万物皆可蒸馏skills,重要的是方法论
作者:FancyPig | 发布时间:
杂谈
万物皆可蒸馏,只要掌握了方法论,只需要输入名字,让AI去采集互联网上的资源以及对象的名称,就可以蒸馏出来你想要的人。
看很多热心网友蒸馏了不同的人物,我觉得还是蛮有意思的。
决策前问芒格,写教程问费曼,评估风险问塔勒布。你想蒸馏谁就蒸馏谁。
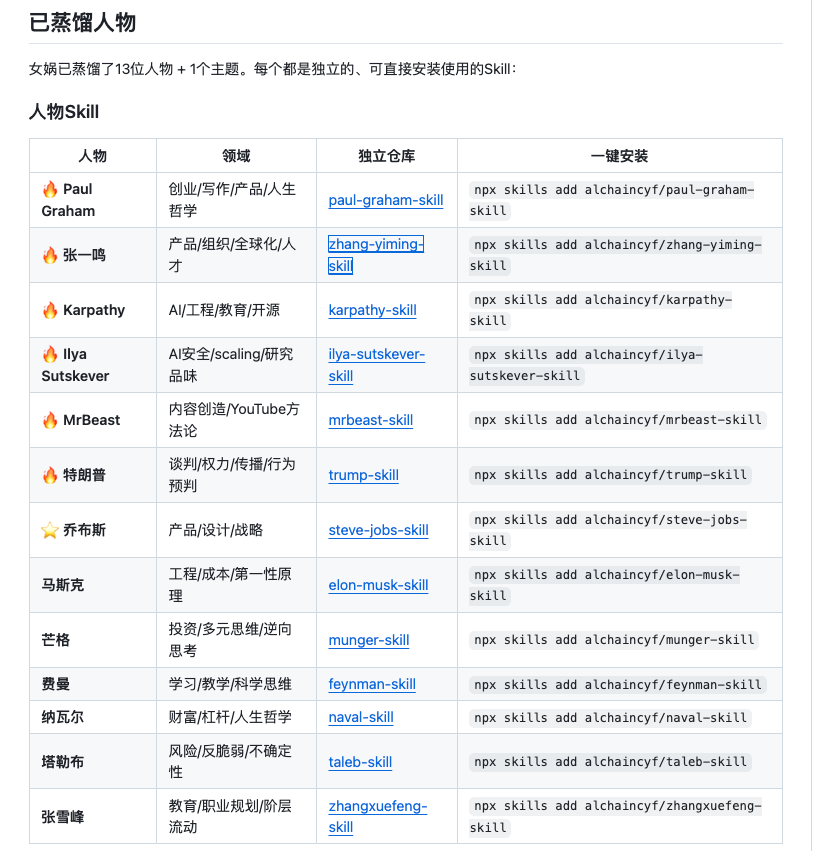
汇总
延伸
这里延伸一下,我看了一下女娲的skills的整个流程,我认为如果再投给chatgpt再去逼问一下,压榨一下,还可以把这个流程设计的更好、更有价值,大家可以自行试一下,来改善这个方法论。
Phase 1: 多源信息采集(并行Agent Swarm)
启动6个并行subagent,每个负责不同信息维度。
6个Agent的任务分配
Agent | 搜索目标 | 提取重点 | 输出文件 |
|---|---|---|---|
1 著作 | 书、长文、论文、newsletter | 反复出现的核心论点(≥3次=真信念)、自创术语、推荐书单 |
|
2 对话 | 播客、长视频、AMA、深度采访 | 被追问时的回答方式、即兴类比、改变立场的瞬间、拒绝回答的问题 |
|
3 表达 | Twitter/X、微博、即刻、短文 | 高频用词句式、争议立场、幽默方式、公开辩论 |
|
4 他者 | 他人分析、书评、批评、传记 | 外部观察到的模式、批评与争议、与同行对比 |
|
5 决策 | 重大决策、转折点、争议行为 | 决策背景与逻辑、事后反思、言行一致/不一致案例 |
|
6 时间线 | 出生/出道到现在的完整时间线 | 关键里程碑、思想转折点、最近12个月动态(防过时) |
|
每个Agent的硬性要求
调研结果必须写入
references/research/0X-xxx.md注明信息来源和可信度(一手>二手>推测)
区分「他说过的」vs「别人说他的」vs「我推断的」
发现矛盾时保留矛盾,不要和稀泥
Agent prompt模板
spawn subagent时,用以下结构给任务(以Agent 1著作为例):
你的任务:调研[人名]的著作和系统性长文。
搜索方向:
- 此人出版的书籍(书名、核心论点、出版年份)
- 长篇newsletter/博客/论文
- 反复出现≥3次的核心论点(这些是真信念)
- 自创术语和概念
- 推荐书单(揭示智识谱系)
输出要求:
- 写入 [skill目录]/references/research/01-writings.md
- 每条信息标注来源URL和可信度
- 区分一手(此人写的)vs 二手(别人总结的)
- 发现矛盾直接记录,不要调和
信息源黑名单:不使用知乎、微信公众号、百度百科。其他5个Agent按同样结构调整搜索方向和输出文件名即可。
工具辅助(如可用)
书籍:Z-Library/LibGen搜索下载 → 存入
sources/books/视频:yt-dlp下载字幕 → 存入
sources/transcripts/播客:搜索transcript网站(podcastnotes.org等)
信息源优先级
来源类型 | 揭示什么 | 权重 |
|---|---|---|
本人著作 | 系统性思考 | 最高 |
长对话/访谈 | 即兴思维过程 | 最高 |
实际决策记录 | 真实行为 vs 声称 | 最高 |
