GLM-5.1:面向长时任务的持续优化能力演进
作者:FancyPig | 发布时间:
模型介绍
GLM-5.1 是我们面向智能体工程(Agentic Engineering)的下一代旗舰模型,其代码能力较前代模型实现了显著提升。
该模型在 SWE-Bench Pro 基准测试中达到了当前最先进(SOTA)的性能表现,并在 NL2Repo(代码仓库生成)和 Terminal-Bench 2.0(真实终端任务)等评测中,相较 GLM-5 实现了大幅领先。
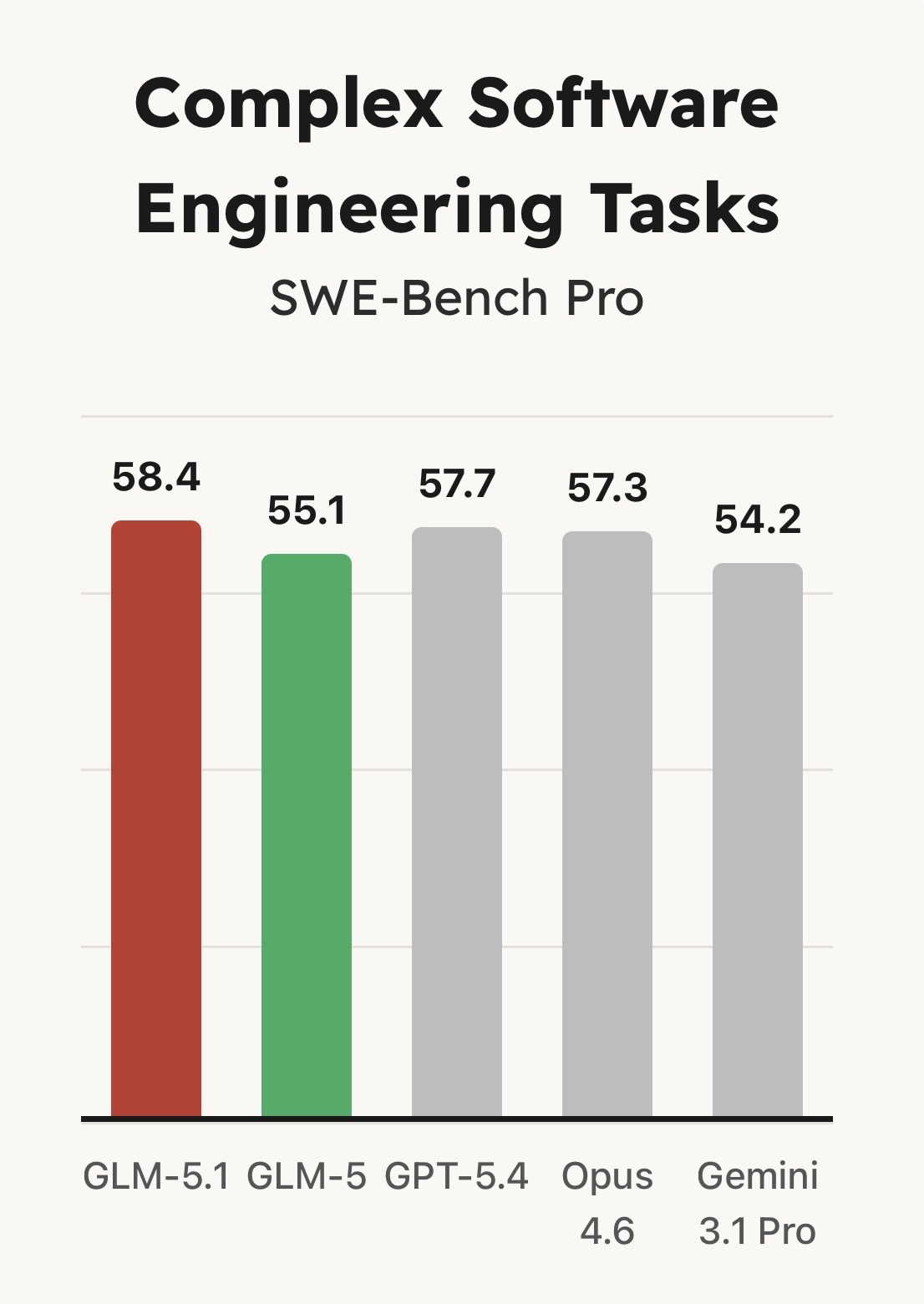
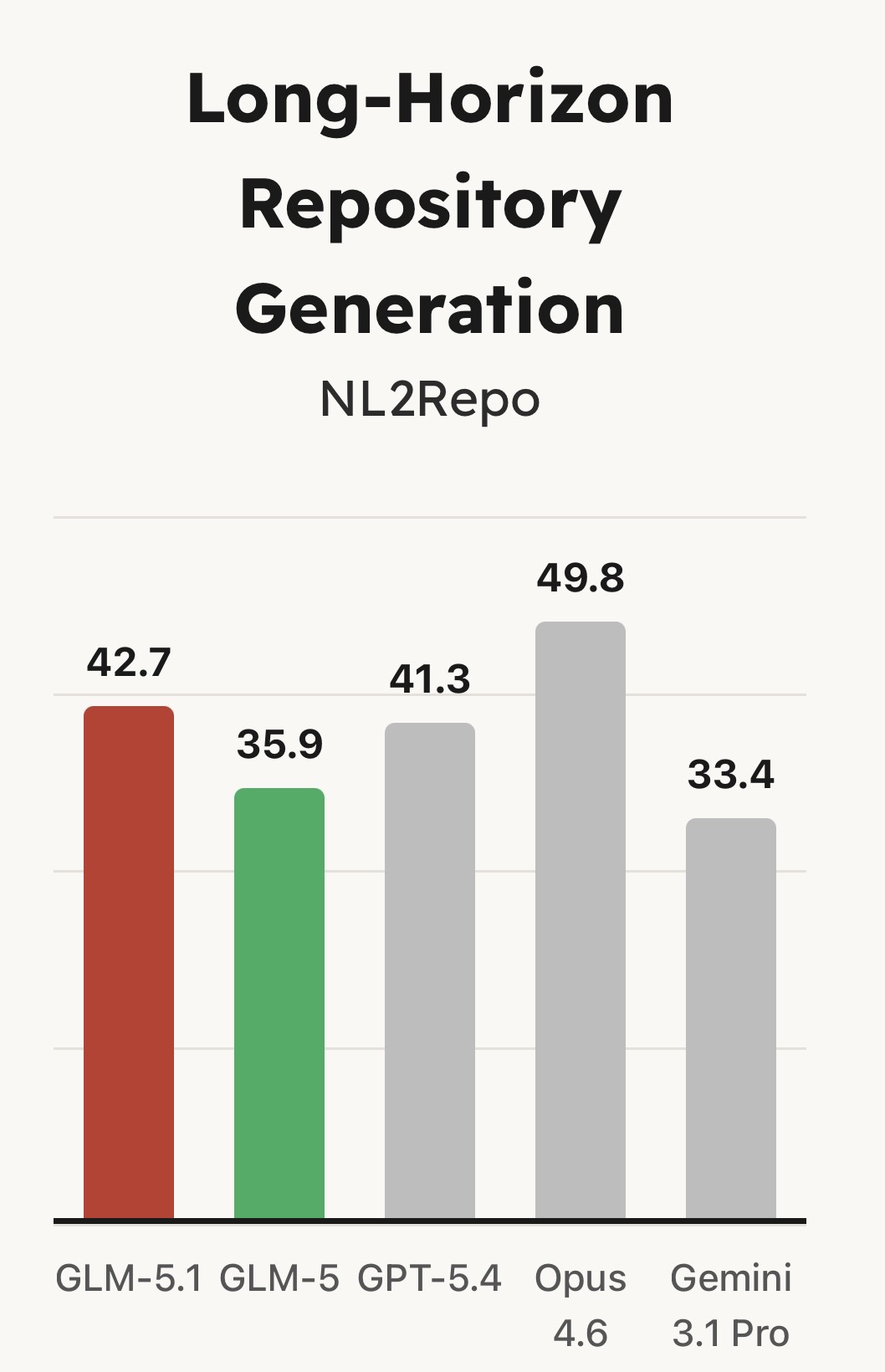
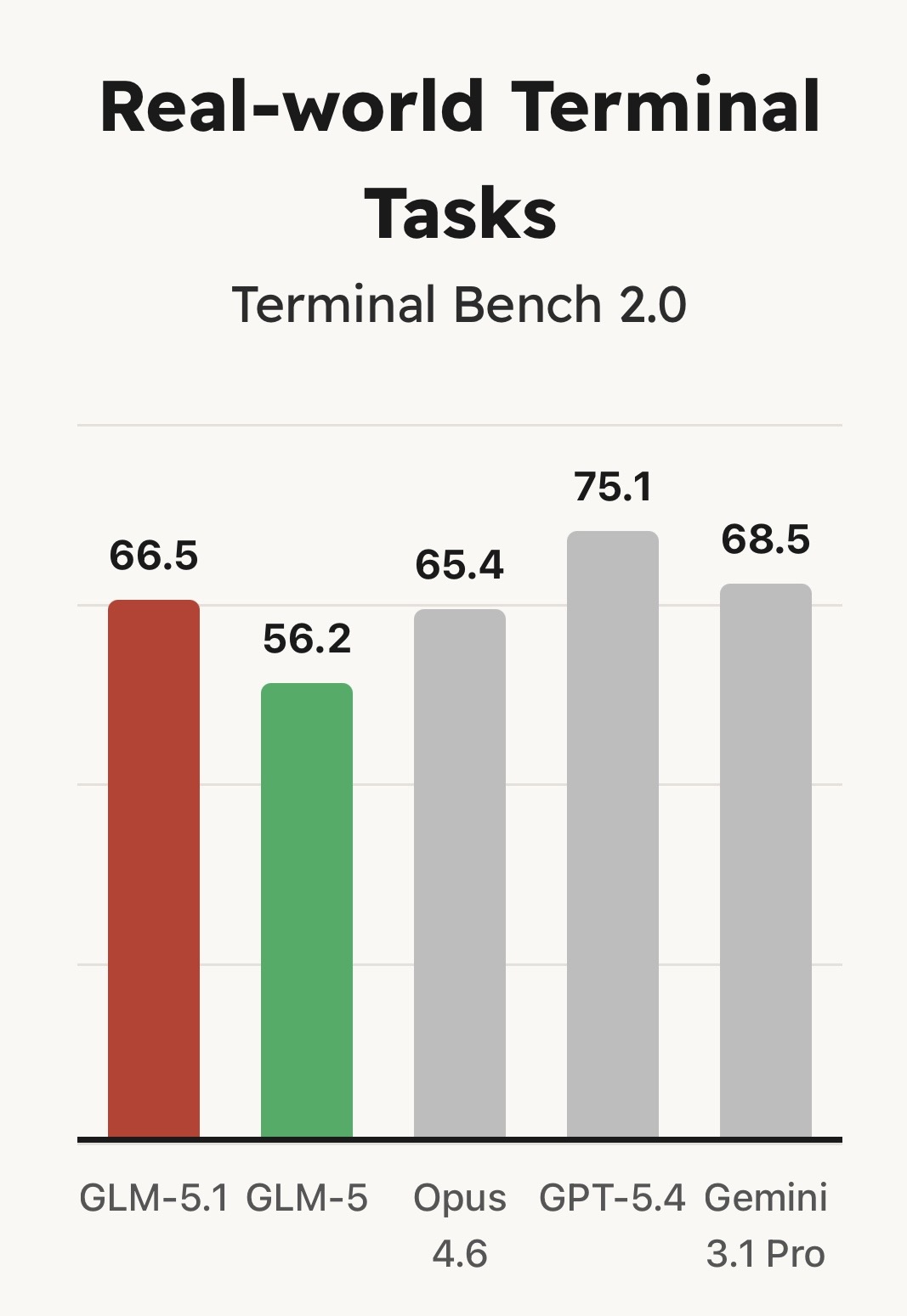
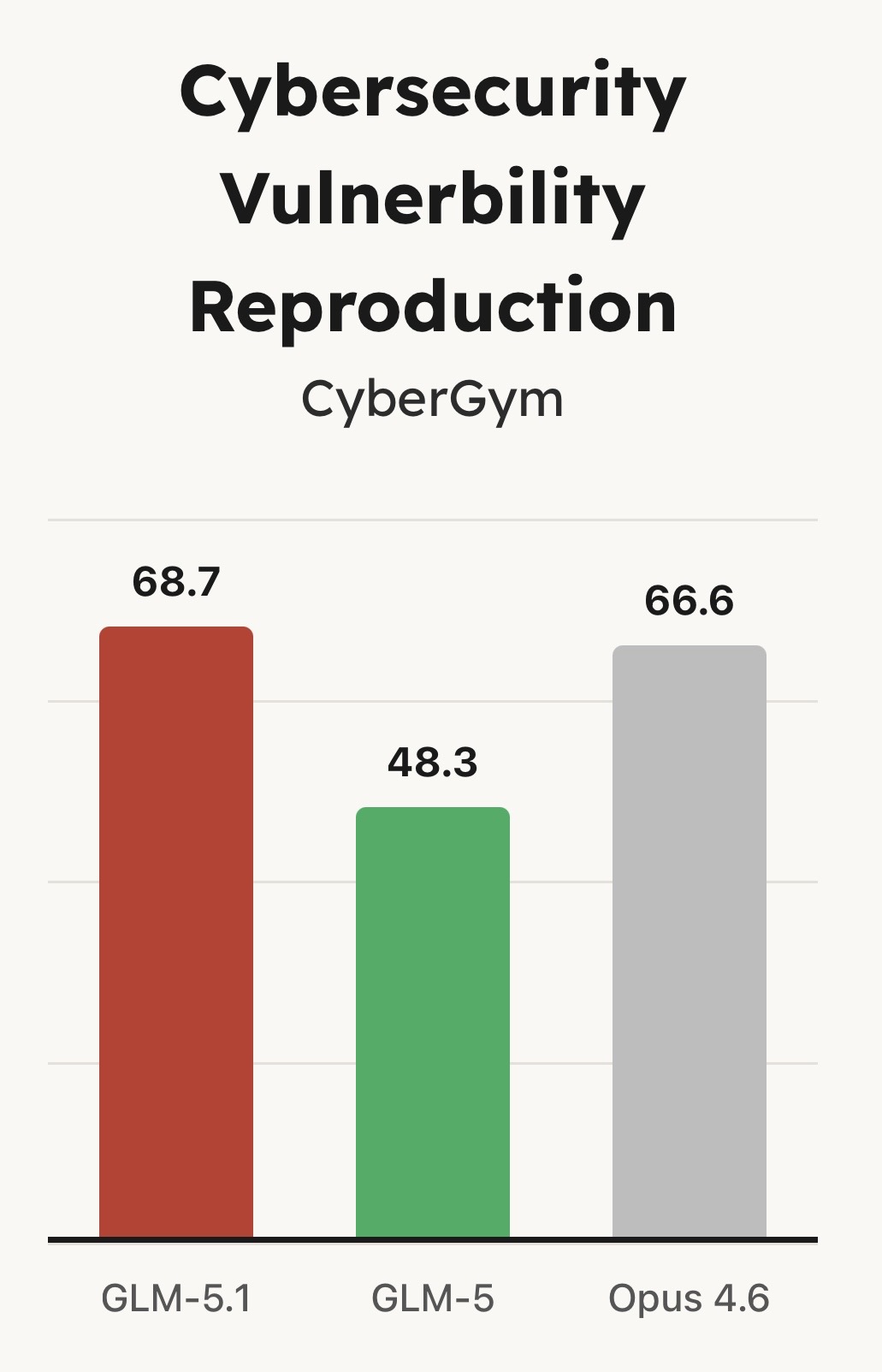
但最关键的突破并不体现在首次结果的性能上。以往的模型(包括 GLM-5)往往在早期就耗尽其可用策略:通过熟悉的方法迅速取得初步提升,随后进入性能瓶颈期。即使延长运行时间,也难以进一步改进。
相比之下,GLM-5.1 被设计用于在更长时间跨度内持续高效地完成智能体任务。实验表明,该模型在处理不确定性问题时具备更强的判断能力,并能够在长时间交互过程中保持稳定的生产效率。
