谷歌Gemini 3.1 Pro暴力碾压Claude和GPT
作者:修BUG | 发布时间:
2026 年 2 月 20 日凌晨,谷歌 DeepMind 正式官宣旗下全新大模型 Gemini 3.1 Pro 预览版发布,这一消息距离上周 Gemini 3 Deep Think 的更新不过数日,却直接刷新了 AI 领域的性能天花板。此前谷歌 CEO 桑达尔・皮查伊在印度 AI 峰会上遭遇小插曲,而此次新品的精准发布,无疑为谷歌在 AI 赛道的竞争添上了重磅筹码。这款模型被谷歌定义为解决复杂问题的基础底座,专为「一个简单答案远远不够」的任务而生,其核心推理能力实现史诗级飞跃,还凭借能打又省钱的优势,让硅谷 AI 战局迎来全新变局,就连 OpenAI 联创 Andrej Karpathy 都直言,应用商店的时代即将结束。
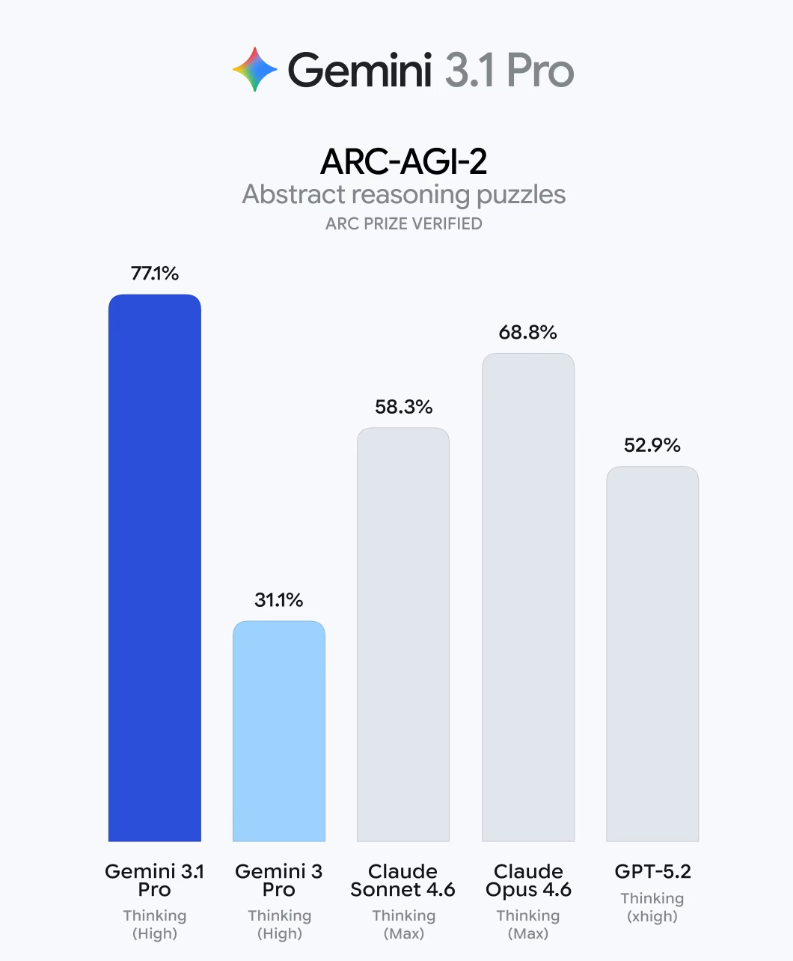
Gemini 3.1 Pro 的性能表现堪称「屠榜封神」,在衡量模型全新逻辑模式解决能力的 ARC-AGI-2 抽象推理测试中,该模型拿下 77.1% 的 ARC Prize 验证成绩,是上一代 Gemini 3 Pro(31.1%)的两倍多,同时直接压过 Anthropic 的 Opus 4.6(68.8%)和 OpenAI 的 GPT-5.2(52.9%);在 ARC-AGI-1 测试中,它更是取得了 98% 的接近满分成绩。