准备好使用的OCR,支持80多种语言和所有流行的书写脚本,包括拉丁文、汉字、阿拉伯文、天城文、斯拉夫文等
作者:Sec-Labs | 发布时间:
项目地址
https://github.com/JaidedAI/EasyOCR
EasyOCR项目
相关技术点
- OCR技术
- CNN卷积神经网络
- CRAFT检测模型
- DBnet检测模型
项目用途
EasyOCR是一个集成了80多种语言的OCR技术库,支持所有常见的书写脚本,包括拉丁、中文、阿拉伯、天城体、西里尔字母等。EasyOCR可以识别图像中的文字,并将其转换为文本格式,可用于文字识别、自然语言处理、电子商务等领域。
EasyOCR使用CNN卷积神经网络来训练模型,使用CRAFT检测模型和DBnet检测模型来检测文本框。EasyOCR具有较高的准确率和速度,并且可以使用自定义的模型进行训练。
EasyOCR可以在Python中使用,也可以在Huggingface Spaces中进行在线使用。EasyOCR的Web Demo可以在其网站上试用。
EasyOCR
EasyOCR是一个现成的OCR,支持80多种语言和所有流行的书写脚本,包括:拉丁、中文、阿拉伯、天城体、斯拉夫文等。
使用Gradio集成到Huggingface Spaces 🤗中。尝试Web演示:
最新消息
- 2023年5月25日 - 版本1.7.0
- 添加Apple Silicon支持(感谢@rayeesoft和@ArtemBernatskyy,请参见PR)
- 修复了几个兼容性问题
- 2022年9月15日 - 版本1.6.2
- 为DBnet添加CPU支持
- 当用户初始化DBnet检测器时才编译DBnet。
- 2022年9月1日 - 版本1.6.1
- 修复Windows的DBnet路径错误
- 添加新的内置模型
cyrillic_g2。该模型是西里尔文脚本的新默认值。
- 2022年8月24日 - 版本1.6.0
- 重构代码以支持替代文本检测器。
- 添加检测器
DBnet,请参见论文。它可以通过这样初始化来使用reader = easyocr.Reader(['en'], detect_network='dbnet18')。
- 2022年6月2日 - 版本1.5.0
- 添加CRAFT检测模型的训练器(感谢@gmuffiness,请参见PR)
- 2022年4月9日 - 版本1.4.2
- 更新依赖项(opencv和pillow问题)
- 2021年9月11日 - 版本1.4.1
- 添加训练器文件夹
- 添加
readtextlang方法(感谢@arkya-art,请参见PR) - 扩展
rotation_info参数以支持所有可能的角度(感谢abde0103,请参见PR)
- 2021年6月29日 - 版本1.4
- 说明如何训练/使用自定义识别模型
- 模型训练的示例数据集
- 针对GPU的批量图像推理(感谢@SamSamhuns,请参见PR)
- 垂直文本支持(感谢@interactivetech)。这是用于旋转文本的,不要与垂直的中文或日文文本混淆。(请参见PR)
- 以字典格式输出(感谢@A2va,请参见PR)
- 2021年5月30日 - 版本1.3.2
- 更快的贪婪解码器(感谢@samayala22)
- 修复了当文本框的纵横比不成比例时的错误(感谢iQuartic报告错误)
- 2021年4月20日 - 版本1.3.1
- 添加对PIL图像的支持(感谢@prays)
- 添加塔吉克语(tjk)
- 更新命令行的参数设置
- 添加
x_ths和y_ths以控制当paragraph=True时合并行为
- 2021年3月21日 - 版本1.3
下一步计划
- 手写文本支持
示例



安装
使用 pip 安装
安装最新稳定版:
pip install easyocr
安装最新开发版:
pip install git+https://github.com/JaidedAI/EasyOCR.git
注意1:对于Windows用户,请根据官方说明先安装torch和torchvision,官方说明请参见 https://pytorch.org。在PyTorch官网上,请确保选择您的正确的CUDA版本。如果您只想在CPU模式下运行,请选择 CUDA = None。
注意2:我们还提供了一个Dockerfile 这里。
使用方法
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # 这里只需要运行一次以将模型加载到内存中
result = reader.readtext('chinese.jpg')
输出结果将以列表格式呈现,每个元素表示一个边界框及其检测到的文本和置信度,依次展示。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]