它能够对复杂问题进行结构化拆解,执行实验、分析结果,并以较高精度识别关键瓶颈。
通过反复回溯推理过程并持续调整策略,GLM-5.1 可以在数百轮迭代与数千次工具调用中持续优化结果。运行时间越长,其输出质量反而越高。
我们通过三类任务验证了这一能力,这些任务的反馈机制逐步降低结构化程度:其一是以单一数值指标评估的向量检索优化问题;其二是基于逐任务加速比进行衡量的 GPU 内核基准测试;其三是一个完全开放式的 Web 应用开发任务,在该任务中不存在任何量化指标,仅依赖模型自身判断下一步的优化方向。
场景一:在 600 轮迭代中优化向量数据库
VectorDBBench 是一个开源编程挑战,用于评估模型构建高性能数据库以执行近似最近邻(ANN)检索的能力。
在该任务中,模型会获得一个基于 Rust 的项目骨架,其中包含 HTTP API 接口及未实现的函数占位。随后,模型通过基于工具调用的智能体机制,对代码进行读写、编译、测试与性能分析,所有操作均需在 50 轮工具调用预算内完成。最终结果在 SIFT-1M 数据集上进行评测:在召回率(Recall)≥ 95% 的约束条件下,以查询吞吐量(QPS)作为排序指标。