在其他核心基准测试中,Gemini 3.1 Pro 同样表现亮眼,科学知识测试 GPQA Diamond 斩获 94.3%,智能体类基准 MCP Atlas 和 BrowseComp 分别拿下 69.2% 和 85.9%;多语言问答基准 MMMLU 达到 92.6%,长上下文性能测试 MRCR v2(8-needle)的 128k 平均语境下得分 84.9%,还独家支持 1M Token 的极限测试并取得 26.3% 的成绩,而 GPT-5.2 和 Opus 4.6 对此均未提供支持。
编程能力方面,Gemini 3.1 Pro 实现了断层领先,竞争性编程基准 LiveCodeBench Pro 的 Elo 评分达到 2887,远超 Gemini 3 Pro 的 2439 和 GPT-5.2 的 2393;SWE-Bench Verified 智能体编码测试中,其 80.6% 的成绩与 Opus 4.6 的 80.8% 基本持平;Terminal-Bench 2.0 智能体终端编码测试拿下 68.5%,压制了专攻代码的 GPT-5.3-Codex(64.7%)。在长周期专业任务基准 APEX-Agents 中,该模型以 33.5% 的成绩傲视群雄,远超 Opus 4.6 的 29.8% 和 GPT-5.2 的 23.0%。第三方知名分析机构 Artificial Analysis 的智能指数评测中,Gemini 3.1 Pro 强势登顶,总分比 Opus 4.6 高 4 分,且完成测试的成本不到 Opus 4.6 的一半;同时,相较于 Gemini 3 Pro,3.1 Pro 的幻觉率还实现了大幅下降,进一步提升了模型的实用性。
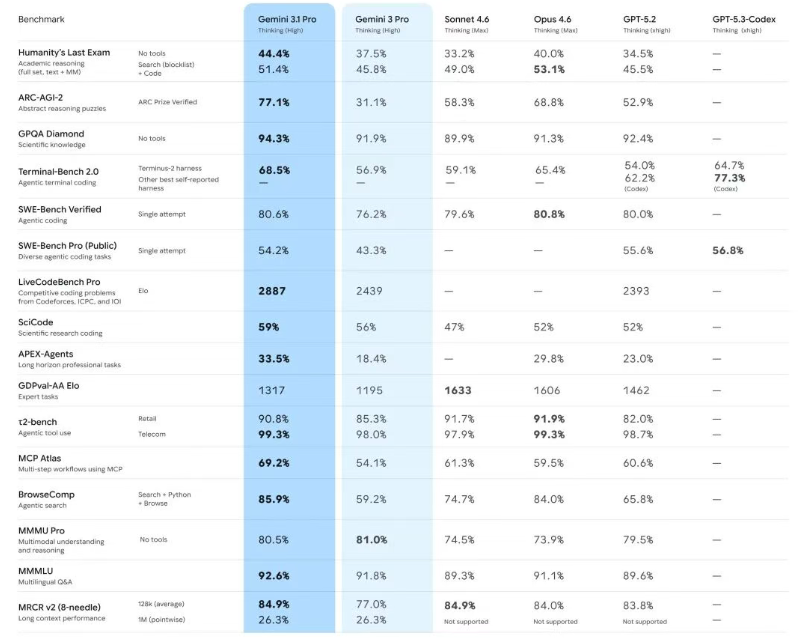
当然,Gemini 3.1 Pro 并非在所有测试中都实现碾压,仍有部分环节稍显不足:多模态理解与推理基准 MMMU Pro 上,上代 Gemini 3 Pro 以 81.0% 的成绩略胜 3.1 Pro 的 80.5%;在启用工具支持的 Humanity's Last Exam 学术推理测试中,Opus 4.6 以 53.1% 的成绩拿下第一,这也让外界对谷歌模型工具使用效率的批评未能完全平息,该短板仍是谷歌后续需要打磨的方向。
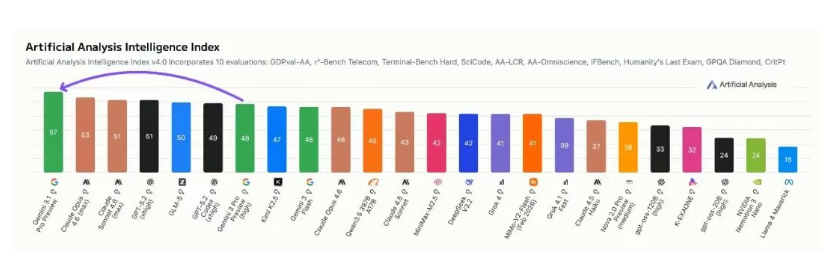
第三方知名分析机构 Artificial Analysis 则给出了相当实在的评价。3.1 Pro 在他们的智能指数里排名第一,比 Opus 4.6 高 4 分;整个测试跑下来总计使用约 5700 万 tokens,完成测试的成本不到 Opus 4.6 的一半。能打又省钱,这个组合还是很香的。
