THUDM/slime
GitHub: THUDM/slime
slime 是一个面向大规模强化学习 scaling 的 LLM 后训练框架,通过深度集成 Megatron 训练与 SGLang 推理引擎,提供高性能训练与灵活数据生成能力。
Stars: 6474 | Forks: 937
# slime
[中文版](./README_zh.md)
[](https://thudm.github.io/slime/)
[](https://github.com/THUDM/slime/pull/2053/checks)
[](https://deepwiki.com/THUDM/slime)
**slime** 是一个用于 RL scaling 的 LLM 后训练框架,提供两项核心能力:
1. **高性能训练**:通过将 Megatron 与 SGLang 相连,支持各种模式下的高效训练;
2. **灵活的数据生成**:通过自定义数据生成接口和基于 server 的 engine,实现任意训练数据生成工作流。
slime 的设计目标是使这两项能力相互增强,而不会将系统变成由互不相连的 trainer、rollout 服务和 agent 框架组成的沉重技术栈。Megatron 训练、SGLang rollout、自定义数据生成、reward 计算、verifier 反馈以及环境交互,都流经相同的“训练 / rollout / 数据缓冲区(Data Buffer)”路径。
这使得 slime 成为经过最充分实战检验的开源 RL 后训练框架之一:它小到足以让人理解和扩展,同时又通过 SOTA 级别模型发布背后的完整训练循环得到了验证。
## 为什么这种设计至关重要
- **经过前沿模型训练的实战检验**:slime 是 [GLM-5.2](https://z.ai/blog/glm-5.2)、[GLM-5.1](https://z.ai/blog/glm-5.1)、[GLM-5](https://z.ai/blog/glm-5)、[GLM-4.7](https://z.ai/blog/glm-4.7)、[GLM-4.6](https://z.ai/blog/glm-4.6) 和 [GLM-4.5](https://z.ai/blog/glm-4.5) 背后的 RL 框架。这验证了完整的后训练循环,而不仅仅是孤立的示例。
- **正确性优先的基础设施**:RL 中的 bug 往往是静默的。slime 保持了显式的数据流,支持独立的纯 rollout 和纯训练调试路径,并将可复现性、容错性、链路追踪、性能分析和 CI 作为头等工程关注点记录在案。
- **原生设计**:slime 直接传递 Megatron 参数,并通过 `--sglang-` 前缀暴露已安装的 SGLang 参数。无需在 slime 内部添加另一个抽象层即可使用新的上游训练和推理优化。
- **最大程度的数据生成自由度**:数学、代码、搜索、工具、沙盒、verifier、环境、多 agent 系统以及长期跨度的 agentic 工作流,都可以作为数据生成或 reward 工作流插入。它们不需要 fork 训练内核。
- **轻量且坚定**:slime 深度聚焦于用于大规模 RL 的 Megatron + SGLang 路径。通过选择单一的 rollout 后端,slime 能够直接使用 SGLang 特有的功能,而不是将多个推理引擎扁平化为“最小公分母”式的抽象。
## 生产验证
slime 已经经受了发布级模型后训练所需的完整工作流的考验:大规模训练、高吞吐 rollout、权重同步、reward/verifier 数据、checkpoint、调试以及长期运行的稳定性。
除了 GLM 系列之外,slime 还支持:
- Qwen 系列:Qwen3.6、Qwen3.5、Qwen3Next、Qwen3MoE、Qwen3、Qwen2.5;
- DeepSeek V3 系列:DeepSeek V3、V3.1、DeepSeek R1;
- Llama 3。
## 原生引擎透传与 SGLang 部署
slime 不仅仅是一个可以调用推理后端的框架。它在添加 RL 数据流的同时,使 Megatron 和 SGLang 的控制面尽可能贴近上游引擎:
- 原生 SGLang 参数透传:已安装的 SGLang 支持的每个参数都可以通过添加 `--sglang-` 前缀来使用,例如将 `--mem-fraction-static` 作为 `--sglang-mem-fraction-static` 传递;