在该评测设定下,当前最佳成绩为 3,547 QPS,由 Claude Opus 4.6 实现。一个自然的问题是:这 50 轮工具调用预算是否构成了性能瓶颈。为此,我们基于 Claude Code 框架,将评测过程重构为一个外层优化循环:在每一轮迭代中,模型可以按需调用任意次数的工具,对代码进行修改、编译、测试与性能分析,随后提交新版本参与基准测试。模型可自主决定提交时机,以及下一步的优化策略。
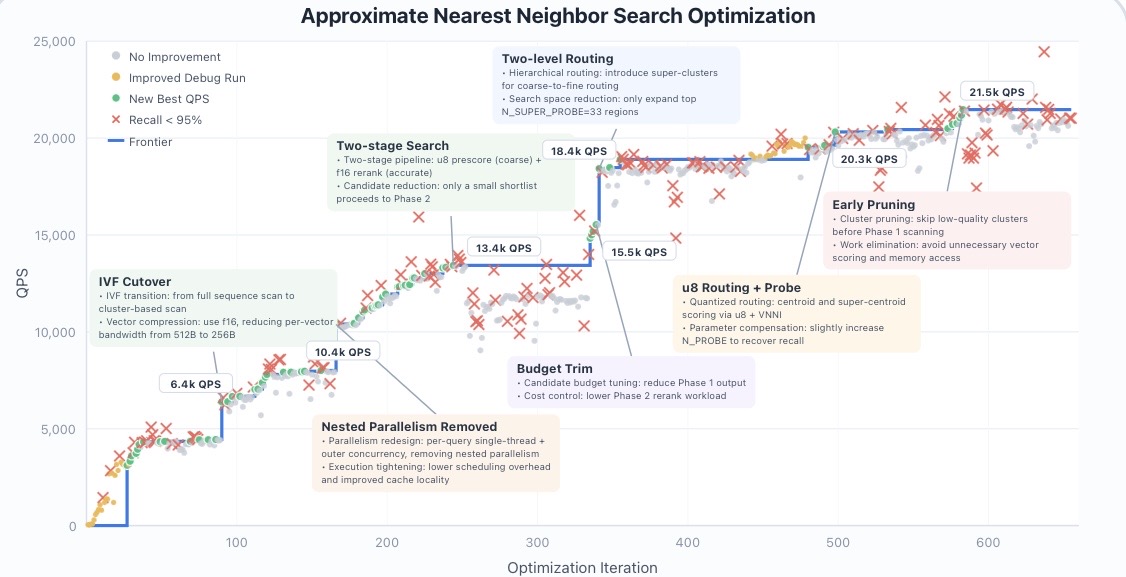
GLM-5.1 并未在 50 次或 100 次提交后出现性能停滞,而是在超过 600 轮迭代、累计 6,000 次以上工具调用的过程中,持续发现并实现有效优化,最终达到 21.5k QPS——约为传统单次 50 轮评测最佳结果的 6 倍。其优化过程呈现出典型的“阶梯式演进”特征:在既定策略下进行一段时间的渐进式调优后,通过结构性调整实现性能跃迁,从而不断突破性能边界。
这一模式在多个关键阶段中得到体现。