狂雨cms采集规则编写
作者:yanling | 发布时间:
【篇前语】看到很多人不会写采集规则,官方的教程也并没有那么详细,索性写一篇,因为我也是小白,搭建还没两天,写的不完整的地方望海涵
【注意】官方明确表明该cms无法采集小说内容分页及文章分页,仅可采集不分页的,api也并没有完整的官方文档,所以api的使用希望大家自己研究下哈!
首先注意,类似红框那种带分页的章节目录,以及内页章节1(1/2)这种是无法采集的

只能采集这种,章节和内容不分页的
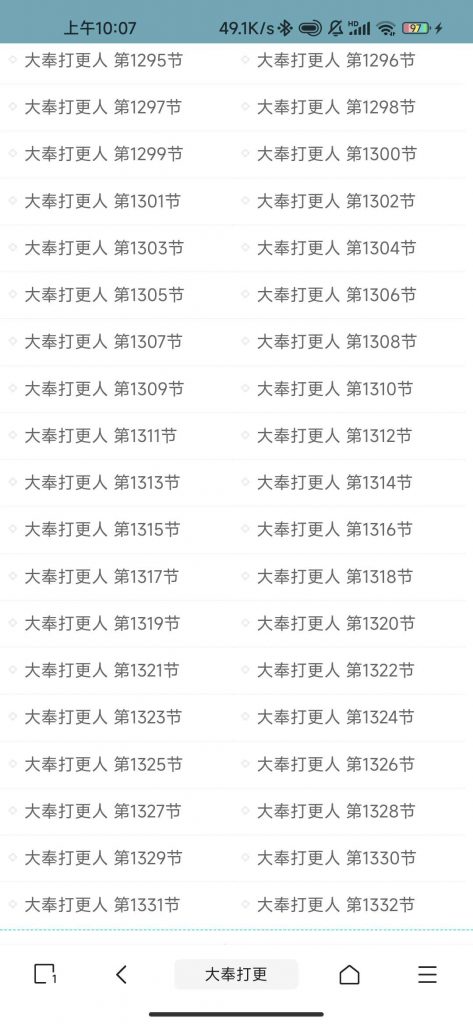
1.点击采集管理-添加采集就会出现这个页面
规则名称自己拟定,其他基本保持默认就可以,图片本地化可以避免源站挂了你图片也挂了(没什么用,大部分封面都是广告)