- 原生 Megatron 参数透传:slime 直接读取 Megatron 参数,因此 Megatron 侧的并行、优化器、checkpoint 和模型选项无需封装代码即可使用;
- [SGLang Config](docs/en/advanced/sglang-config.md) 作为可选的 YAML 扩展,用于特定拓扑的控制,例如分离的 prefill/decode/EPD 风格设置、异构 server 组、多模型部署以及基于组的 SGLang 覆盖;
- [PD 分离](docs/en/advanced/pd-disaggregation.md)(PD Disaggregation)适用于具有不同 prefill/decode 资源需求的多轮和 agentic 工作负载;
- router 策略,例如用于多轮 agent 的 session affinity;
- [Delta 权重同步](docs/en/advanced/delta-weight-sync.md)(Delta Weight Sync)用于训练/推理分离以及大模型更新效率;
- [外部 Rollout 引擎](docs/en/advanced/external-rollout-engines.md)(External Rollout Engines)适用于在训练作业之外管理推理的部署。SGLang 推理侧可以使用独立的环境,通过磁盘传输甚至可以在不同的 GPU 型号或供应商上运行,同时使用来自磁盘的完整 checkpoint 更新或通过共享文件系统的增量更新。
这种透传设计从一开始就使 slime 具备了原生特性。随着引擎的发展,大多数上游引擎的改进依然可以访问,而 slime 则专注于 RL 循环、数据流、同步和正确性检查。
选择 SGLang 作为单一的 rollout 后端也是有意为之。多后端框架通常必须对多个推理引擎的公共子集进行抽象,这可能会隐藏每个后端最强大的功能。相反,slime 针对 SGLang 进行了深度优化,因此 RL 工作负载可以直接使用 SGLang 特有的推理、路由、缓存、分离和权重同步行为。
## 正确性、稳定性与 CI
slime 是作为 RL 基础设施开发的,在这里仅仅“脚本能运行”是不够的。该项目维护着 CPU 单元测试、自定义 hook 的契约测试,以及涵盖密集和 MoE 模型、Megatron 训练路径、SGLang 部署配置、checkpoint、数值精度、异步 rollout、OPD、PPO 风格工作流以及先 rollout 再训练的调试重放的 GPU 端到端测试。
有用的工程文档:
- [CI](docs/en/developer_guide/ci.md)
- [调试](docs/en/developer_guide/debug.md)
- [可复现性](docs/en/advanced/reproducibility.md)
- [容错性](docs/en/advanced/fault-tolerance.md)
- [Trace 查看器](docs/en/developer_guide/trace.md)
- [性能分析](docs/en/developer_guide/profiling.md)
## 博客
- 我们的愿景:[slime:一个用于 RL scaling 的 SGLang 原生后训练框架](https://lmsys.org/blog/2025-07-09-slime/)。
- 我们关于 agentic 训练的想法:[Agent 导向设计:一个用于 Agentic RL 的异步解耦框架](https://www.notion.so/Agent-Oriented-Design-An-Asynchronous-and-Decoupled-Framework-for-Agentic-RL-2278e692d081802cbdd5d37cef76a547)
- v0.1.0 发布说明:[v0.1.0:重新定义高性能 RL 训练框架](https://thudm.github.io/slime/blogs/release_v0.1.0.html)
## 目录
- [为什么这种设计至关重要](#why-this-design-matters)
- [生产验证](#production-validation)
- [原生引擎透传与 SGLang 部署](#native-engine-pass-through-and-sglang-deployment)
- [正确性、稳定性与 CI](#correctness-stability-and-ci)
- [架构概览](#architecture-overview)
- [快速开始](#quick-start)
