规避分类(Evadere Classifications)
作者:Sec-Labs | 发布时间:
规避分类
介绍
逃避一词源自拉丁语“evadere”,意思是“逃避,逃避”。 国防部将逃避定义为——“孤立的人员避免被俘虏以成功返回友好控制区的过程。”
我经常在 Twitter 或新博客上看到谈论新 规避 或 绕过 技术的帖子。 无论是否明确说明。 我看过讨论 UAC Bypass、新的进程注入方法或 LSASS 转储的帖子,它们将绕过某些传感器甚至发布的精确检测(起初这听起来不像是一种规避技术,但这将稍后在博客中解释)。
这让我思考—— 逃避 或 绕过 的真正含义是什么? 这些规避技术是否属于不同的类别? 最后,如果要将这些技术归类——检测工程师如何利用这些技术开展业务?
捕获执行的规避类型将有助于识别环境中的差距,这反过来又将帮助工程师了解该差距是否是他们可以修复的,或者是否是他们无法控制的。 一旦确定了这些差距,就可以创建优先级。
例如:假设执行红队交战并且红队队员 躲避 传感器,则有 3 种情况可能会生效:
- 传感器未收集与事件关联的正确数据
- 传感器具有红队逃避的内置检测(工程师不了解检测逻辑是什么)
- 传感器收集正确的遥测数据以提供对活动的可见性,但工程师现在必须创建自定义检测。
我将在下一节讨论这个问题,但是一旦确定了上述正确的场景,就可以设置优先级。
对于场景 2 和 3,如果数据存在,则为创建检测设置优先级应该很高。
对于场景 1,如果传感器不收集与事件关联的数据,则应优先解决此问题。
在这篇博文中,我将使用术语 逃避 来指 代逃避 和 旁路 术语,因为它们的定义可以互换。
规避的类型
注意: 在整篇文章中,我将引用适用于 保真度漏斗的 术语,这是由 Jared Atkinson 创建的映射。 我强烈建议在继续之前阅读他关于该方法的文章,以及他在 SO-CON 上的演讲—— 重新思考检测工程 ,其中探讨了如何通过利用基本条件对误报/漏报进行分类。
最初,在深入研究这种方法时,我想确保我将这些机会应用于已经创建的映射以帮助理解。 为了实现这一点,我选择将每个逃避机会与忠诚漏斗的一部分联系起来。 这使我能够更轻松地对这些方法进行分类,同时帮助我确定每种方法的优先级。 例如,如果一个环境更关注他们的检测过程,他们会希望关注与漏斗的那一部分相关的规避机会。 然而; 无论组织想要关注漏斗的哪一部分,我都建议首先关注与数据收集部分相关的机会,因为它贯穿整个漏斗。 当涉及到这种方法时,这就是我选择开始关注的地方。
当我将重点放在漏斗的数据收集部分时,我决定花大量时间在数据/传感器工具上。 我经常看到有人说“这种攻击方法绕过了传感器 x”,然后我的问题就变成了“它绕过传感器的日志记录功能、传感器/EDR(端点检测和响应工具)的默认检测,还是您自定义的检测?”到位了吗?” 在分解这些东西时,确定了 2 种不同的规避技术以及 2 种子技术:
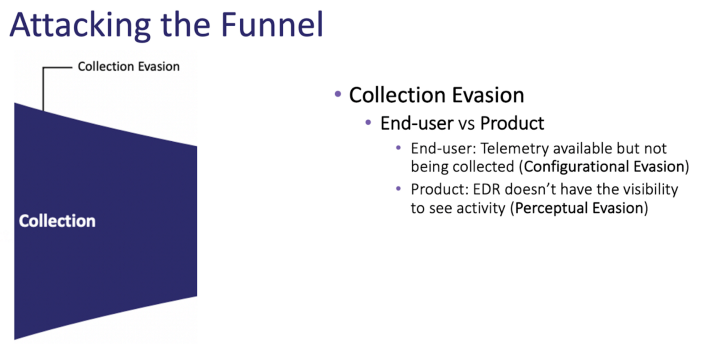
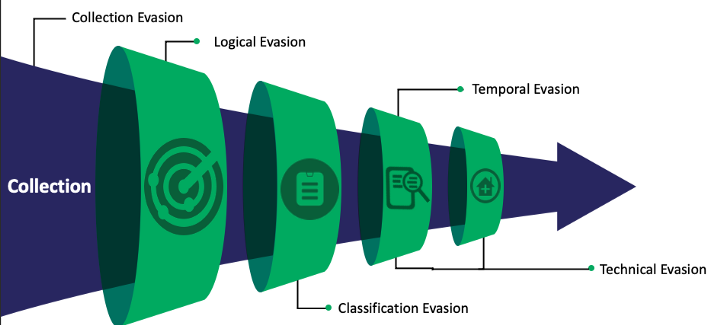