2.列表网址,如http://xxx.com/sort/1/1.html
那么1.html的1就是变量,我们替换为通配符,那么就变成了http://xxx.com/sort/1/[内容].html
页数就是到尾页的页数了
3.获取区间,就是从分类页从题头开始,到页数栏以上,我们审查元素查看一下该获取什么。
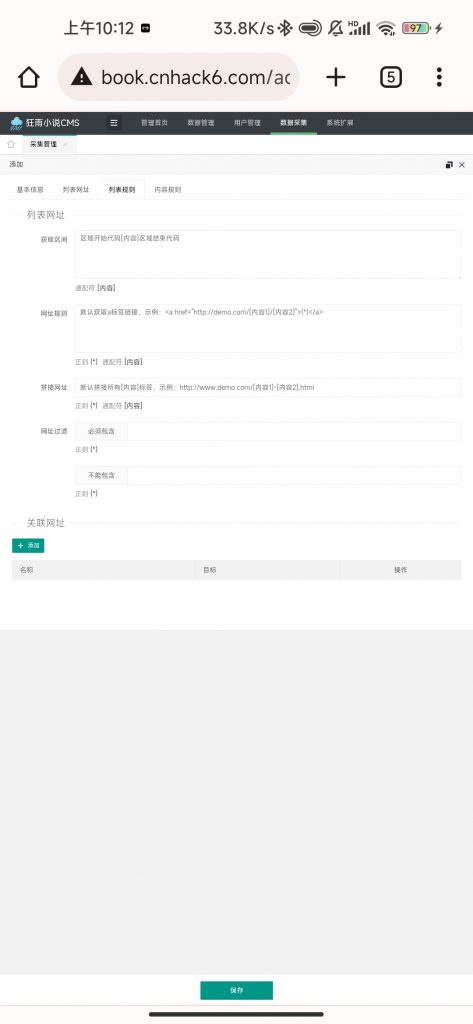
通过分析,我们知道《div id="sitebox"》就是开始,《div class="clearfix"》就是结束,那么获取区间我们这样填写:《div id="sitebox"》[内容]《div class="clearfix"》
因为不能尖括号,所以我用书名号替代


获取内容就是a标签,如《a href="http://xxx.com/book/xxx"》标题标题《/a》
