每周AI新闻:马斯克和扎克伯格“约架”
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
欢迎来到每周的AI时间线,我们将分享与AI有关的一切趣闻。
相关资料
Seeing the World through Your Eyes
Meta 人工智能语音
GPT-4不能胜任MIT考试
- 相关文章 https://flower-nutria-41d.notion.site/No-GPT4-can-t-ace-MIT-b27e6796ab5a48368127a98216c76864?pvs=4
LIMA: Less Is More for Alignment
新开源语言模型open_llama_13b
- Hugging Face地址 https://huggingface.co/openlm-research/open_llama_13b
Google衣服试穿模型 Try-on AI
- 相关Twitter 含宣传视频 https://twitter.com/Google/status/1669431242889089029?s=20
- 相关论文 https://arxiv.org/pdf/2306.08276.pdf
假发相关AI技术
动漫风格渲染视频AI
Segment Anything
- 相关Twitter 移除现实生活中的广告演示 https://twitter.com/localghost/status/1670884510261706752?s=20
ChatGPT新功能泄露
机器人技能合成的语言到奖励的转化
语言模型新型微调方法GLoRA
AniFaceDrawing:在你的草图中探索动漫人物肖像
TAPIR:使用逐帧初始化和时序精化跟踪任何点
BITE:超越先验的改进三维狗姿势估计
GAIA-1:一款先进的生成式人工智能模型,用于自主技术
Vid2Avatar:通过自监督场景分解从野外视频中重建3D角色模型
PS1中的游戏图片通过AI优化
- 相关Twitter https://twitter.com/Vajayjay_K
图文讲解
欢迎大家回来,我又为大家整理了上周最新的人工智能新闻和研究成果。首先,这可能是我见过的最具有科幻电影色彩的人工智能研究概念。通过你的眼睛看世界是一项称为“nerf”的研究,它通过重构某人眼睛反射的场景或基本上他们当时看到的东西来重建一个场景。

它是通过在他们移动时对他们的眼睛进行成像,并收集他们眼睛中的多个反射来完成的。

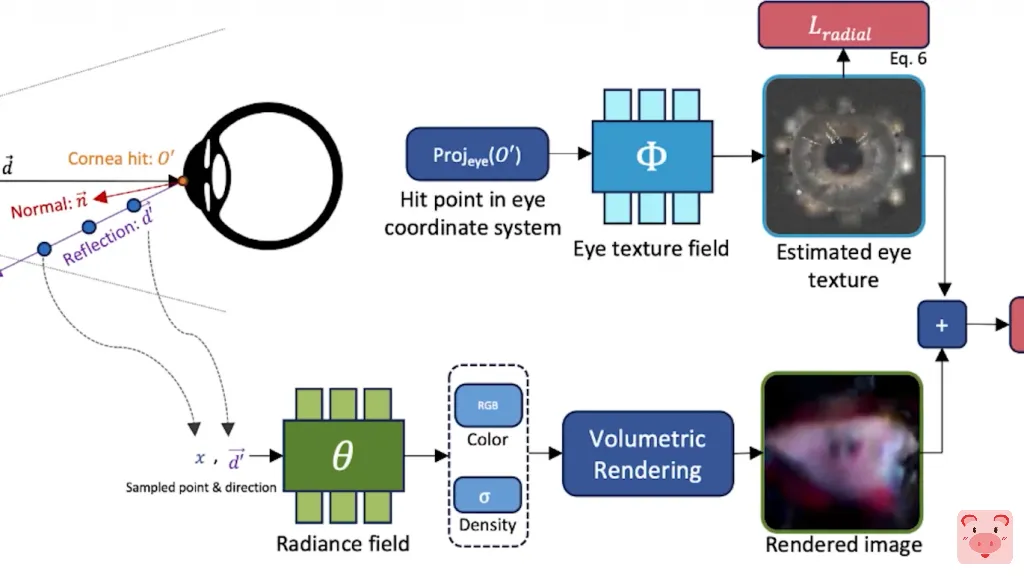
然后人工智能利用这些眼睛的反射来重建摄像机视线之外的三维场景。这听起来真的像那些犯罪电影,他们以某种方式从人们的眼睛反射中获得信息。

呃……埃隆-马斯克挑战扎克的笼中大战算不算是人工智能新闻?