Collection Evasion 分为两种不同的子技术: 最终用户 和 产品 。 将这两种子技术分开是有价值的,即使它们属于相同的规避类别。 一种方法由客户/分析师控制: 最终用户 。 数据在那里供您收集,启用只需要发生。 另一种方法: 产品 是客户/分析师零控制的东西。 没有人可以控制传感器是否能够收集,这取决于该工具的开发人员。 细目如下:
最终用户与产品:
- 最终用户:遥测可用但未被收集( 配置规避 )
场景 :传感器具有提供行为可见性的数据,但当前的日志记录配置阻止了覆盖
- 产品:传感器无法看到活动( 感知逃避 )
场景 :操作利用低级系统调用来执行行为,但传感器挂钩 Win32 API 以实现日志记录功能
在确定了最初的规避方法后,我问自己——“如果传感器的内置检测逻辑或检测工程师的自定义检测逻辑被规避怎么办?” 这个话题很有趣,因为很多时候分析师并不了解 EDR 供应商的内置检测逻辑。 如果不深入了解这一点,工程师如何知道环境中涵盖的内容? 由于工程师对这种策略几乎一无所知,因此这是他们无法控制的。 然而; 这并不意味着这些策略不会为组织提供价值,但在应用时会产生差距。 在创建自定义检测时,尽我们所能识别这些差距是有益的。 自定义检测是工程师可以控制的。 这些检测是建立在某种策略或方法之上的。 在查看命令行参数和某些二进制文件时,检测是否准确? 是否更广泛地寻找攻击者可以利用的特定 API? 有很多策略,但重要的是要注意——没有检测是万无一失的。 他们都有差距。 这些差距是攻击者的逃避机会。 这种逃避机会将被归类为 逻辑规避 ,分解如下:
逻辑规避:
- 攻击者逃避检测实施的分析逻辑
场景:有意 的——对手发现/利用了适当的逻辑集
场景:无意 的——检测工程师实施了一个检测,其中有未被覆盖的漏洞,允许攻击者进行这种规避行为

过去的几种规避技术属于数据收集或检测工程,但检测和响应管道的其他部分是否存在规避机会? 说——分类。
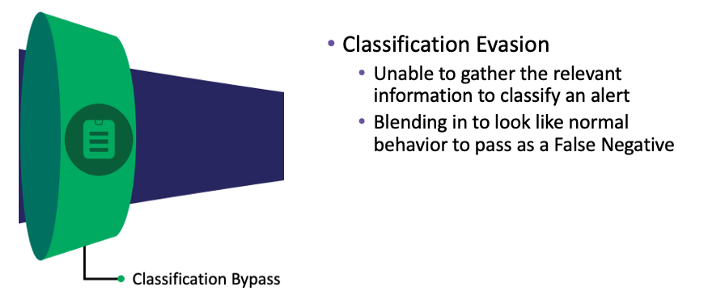
在深入探讨可应用于 Triage 的规避机会之前,让我们首先定义我的意思。 在检测和响应管道中,分类旨在将上下文添加到由检测中的基本条件捕获的数据集。 这些上下文片段被应用到数据集,给定应用的不同属性,为每个数据集分配一个优先级,然后将其传递给调查,以便分析师有一个预先应用的知识库附加到他们给出的警报。 这使分析师能够更快地响应警报。 然而; 有一种规避技术可以应用于此 Triage 件。 当上下文无法应用于数据集或难以区分此数据集与“正常”行为不同时,此技术适用。 这种规避技术称为: 分类规避 ,分解如下:
分类规避:
- 无法收集相关信息来对警报进行分类
场景 :想查看服务是否是远程创建的,但没有收集网络数据
- 混入看起来像正常行为以作为假阴性传递
- 这是一个特定于组织的示例
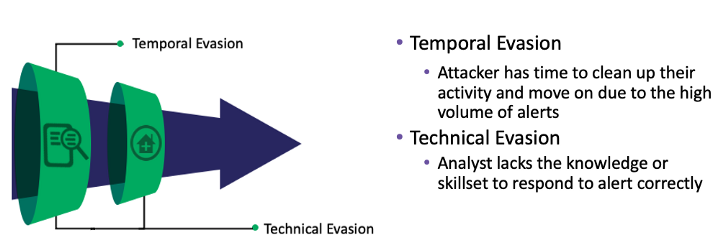