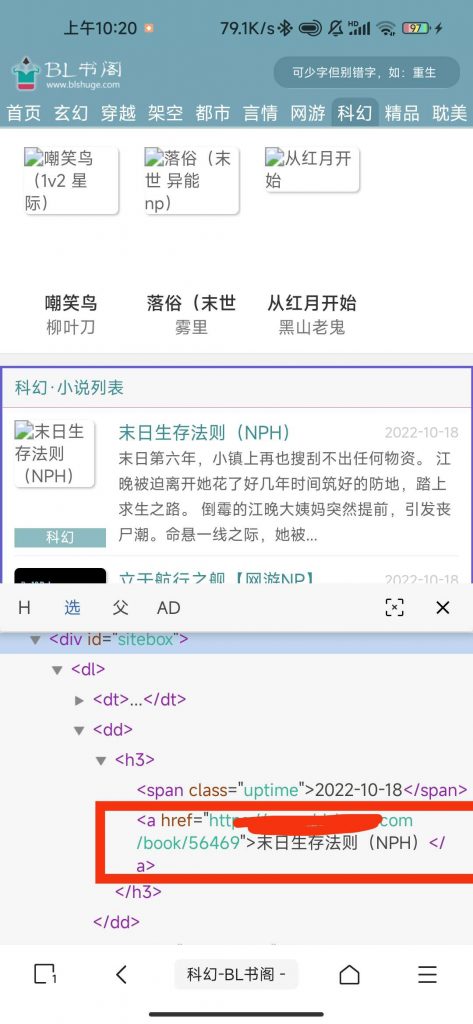
这里xxx就是变量,需要用[内容]替换,标题标题就是书名,用(*)替换,那么结果就是
《a href="http://xxx.com/book/[内容1]"》(*)《/a》
拼接规则就是,如果后面测试采集规则的时候,获取到的结果不是完整链接,那需要将上面a标签的内容输入进去,如果测试可以获得完整链接,则不用管它
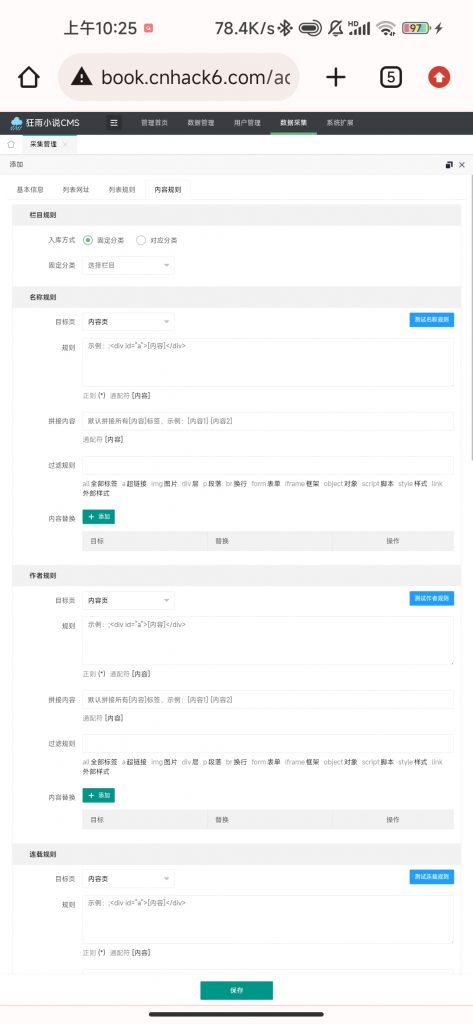
4.内容规则
栏目可以选择采集到固定栏目,或者远程与本地栏目对应,采集到固定栏目不需要获取,而后者则需要获取,以如图小说为例,栏目规则为圈出部分,“将玄幻”替换为[内容1]即可
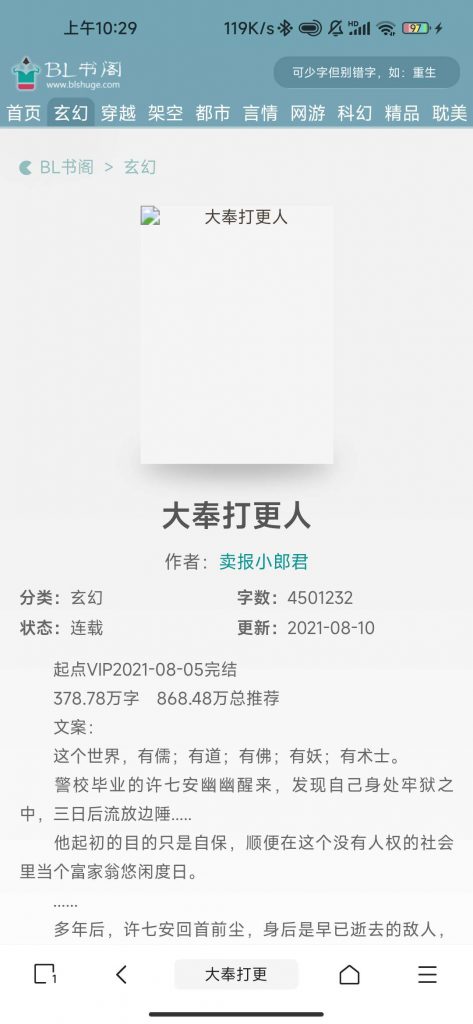

