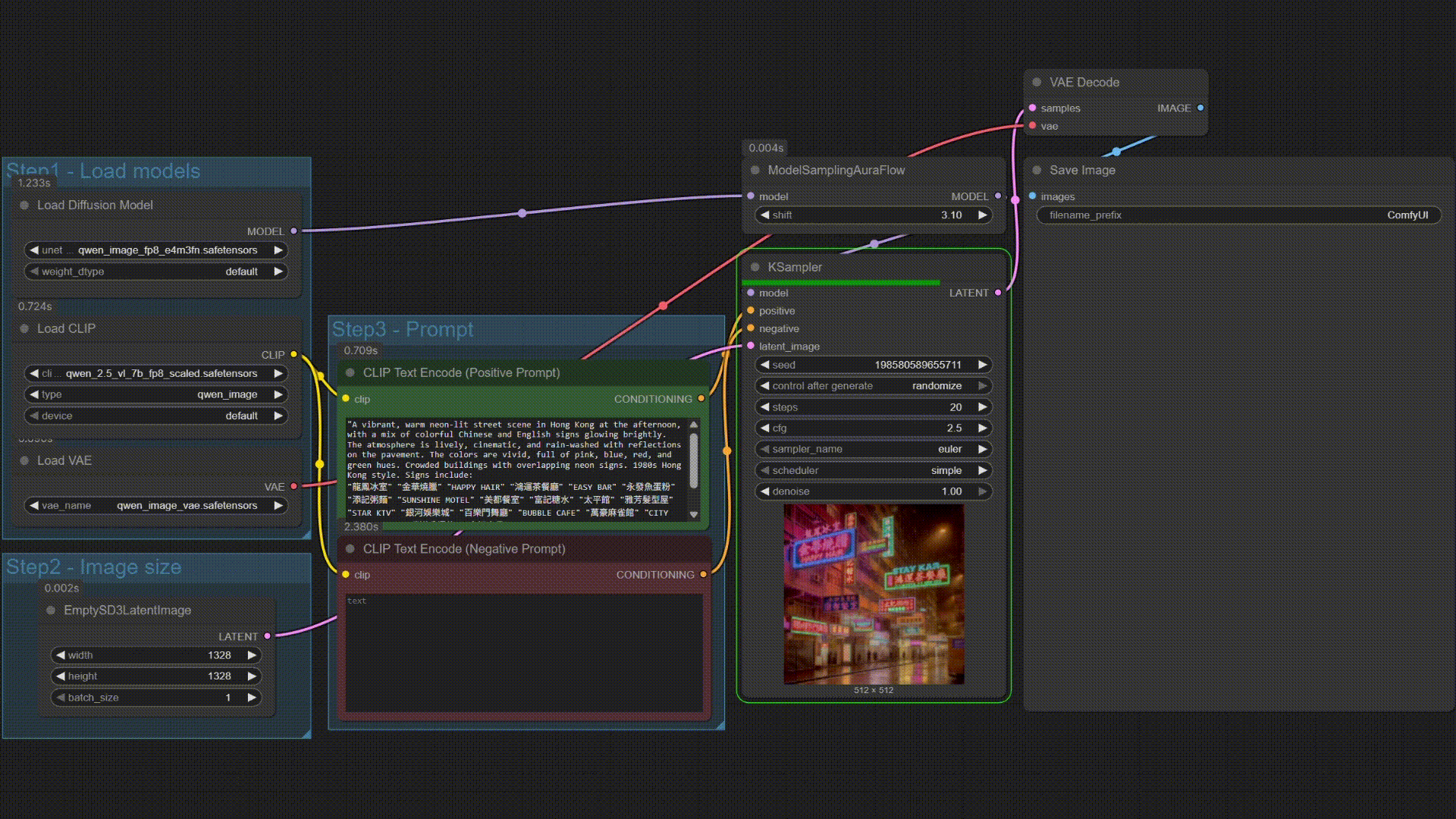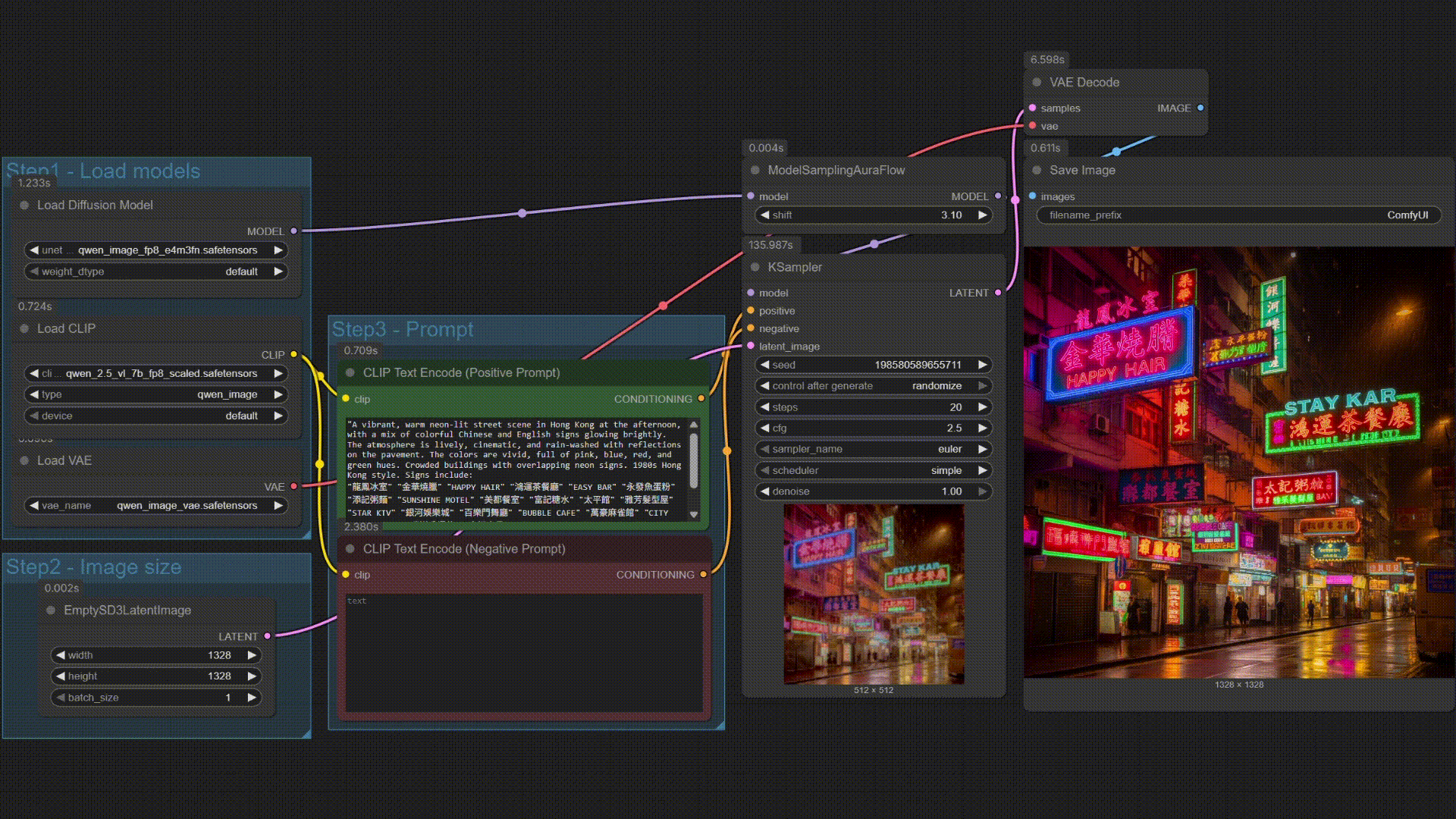 | 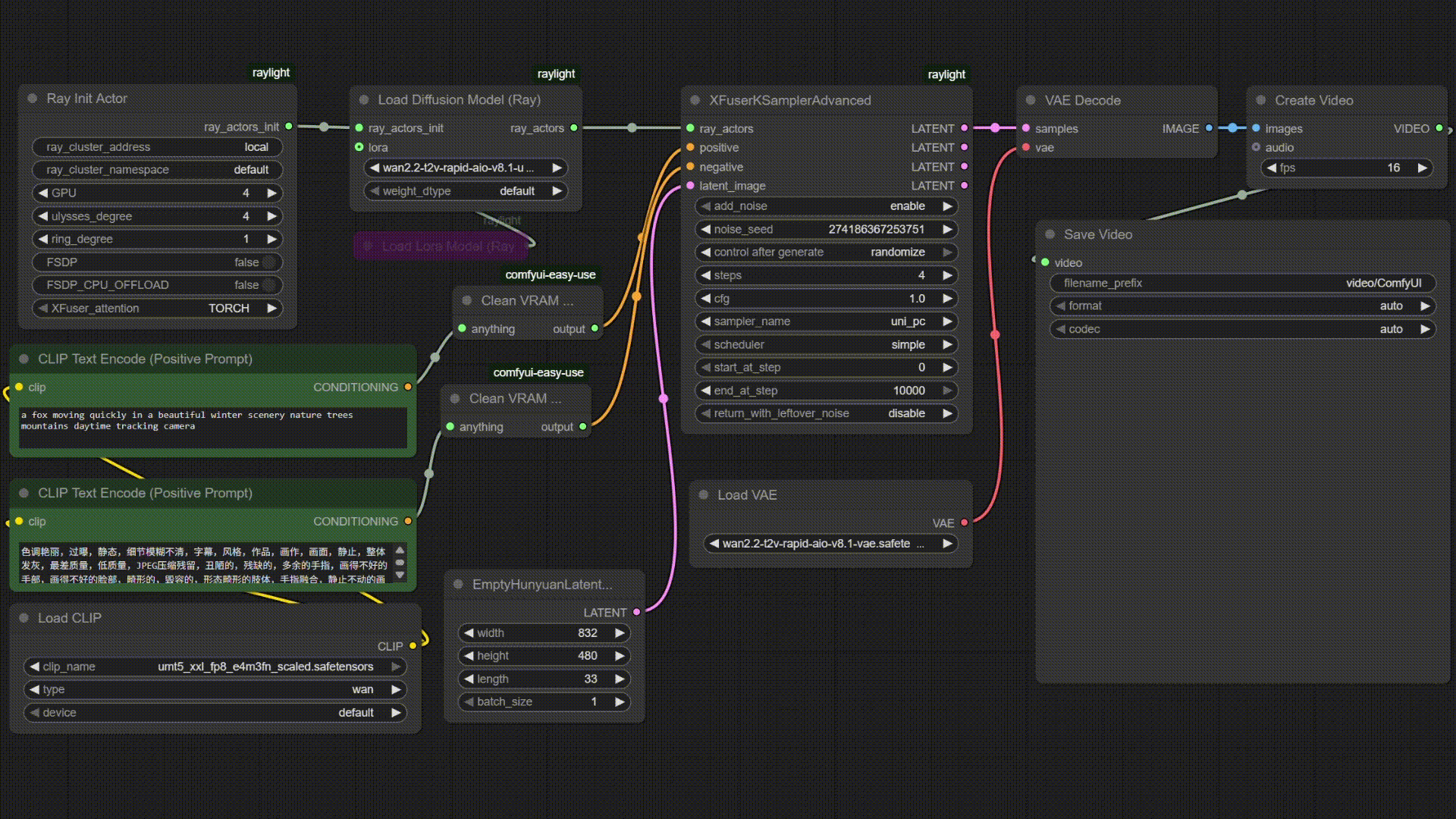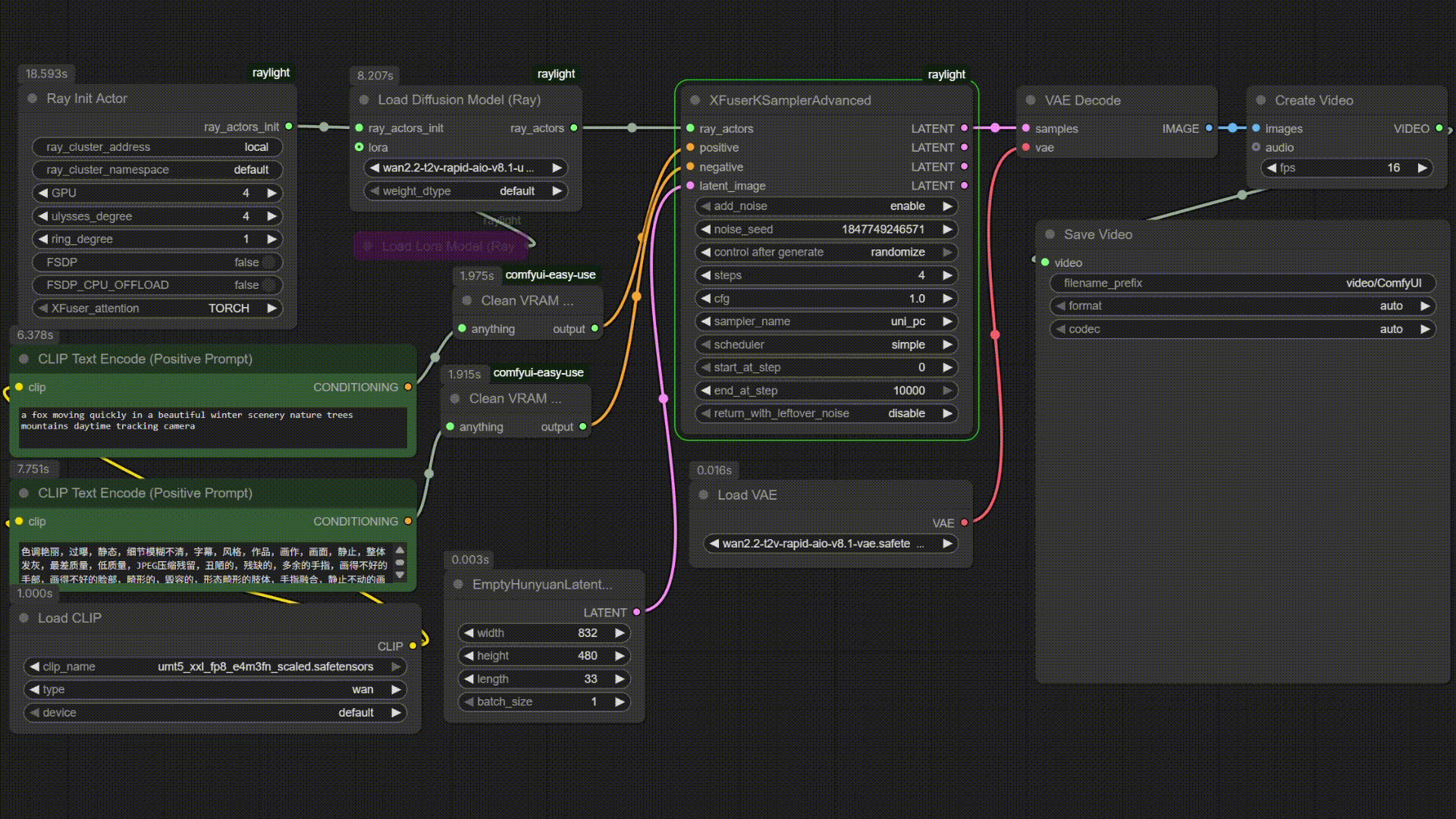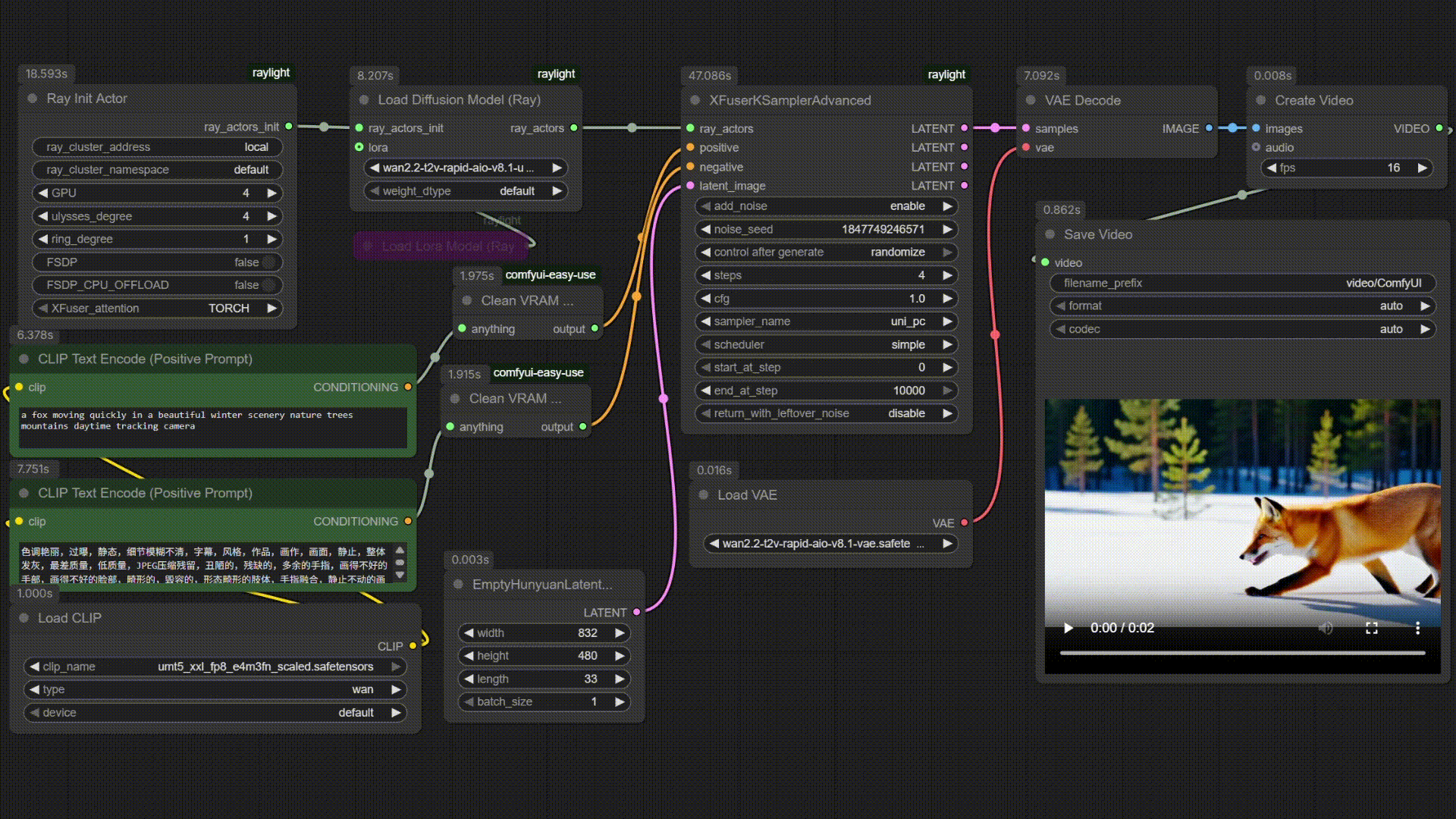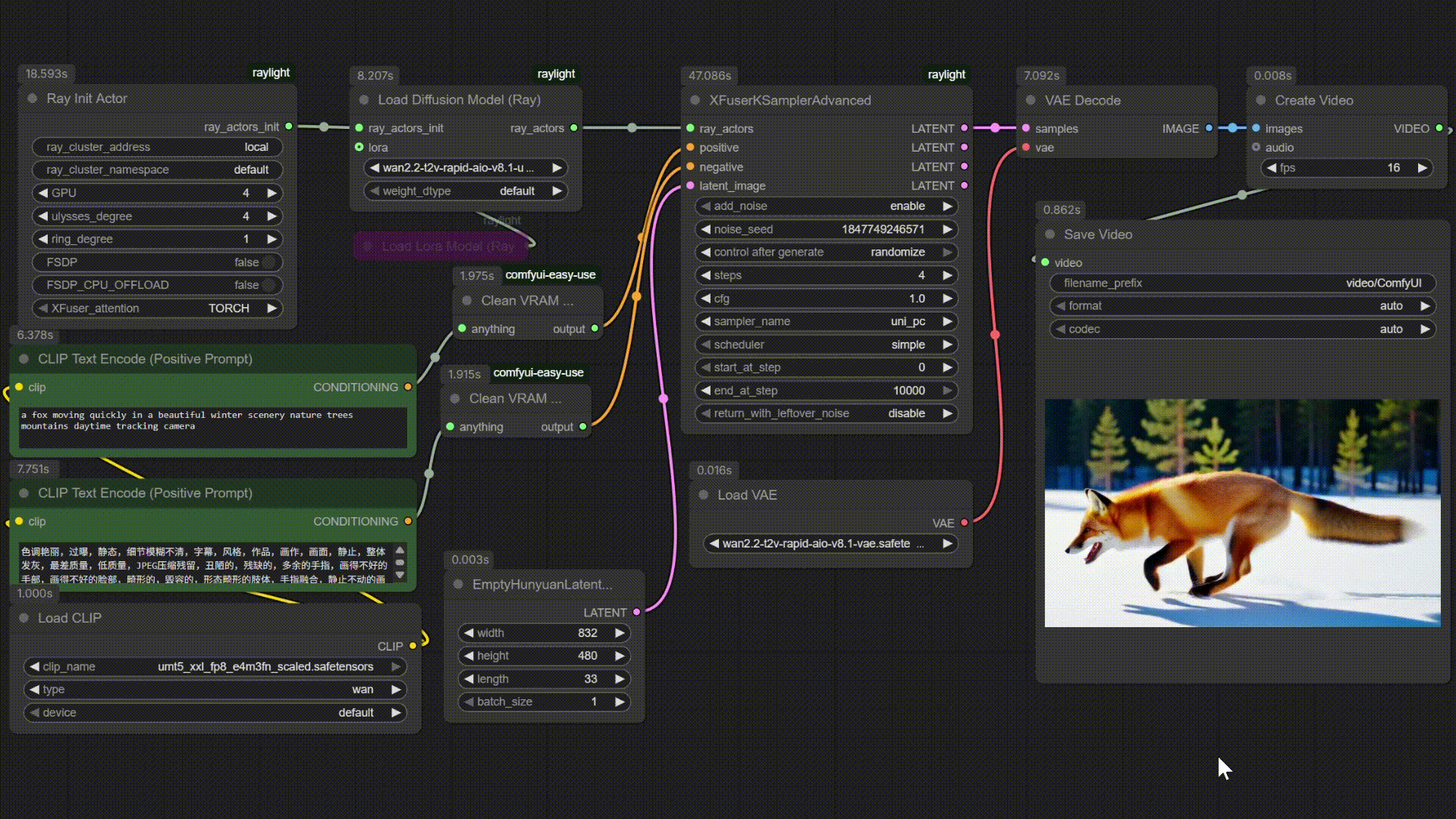 |
### Omni Studio (ComfyUI WebUI 交互)
`Omni Studio` 支持图像生成/编辑、视频生成、音频生成、3D 生成等。