分类完成后,想象一下触发大量警报并且分析师感到警报疲劳的场景? 对手是否有机会清理他们的恶意活动或有足够的时间执行其他行为,从而允许他们进一步迁移到环境中? 这是 Fidelity Funnel 试图确定的东西,如何获取 1000000 个事件并将它们集中到 10 个潜在客户。 除非那并不总是适用。 警报的逻辑可能非常广泛,导致触发大量警报,在经过分类后,分析师有大量数据需要查看,不仅会发生警报疲劳,而且数据分析瘫痪也会发生。 如果执行得当,调查过程需要时间。 分析师必须摄取基础数据集,通过分类应用添加的上下文片段,然后如果他们需要的所有数据都没有做出决定,他们必须去获取该数据以做出升级此警报或关闭警报。 适用于此场景的规避技术是: 时间规避 和细分如下:
时间回避:
- 由于大量警报,攻击者有时间清理他们的活动并继续前进
- 攻击者完成任务的能力快于防御者补救任务的能力
场景: 防御者检测到攻击,但无法迅速采取行动阻止攻击者得逞
接下来让我们谈谈警报触发、上下文添加到数据集并且分析师成功接收到此事件的情况。 如果分析师不具备有效理解警报的技术技能,进而影响他们正确响应的能力,会发生什么情况? 这并不意味着这些技能无法学习,但在确定可能的逃避机会时必须考虑到这一点。 缺乏技术理解可能来自检测文档中知识的缺乏或分析人员技术深度的当前状态。 这种逃避机会可以应用于调查和响应。 这种机会可以定义为 技术规避 ,细分如下:
技术规避:
- 分析师缺乏正确响应警报的知识或技能
场景: 可疑的二进制文件落在主机上,但分析师没有适当的技能来反转二进制文件以确定它是否是恶意软件
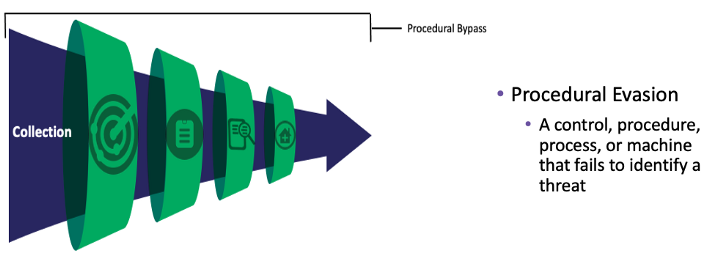
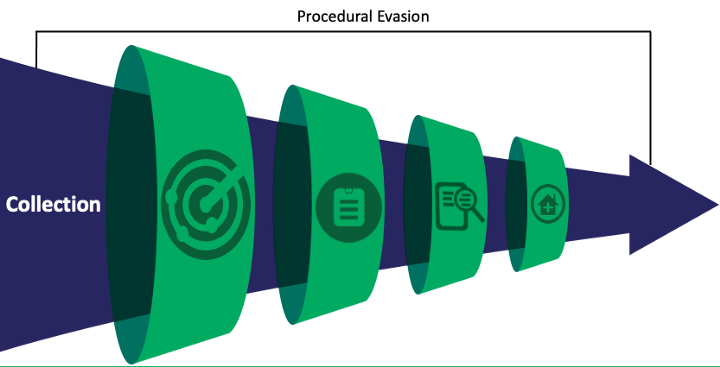
在了解了这种方法之后,我很快意识到攻击者还有其他机会可以规避当前的防御措施,无论是数据收集、警报逻辑、分类、调查还是响应。 仅仅是这些过程中的一个被破坏、控制配置错误、机器离线、传感器被篡改,或者组织根本没有以稳健的方式执行这些程序之一。 所有这些可能性都会导致无法识别威胁。 这将适用于整个漏斗,可以归类为 程序规避 ,细分如下:
规避程序:
- 无法识别威胁的控制、程序、过程或机器
场景 1: 传感器关闭,无法收集数据
场景 2: 查询特定注册表项时 SACL 配置错误,查询了该注册表项,但未收集任何见解 (MSHTA)
场景 3: 无法识别的检测差距,导致与技术覆盖相关的错误安全感
一旦我们将所有这些不同的规避机会结合起来,与漏斗的相关性就可以可视化为:
结论
我认为随着时间的推移,某些术语由于重新定义或误用而开始失去意义。 我们看到很多术语,甚至在 InfoSec 之外。 规避和旁路似乎属于这一类。 也许并不是它们失去了意义,而是在谈论这个主题时必须应用更具体的分类。 当谈到这个话题时,这激起了我的兴趣。 不仅——我们如何对这些规避方法进行分类,以便检测工程师可以更好地利用它们,而且还设置了一个通用术语,供 SOC 和所有子团队(威胁研究、红队、检测工程师等)使用.
重要的是要记住,无论某人是红队、检测工程师、威胁狩猎队等的一员,目标始终应该是向 SOC 输出一些东西。 如果术语被误解并且每个人对一个词都有不同的定义,那么对输出的期望可能会丢失。
我敢肯定,随着时间的推移,还会有更多内容添加到其中,但这是令人兴奋的部分。 一切都在进化,注定要进化。