所以,不知从哪里来的,埃隆向扎克进行笼子里的斗争,然后扎克在Instagram上回复说他愿意,让他选择地点,现在埃隆回复说是拉斯维加斯的八角场?
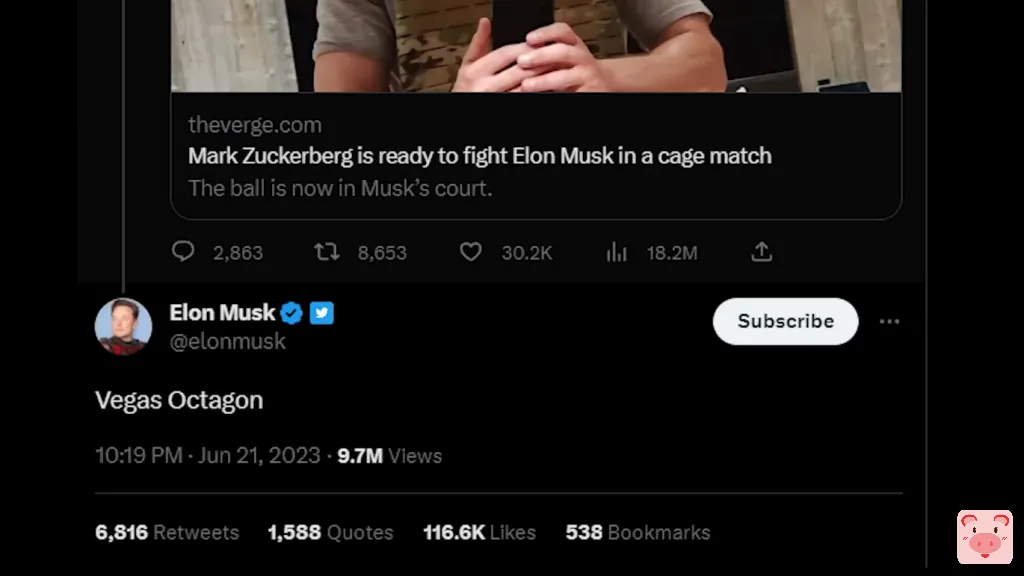
我的意思是,这将是有趣的。
Meta公司发布了名为VoiceBox的文本到语音的人工智能,而且这个编辑功能可能是最酷的。

萨米和佩内洛普温馨的友谊带来了欢乐。(背景音中包含狗吠的声音)
萨米和佩内洛普温馨的友谊带来了欢乐。(背景音中去除了狗吠的声音)