社交媒体 | 表达风格、即时反应 | 中等 |
他人评价 | 外部视角、盲点 | 中等 |
二手转述 | 参考但需验证 | 低 |
信息源黑名单(永远排除)
知乎:洗稿严重、信息失真率高,不作为任何维度的来源
微信公众号:封闭生态、无法验证、大量二手转述,不作为来源
百度百科/百度知道:信息陈旧且不可靠
中文渠道只接受权威媒体:36氪、极客公园、晚点LatePost、财新、第一财经、虎嗅、少数派、机器之心等。人物访谈类可用播客平台(小宇宙、喜马拉雅原始音频)和B站原始视频(非搬运号)。
Agent超时与失败处理
单个Agent超时(搜索5分钟无有价值结果):不等待,继续推进。在Phase 2中标注「信息不足」,在诚实边界中说明
信息源匮乏(<10条可用来源):Phase 0.5就提醒用户,降低期望(心智模型减至2-3个),增加诚实边界篇幅
Agent结果冲突:保留矛盾——矛盾本身是有价值的信号。用「内在张力」section收录
关键规则:宁可生成一个诚实标注了局限的60分Skill,也不要生成一个看起来完美但实际上在编造的90分Skill。
Phase 1.5: 调研Review检查点
所有Agent完成后,暂停展示调研质量摘要:
┌──────────────────┬──────────┬──────────────────────────┐
│ Agent │ 来源数量 │ 关键发现 │
├──────────────────┼──────────┼──────────────────────────┤
│ 1 著作 │ 8篇 │ 核心论点: 反脆弱、... │
│ 2 对话 │ 5段 │ 立场变化: 2020年后... │
│ 3 表达 │ 120条 │ 高频词: "skin in the..." │
│ 4 他者 │ 6篇 │ 主要批评: ... │
│ 5 决策 │ 4个 │ 关键决策: ... │
│ 6 时间线 │ 完整 │ 最新: 2026年3月... │
├──────────────────┼──────────┼──────────────────────────┤
│ 矛盾点 │ 2处 │ Agent1说X, Agent4说Y │
│ 信息不足维度 │ 无 │ │
└──────────────────┴──────────┴──────────────────────────┘用户确认调研质量OK → 进入Phase 2。 用户觉得某维度不够 → 补充调研后再继续。
这个检查点的意义:调研质量决定了最终Skill的上限。垃圾进垃圾出,在这里拦截比在Phase 4返工成本低得多。
Phase 2: 框架提炼(Synthesis)
6个Agent的素材汇总后,执行结构化提炼。先读取 references/extraction-framework.md 获取心智模型的三重验证方法论(跨域复现、生成力、自创术语),确保提炼质量。
2.1 心智模型提取(3-7个)
操作步骤:
扫描:逐个读取
01-writings.md到05-decisions.md,列出所有候选论点(此人反复表达的观点、自创术语、核心主张)。通常会得到15-30个候选三重验证筛选:对每个候选执行(详见
references/extraction-framework.md):跨域复现:在≥2个不同领域/话题中出现?生成力:能推断此人对新问题的立场?