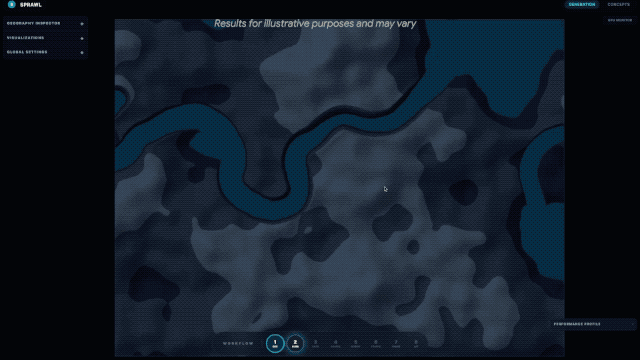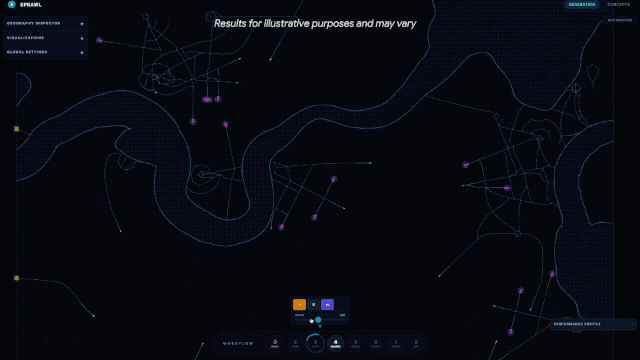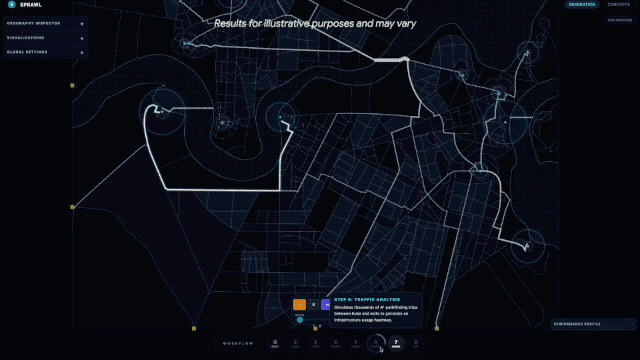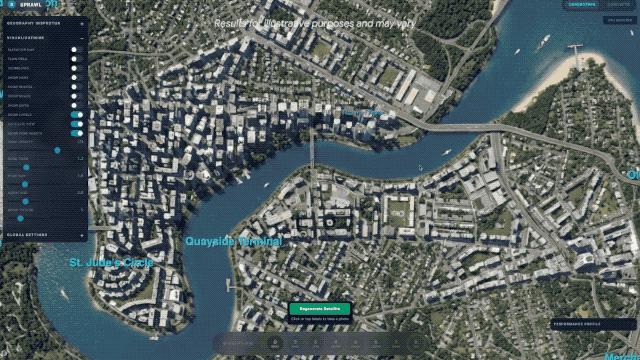
除了硬核的跑分数据,Gemini 3.1 Pro 在实际落地应用中,展现出了从「回答问题」到「完成一整套专业或创意工作流」的能力跃升,谷歌官方及网友的实测 demo 更是让人眼前一亮。谷歌 DeepMind 首席科学家 Jeff Dean 转发了 3.1 Pro 模拟城市规划的应用,该模型能从零生成可交互的城市规划界面 demo;
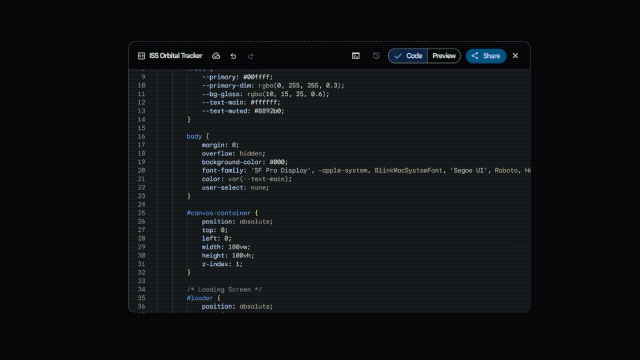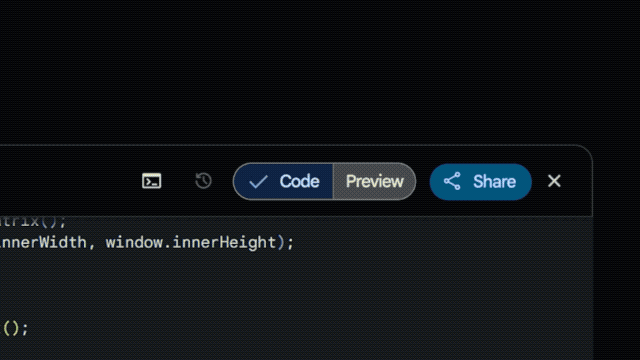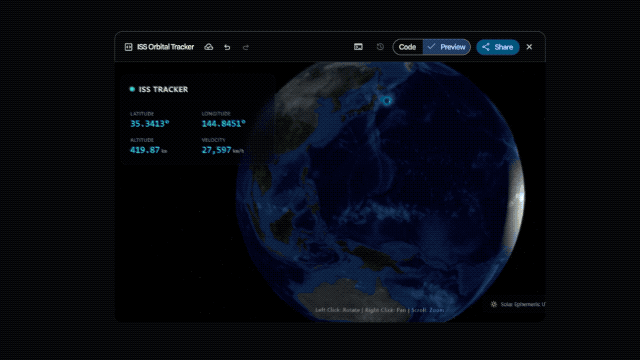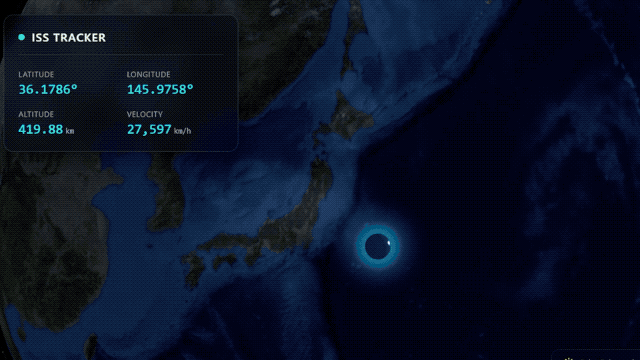
谷歌官方博客还展示了其在代码动画、复杂系统整合方面的能力,只需文字提示,它就能生成纯代码的动态 SVG,这类动画支持任意缩放且不失真,文件体积远小于传统视频,还能直接接入公开遥测数据流,搭建出实时追踪国际空间站轨道的航天仪表盘。