名称规则就是小说书名,由图可知h1标签即为书名,则规则这样编写《h1》[内容]《/h1》
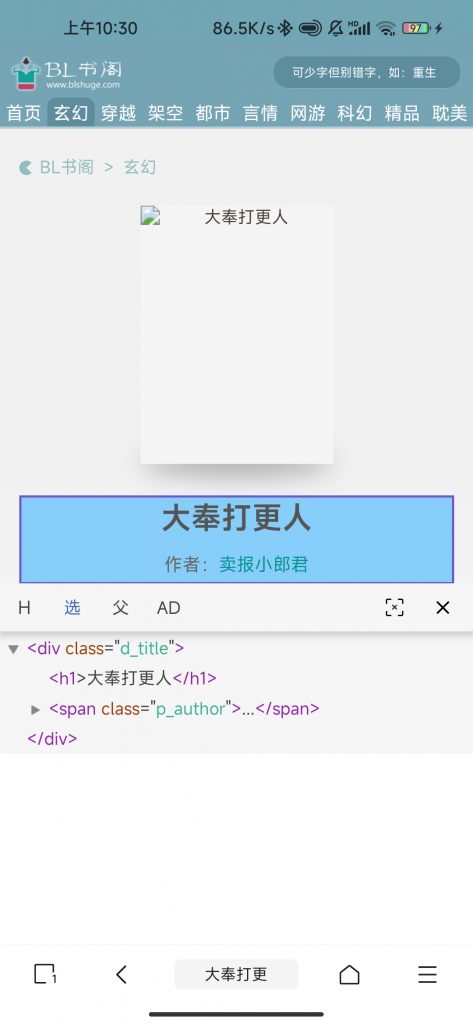
此页面内的作者规则、介绍规则、标签规则、连载规则均如栏目规则同理,所以不再赘述
5.章节名称及章节内容规则编写
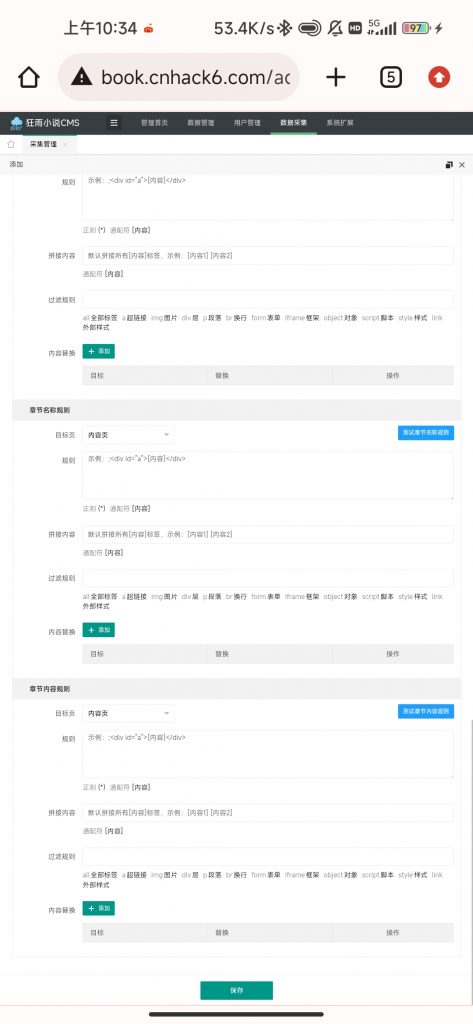
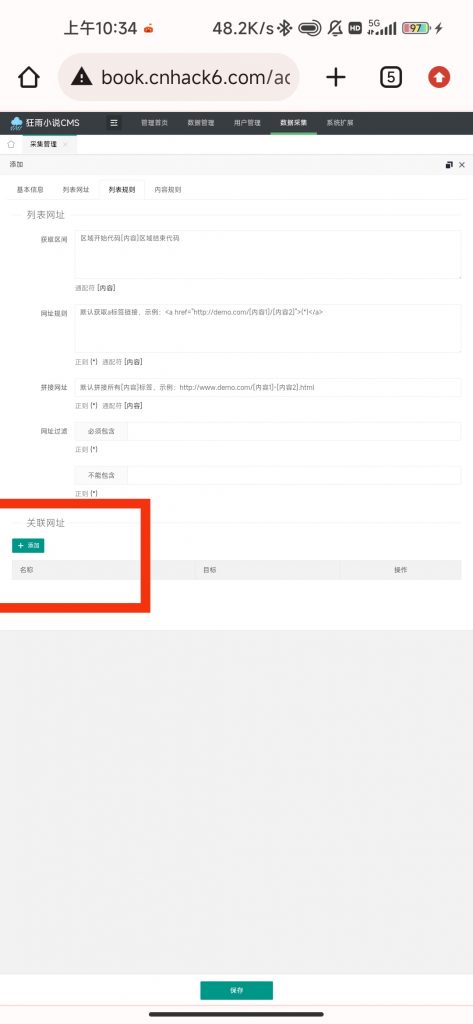
我们需要重新回到“列表规则”栏内,点击如图圈出部分,关联页添加
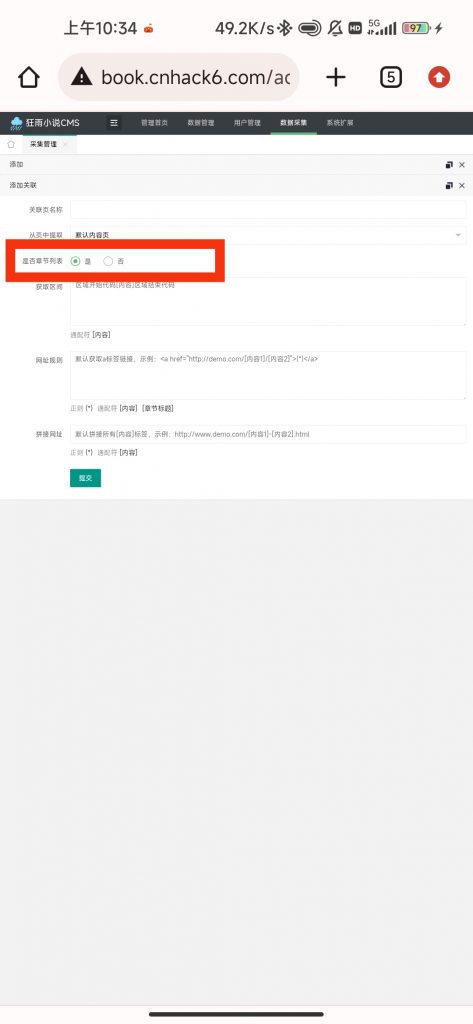
进入添加界面,注意勾选是否章节列表
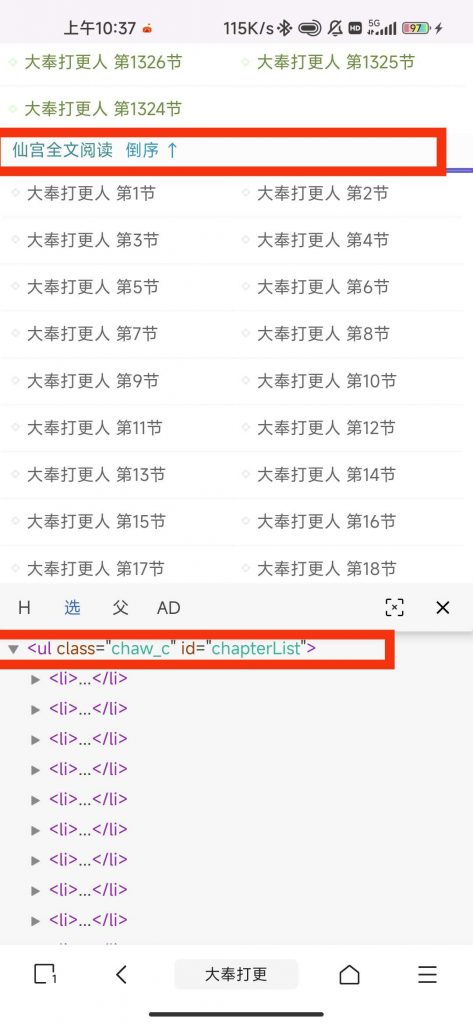