例如,在约第 90 轮迭代时,模型从全量扫描策略切换为基于 IVF(倒排文件索引)的簇探测机制,并引入 f16 向量压缩,使性能跃升至 6.4k QPS;在约第 240 轮迭代时,模型进一步构建了两阶段处理流水线——先使用 u8 进行预打分(prescoring),再通过 f16 进行精排(reranking),将性能提升至 13.4k QPS。在整个优化过程中,共发生了 6 次此类结构性策略切换,且每一次均由模型基于自身基准测试日志分析,自主识别当前瓶颈后发起。
需要注意的是,在性能曲线中标记为红色交叉点的阶段,代表召回率(Recall)短暂低于 95%。这些波动通常集中出现在策略切换阶段:模型在探索新方向时会暂时突破约束条件,随后通过调整参数或策略重新恢复至约束范围之内,从而在探索与约束之间实现动态平衡。
场景二:在 1000+ 轮交互中优化机器学习工作负载
KernelBench 用于评估模型是否能够基于参考的 PyTorch 实现,生成在输出结果完全一致前提下性能更优的 GPU 内核。该基准测试按照优化范围与系统复杂度划分为三个层级:Level 1 针对单算子优化,Level 2 针对算子融合序列优化,Level 3 则面向完整模型的端到端优化,覆盖包括 MobileNet、VGG、MiniGPT 和 Mamba 在内的完整架构,总计 50 个优化任务。
