【社工进阶】如何通过Twitter社交软件进行社工
作者:FancyPig | 发布时间: | 更新时间:
杂谈
之前我们讲了很多基于OSINT(开源情报)框架下的内容,例如
当然,我们也整理了一份完整思路,如果您感兴趣也可以看下
即日起,我们将针对社交软件给大家提供一些思路和工具,今天我们先分享一下twitter的社工技巧吧!

下面的工具最大的优势就是不基于twitter的api,纯python爬虫实现的,所以超级强大!
视频教程
视频里的方法是直接使用的国外的服务器,因此无需科学上网,直接输入命令就好了!
(福利:您可以点这里领取到vultr 100美元体验券,可以白嫖一年最低配的国外服务器)
勘误说明:视频中是clear清屏 口误打成clean了😅
工具安装
方法一:从git上clone
git clone --depth=1 https://github.com/twintproject/twint.git
cd twint
pip3 install . -r requirements.txt方法二:Python下的twint模块安装(视频中使用的下面这种方法)
安装twint模块
pip3 install --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint部分运行出现报错,则需要修改token.py
具体每个人的环境不同(我的是在/usr/local/lib/python3.6/site-packages/twint/token.py下面)
import re
import time
import requests
import logging as logme
class TokenExpiryException(Exception):
def __init__(self, msg):
super().__init__(msg)
class RefreshTokenException(Exception):
def __init__(self, msg):
super().__init__(msg)
class Token:
def __init__(self, config):
self._session = requests.Session()
self._session.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'})
self.config = config
self._retries = 5
self._timeout = 10
self.url = 'https://twitter.com'
def _request(self):
for attempt in range(self._retries + 1):
# The request is newly prepared on each retry because of potential cookie updates.
req = self._session.prepare_request(requests.Request('GET', self.url))
logme.debug(f'Retrieving {req.url}')
try:
r = self._session.send(req, allow_redirects=True, timeout=self._timeout)
except requests.exceptions.RequestException as exc:
if attempt < self._retries:
retrying = ', retrying'
level = logme.WARNING
else:
retrying = ''
level = logme.ERROR
logme.log(level, f'Error retrieving {req.url}: {exc!r}{retrying}')
else:
success, msg = (True, None)
msg = f': {msg}' if msg else ''
if success:
logme.debug(f'{req.url} retrieved successfully{msg}')
return r
if attempt < self._retries:
# TODO : might wanna tweak this back-off timer
sleep_time = 2.0 * 2 ** attempt
logme.info(f'Waiting {sleep_time:.0f} seconds')
time.sleep(sleep_time)
else:
msg = f'{self._retries + 1} requests to {self.url} failed, giving up.'
logme.fatal(msg)
self.config.Guest_token = None
raise RefreshTokenException(msg)
def refresh(self):
logme.debug('Retrieving guest token')
res = self._request()
match = re.search(r'\("gt=(\d+);', res.text)
if match:
logme.debug('Found guest token in HTML')
self.config.Guest_token = str(match.group(1))
else:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0',
'authority': 'api.twitter.com',
'content-length': '0',
'authorization': self.config.Bearer_token,
'x-twitter-client-language': 'en',
'x-csrf-token': res.cookies.get("ct0"),
'x-twitter-active-user': 'yes',
'content-type': 'application/x-www-form-urlencoded',
'accept': '*/*',
'sec-gpc': '1',
'origin': 'https://twitter.com',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
'referer': 'https://twitter.com/',
'accept-language': 'en-US',
}
self._session.headers.update(headers)
req = self._session.prepare_request(requests.Request('POST', 'https://api.twitter.com/1.1/guest/activate.json'))
res = self._session.send(req, allow_redirects=True, timeout=self._timeout)
match = re.search(r'{"guest_token":"(\d+)"}', res.text)
if match:
logme.debug('Found guest token in JSON')
self.config.Guest_token = str(match.group(1))
else:
self.config.Guest_token = None
raise RefreshTokenException('Could not find the Guest token in JSON')实战案例
以下内容,我们默认您已经下载好了相关的python脚本
今天,我们要社工的对象,是黑寡妇(Scarlett Johansson)~