这就像音频的AI橡皮擦。
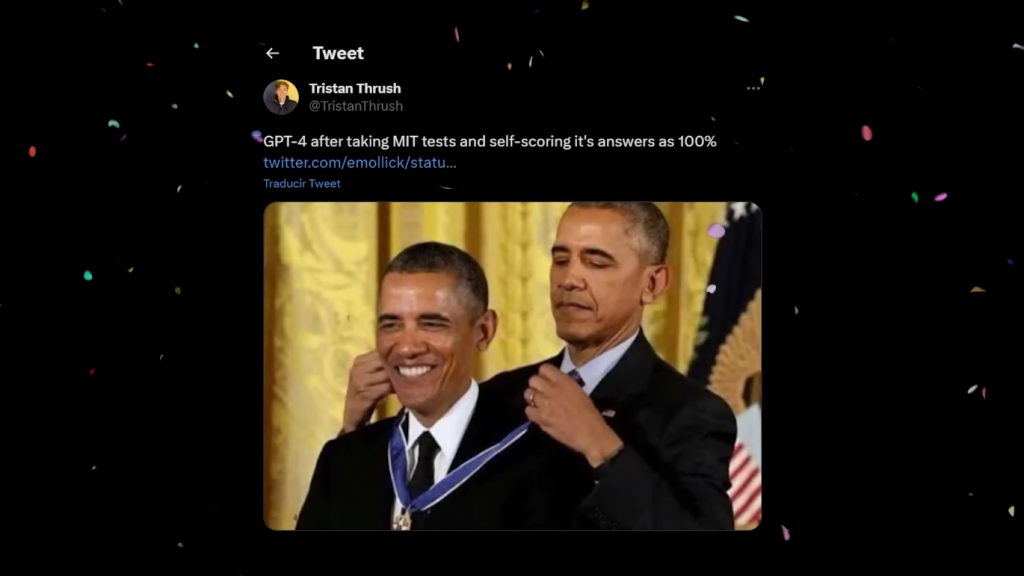
不,GPT-4无法在MIT中表现出色。
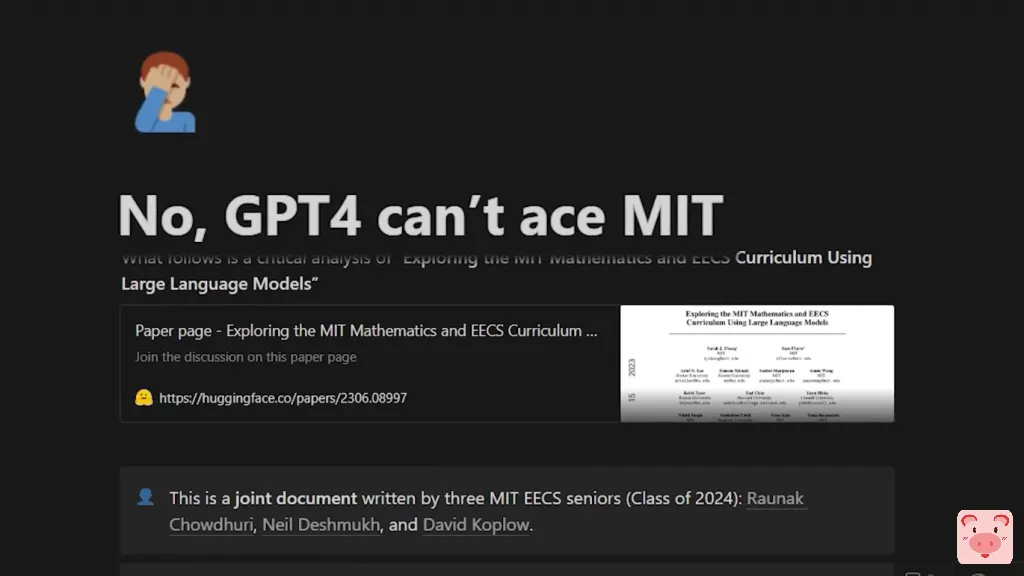
最近有一篇文章声称,只要给GPT-4正确的提示词,它就可以在MIT的EECS课程中得到100分。

然而,三位MIT EECS高年级学生撰写的这篇批判性分析揭穿了这篇论文,并展示了他们的研究方法存在漏洞和数据集中的缺陷。他们没有进行任何合理性检查,他们缺乏严谨性,最重要的是,试题甚至不能准确代表麻省理工学院(MIT)的课程。

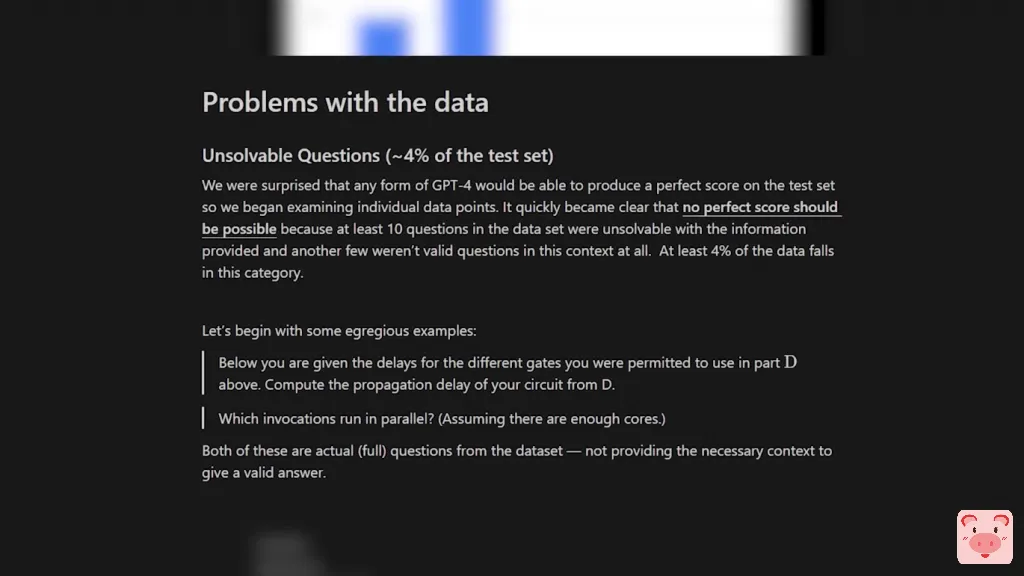
现在的论文如何偷工减料,以获得理想的结果,以使令人震惊的标题成真,这是科学研究的新低。
正如博客所说,这篇论文说明了最近人工智能的大趋势,虽然该领域的进展越来越快,但但发现时间表似乎在缩短,这往往伴随着捷径。