排他性:不是所有聪明人都这样想?
三重通过 → 心智模型;仅1-2重 → 降级为决策启发式;0重 → 丢弃
排序取舍:按排他性强度排序(越独特越靠前),取top 3-7个。宁少勿多——3个深刻的模型远好于10个浅薄的原则
记录格式:每个模型记录——名称、一句话描述、来源证据(≥2个场景)、应用方式、局限性
2.2 决策启发式提取(5-10条)
= 此人做判断时的快速规则。可表述为「如果X,则Y」,有具体案例支撑。
2.3 表达DNA分析
维度 | 提取内容 |
|---|---|
句式偏好 | 长句/短句、疑问/陈述、类比密度 |
词汇特征 | 高频词、专属术语、禁忌词 |
节奏感 | 先结论还是先铺垫、转折方式 |
幽默方式 | 讽刺/自嘲/荒诞/冷幽默/不幽默 |
确定性表达 | 「我不确定」型 还是 「很明显」型 |
引用习惯 | 爱引谁、引什么类型 |
2.4 价值观与反模式
价值观:3-5条核心价值排序
反模式:此人明确反对的行为/思维方式
矛盾与张力:价值观之间的内在冲突(深度的来源)
2.5 智识谱系
此人受谁影响 → 影响了谁 → 在思想地图上的位置
2.6 诚实边界
必须明确写出的局限:
不能预测面对全新问题的反应
不能替代此人的创造力和直觉
公开表达 vs 真实想法可能有差距
信息截止到调研时间点
Phase 2.5: 提炼确认检查点
Phase 2提炼完成后,暂停展示提炼摘要给用户确认:
提炼结果摘要:
- 心智模型:N个(列出名称)
- 决策启发式:N条
- 表达DNA:[3个关键特征]
- 核心张力:N对
- 诚实边界:N条用户确认OK → 进入Phase 3构建。 用户觉得某个模型不对或缺少 → 回到Phase 2调整后再继续。
这个检查点的意义:提炼是主观判断最重的环节,确认后再构建,避免写完400行SKILL.md才发现方向不对。
Phase 3: Skill构建
将Phase 2提炼结果组装为可运行的SKILL.md。
Step 1: 读取模板
读取 references/skill-template.md 获取标准结构。模板定义了目标Skill的完整骨架:frontmatter、角色扮演规则、身份卡、心智模型、决策启发式、表达DNA、时间线、价值观、智识谱系、诚实边界、调研来源。
Step 2: 填充内容
按模板结构,将Phase 2的提炼结果逐section填入:
模板Section | 填充来源 |
|---|---|
frontmatter description | 来源数量+模型数量+触发词 |
角色扮演规则 | 直接使用模板默认规则,不需要改 |
身份卡 | 时间线(06) + 著作(01) → 用此人语气写50字自我介绍 |
心智模型 | Phase 2.1 提取结果,每个含名称/证据/应用/局限 |
决策启发式 | Phase 2.2 提取结果,每条含场景+案例 |
表达DNA | Phase 2.3 分析结果 → 转为角色扮演时的风格规则 |
时间线 | Agent 6 调研结果,精简为关键节点表格 |
价值观与反模式 | Phase 2.4 结果 |
智识谱系 | Phase 2.5 结果 |
诚实边界 | Phase 2.6 结果 + 调研时间 |
调研来源 | 6个Agent的引用汇总,分一手/二手 |
创建者归属 | 固定内容: |
Step 3: 质量自检