注意1: ['ch_sim','en'] 是您想要读取的语言列表。您可以一次传递多个语言,但不是所有语言都可以一起使用。英语与每种语言兼容,并且共享公共字符的语言通常彼此兼容。
注意2: 您可以传递OpenCV图像对象(numpy数组)或图像文件的字节,而不是文件路径 chinese.jpg。原始图像的URL也是可接受的。
注意3: 行 reader = easyocr.Reader(['ch_sim','en']) 用于将模型加载到内存中。这需要一些时间,但只需要运行一次即可。
您还可以设置 detail=0 以获取简化的输出。
reader.readtext('chinese.jpg', detail = 0)
结果:
['愚园路', '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']
选择的语言的模型权重将自动下载,或者您可以从model hub手动下载它们并将它们放入 '~/.EasyOCR/model' 文件夹中。
如果您没有GPU,或者您的GPU内存较低,您可以通过添加 gpu=False 在CPU-only模式下运行模型。
reader = easyocr.Reader(['ch_sim','en'], gpu=False)
在命令行上运行
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True
训练/使用您自己的模型
对于识别模型,请阅读此处。
对于检测模型(CRAFT),请阅读此处。
实现路线图
- 手写支持
- 重构代码以支持可交换的检测和识别算法 API应该像这样简单
我们的想法是能够将任何最先进的模型插入到EasyOCR中。有很多天才试图制作更好的检测/识别模型,但我们并不试图成为天才。我们只想让他们的作品快速地免费对公众可用…(好吧,我们相信大部分天才希望他们的作品尽可能快地产生积极的影响)。管道应该是下图所示的样子。灰色插槽是可更改的淡蓝色模块的占位符。reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
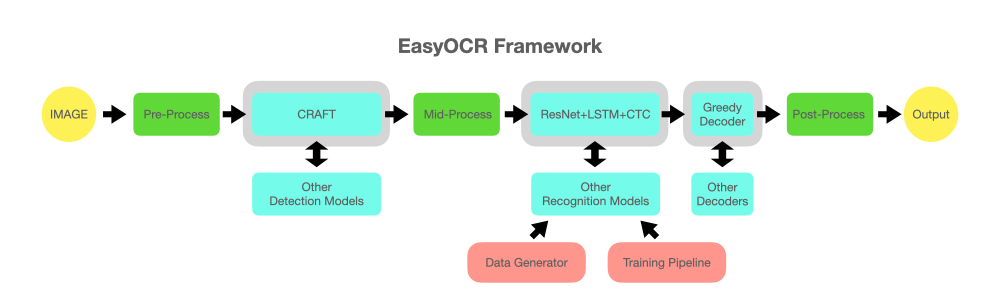
致谢与参考资料
本项目基于多篇论文和开源代码。所有深度学习的执行都基于Pytorch。:heart:
检测执行使用CRAFT算法,来自这个官方仓库 和他们的论文 (感谢@clovaai的@YoungminBaek)。我们也使用了他们的预训练模型。训练脚本由@gmuffiness提供。
识别模型是一个CRNN(论文)。它由3个主要组成部分组成:特征提取(我们目前正在使用Resnet)和VGG,序列标记(LSTM)和解码(CTC)。识别执行的训练流程是deep-text-recognition-benchmark框架的一个修改版本(感谢@clovaai的@ku21fan)。 这个仓库是一个值得更多赞誉的宝石。
Beam search代码基于这个仓库和他的博客。(感谢@githubharald)
数据合成基于TextRecognitionDataGenerator。(感谢@Belval)
关于CTC的好读物可以在这里找到distill.pub。
想要贡献?
让我们共同推进人类,使AI可用于每个人!
有三种贡献方式:
编码人员: 请发送一个小的错误/改进的PR。对于更大的问题,请先通过打开问题与我们讨论。标有'PR WELCOME'的可能存在错误/改进问题的列表。
用户: 告诉我们EasyOCR如何使您/您的组织受益,以鼓励进一步发展。还可以在问题部分发布失败案例,以帮助改进未来的模型。
技术领袖/大师: 如果您发现这个库有用,请传播这个消息!(请参见Yann Lecun的帖子关于EasyOCR)
新语言请求指南
要请求新语言,我们需要您发送一个带有以下两个文件的PR:
- 在文件夹easyocr/character中,我们需要包含所有字符列表的'yourlanguagecode_char.txt'文件。请参见该文件夹中其他文件的格式示例。
- 在文件夹easyocr/dict中,我们需要包含您语言中的单词列表的'yourlanguagecode.txt'文件。平均而言,每种语言有~30000个单词,更流行的语言有超过50000个单词。在这个文件中,更多是更好的。
如果您的语言具有独特的元素(例如1.阿拉伯语:字符在彼此附着时改变形式+从右到左书写2.泰语:有些字符需要在线上方,有些需要在线下方),请尽可能地向我们提供相关信息和/或有用的链接。关注细节是实现真正工作的系统的重要因素。
最后,请理解我们的优先级将不得不优先考虑流行的语言或其中相互共享大部分字符集的语言集(也请告诉我们是否适用于您的语言)。我们至少需要一周时间开发一个新模型,因此您可能需要等待一段时间才能发布新模型。
请查看开发中的语言列表
Github问题
由于资源有限,超过6个月的问题将自动关闭。如果问题很关键,请重新打开问题。## 商务合作