作为对照,torch.compile 在默认配置下可实现约 1.15× 的性能提升,而在启用最大自动调优(max-autotune)后可达到约 1.49×。在本实验中,我们选取四个模型,在 Level 3 场景下进行评估,并以工具调用轮次为横轴,统计其在全部 50 个任务上的几何平均加速比(geometric mean speedup),以衡量模型在长时优化过程中的性能提升能力。
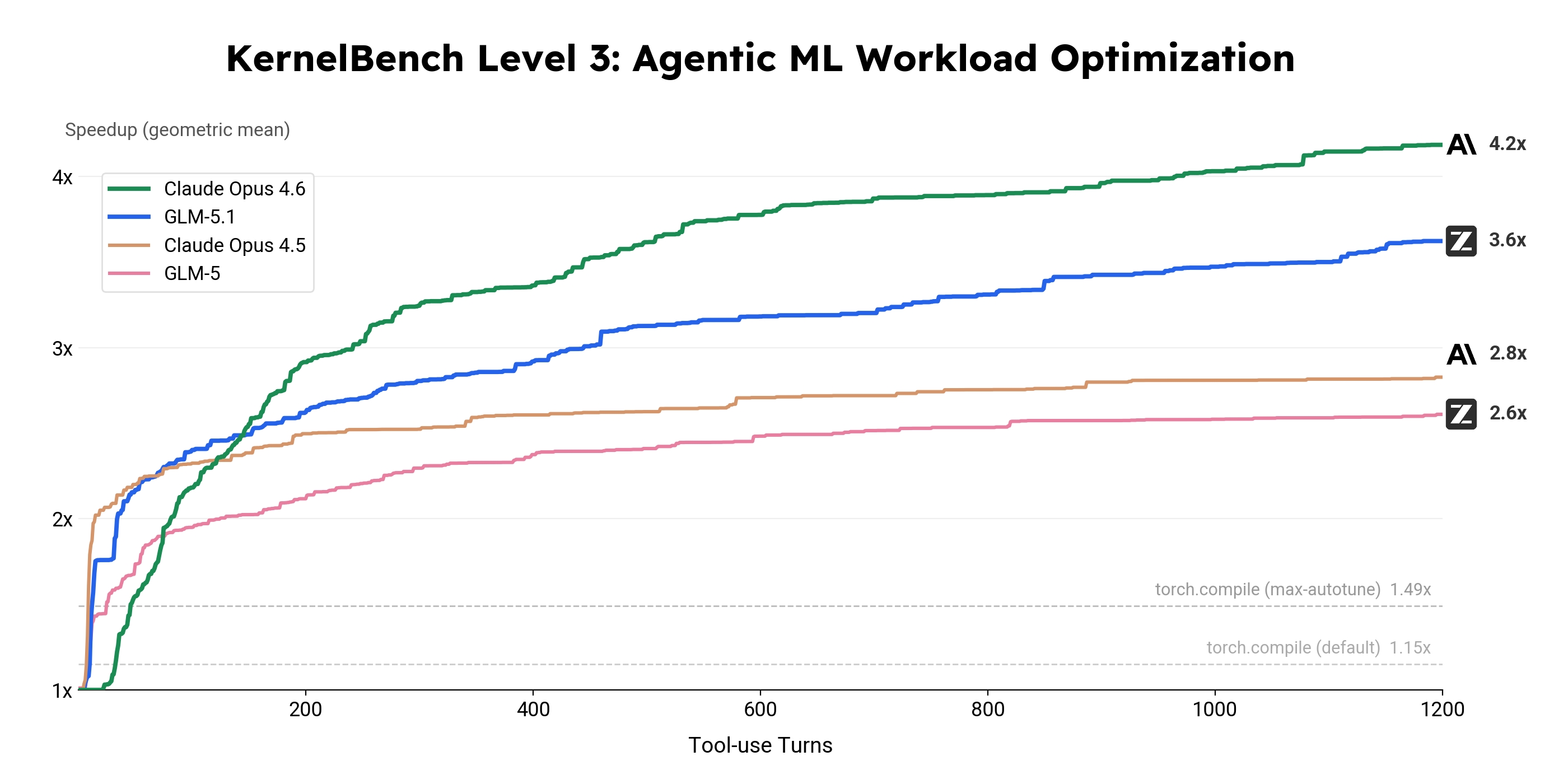
实验曲线清晰展示了不同模型在长时间优化过程中的行为差异。GLM-5 在初期能够快速取得性能提升,但较早进入平台期;Claude Opus 4.5 虽然可以在更长时间内持续优化,但在后期同样出现收益递减的趋势。相比之下,GLM-5.1 将这一优化边界进一步向前推进,在整个运行过程中实现了 3.6× 的性能提升,并且在较长阶段内持续保持有效优化能力。尽管其优化速率也会随时间逐步下降,但相较 GLM-5,其有效优化周期显著延长。
在该评测场景中,Claude Opus 4.6 仍然表现最强,最终达到 4.2× 的加速比,且在测试结束时仍显示出进一步提升的潜力。
场景三:在 8 小时内构建类 Linux 桌面环境
