别再让 AI 偷偷烧钱了:一篇讲透 Token 的成本逻辑
作者:修BUG | 发布时间: | 更新时间:
相信如今大多数人在使用 AI时,最关心的通常是这些问题:模型聪不聪明?写文章像不像人?会不会写代码?回答准不准?这些重要吗?当然重要!但当大家真正开始将AI作为生产力工具时,尤其是开始接触 API、Claude Code、Cursor、Codex、各种 Agent 工具之后,你很快会遇到另一个更现实的问题:AI为啥为什么这么烧钱?明明只是让 AI 改一个小 bug,结果它一波操作,token直接烧了上千万。渐渐的你会意识到有时你以为自己只发了一句话,但系统可能同时带上了历史对话、系统提示词、工具说明、项目文件、搜索结果、代码上下文,这都将极大浪费你的token消耗。如果你不懂 Token,就那就很难真正控制 AI 成本。所以这篇不讲玄学,也不讲什么“万能提示词”。我们只把 Token 这件事讲清楚。
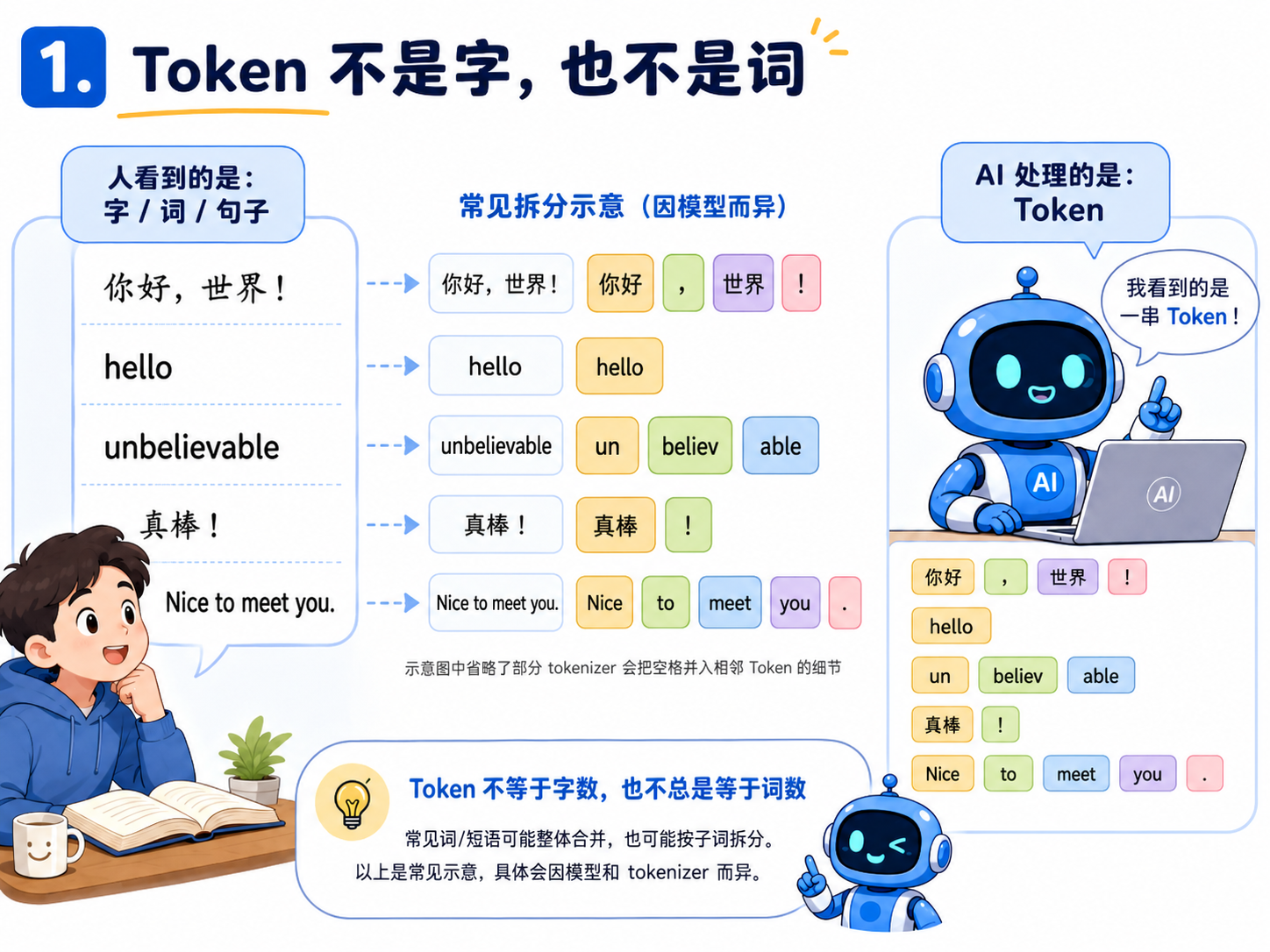
1.Token 不是字,也不是词
Token 是 AI 处理文本时使用的基本单位。它不是我们平时说的“一个字”,也不完全等于“一个词”。人们看文字时,会自然的按词语、句子、语义去理解。但AI 在处理文本前,会先把内容切成一小块一小块,这些小块就是 Token。
比如:
“hello” 这种常见英文单词,可能就是 1 个 Token。“unbelievable” 这种长一点的词,可能会被拆成几个 Token。
