让ChatGPT在几个小时内使用单个GPU帮助您创建自己的聊天机器人!
作者:Sec-Labs | 发布时间:
项目地址
https://github.com/project-baize/baize-chatbot

新闻
- 2023年4月21日 我们现在有一个脚本,可以将LoRA权重合并到标准的HF模型中,这样您就可以在HF支持的任何地方使用它了!
Baize是什么?
Baize是一个使用LoRA训练的开源聊天模型。它使用让ChatGPT自己聊天生成的10万个对话。我们还使用了Alpaca的数据来提高其性能。我们已发布7B、13B和30B模型。更多细节请参阅论文。
为什么叫做Baize?
Baize(白泽)是中国民间传说中的一种神话生物,能够讲人类语言,知道一切。这正是我们期望从一个聊天模型中得到的。
概览
⚠️ 所有的模型权重和数据仅用于研究目的。商业用途严格禁止。我们对使用我们的数据、代码或权重不承担任何责任或义务。
这是Baize项目的代码库,旨在使用LLaMA构建聊天模型。该代码库包含:
- 来自Quora、StackOverFlow和MedQuAD问题的54K/57K/47K 对话
- 收集自我聊天数据的代码
- 训练Baize的代码
- 聊天模型演示的代码(从ChuanhuChatGPT进行了分支)
模型发布
- Baize-7B
- Baize-13B
- Baize-30B
- Baize Healthcare-7B
- Baize Chinese-7B(即将推出)
社区模型和数据
演示


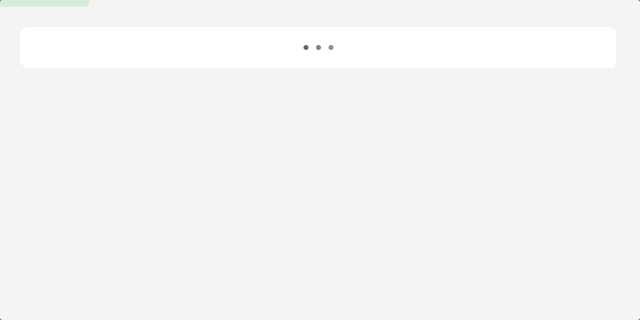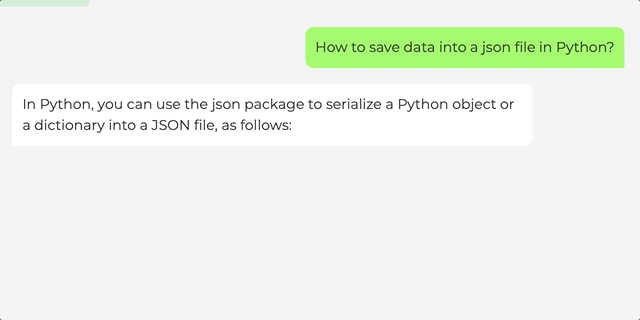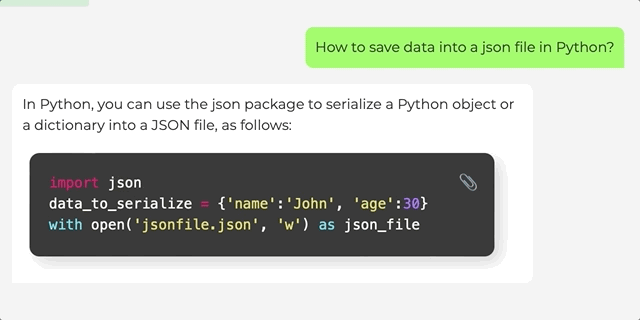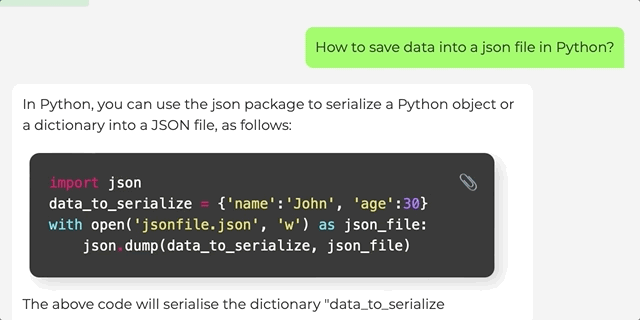
您可以在本地主机上运行,也可以访问在线演示。演示从Hugging Face模型中心获取LLaMA模型和LoRA权重,然后运行一个用户友好的Gradio界面进行聊天。
本地运行方法
首先,请确保您的Python版本为3.8,并使用以下命令安装所需的软件包:
cd demo
pip install -r requirements.txt您可以使用以下命令在本地主机上运行该模型:
# 我们假设您已获得使用LLaMA的权限。以下LLaMA权重来自第三方。
base_model=huggyllama/llama-7b
lora_model=project-baize/bGPU VRAM要求
| 推理(不包括int8) | |
|---|---|
| Baize-7B | 16GB |
| Baize-13B | 28GB |
| Baize-30B | 67GB |
如果您的GPU具有较小的VRAM,则可以通过传递8bit参数进行推理:
python app.py $base_model $lora_model 8bit如何复现
设置
- 安装依赖项
数据收集
您可以使用我们的发布的数据,或使用以下命令从ChatGPT收集数据:
num_process=10 # 收集数据的进程数
max_total_tokens=500000 # 设置要收集的数据的最大标记数
api_key=xxxxxxxxxxxxxxxxx # 设置您的OpenAI API密钥
for ((i=0; i<$num_process; i++))
do
python collect.py $api_key $max_total_tokens $i $num_process stackoverflow &
python collect.py $api_key $max_total_tokens $i $num_process quora &
python collect.py $api_key $max_total_tokens $i $num_process medical &
done收集数据后,您可以使用以下命令预处理数据:
python preprocess.py stackoverflow
python preprocess.py quora
python preprocess.py medical使用您自己的数据
如果您有特定的数据集要用作ChatGPT自我聊天的种子,您可以简单地修改collect.py以加载自己的数据。
训练
微调代码是为在A100-80G GPU上运行设计的。finetune.py脚本接受三个参数:基础模型大小(即7B、13B或30B)、批量大小、学习率和数据集。请注意,总批处理大小固定为64(可以在这里进行修改),这里的批量大小是梯度累积之前每个设备的批量大小。如果您在具有较小VRAM的GPU上进行训练,请将其设置为较小的值。
# 对于7B模型(约需要9小时)
python finetune.py 7b 32 0.0002 alpaca,stackoverflow,quora
# 对于13B模型(约需要16小时)
python finetune.py 13b 16 0.0001 alpaca,stackoverflow,quora
# 对于30B模型(约需要36小时)
python finetune.py 30b 8 0.00005 alpaca,stackoverflow,quoraGPU VRAM消耗
使用以上设置:
| 训练(使用int8) | |
|---|---|
| Baize-7B | 26GB |
| Baize-13B | 25GB |
| Baize-30B | 42GB |
有问题?请参见此问题。
将LoRA合并到LLaMA
现在,您可以轻松地将训练好的LoRA权重合并到LLaMA模型中,这样您就可以将其与支持标准Hugging Face API的所有内容一起使用!
以下是将baize-lora-7B合并到LLaMA-7B的示例。
python merge_lora.py \
--base huggyllama/llama-7b \
--target ~/model_weights/baize-7b \
--lora project-baize/baize-lora-7B