这里需要填写的东西我们要从小说界面获取,以如图小说为例,“仙宫全文阅读”标签下面就是小说全部章节,我们审查元素一下,发现《ul class="chaw_c" id="chapterList"》为开始部分,《/ul》为结束部分,则章节获取区间规则这样编写:《ul class="chaw_c" id="chapterList"》[内容1]《/ul》
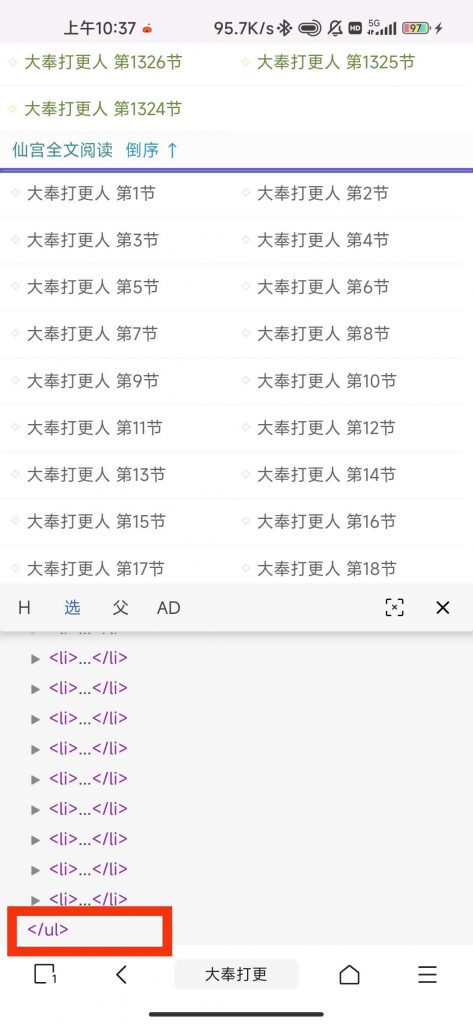
而网址规则,我们点开li标签,下面的a标签即为我们所需要的内容,所以规则这样编写:《a href="http://xxx.com/book/[内容1]">[章节标题]《/a》
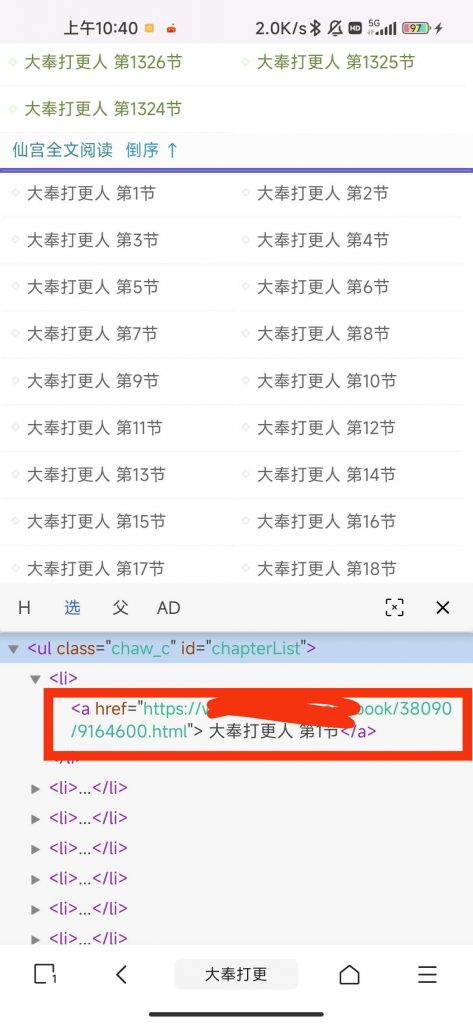
关联页完成
6.章节名称及章节内容规则