而中文里的“你好”“今天”“应用”这类词,有时会合并,有时会拆开。标点、空格、换行、代码里的括号和缩进,也都可能算 Token。
所以你不能简单理解成:我写了多少字,就等于多少 Token。
更准确的说法是:AI 不是按你输入了多少字来工作,而是按它需要处理多少文本碎片来工作。
这也是为什么有时候你觉得自己没写多少内容,但 Token 消耗并不低。
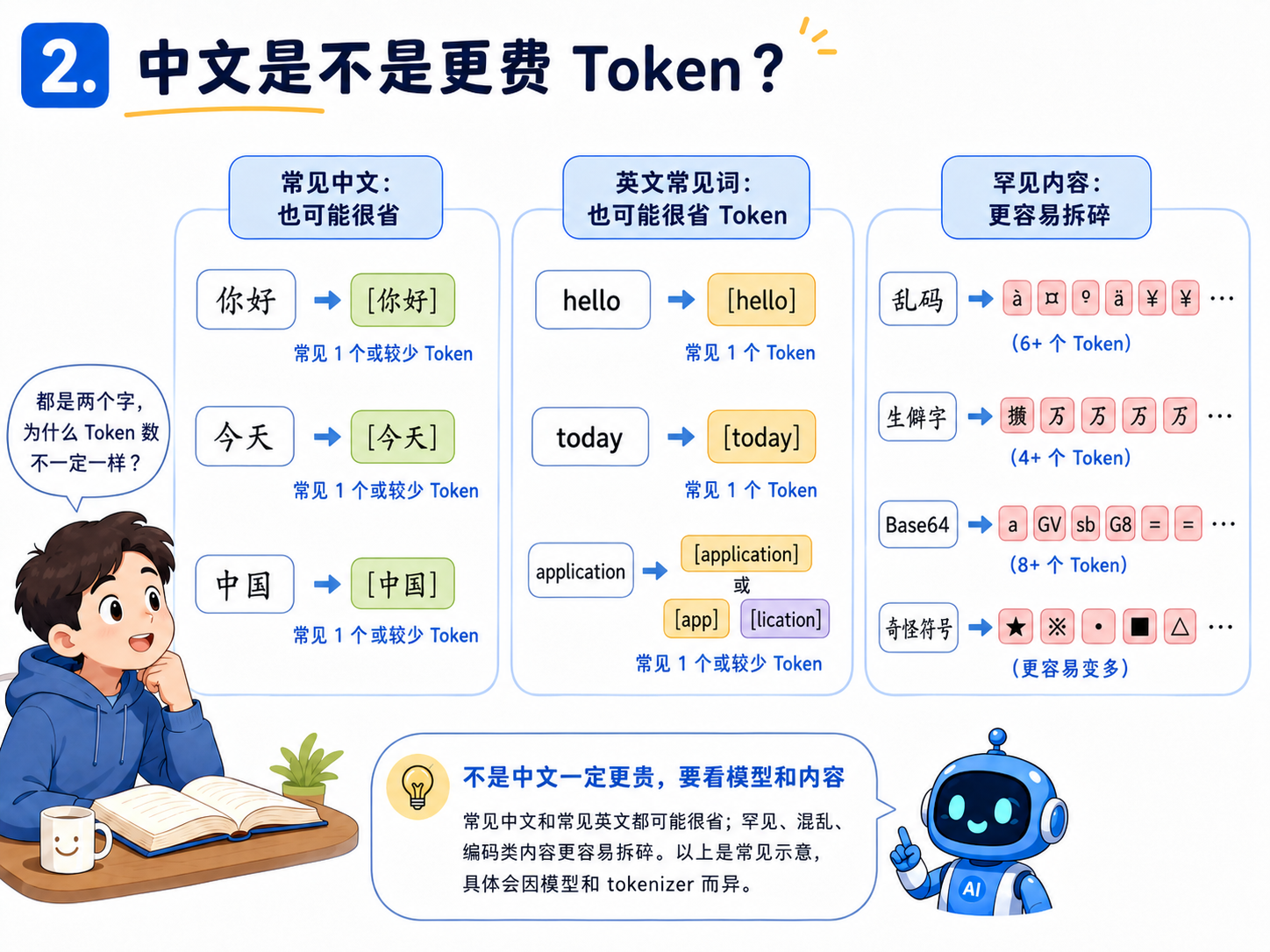
2.中文是不是更费 Token?
很多模型里,中文平均每个字对应的 Token 数可能比英文更高一些,但这不是绝对的。因为不同模型的 tokenizer (分词器)不一样,文本内容也会影响切分结果。最靠谱的办法,是用对应平台的 tokenizer 工具实际测一下。英文里有很多高频词,比如 “the”“app”“love”,经常可以被整体识别成一个 Token。中文虽然信息密度高,但切分方式不一样。有些常见词可能会被合并,有些字可能会被单独拆出来。
这里有个规律可以记住:越常见的表达,越容易被合并;越罕见、越奇怪的内容,越容易被拆碎。
比如“你好”“今天”“应用”这类常见词,一般不会太夸张。但如果你输入的是生僻字、乱码、奇怪符号、Base64、压缩后的代码,Token 数就可能明显上升。
代码也是一个很典型的场景。
很多人以为代码只是文本,其实代码里的缩进、换行、括号、注释、长变量名,都会进入 Token 计算。
所以一般来说,下面这些内容都比较容易消耗 Token:
长代码文件
复杂 JSON
大量日志