一个非常令人担忧的趋势是使用基于语言的模型(如GPT-4)来评估一个模型的准确性的技术,甚至会从中制作出网络梗。
在评估方面,LIMA, Less is More for Alignment是一篇论文,它表明一个语言模型的数字结果并不能反映模型在现实中的性能。

这篇论文还表明,语言模型的大部分能力都是在预训练阶段获得的,



所以像650亿个参数的巨型模型包含了极高的能力,这些能力可以通过非常少的例子来解锁。这就提出了一个问题:损失计算和数值评估在语言生成任务上到底是如何发挥作用的。

但另一方面的好消息是,OpenLLaMA 13B已经发布了,它具有与Meta发布的LLaMA 13B类似的能力。

由于它是在Apache 2.0下,它可以免费用于商业用途。
还有就是谷歌宣布了他们新的Try-on AI,TryOnDiffusion。
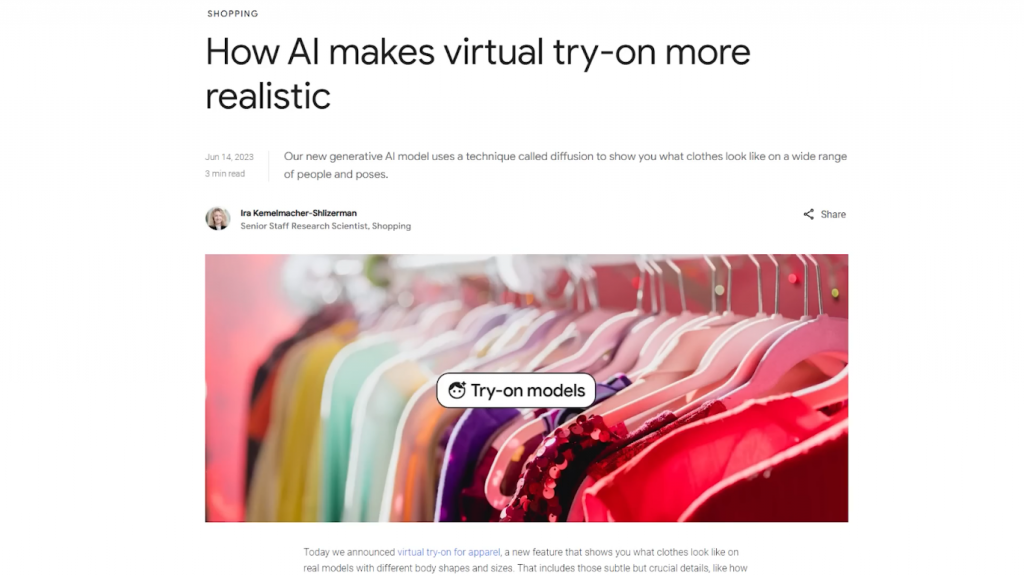
实际上,它对此进行了相当大的营销,

它甚至有自己的关于这个人工智能研究的宣传视频,旁边也有一些博客。


但这个Try-on AI并不是一个真正的新概念,它已经存在了相当长的时间。然而,我认为他们的成果可能是迄今为止最好的。他们对服装在所有身形和体型上的转换效果也非常自信和一致。