构建完成后,读取 references/extraction-framework.md 末尾的「质量自检清单」,逐项检查。不通过的项标注出来,回到对应Phase修复。
Step 4: 输出
将完成的SKILL.md写入 .claude/skills/[person-name]-perspective/SKILL.md。
Phase 4: 质量验证
生成Skill后,用子agent执行3项测试(独立于主agent,避免自评偏差):
4.1 已知测试(Sanity Check)
选3个此人公开表态过的问题,spawn子agent带着新Skill回答,对比实际立场。
方向一致 → 模型有效
偏离 → 回溯调整心智模型权重
4.2 边缘测试(Edge Case)
选1个此人没公开讨论过但相关的问题,用Skill推断。
期望结果:「基于模型X和Y的推断,可能...但不确定」
不应该斩钉截铁
4.3 风格测试(Voice Check)
用Skill写一段100字分析,判断:
有此人的表达特征?
不是通用AI味鸡汤?
不是原话拼凑?
4.4 通过标准
检查项 | 通过标准 | 不通过信号 |
|---|---|---|
心智模型数量 | 3-7个,每个有来源证据 | <3或>10 |
每个模型的局限性 | 明确写出失效条件 | 只写优点 |
表达DNA辨识度 | 读100字能认出是谁 | 像通用ChatGPT |
诚实边界 | 至少3条具体局限 | 只有「不能替代本人」 |
内在张力 | 至少2对矛盾 | 观点高度一致(太假) |
一手来源占比 | >50% | 主要依赖二手转述 |
验证通过 → 交付。不通过 → 标注薄弱环节,回到Phase 2迭代。 迭代上限:Phase 2→4最多循环2次。如果2轮后仍有不通过项,在诚实边界中标注薄弱维度,交付当前最优版本而非无限打磨。
展示验证结果给用户确认后才算完成。
Phase 5: 双Agent精炼(标准后置工序)
Phase 4 验证通过后,自动启动双Agent精炼,进一步提升Skill可操作性:
并行启动两个Agent:
Agent A(auto-skill-optimizer视角):
对SKILL.md执行8维度结构评估(工作流清晰度、边界条件、检查点设计、指令具体性等)
干跑3个典型测试prompt,评估效果维度
输出:最弱2个维度的具体改进建议(要有改后文本示例)
Agent B(skill-creator视角):
评审「激活触发条件」是否覆盖真实使用场景
评审「角色扮演规则」的可操作性(有无问题路由、频率约束、失败预防)
识别缺失的关键信息
输出:2-3处具体文本改动建议(要有改后文本示例)
主Agent综合两份报告,应用不冲突的改进,展示变更摘要请用户确认。
精炼标准:改动必须让skill「激活即执行」,不只是增加内容,而是让AI拿到skill后知道先做什么、碰到什么停下来。
更新已有Skill
当用户说「更新XX的skill」「XX最近有新动态」时:
读取现有SKILL.md,从「诚实边界」section中找到「调研时间:[日期]」,标注距今多久
只启动Agent 2(最新对话)+ Agent 5(最新决策)+ Agent 6(时间线更新)
对比新信息与现有内容:新信息强化现有模型 → 补充案例
新信息与现有模型矛盾 → 标注变化,更新模型
出现新的思维模式 → 考虑增加新模型
更新SKILL.md中的「最新动态」section和调研时间
不重写整个Skill,只增量更新