生僻词和乱码
重复的报错堆栈
很长的历史对话
复制粘贴的一整篇网页
真正省 Token 的第一步,不是学什么神奇提示词,而是先学会一件事:不要把没用的信息都丢给 AI。
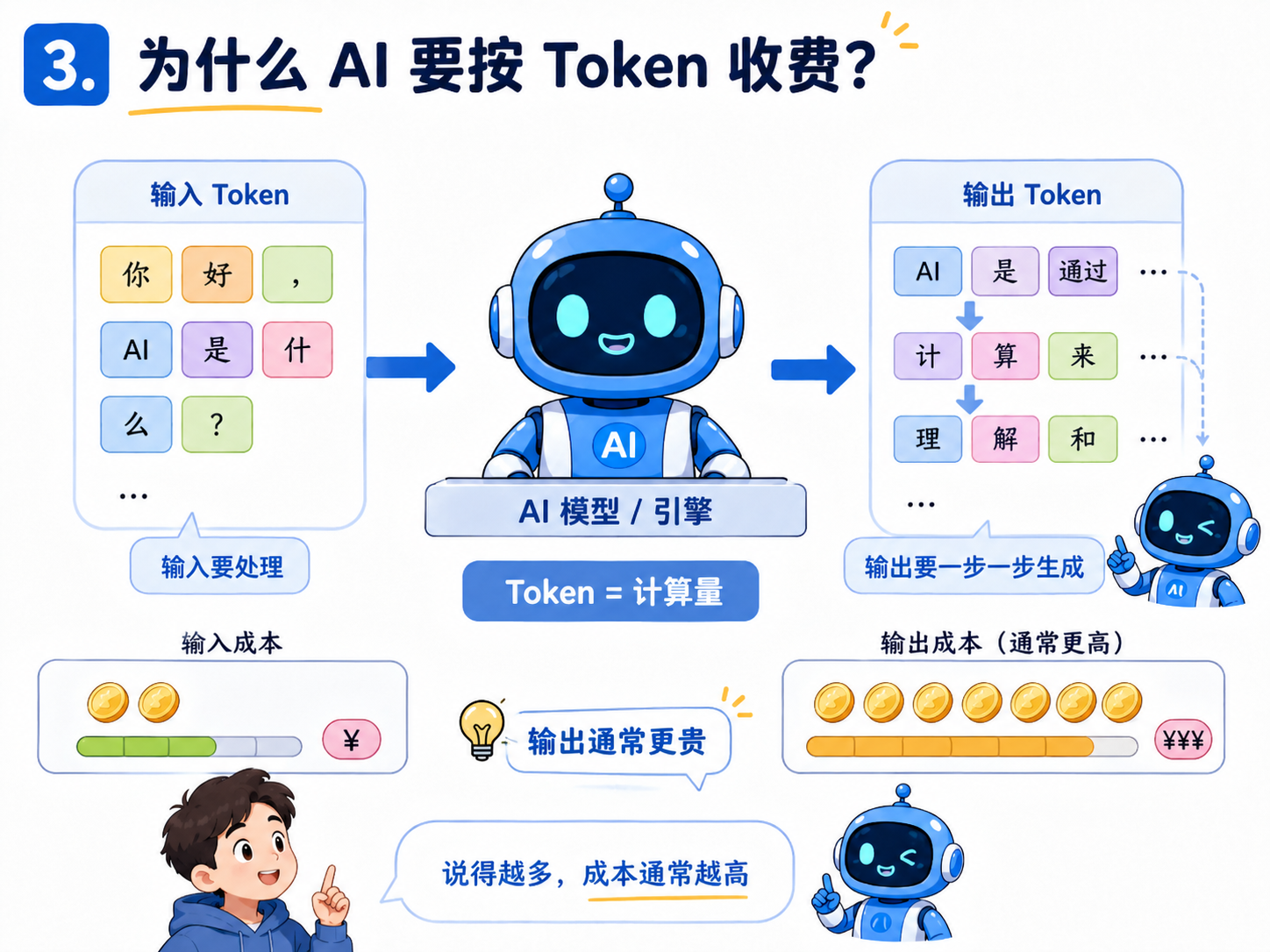
3.为什么 AI 要按 Token 收费?
每一个 Token 背后都是计算,输入的 Token,模型要处理 ,模型输出的 Token,也要一步一步生成。Token 本质上就是 AI 世界里的计算单位。
现在主流 API 基本都是按输入 Token 和输出 Token 分开计费。有些平台还会区分普通输入、缓存输入、输出等不同类型。
这里有一点很关键:输出 Token 通常比输入 Token 更贵。
原因也不难理解,输入内容可以一次性送给模型处理,但输出不是一次性吐出来的,它是一个 Token 一个 Token 生成的。
生成第一个 Token,要算。生成第二个 Token,要基于前面的内容继续算。生成第三个 Token,还要继续往后推。所以输出越长,成本越高。
这也是为什么有些 AI 工具喜欢先说一堆背景、客套话、解释过程,看起来很贴心,但如果你是按量付费,其实每一句废话都在花钱。
有时候一句简单的要求就很管用:直接给结果,不要解释。这不是不礼貌,是省钱。
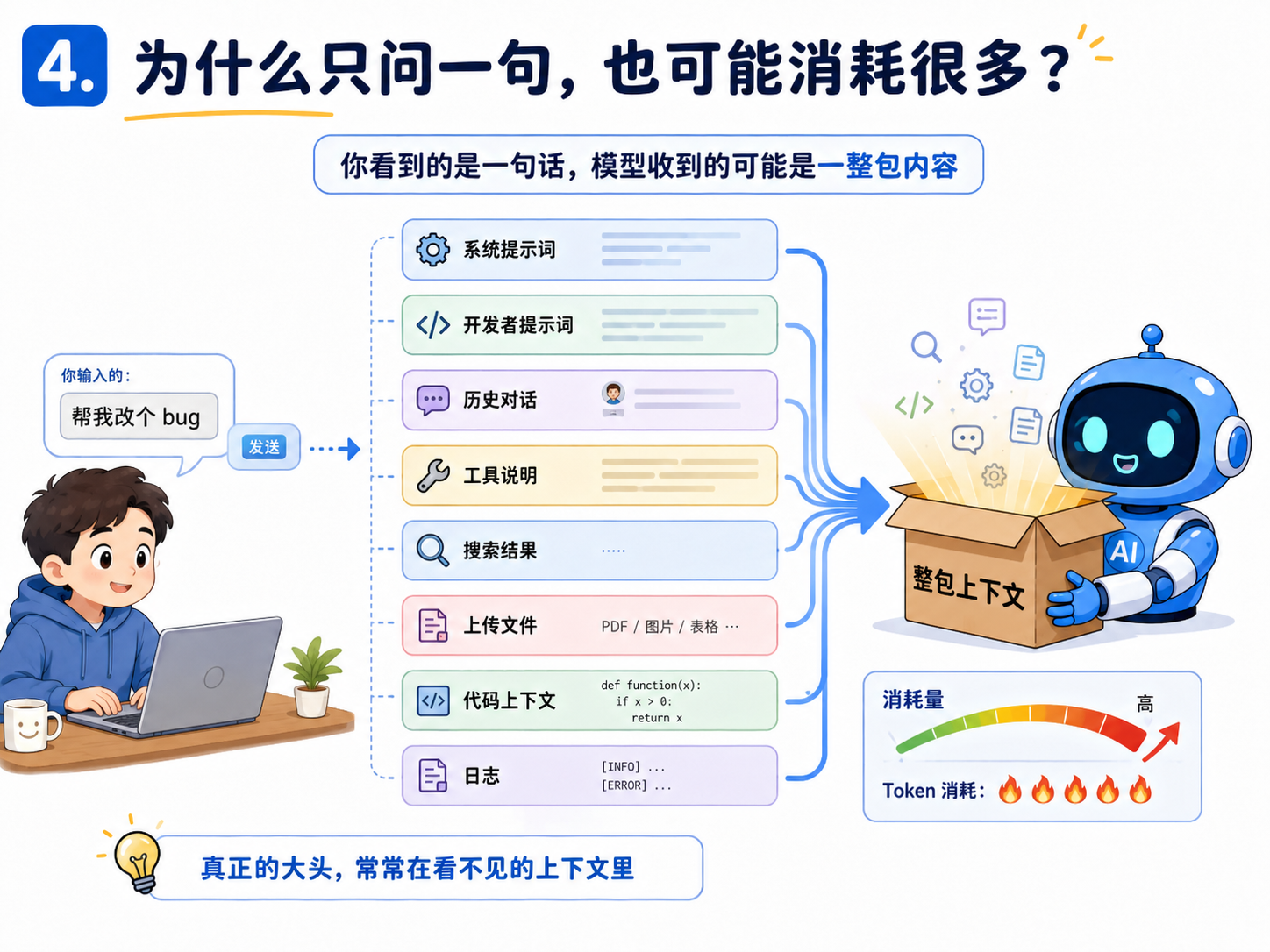
4.你以为的一句话,其实可能发送带了一大堆的东西
很多人第一次看 Token 消耗,会觉得奇怪:“我明明只问了一句,为什么用了这么多?”
