🤖 自托管、社区驱动、本地的OpenAI兼容API。可在消费级硬件上替代OpenAI运行LLMs。无需GPU
作者:Sec-Labs | 发布时间:
项目地址
https://github.com/go-skynet/LocalAI

项目介绍
🤖 自托管、社区驱动、本地的OpenAI兼容API。可在消费级硬件上替代OpenAI运行LLMs。无需GPU。LocalAI是一个RESTful API,用于运行ggml兼容模型:llama.cpp、alpaca.cpp、gpt4all.cpp、rwkv.cpp、whisper.cpp、vicuna、koala、gpt4all-j、cerebras等等!
如何工作
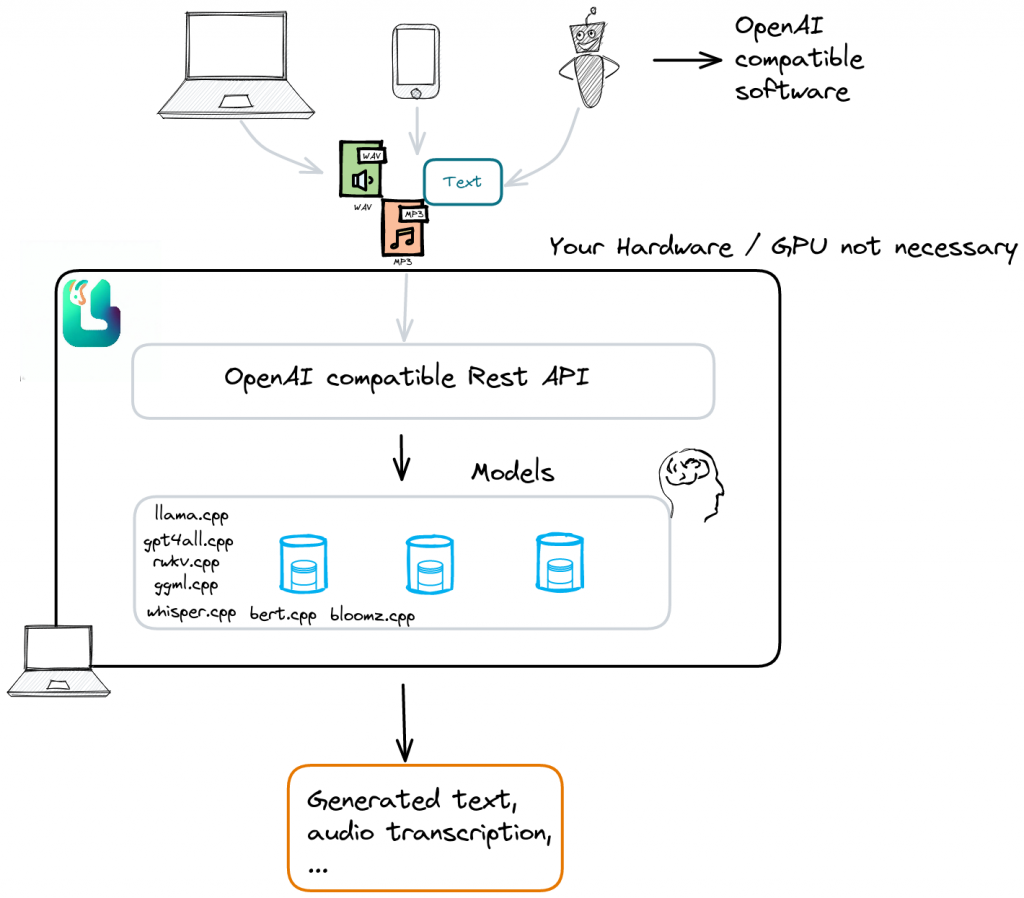
LocalAI是一个与OpenAI API规范兼容的、可用于本地推理的即插即用的REST API。它允许在本地或企业内部使用消费级硬件运行模型,支持多个与ggml格式兼容的模型系列。请参阅下面的模型兼容性表格以获取支持的模型系列列表。
- 本地的、OpenAI的备选REST API。您拥有自己的数据。
- 支持多个模型,包括音频转录、使用GPT进行文本生成,以及使用稳定扩散(实验性功能)进行图像生成。
- 首次加载后,将模型保留在内存中,以加快推理速度。
- 支持提示模板。
- 不使用外部Shell,而是使用C++绑定进行更快的推理和更好的性能。
- 不需要GPU。也不需要互联网访问。可选择在与
llama.cpp兼容的LLMs中启用GPU加速。请参阅构建说明。
LocalAI是一个由社区驱动的项目,致力于让任何人都能够使用人工智能。欢迎任何贡献、反馈和PR!它最初由SpectroCloud OSS Office的mudler创建。
LocalAI使用C++绑定来优化速度。它基于llama.cpp、gpt4all、rwkv.cpp、ggml、whisper.cpp进行音频转录,以及bert.cpp进行嵌入。
请参阅示例以了解如何集成LocalAI。
新闻
- 2023年5月17日: 发布 v1.12.0!🔥🔥 包括对
llama.cpp兼容模型和图像生成的CUDA(#258)支持。 - 2023年5月16日: 🔥🔥🔥
llama.cpp后端实验性支持CUDA(#258),master分支实现稳定扩散的CPU图像生成(#272)。
现在LocalAI也能生成图像了:
| mode=0 | mode=1 (winograd/sgemm) |
|---|---|
|
|
|


- 2023年5月14日: 发布 v1.11.1!修复了
rwkv后端的问题。 - 2023年5月13日: 发布 v1.11.0!🔥 更新了
llama.cpp绑定:此更新包含了模型文件的重大更改(ggerganov/llama.cpp#1405),旧的模型仍可与gpt4all-llama后端兼容。 - 2023年5月12日: 发布 v1.10.0!🔥🔥 更新了
gpt4all绑定。添加了对GPTNeox(实验性)、RedPajama(实验性)、Starcoder(实验性)、Replit(实验性)和MosaicML MPT的支持。现在embeddings端点支持令牌数组。请查看langchain-chroma示例!注意 - 此更新不包括 ggerganov/llama.cpp#1405,该更改会导致模型不兼容。 - 2023年5月11日: 发布 v1.9.0!🔥 重要的whisper更新(#233 #229),扩展了gpt4all模型系列的支持(#232)。Redpajama/dolly实验性(#214)
- 2023年5月10日: 发布 v1.8.0!🔥 添加了对
bert.cpp的快速准确嵌入支持(#222) - 2023年5月9日: 添加了对转录端点的实验性支持(#211)
- 2023年5月8日: 支持使用
llama.cpp后端的模型进行嵌入(#207) - 2023年5月2日: 支持
rwkv.cpp模型(#158),以及/edits端点 - 2023年5月1日: 支持在
llama.cpp后端使用SSE流的令牌(#152)
Twitter:@LocalAI_API 和 @mudler_it
模型兼容性
它与llama.cpp支持的模型兼容,并且还支持GPT4ALL-J和cerebras-GPT(使用ggml)。
已测试的模型有:
- Vicuna
- Alpaca
- GPT4ALL
- GPT4ALL-J(无需更改)
- Koala
- cerebras-GPT(使用ggml)
- WizardLM
- RWKV模型使用rwkv.cpp
注意:您可能需要将一些旧模型转换为新格式,有关指示,请参阅llama.cpp中的README,例如运行gpt4all。
标签:工具分享