虽然在另一方面,有点难以看到衣服在身体上保持一致,比如某些衣服的图案或长度实际上是精确的。但这确实有可能创造更多冲动购买的机会。

比如说,我穿上这个,取代了 "嗯,我穿上这个会怎么样 "的想法。

这种想法是人们犹豫不决或不在网上买衣服的主要原因。我想,是时候通过云商来设计了。
新假发技术代表神经动力学模型,用于体积捕捉和动画。

Blender或Unity的人可能会说,我们10年前就可以做这个了。但听我说,我认为这里的关键是,头发是完全生成的,不是3D模型,而是3D潜伏的头发状态,包含它的运动和外观。所以它可以创建头发的动画,而不必依靠头发的观察作为驱动信号,而是依靠面部地标和重力方向来生成真实的运动。
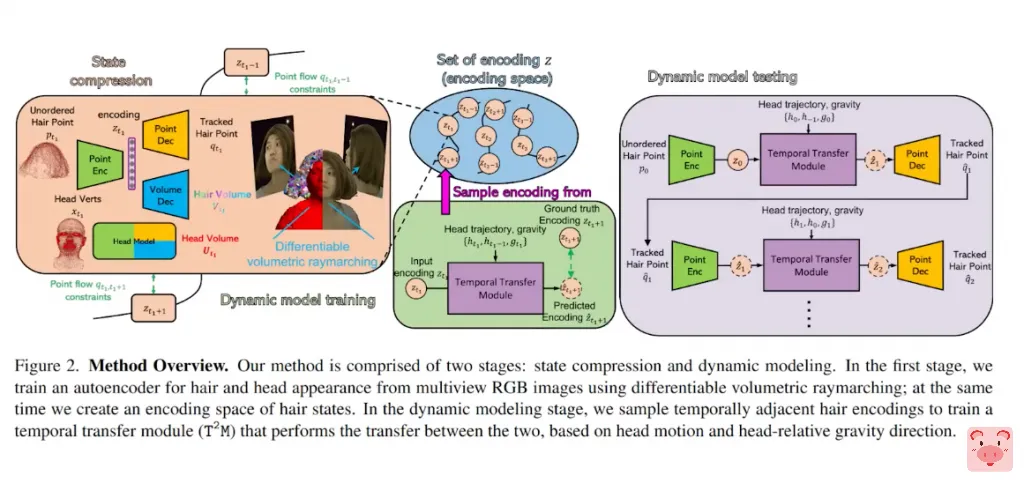
头发看起来相当逼真,然而,它是通过像nerfs使用的体积渲染实现的。所以在某些情况下,你可以看到头发顶端的那种奇怪的鬼影纹理。

但这就像是在渲染所有单独的头发和渲染整个使用AI学习的体积渲染运动的逼真头发之间的权衡。

有一篇关于视频到视频转换的匿名论文,叫做ReRenderVideo。这就像我经常谈到的图像到图像的视频。

他们提出了一个称为“分层交叉帧约束”的新结构,



其中涉及交叉帧注意力、颜色感知自适应潜在调整、形状感知交叉帧潜在融合、像素感知交叉帧潜在融合和帧传播。

所有这些花哨的词确实使结果看起来更加花哨。像这种吉卜力风格的人物看起来特别出色我猜这项研究专注于动漫风格的视频转换,因为这些动漫和人工智能肖像的结果看起来好多了。