原因是,模型收到的内容不一定只有你刚刚输入的那句话。一次请求里可能包括:系统提示词 开发者提示词 前面的对话历史 工具说明
插件定义 搜索结果 上传文件内容 当前打开的代码文件 项目配置 命令运行结果 报错日志
你看到的是一个聊天框。模型看到的,可能是一整包上下文。
这就像你叫一个人帮你看一句话,但同时把前面 50 页聊天记录、20 个工具说明、8 个代码文件和一堆报错日志都塞给他。背景当然更完整了。
但他也要花更多成本去处理。所以 AI 使用成本真正的大头,经常不在你刚刚打的那几个字,而在你看不见的上下文里。
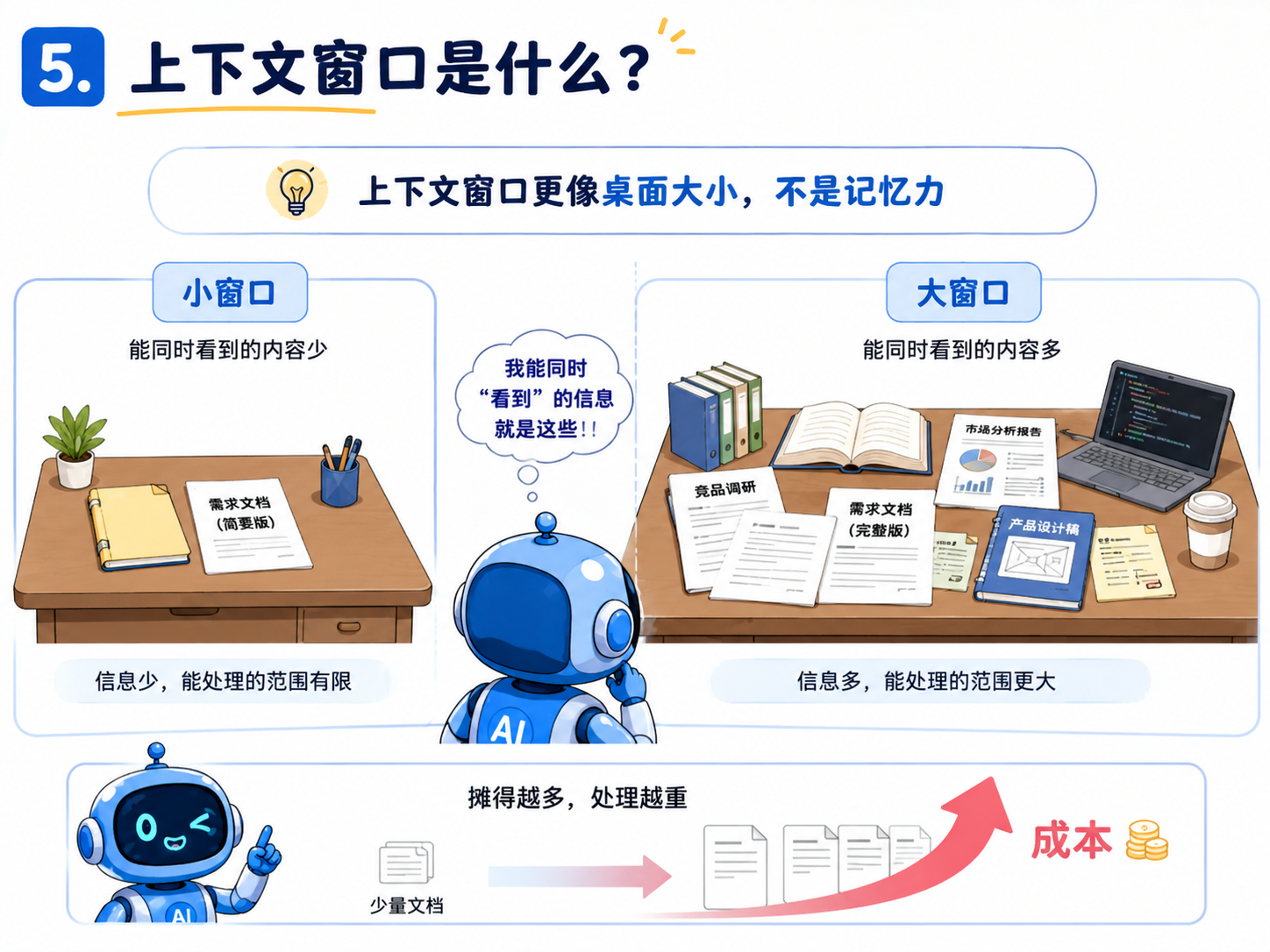
5.上下文窗口不是记忆力,更像桌面大小
现在很多模型都会宣传上下文窗口:128K、200K、1M,甚至更长。很多人会把它理解成:“这个 AI 记忆力很强。”
但这个说法不太准确。更准确地说:上下文窗口,是模型这一轮最多能同时看到多少内容。它更像一张桌子。桌子小,只能摊开几页纸。桌子大,可以同时摊开一本书、几份报告、几个代码文件。但桌子大,不代表你每次都应该把所有东西都摊上去。因为你摊开的每一页,模型都要看。上下文越长,单次请求越重,成本也越高。长上下文当然有用,尤其是读长文档、分析代码库、做复杂研究的时候。但如果只是让 AI 改一句文案,还把前面几十轮完全不相关的对话都带着,那就是浪费。会用 AI 的人,不是永远开最大上下文的人。而是知道什么时候该清场。
6.Agent 为什么特别费 Token?
