使用Web缓存欺骗接管ChatGPT账户
作者:Sec-Labs | 发布时间:
相关资料
https://twitter.com/naglinagli/status/1639343866313601024
推文内容
@OpenAI团队刚刚修复了我几个小时前报告的关于#ChatGPT的一个重要账户接管漏洞。攻击者可以接管某人的账户,查看他们的聊天记录并访问他们的账单信息,而被攻击者不会察觉到。详见上面的视频
这个漏洞叫做“Web缓存欺骗”,我将详细解释如何绕过https://chat.openai.com上的现有保护。需要注意的是,该问题已经得到修复,并且我收到了来自@OpenAI团队的“Kudos”电子邮件,以表彰我的负责任披露行为。

在探索处理ChatGPT身份验证流程的请求时,我正在寻找可能暴露用户信息的任何异常情况。以下GET请求引起了我的注意:https://chat.openai[.]com/api/auth/session
基本上,每当我们登录到ChatGPT实例时,该应用程序都会从服务器获取我们的帐户上下文信息,例如我们的电子邮件、姓名、图像和访问令牌,如下所示:
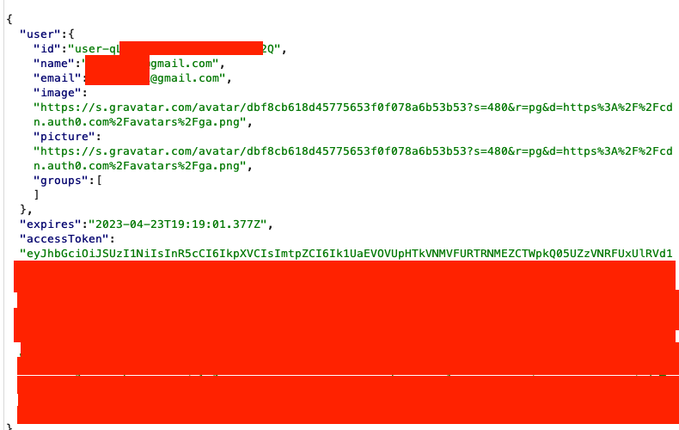
泄露此类信息的常见用例是利用服务器上的“Web缓存欺骗”,我已经在多次实际黑客事件中成功找到它,它也在各种博客中有详细记录,例如:
https://omergil.blogspot.com/2017/02/web-cache-deception-attack.html
从高层次的视角看,这个漏洞非常简单,如果我们成功地强制负载均衡器在我们特定的构造路径上缓存我们的请求,我们将能够从缓存的响应中读取受害者的敏感数据。但在这种情况下不是那么直截了当。
为了使漏洞利用成功,我们需要让CF-Cache-Status响应确认缓存了数据,并将其提供给同一区域内的下一个请求。
但是我们收到的是“DYNAMIC”响应,这不会缓存数据。

现在,进入有趣的部分。
当我们部署Web服务器时,“缓存”的主要目标是能够更快地向最终用户提供我们的重型资源,主要包括JS / CSS /静态文件,
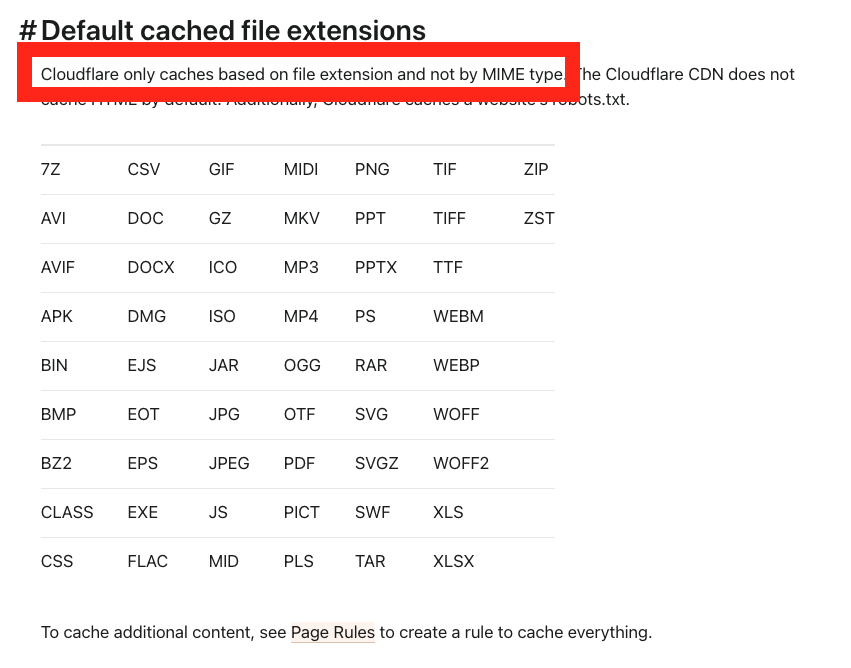
CloudFlare有一个默认扩展名列表,这些扩展名会在其负载均衡器后面被缓存。
https://developers.cloudflare.com/cache/about/default-cache-behavior/
Cloudflare只根据文件扩展名缓存,而不是根据MIME类型”❗️
基本上,如果我们设法以下面指定的某个文件扩展名之一加载相同的端点,同时强制其保留敏感的JSON数据,我们就能够将其缓存。
因此,我要尝试的第一件事是将文件扩展名附加到端点上获取资源,并查看它是否会抛出错误或显示原始响应。
chat.openai[.]com/api/auth/session.css -> 400 ❌
chat.openai[.]com/api/auth/session/test.css - 200 ✔️

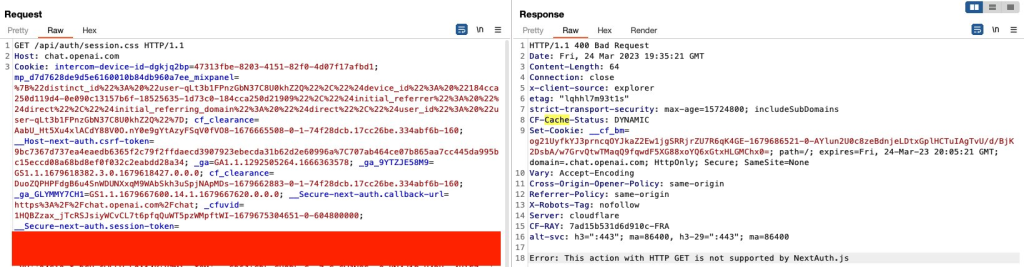
这非常有希望,
仍然会用css文件扩展名返回敏感JSON,这可能是由于正则表达式匹配失败或者只是他们没有将此攻击向量考虑在内。现在只剩下一件事要检查,是否可以从LB缓存服务器中得到一个“HIT”。
攻击流程:
- 攻击者构造了/api/auth/session端点的专用.css路径。
- 攻击者分发链接(直接发送给受害者或公开发布)。
- 受害者访问合法链接。
- 响应被缓存。
- 攻击者收集JWT凭证。
获取授权。
完整截图