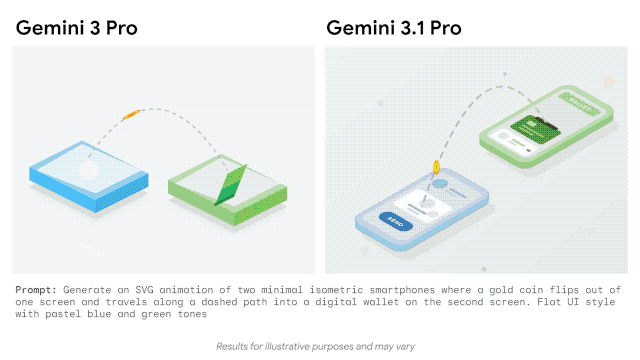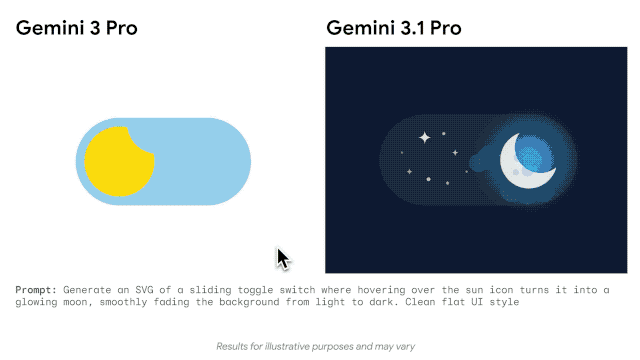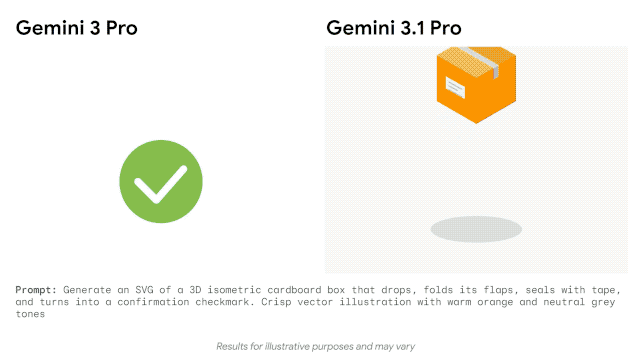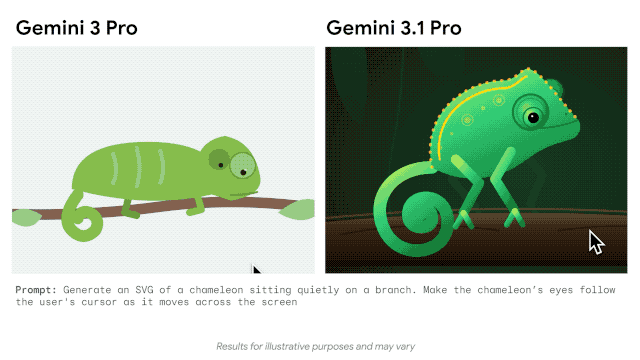
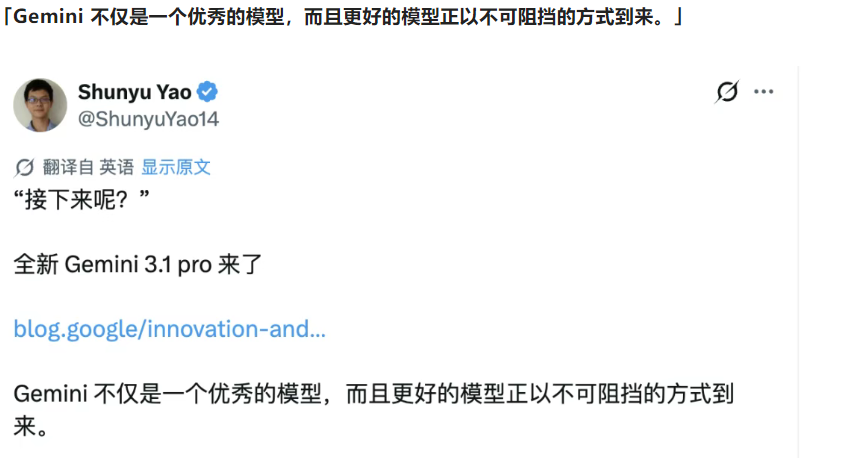
这款模型的发布,也迎来了重磅人士的站台与认可。从 Anthropic 转投谷歌 DeepMind 的清华物理系特奖得主姚顺宇,不仅参与了 Gemini 3.1 Pro 的研发,还发文为其宣传:「Gemini 不仅是一个优秀的模型,而且更好的模型正以不可阻挡的方式到来。」谷歌相关负责人也表示,从 2025 年 11 月至今,用户的真实反馈加速了 Gemini 系列模型的每一次研发迭代,从 3.0 到 3.1 的快速进步,印证了谷歌在 AI 领域的迭代速度。
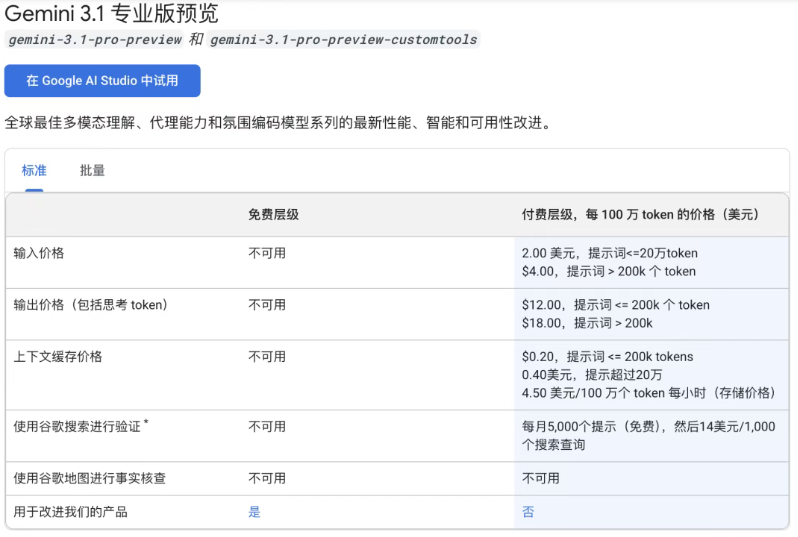
目前,Gemini 3.1 Pro 预览版已开放多渠道使用,不同用户群体均可体验:开发者可通过 Google AI Studio、Gemini API、Gemini CLI、智能体开发平台 Google Antigravity 以及 Android