我们日常使用AI的情景大概是:你问一句,AI 答一句。但Agent 不一样,你给它一个目标,它会自己拆任务、查资料、读文件、写代码、跑命令、看报错、再修改、再验证。这就不是一个量级了。
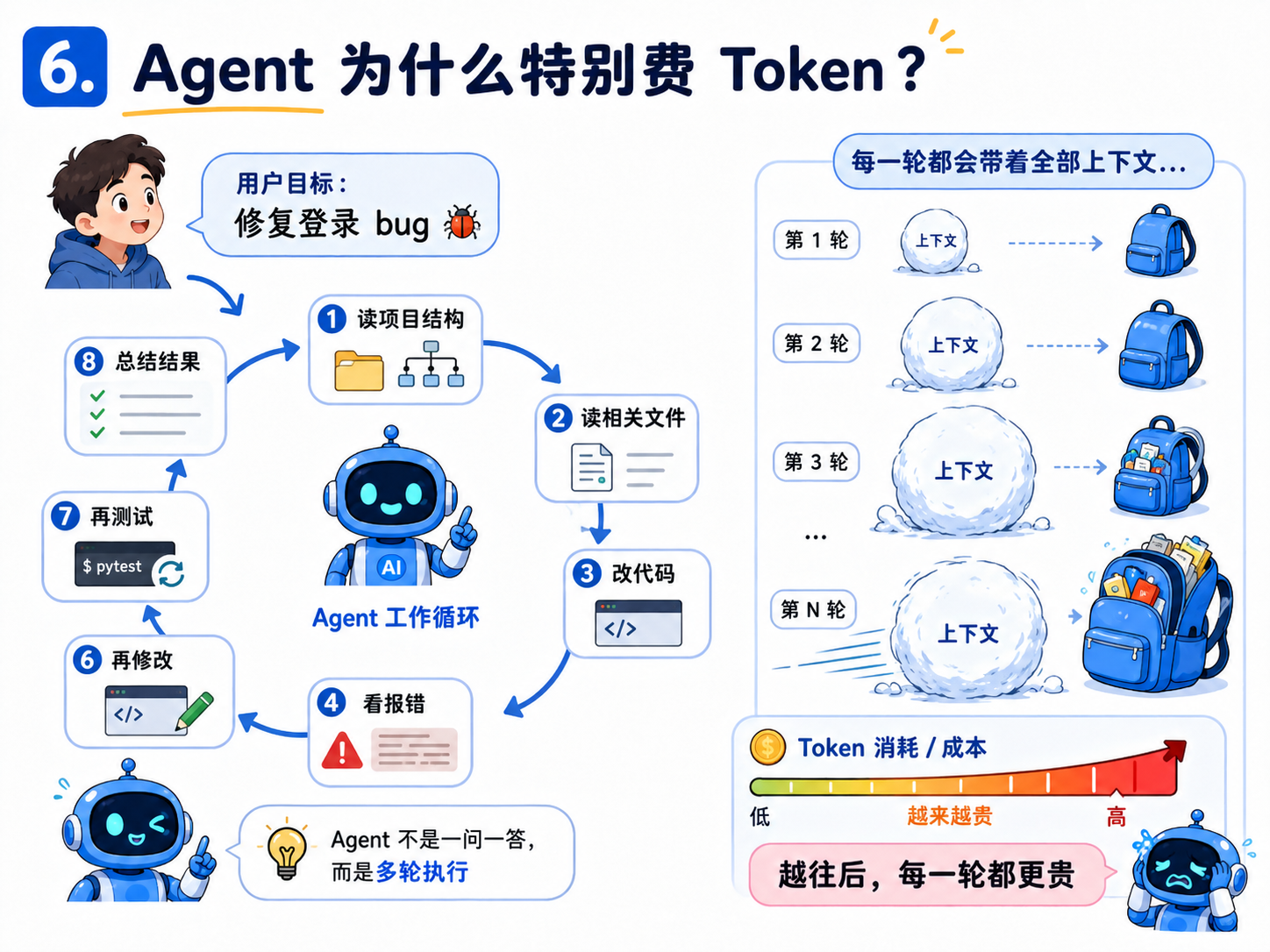
比如你说:“帮我修一下登录页面的 bug。”普通聊天可能只是给你一些建议。但 Agent 可能会这样做:
先读项目结构。
再找登录相关文件。
再读路由文件。
再读接口文件。
再读状态管理文件。
尝试修改。
跑测试。
测试失败后读取报错。
再修改。
再跑一次。
最后总结结果。
你看到的只是一句话。
它背后可能已经跑了十几轮。
更麻烦的是,Agent 的上下文会滚雪球。
第一轮,它带着系统提示和你的任务。
第二轮,它多了读到的文件。
第三轮,它多了命令输出。
第四轮,它多了报错日志。
第五轮,它多了修改记录。
越往后,每一轮都更贵。
所以很多人刚开始用 Claude Code、Codex、Cursor Agent 的时候,会觉得它“吃 Token 跟喝水一样”。
不是它故意浪费。而是 Agent 模式本来就比普通聊天重得多。
7.Prompt Caching 是怎么省钱的?