代码也将很快推出。
有人向ChatGPT索要Windows激活密钥而这些密钥确实有效。

不过他们很快就打了补丁。而且它也在Google Bard上工作,这很搞笑。

Adobe已经在Illustrator中实现了Firefly。有了Firefly,您可以为设计填充、选择或生成变化。



这对于加快工作流程和测试想法来说,看起来不可思议。这家伙使用Segment Anything技术移除真实生活中的广告。
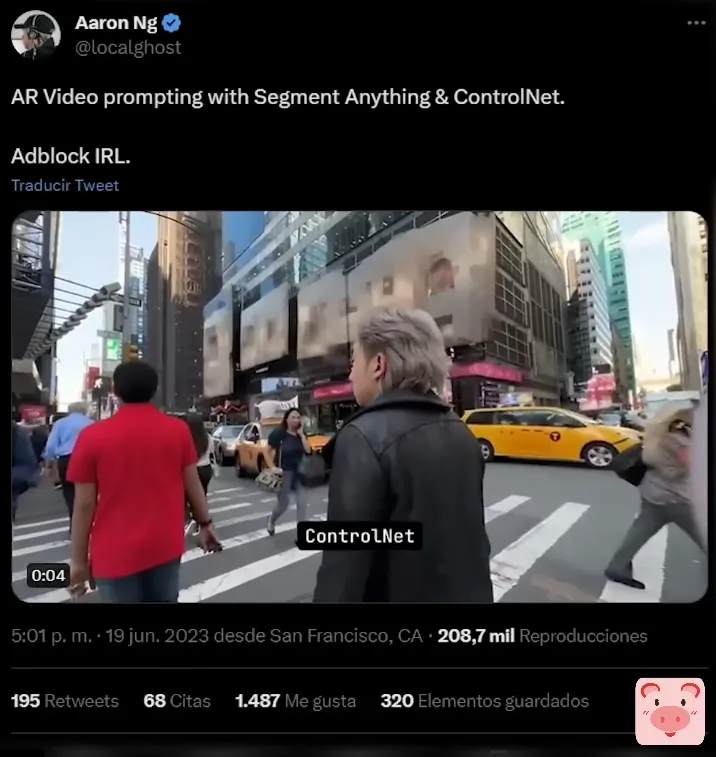
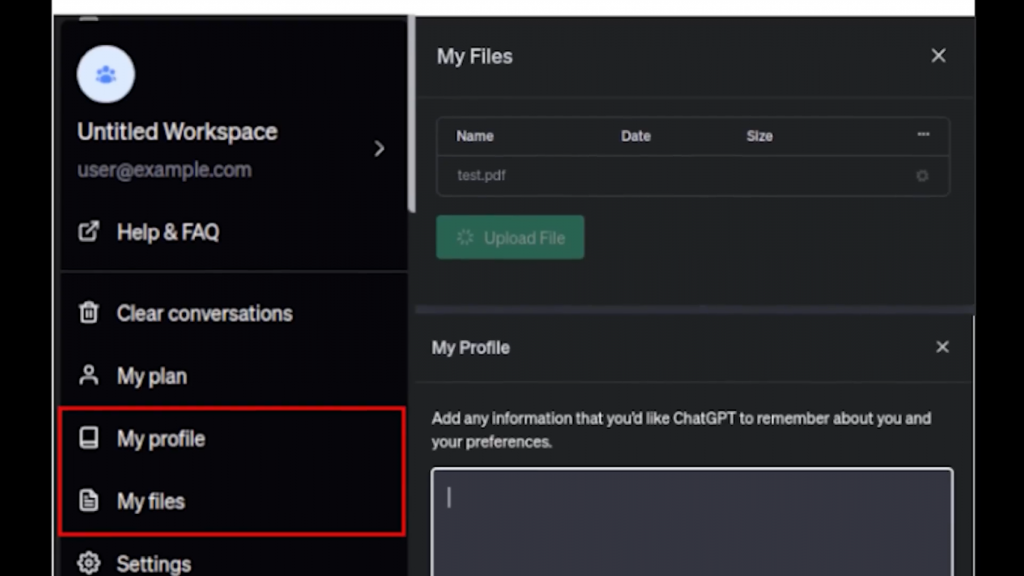
我肯定能在20年后的越狱版苹果视觉专业中看到这个。哦,对了,还有ChatGPT泄露了即将到来的功能,在那里你可以有工作空间甚至文件上传,用于阅读PDF,而无需使用插件。但是,由于它只是一个泄漏,我们应该保持谨慎。
《基于语言的机器人技能合成奖励》是一篇关于使用LLM进行机器人动作的研究论文。

主要的区别在于,它不使用低级指令或动作描述,而是使用一种操作机器人的奖励代码。这项研究能够实现90%的目标,超过了基线的50%。

有一项新的LoRa研究,称为GLoRa或GLoRa,与其他优化适配器技术相比,它的表现好得多。

它表现出更强的迁移学习、少许学习和领域泛化能力。

你是否曾经尝试过学习绘画,但当你看着自己所画的东西时,总是难以找到出错的地方,并梦想着在绘画时得到指导?