前两个场景均具备明确的数值优化目标(如 QPS、加速比),模型可以据此进行定量评估与优化。而在网站生成任务中,评价标准本质上更具主观性:模型需要根据自然语言描述生成一个可运行的 Web 应用,但并不存在统一的优化指标,所谓“质量”更多取决于功能完整性、界面表现以及交互体验等多个维度。
在该实验中,我们设定了一个具有挑战性的任务:构建一个类 Linux 桌面环境的 Web 应用。整个过程不提供任何初始代码、设计稿或中间指导。在单轮执行模式下,大多数模型(包括早期版本的 GLM)往往会迅速“收敛”:仅生成一个基础框架,例如静态任务栏和一到两个占位窗口,随后即判定任务完成。这类模型缺乏反思与自检机制,无法主动识别系统中尚未实现或存在缺陷的部分。
针对这一问题,我们为 GLM-5.1 构建了一个简化的执行框架:在每一轮执行结束后,模型需对自身输出进行评估,识别可改进项(如缺失功能、粗糙样式或交互缺陷),并继续迭代优化。该闭环持续运行 8 小时,其最终效果与单轮执行相比呈现出显著差异。
在初始阶段,GLM-5.1 会生成一个基础界面布局,包括任务栏和简单窗口,这与短时运行所能达到的结果基本一致。但与之不同的是,它不会止步于此。