这里有一个很多人不太注意,但很重要的机制:缓存。如果一段内容在多次请求里重复出现,比如系统提示词、工具说明、长文档前半部分,模型服务商有时可以把这部分缓存起来。下一次再用到相同内容时,就不一定按完整输入价格重新计算,而是按更低的缓存输入价格计费。这对长文档、代码库、固定系统提示词很有用。但缓存不是魔法。它更适合那些“重复使用的大段稳定内容”。如果你每次都改提示词、换文件、换结构,缓存命中率就会下降。缓存通常有门槛,也依赖平台机制。比如有的平台主要缓存较长的重复前缀,有的平台需要显式设置 cache control。它不是“重复一句话就一定省钱”。OpenAI 公开文章提到,缓存通常从超过 1,024 tokens 的 prompt 开始匹配,并按 128 token 增量缓存最长重复前缀。 Anthropic 的 Claude 也支持 prompt caching,但机制上需要设置 cache control,或者使用自动缓存相关配置。
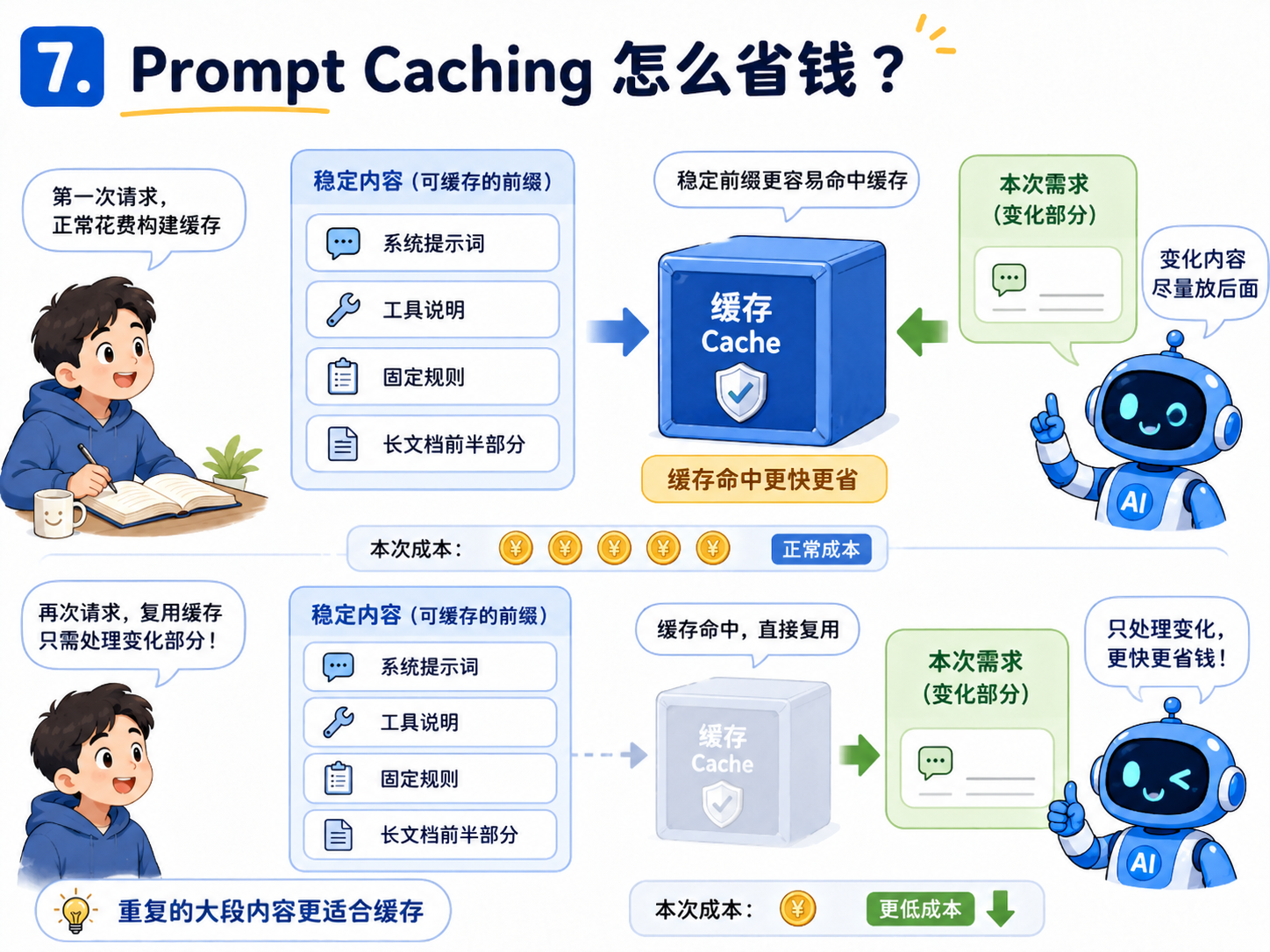
所以一个很实用的习惯是:固定背景尽量保持稳定,变化的需求放在后面。因为很多缓存机制看的是 prompt 的稳定前缀。如果你把经常变化的内容放在前面,后面即使有大段固定内容,也可能影响缓存命中。
比如你做一个固定项目,不要每次都把项目说明改来改去。把稳定规则放前面,把这次具体要做的事放后面。这样更容易让缓存发挥作用。
8.省 Token 不是少打字,而是少返工
很多人以为省 Token 就是:提示词写短一点。少发几个字。能缩写就缩写。
这只对了一小部分。
真正贵的,往往不是你输入的几十个字,而是 AI 输出的几千字、Agent 读取的几十个文件、来回纠错的十几轮对话。