- [基于 slime 构建的生态](#ecosystem-built-on-slime)
- [参数详解](#arguments-walkthrough)
- [开发者指南](#developer-guide)
- [常见问题与解答 & 致谢](#faq--acknowledgements)
## 架构概览
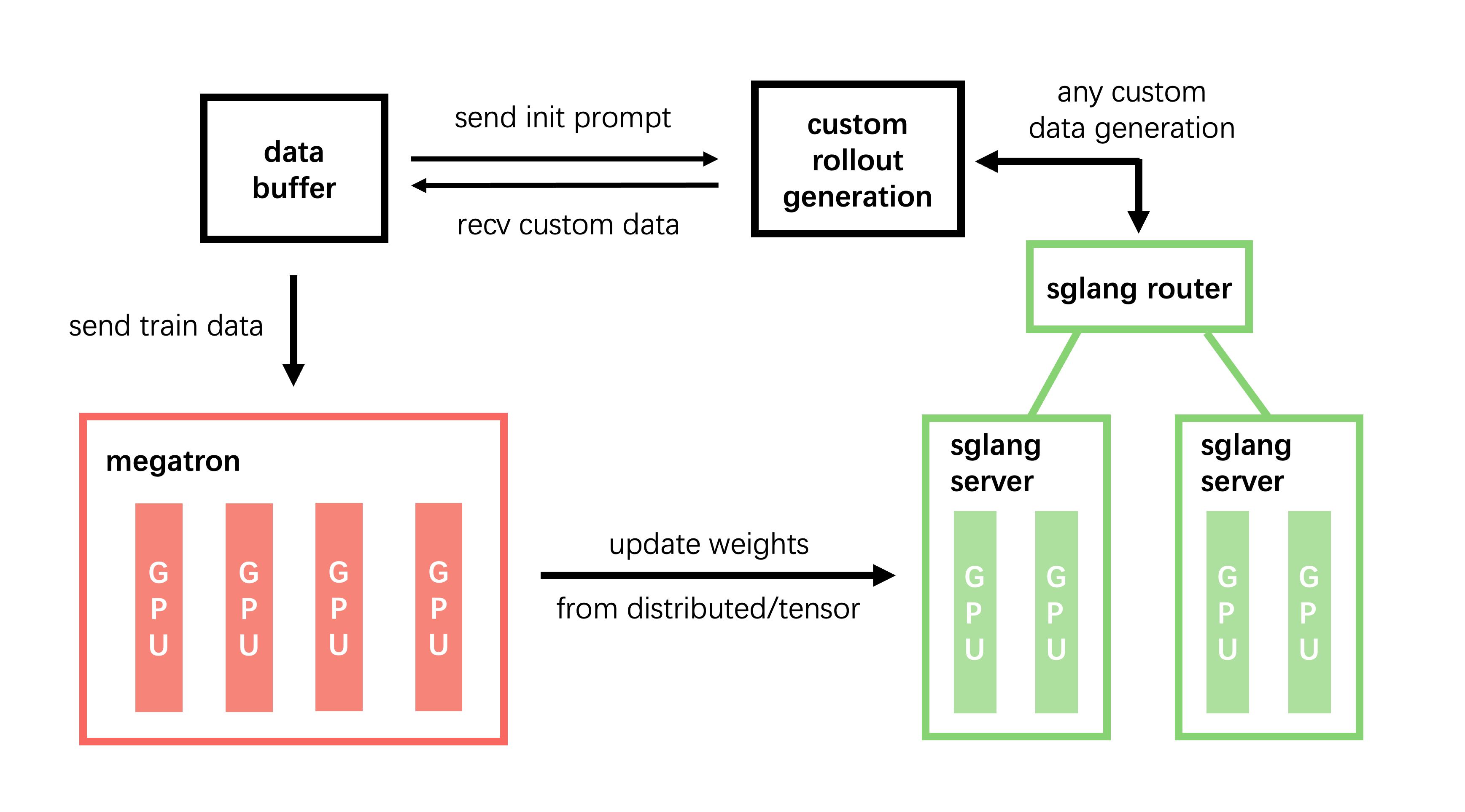
**模块说明**:
- **training (Megatron)**:负责主训练流程,从数据缓冲区读取数据,并在训练后将参数同步到 rollout 模块。
- **rollout (SGLang + router)**:生成新数据(包括 reward/verifier 输出)并将其存储在数据缓冲区中。自定义 generate 函数可以用多轮循环、工具调用、环境/沙盒交互以及基于 verifier 的 reward 来包装它。
- **数据缓冲区**:一个桥接模块,用于管理 prompt 初始化、自定义数据和 rollout 生成方法(包括通过相同接口生成样本的 agentic 工作流)。
## 快速开始
有关涵盖环境设置、数据准备、训练启动和关键代码分析的详尽快速入门指南,请参阅:
- [快速入门指南](./docs/en/get_started/quick_start.md)
我们还为快速入门指南中未涵盖的一些用例提供了示例;请查看 [示例](examples/)。
### Agentic RL 示例
对于 agentic RL 工作负载,以下示例通过自定义接口插入到标准的“rollout / 数据缓冲区”循环中——它们不是独立的框架:
- [`examples/multi_agent`](examples/multi_agent/README.md):通过自定义的 `--rollout-function-path` 进行多 agent rollout。
- [`examples/search-r1`](examples/search-r1/):通过 `--custom-generate-function-path` 进行搜索/RAG 风格的多轮生成。
- [`examples/fully_async`](examples/fully_async/README.md):完全异步的 rollout,适用于某些样本耗时远长于其他样本的长尾 agentic 生成。
- [`examples/coding_agent_rl`](examples/coding_agent_rl/README.md):端到端的 SWE 编程 agent RL,具有沙盒工具使用、基于测试的 reward,以及通过 `--custom-generate-function-path` 实现的 token 正确的轨迹切片。
有关对于特定的 agentic 工作流应使用哪种接口,请参阅 [自定义指南](docs/en/get_started/customization.md)。
## 基于 slime 构建的生态
这些不仅是演示。它们是独立的系统,将 slime 用作生产规模后训练、agentic RL、领域 RL 和 rollout 系统研究的可重用 RL 基础底座。
### ⛵ Miles:用于大规模模型训练的企业级强化学习
[Miles](https://github.com/radixark/miles) 是一个面向大规模模型的 RL 后训练框架,由 [RadixArk](https://github.com/radixark) 基于 slime 构建。它与 slime 的上游开发保持紧密一致,同时通过面向企业的功能对其进行扩展:更深度的 [SGLang](https://github.com/sgl-project/sglang) 集成、运维工具、部署支持,以及对新 [模型](https://www.radixark.com/miles/docs/models) 和 [硬件](https://www.radixark.com/miles/docs/platforms) 的优化。Miles 还增加了一系列不断增长的生产功能,包括 LoRA、TITO 和低精度训练。
### 🔷 vime:基于 slime 构建的 vLLM 原生 RL 后训练
[**vime**](https://github.com/vllm-project/vime) 是一个基于 slime 构建并由 vLLM 项目维护的后训练框架。它保留了 slime 的 Megatron 训练技术栈、数据缓冲区数据流和自定义数据生成设计,其主要变化是将 rollout 后端替换为 [**vLLM**](https://github.com/vllm-project/vllm) 和 [vllm-router](https://github.com/vllm-project/router)。从现有的 slime 启动脚本开始,只需调整与 rollout 相关的参数,就足以使用 vime 快速运行训练。