随着持续迭代,系统功能逐步完善:文件浏览器、终端、文本编辑器、系统监控、计算器以及各类应用不断被引入,并以统一的界面体系进行整合,而非事后拼接。与此同时,界面样式逐渐精细化,交互体验更加流畅,各类边界情况也得到有效处理。最终呈现的是一个完整且视觉一致的浏览器内桌面环境,这一结果直观展示了当模型具备持续迭代能力并拥有充足执行时间时所能达到的效果上限。
在上述三个实验场景中,决定性因素并非单纯的运行时长,而是额外运行时间是否仍具备“有效性”。GLM-5.1 将这一有效优化周期显著延长,相较 GLM-5 能在更长时间内持续产生改进。然而,在 KernelBench 等任务中仍然存在明显提升空间,这表明长时优化能力仍处于探索阶段。
当前仍面临若干关键挑战:在渐进式调优收益减弱时,如何更早跳出局部最优;在跨越数千次工具调用的执行过程中,如何保持整体一致性;以及在缺乏明确数值指标的任务中,如何建立可靠的自评估机制。这些问题尚未完全解决。GLM-5.1 仅是这一方向的初步探索,后续仍将持续推进相关能力的演进。
GLM-5.1 以 MIT 许可证形式开源发布。同时,GLM-5.1 已上线开发者平台 api.z.ai 与 BigModel.cn,并兼容 Claude Code 与 OpenClaw 生态体系。