所以省 Token 的核心不是“把话说短”,而是:一次把需求说清楚,减少无效来回。
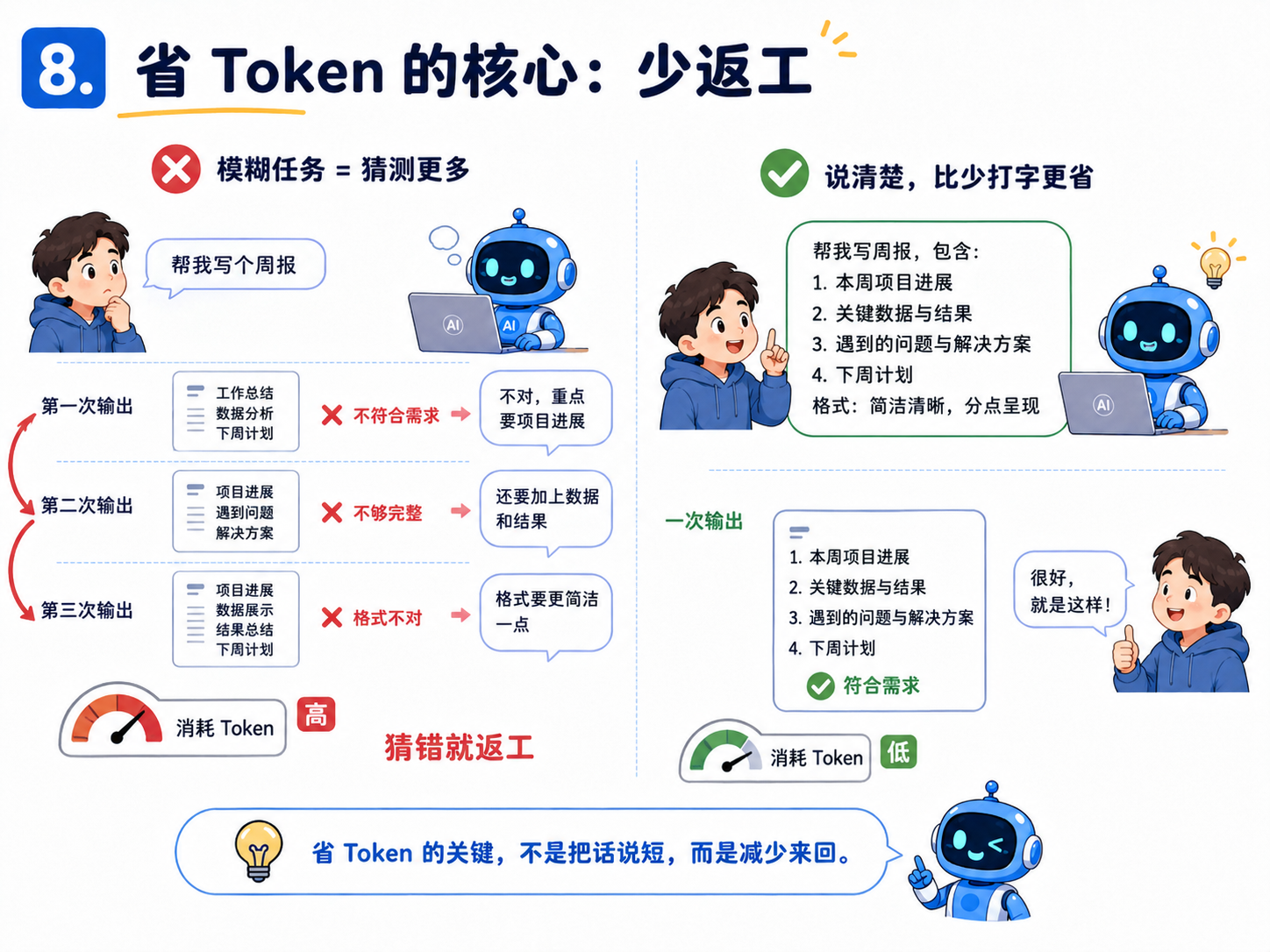
比如你让 AI 写周报。
低效写法是:“帮我写个周报。”AI 不知道你这周做了什么,只能写模板。你再说:“不对,太空了。”它再改。你又说:“加上项目 A。”它再改。几轮下来,Token 就上去了。
更好的写法是:“帮我写一份本周工作周报,内容包括:1. 完成登录模块重构;2. 修复支付金额计算 bug;3. 参加新项目需求评审。语气正式但不要太虚,每条 2-3 句话,最后加下周计划。”
这不是什么高级提示词。只是把信息给全了。AI 最怕的不是复杂任务,而是模糊任务。模糊任务会导致猜测。猜错就要返工。返工就烧 Token。
9.普通用户怎么省 Token?
下面这些方法,不管你用 ChatGPT、Claude、Gemini,还是其他 AI 写作工具,都适用。
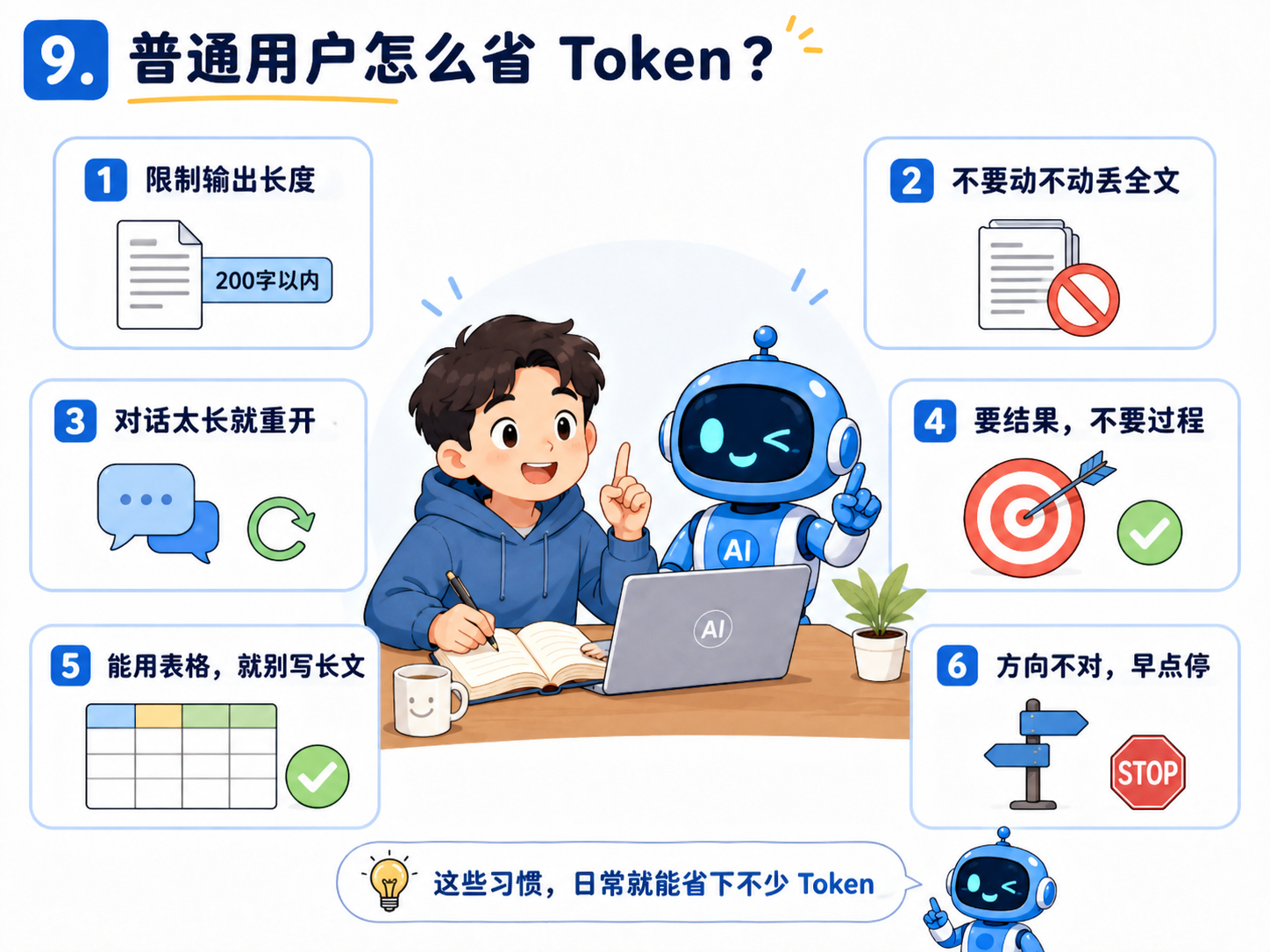
1. 直接限制输出长度
不要只说:
“帮我分析一下。”
可以改成:
“控制在 300 字以内。”
“只列 5 条。”
“每条不超过两句话。”
“不要写背景介绍,直接给结论。”
“用表格输出。”
这些限制很有用。
因为输出 Token 往往更贵。
你让 AI 少说废话,本质上就是在省钱。
2. 不要动不动丢全文
很多人让 AI 总结网页,会直接复制整篇文章。
让 AI 分析合同,会直接丢完整 PDF。
让 AI 改代码,会直接贴整个文件。
有时候这是必要的,但不是每次都必要。
在发送之前,先问自己几个问题:
我到底要它看哪部分?