### 🌈 Relax:面向全模态 Agentic 训练的异步 RL 引擎
[**Relax**](https://github.com/redai-infra/Relax)(Reinforcement Engine Leveraging Agentic X-modality)是由 RedAI Infra 团队开源的全模态 agentic RL 框架,构建在结合了 Ray、Megatron-LM 和 SGLang 的 slime 基础设施栈之上。Relax 在 Ray Serve 上采用了面向服务的架构,并以 Megatron-LM 和 SGLang 作为训练/推理后端。它使用 [TransferQueue](https://github.com/Ascend/TransferQueue) 将 Actor、Rollout、ActorFwd、Reference 和 Advantage 的计算完全解耦到独立的 GPU 集群上,并引入了 **DCS (Distributed Checkpoint Service)**——这是一个通过 NCCL 广播进行权重同步的引擎,它异步地将更新后的 Actor 权重流式传输给 Rollout/ActorFwd/Reference,并将传输与下一个训练步重叠,从而实现具有可配置 staleness 的完全异步训练。Relax 支持文本、视觉和音频(包括 Qwen3-Omni)的端到端 RL 以及 agentic 多轮 rollout。
### 🦞 OpenClaw-RL:只需通过对话即可训练个性化的 Clawbot
[**OpenClaw-RL**](https://github.com/Gen-Verse/OpenClaw-RL) 是一个用于个性化 OpenClaw agent 的 RL server。它托管了 OpenClaw 模型,并在跨部署中从先前的对话中不断改进它,同时 slime 的异步 RL 基础设施防止训练干扰 API 服务。它支持两种自动优化方法:利用从后续状态推断出的二元反馈的 GRPO,以及从后续反馈中为当前策略提取事后提示的 on-policy distillation。
### ⚛️ P1:用强化学习掌握物理奥林匹克竞赛
[**P1**](https://prime-rl.github.io/P1/) 是一系列完全通过强化学习训练的开源物理推理模型。P1 以 slime 作为 RL 后训练框架,并引入了一种多阶段 RL 训练算法,该算法通过自适应可学习性调整和稳定化机制增强推理能力。在这种训练范式的赋能下,P1 在开源物理推理方面取得了突破性的表现。
### 📈RLVE:利用自适应可验证环境扩展语言模型的强化学习
[**RLVE**](https://github.com/Zhiyuan-Zeng/RLVE) 引入了一种使用可验证环境的方法,这些环境以程序化方式生成问题并提供算法上可验证的 reward,从而扩大语言模型(LM)的 RL 规模。通过跨 400 个可验证环境的联合训练,RLVE 使每个环境能够在训练过程中根据策略模型的能力动态调整其问题难度分布。
### ⚡ TritonForge:用于 Kernel 生成的 Agentic RL 训练框架
[**TritonForge**](https://github.com/RLsys-Foundation/TritonForge) 利用 slime 的 SFT 和 RL 功能来训练能够自动生成优化 GPU kernel 的 LLM。通过采用两阶段训练方法(即监督微调,随后是带有编译多轮反馈的强化学习),TritonForge 在将 PyTorch 操作转换为高性能 Triton kernel 方面取得了显著成果。
### 🚀 APRIL:通过主动部分 Rollout 加速 RL 训练
[**APRIL**](https://github.com/RLsys-Foundation/APRIL) 引入了一种系统级优化,可与 slime 无缝集成以加速 RL 训练中的 rollout 生成阶段。通过智能地超额配置请求并主动管理部分完成情况,APRIL 解决了通常会消耗 RL 训练时间 90% 以上的长尾生成瓶颈。