我们先找到twitter的地址(我们发现寡姐并没有twitter认证的账户,因此我们只能从粉丝账户里寻找一些信息了)
https://twitter.com/Scarlett_Jo
https://twitter.com/BestfScarlett
(访问不了的请科学上网)
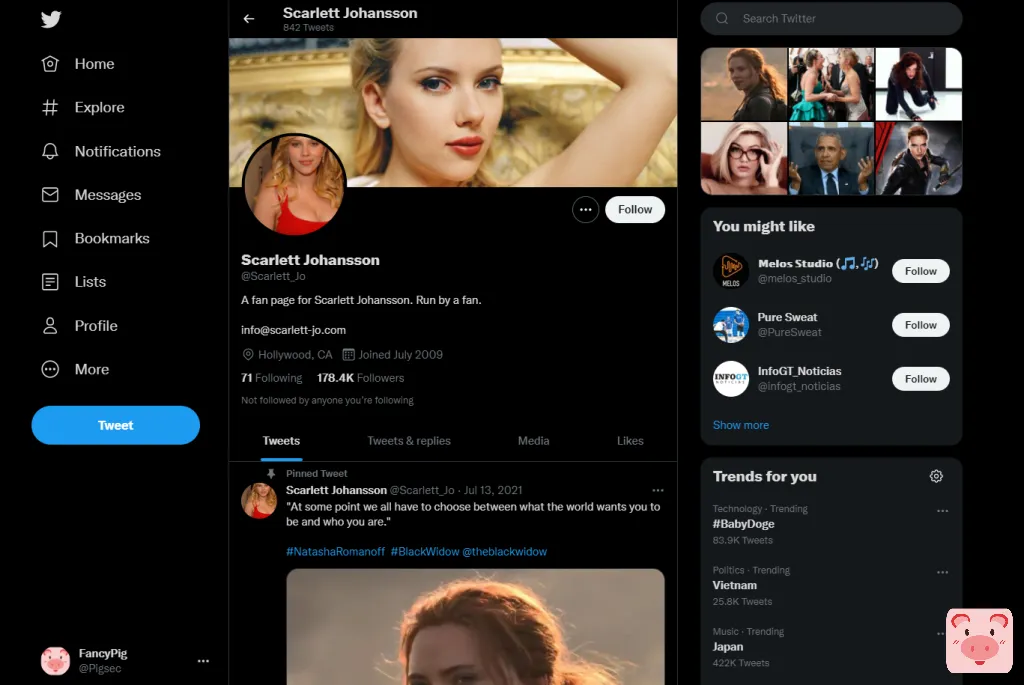
由于以下内容是实战部分,如果你想借用命令,请记得将BestfScarlett改成你要搜寻的用户名
首先,我们可以先收集一下寡姐之前发过的全部推特内容
twint -u BestfScarlett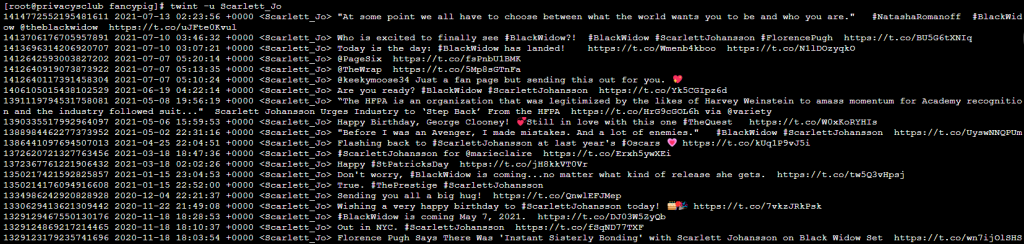
但是这样并不高效,因为一个人的推文有很多,这时,我们可以做一些筛选!
根据点赞数、评论、转发数筛选
例如,我们只看点赞数超过500的
twint -u BestfScarlett --min-likes=500
或者,我们只看评论超过10的
twint -u BestfScarlett --min-replies=10
链接一般在一条的最后面,随便打开一个

或者,我们只看转发量超过100的
twint -u BestfScarlett --min-retweets=100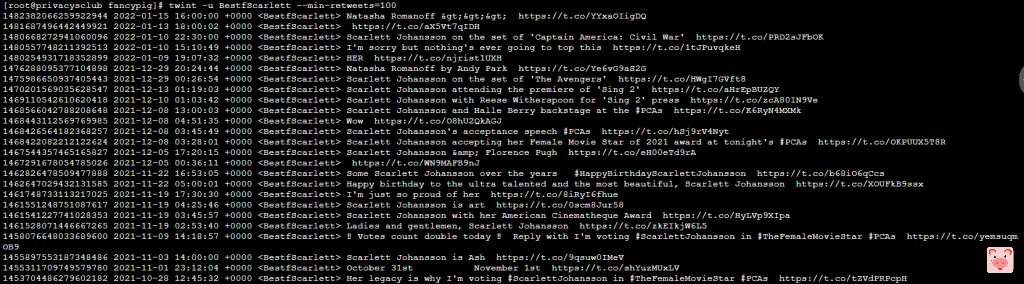
根据时间维度筛选
当然,我们还可以做到更精细,比如我们想看寡姐2021年之前发过的内容,我们可以这样
twint -u BestfScarlett --year 2021
某个日期后发送的内容,比如在《复联4》在美国上映后(2019年4月26日),我想看看寡姐的推文
twint -u BestfScarlett --since 2019-4-26某个时间点之后发送的内容,例如在2019-04-26 20:30:15之后发布的内容
twint -u BestfScarlett --since "2019-04-26 20:30:15"社工进阶
- 关键词索引
我这里下搜索twitter整个社交平台下,关于 寡姐(Scarlett Johansson)的资料
twint -s Scarlett然后你可以看到全球用户发布的与其相关的内容