这项名为AniFaceDrawing的新研究实际上是在素描过程中把粗糙的草图转化为动漫肖像。虽然它主要是为了协助用户创作动漫肖像,而且我认为代码是不能用的,但这仍然是一个有趣的概念。

它使用StyleGAN2,而不是Diffusion,这有点说得通,因为它是互动的,所以它必须是实时和快速的。

还记得我上周提到的论文《一次追踪任何东西》(Tracking Everything Everywhere All at Once)吗?

本周DeepMind也发布了他们的追踪研究,名为TAPIR。
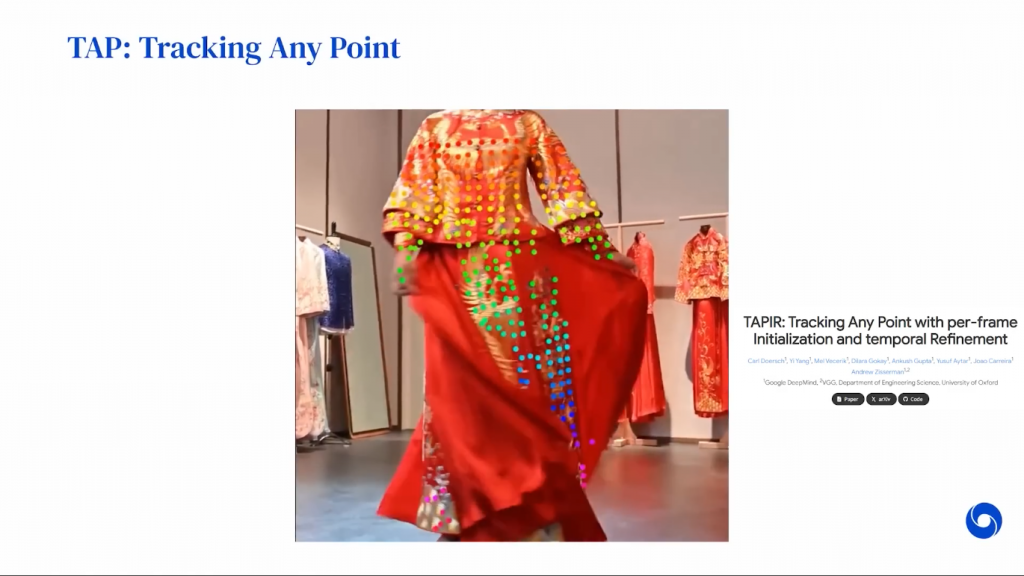
我想,他们真的很慌张,推了他们的研究,就怕它不被淘汰,但它确实看起来非常好。这项研究是关于从图像中重建3D图像,并致力于构建狗的3D模型,它被称为BITE。

你现在看到的这段录像并不是真实的。它是真实世界中生成的仪表盘录像,如果它足够小,你可能无法看出它是假的。Gaia-1是一项研究,可以生成捕捉车辆行为和场景特征的视频片段,这使它成为未来研究和训练自动驾驶汽车系统的理想选择。

这项名为Vid2Avatar的研究可以将视频中的人转换为3D模型。

与之前的研究相比,提取的人类3D模型具有高度的时间一致性和清晰的细节。

在没有经过训练的视频上工作,而且非常流畅。完全没有闪烁。这有大量的用例,而且代码是可用的,所以你现在就可以尝试。

人们对QR码的艺术有了更多的创意。这个人将二维码和ControlNet结合在一起,使二维码成为一张大图片的一部分。二维码可以使用,我只是要降低它的亮度。

这个人用稳定的扩散技术改进了PS1的图形,有些结果让人看了相当满意。

这个人做了一个不可思议的视频到视频,是由各种不同的、连贯的3D物体组成的。

让我们以Stefan Wolfram戴着派对帽看猫结束今天的视频。是的,就是那个制作了名为Wolfram Alpha的数学计算器的家伙。

对了,请在评论区告诉我你对今天的节目有什么看法。
向Andrew Lescelius、Alex J、Chris Ledoux、Alex Maurice、Deegan以及其他许多通过Patreon或YouTube支持我的人致敬。
如果你还没有,请关注我的推特,我们下一期再见。