### 🏟️ qqr:利用 ArenaRL 和 MCP 扩展开放式 Agent
[**qqr**](https://github.com/Alibaba-NLP/qqr)(又名 hilichurl)是 slime 的一个轻量级扩展,旨在进化开放式 agent。它实现了 **ArenaRL** 算法,通过基于锦标赛的相对排名(**例如,种子单败淘汰赛、循环赛**)来解决判别性坍塌问题,并无缝集成了 **Model Context Protocol (MCP)**。qqr 利用 slime 的高吞吐训练能力,在标准化、解耦的工具环境中实现 agent 的可扩展、分布式进化。
### ☁️ ART:AWS Bedrock AgentCore Runtime 上可扩展且沙盒化的 Agentic RL
[**ART (AgentCore RL Toolkit)**](https://github.com/awslabs/agentcore-rl-toolkit) 是一个 SDK,用于适配生产环境中的 agent,以便在 **AWS Bedrock AgentCore Runtime** 上进行 RL 训练。AgentCore Runtime 提供了自动扩缩容且沙盒化的 agent 执行环境,非常适合安全地运行大量并行的 agent rollout。使用 ART,用户只需将一个装饰器(`@app.rollout_entrypoint`)应用到他们的 agent 代码上即可进行 RL 适配,同时直接重用相同的生产级 agent 框架,其中用于 RL 的 token 捕获在模型网关层处理。ART 将 slime 作为训练后端选项之一,使用户能够轻松地在 slime 中使用 RL 训练算法优化生产 agent 模型。
综上所述,这些项目展示了 slime 背后的核心理念:一个高性能的 RL 内核,无需更改核心训练循环,即可支持前沿模型后训练、在线 agent 优化、可验证环境、全模态 rollout、kernel 生成 agent 和 rollout 系统研究。
## 参数详解
slime 中的参数分为三类:
1. **Megatron 参数**:slime 直接读取 Megatron 参数。你可以通过传递像 `--tensor-model-parallel-size 2` 这样的参数来配置 Megatron。
2. **SGLang 参数**:已安装的 SGLang 的所有参数都通过透传得到支持。这些参数必须以 `--sglang-` 作为前缀。例如,`--mem-fraction-static` 应该作为 `--sglang-mem-fraction-static` 传递。
3. **slime 特定参数**:请参阅:[slime/utils/arguments.py](slime/utils/arguments.py)
有关完整的用法说明,请参阅 [使用文档](docs/en/get_started/usage.md)。
## 开发者指南
```
apt install pre-commit -y
pre-commit install
# 运行 pre-commit 以确保代码风格一致性
pre-commit run --all-files --show-diff-on-failure --color=always
```
- 有关调试技巧,请参阅 [调试指南](docs/en/developer_guide/debug.md)
## 常见问题与解答 & 致谢
- 有关常见问题,请参阅 [问答](docs/en/get_started/qa.md)
- 特别感谢以下项目和社区:SGLang、Megatron‑LM、mbridge、OpenRLHF、veRL、Pai-Megatron-Patch 等。
- 如需引用 slime,请使用:
```
@misc{slime_github,
author = {Zilin Zhu and Chengxing Xie and Xin Lv and slime Contributors},
title = {slime: An LLM post-training framework for RL Scaling},
year = {2025},
howpublished = {\url{https://github.com/THUDM/slime}},
note = {GitHub repository. Corresponding author: Xin Lv},
urldate = {2025-06-19}
}
```
标签:DLL 劫持, RL Scaling, 人工智能, 凭据扫描, 大语言模型, 强化学习, 模型训练, 用户模式Hook绕过, 逆向工具