有没有目录、摘要、关键段落?
能不能只给相关内容?
能不能先让它判断需要哪些信息?
AI 不是垃圾桶。
你喂得越乱,它处理成本越高。
3. 对话太长就重开
如果一个对话已经聊了几十轮,前面的话题早就不相关了,那就不要继续硬聊。
长对话有两个问题:
第一,成本变高。
第二,模型容易被旧信息干扰。
比如你前面一直在讨论 A 项目,后面突然切到 B 项目。
如果不清理上下文,AI 可能还会把 A 项目的规则带进来。
这时候新开一个对话,反而更干净。
4. 要结果,不要过程
很多时候,你不需要 AI 解释它为什么这么做。
可以直接说:
“只给最终答案。”
“不要解释推理过程。”
“不要寒暄。”
“不要重复我的问题。”
“错误的地方直接改,不要长篇说明。”
这些话很朴素,但真的有用。
5. 能用表格,就别写成长文
如果你要对比信息,尽量让 AI 用表格。
比如:
“对比三个工具,从价格、适合人群、优点、缺点四列输出。”
这通常比写一篇 2000 字分析更省,也更容易读。
6. 方向不对,早点停
如果 AI 连续两三轮都没理解你的意思,不要继续小修小补。
很多人会陷进去:
AI 答错了,我补充一点。
又错了,我再补充一点。
还是错了,我继续解释。
最后对话越来越长,AI 越来越乱,Token 越烧越多。
更好的做法是直接重置方向:
“我们重新来。忽略前面的方向。我的真实需求是……”
这通常比在错误上下文里硬拽回来更省。
10.写代码时,Token 花得最快
程序员是 Token 消耗大户。因为代码文件长,项目结构复杂,Agent 又会读文件、跑命令、看日志、改代码。每一步都可能把上下文撑大。
如果你经常用 Claude Code、Cursor、Codex 这类工具,下面这些习惯很重要。

1. 先让 AI 做计划,别一上来就改代码
不要直接说:“帮我实现这个功能。”
可以先说:“先不要改代码。请先阅读相关文件,给我一个实现计划,列出需要改哪些文件、为什么改、风险是什么。等我确认后再动手。”
这一步看似多花 Token,其实很多时候更省。因为最贵的不是规划,而是方向错了之后大规模返工。
2. 指定文件和范围
低效写法:“帮我看看登录逻辑。”
更好的写法:“请只看 src/auth/session.ts 和 src/api/login.ts,重点检查 token refresh 逻辑。”
范围越清楚,AI 越不需要到处搜索。它少读一个无关文件,你就少付一份上下文成本。
3. 让 AI 输出 diff,不要输出完整文件
改代码时要记住一句话:只给修改部分,不要重贴全文。
比如:
“请用 diff 格式输出修改,不要输出完整文件。”一个 500 行文件可能只改 10 行。
如果 AI 把整个文件重新贴一遍,Token 消耗会被放大很多。
4. 日志只给关键部分
测试失败后,不要把几千行日志全丢给 AI。
先筛一下:
只保留 ERROR。
只保留 FAIL。
只保留最相关的 stack trace。
只保留最后 100 行。
删掉重复日志。
很多时候,一条关键报错就够了。你丢 5000 行日志进去,AI 不一定更聪明,只是更贵。
5. 项目说明文件要短
很多 AI 编程工具会读取项目说明,比如规则文件、项目配置、coding style 等。这些文件如果写得太长,就会变成每一轮都要交的“固定税”。
应该写什么?
项目特有的命令。
特殊架构约定。
容易踩坑的地方。
必须遵守的代码风格。
不该写什么?
“请写高质量代码。”
“请保持简洁。”
“请注意可维护性。”
一大堆语言通用知识。
代码里已经能看出来的废话。
这些东西不仅帮不上多少忙,还会长期占上下文。
6. 一个会话只做一个任务
不要在一个 Agent 会话里连续做太多事:
先修登录。
再改数据库。
再写测试。
再优化 UI。
再整理文档。
看起来连贯,其实上下文会越来越胖。
更好的方式是拆开:
登录问题一个会话。
数据库迁移一个会话。
UI 调整一个会话。
文档整理一个会话。
每个会话目标单一,AI 更不容易跑偏,也更省 Token。
11.别什么任务都用最贵模型
很多人有个习惯:“要用就用最强的。”
这在 AI 上不一定划算。因为不同任务对模型能力的要求差别很大。改一句文案,不需要最强推理模型。总结一篇普通文章,不需要最贵模型。批量改格式,不需要旗舰模型。简单分类、提取字段、翻译短文本,便宜模型通常就够了。
强模型应该留给更难的事:复杂推理。架构设计。困难代码问题。多文档综合判断。高风险决策前的分析。需要严谨性的任务。
真正会用 AI 的人,不是永远用最贵模型。
而是会分层使用:简单任务用便宜模型。普通任务用中档模型。难任务再上强模型。这跟开车差不多。买菜没必要开赛车。
12.几个最实用的省钱句式
下面这些话可以直接复制到提示词里。
写作类
总结类
代码类
Agent 类
13.最容易浪费 Token 的 7 个习惯
下面这些习惯,最容易让 Token 白白烧掉:
Token 不是技术概念,而是使用 AI 的成本意识
Token 看起来像一个技术概念,但它其实非常现实。
它决定了:
你的一次请求多少钱。
你的 Agent 能跑多久。
你的上下文能塞多少东西。
你的模型为什么会变慢。
你的账单为什么突然变高。
刚开始用 AI,大家比的是谁会写提示词。真正用深了,大家比的是谁会管理上下文,谁会控制输出,谁会拆任务,谁知道什么时候该停。
说白了,Token 就是 AI 世界里的“油”。你当然可以不看油表,一脚油门踩到底。
但如果你想长期用、重度用、低成本用,就必须知道油花到哪里去了。理解 Token 之后,你会发现,省钱不是靠抠那几个字,而是靠更清楚地表达需求、更干净地管理上下文、更聪明地选择模型。AI 不是越聊越省。很多时候,是越会收,越省。
如果你能看到结尾那你真的很棒棒了,很感谢大家能耐心看完,文章中可能有些地方表达和讲解的不够准确也欢迎大家指正!!!
如果觉得文章写的不错也希望大家动动发财的小手点个赞赞喽!!