Studio 上手;企业用户可借助 Vertex AI 和 Gemini Enterprise 使用;普通用户能在 Gemini 应用和 NotebookLM 中体验,其中 NotebookLM 仅限 Pro 和 Ultra 订阅用户使用。价格方面,Gemini 3.1 Pro 的 API 采用分级付费模式,整体与上代 Gemini 3 Pro 保持一致,且相较于 Anthropic Opus 系列更具性价比:20 万 tokens 以内,输入单价为 2 美元 / 每百万 tokens,输出为 12 美元 / 每百万 tokens;超过 20 万 tokens 后,输入涨至 4 美元 / 每百万 tokens,输出为 18 美元 / 每百万 tokens;搜索功能每月前 5000 次免费,之后每 1000 次查询收费 14 美元。
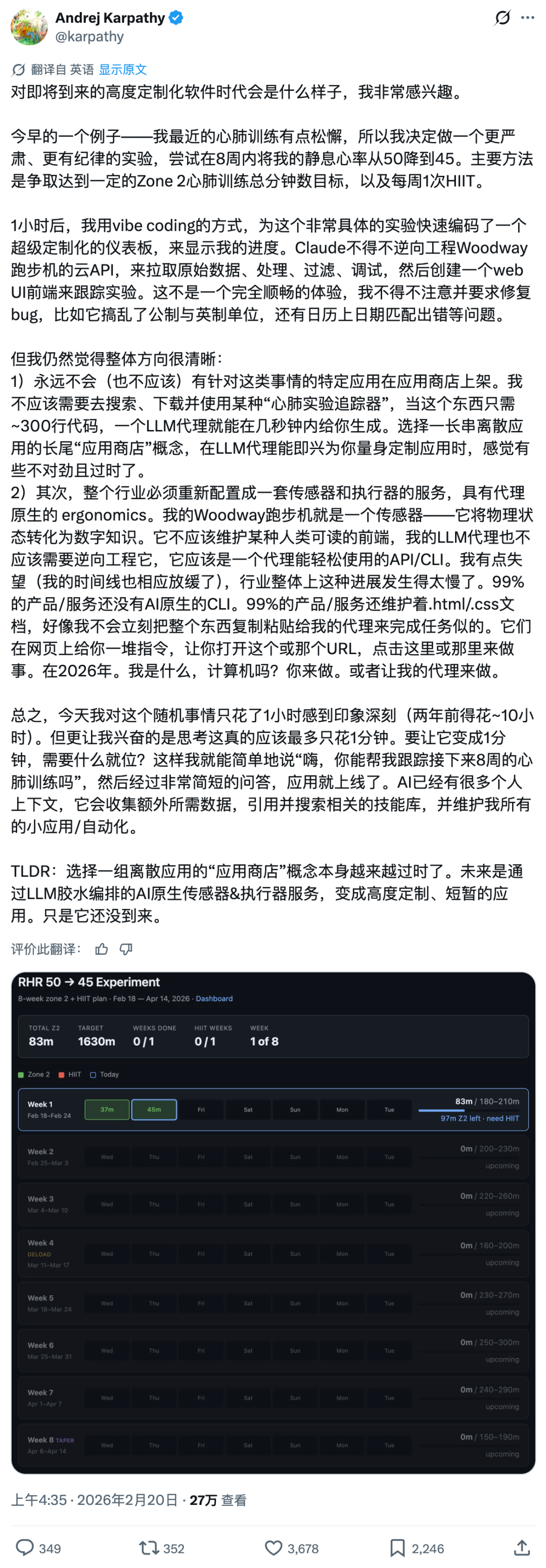
Gemini 3.1 Pro 的发布,也让行业对 AI 的未来发展有了新的思考,OpenAI 联创 Andrej Karpathy 的观点颇具代表性。他为了在 8 周内将静息心率从 50 降到 45,花 1 小时用 vibe coding 做了一个专属的心肺训练仪表盘,过程中 Claude 需要逆向工程 Woodway 跑步机的云 API,还出现了公制与英制单位混用、日历日期匹配出错等问题,虽比两年前的 10 小时大幅提升,但他认为这个过程本该只需要 1 分钟。