- 关键词配合twitter号索引
我这里想搜索寡姐(Scarlett Johansson)中与美队相关的内容(关键词我们这里就写Captain就行)
twint -u BestfScarlett -s Captain- 关键词配合认证twitter账户索引
比方说,我这里想搜索寡姐(Scarlett Johansson),而且来源要是认证账户的
twint -s "Scarlett Johansson" --verified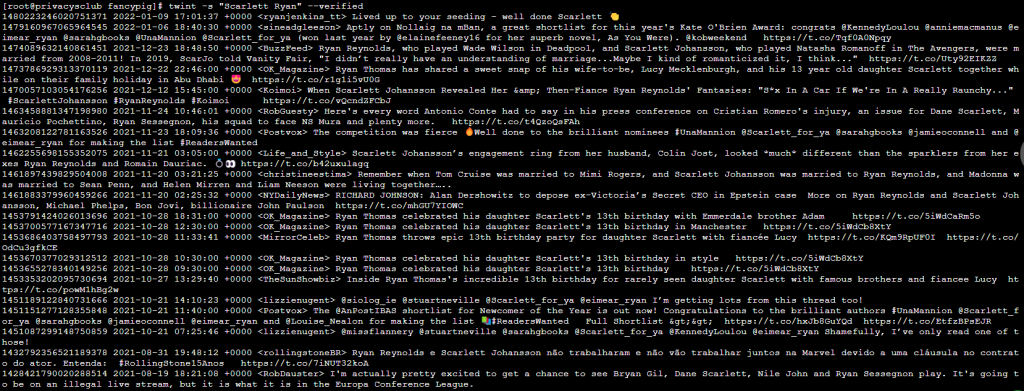
- 泄露手机号、邮件信息索引
我们可以通过下面的命令来检测寡姐(Scarlett Johansson)的手机号、邮箱等资料是否曾泄露于她之前的推文中
检测邮件泄露的命令
twint -u BestfScarlett --email检测手机号泄露的命令
twint -u BestfScarlett --phone我们这里没有检测到,我们这里换到了寡姐的前夫小贱贱(https://twitter.com/VancityReynolds),我们尝试一下

twint -u VancityReynolds --email
居然真的可以检测到泄露的邮件账户地址
导出数据
导出数据只是命令中的一个附加参数,相当于之前我们的命令在后面加上-o相关的命令,也可以导出
(这里假定我们导出的文件名称为file)
- 导出txt格式 -o file.txt
- 导出csv格式 -o file.csv --csv
- 导出json格式 -o file.json --json
当然,这些都是简单的,如果你还想玩点更骚的,还可以直接写到数据库里
- 写入sqlite数据库中 --database tweets.db
- 写入es数据库中 -es localhost:9200
写到数据库中玩法就更多样了,你可以通过一些图表,来更清晰地展现这些用户画像,用户之间的关系以及发送推文的报表,深层次的玩法,我们以后讲!大家可以期待一下!



下面我们将配合实际的功能,跟大家说下如果我想把用户的一些资料导出到json文件中,应该怎么做?
导出粉丝列表
如果你想看哪些用户关注了寡姐,可以通过下面的命令导出到Scarlett_followers.json文件中
一般在社工中我们不这么操作,她的粉丝数太多了,这样做一般意义不大!
twint -u Scarlett_Jo --followers -o Scarlett_followers.json --json导出TA的关心用户
如果你想看寡姐关注了谁,可以通过下面的命令导出
twint -u BestfScarlett --following --user-full -o Scarlett_folloing.json --json导出最近900条推文
twint -u BestfScarlett --following --user-full -o Scarlett_latest_post.json --json导出TA喜欢的文章
twint -u BestfScarlett --favorites -o Scarlett_favorites.json --json