我们先选择关联页为步骤5添加的“章节”(叫什么名字可以自己想)
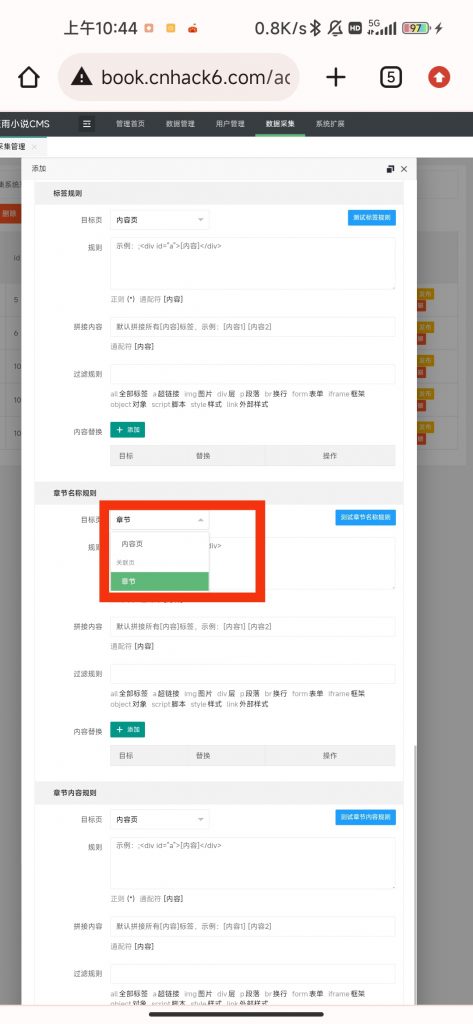
规则同步骤5的网址规则相同,有点不一样的地方,如下
《li》《a href="http://xxx.com/book/[内容1]"> (*)《/a》《/li》
可以注意到,章节标题替换为了(*),其他并无不同
然后就是章节内容的编写,也需要选择关联页
我们先找一章进去看,然后审查元素



由图中圈出可知,开始是《div id="TextContent" class="read-content fz22"》 结束是《/div》
则规则:《div id="TextContent" class="read-content fz22"》[内容1]《/div》
完成后,点击保存,即可开始采集啦!