Karpathy 直言,应用商店的时代正在变得过时,300 行代码就能实现的专属工具,由 LLM 几秒即可生成,完全没必要做成正经 App 让用户搜索下载;他还指出当下行业的痛点,99% 的产品 / 服务仍未配备 AI 原生的 CLI,还在维护给人类看的.html/.css 前端界面,而非提供便于智能体调用的 API,导致 LLM 需要逆向工程才能获取数据,效率大打折扣。在他看来,未来的 AI 时代,是由 AI 原生的传感器和执行器服务构成,通过 LLM 胶水编排,生成高度定制、短暂的专属应用,这一趋势已近在眼前。
Gemini 3.1 Pro 的深夜突袭,直接重塑了硅谷的 AI 战局,如今重量级玩家仅剩谷歌 DeepMind 和 Anthropic 正面抗衡,此前风头无两的 OpenAI,正逐渐失去主战场上的主动权。值得注意的是,目前 Gemini 3.1 Pro 仅为预览版,谷歌大概率还会继续打磨智能体工作流再推出正式版,此番发布更像是谷歌未使出全力的一次展示。而谷歌以近乎「肌肉秀」的迭代速度告诉行业,在通往 AGI 的深水区,只有实现硬件算力与算法深度耦合的玩家,才能牢牢握住下半场的入场券,而 AI 行业的进化,从来没有终点,只会有更强的下一幕。
注:帖子内容部分图片和文章参考自APPSO