| 模型类别 | 模型 | 类型 |
|----------------------|------------|---------------|
| **图像生成** | Qwen-Image, Qwen-Image-Edit | Text-to-Image, 图像编辑 |
| **图像生成** | Stable Diffusion 3.5 | Text-to-Image, ControlNet |
| **图像生成** | Z-Image-Turbo | Text-to-Image |
| **图像生成** | Flux.1, Flux.1 Kontext dev | Text-to-Image, 多图参考, ControlNet |
| **图像生成** | FireRed-Image-Edit-1.1 | 图像编辑 |
| **视频生成** | Wan2.2 TI2V 5B, Wan2.2 T2V 14B, Wan2.2 I2V 14B | Text-to-Video, Image-to-Video |
| **视频生成** | Wan2.2 Animate 14B | 视频动画 |
| **视频生成** | HunyuanVideo 1.5 8.3B | Text-to-Video, Image-to-Video |
| **视频生成** | LTX-2 | Text-to-Video, Image-to-Video |
| **3D 生成** | Hunyuan3D 2.1 | 文本/图像转 3D |
| **音频生成** | VoxCPM1.5, IndexTTS 2 | Text-to-Speech, 语音克隆 |
| **视频超分** | SeedVR2 | 视频修复与超分辨率 |
请查看 [ComfyUI 支持](omni/README.md/#comfyui) 了解更多详情。
### Omni Serving (兼容 OpenAI-API 的服务)
`Omni Serving` 支持图像生成、音频生成等。
- 图像生成 (`/v1/images/generations`): Stable Diffusion 3.5, Flux.1-dev
- Text to Speech (`/v1/audio/speech`): Kokoro 82M
- Speech to Text (`/v1/audio/transcriptions`): whisper-large-v3
请查看 [Xinference 支持](omni/README.md/#xinference) 了解更多详情。
## 发布版本
- 请查看 [llm-scaler-vllm](Releases.md/#llm-scaler-vllm) 和 [llm-scaler-omni](Releases.md/#llm-scaler-omni) 的 Docker 镜像发布版本
## 获取支持
- 请通过提交 [Github Issue](https://github.com/intel/llm-scaler/issues) 来报告 Bug 或提出功能需求
标签:AIGC, AI基础设施, ComfyUI, DLL 劫持, FP8, GenAI, GPTQ, GPU计算, INT4, Intel Arc Pro B60, Intel GPU, LLM, PyTorch, Qwen, SGLang, Unmanaged PE, vLLM, Xinference, 人工智能, 凭据扫描, 图像生成, 多模态, 大模型部署, 大语言模型, 开源搜索引擎, 开源框架, 持续集成, 文本生成, 文生图, 文生视频, 模型服务化, 模型量化, 深度学习推理, 独立显卡, 生成式AI, 用户模式Hook绕过, 索引, 视频生成, 请求拦截, 逆向工具, 高性能计算