⛓️ 无需编写代码就可以接入私有域数据 | 创建自己的AI客服机器人 | Flowise
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
在本期视频中,我将为您介绍一款名为Flowise的神奇工具!它是一个无代码平台,能让您利用大型语言模型轻松搭建强大的应用。Flowise与之前介绍过的Langflow非常相似,基于Node.js编写,提供了图形用户界面,让您可以使用来自Langchain的组件构建各种应用,如LLM链、问答检索等。在本期视频中,我还将手把手教您安装Node.js,并展示如何使用npm安装Flowise。当您完成安装后,我们会引导您启动Flowise服务。之后,我将演示如何在Flowise中创建应用程序,使用预设流程作为模板,以及如何从零开始搭建您的应用。我们会以PDF文件读取并进行问答向大家展示Flowise的强大之处。在后续视频中,我们还将向您展示如何设计提示词,以便模型只从指定文件中提取信息并回答。
总之,Flowise和Langflow都是出色的无代码工具,让您能够基于大型语言模型轻松开发功能强大的应用程序。千万不要错过这两个神奇的工具,快来尝试下吧!
相关资料
- ⛓️ Flowise Github项目地址 https://github.com/FlowiseAI/Flowise
图文讲解
今天我们要看的是另一个惊人的项目,叫做Flowise。它是一个无代码平台,可以让你使用大型语言模型建立强大的应用程序。在功能和界面方面,Flowise与另一个伟大的项目Langflow非常相似。

我已经做了一个关于Langflow的视频,所以链接会在视频的描述中出现 。
如果你有兴趣的话,可以去看看。Flowise是用Node.js编写的。现在,它基本上给你一个图形用户界面,你可以使用来自Langchain的组件来构建基于大型语言模型的应用程序。因此,例如,有一个简单的LLM链,或者你可以开发用于QnA检索的应用程序。

现在有一些例子,你可以为翻译建立应用程序,你甚至可以使用来自Langchain的记忆的对话代理。在这个视频中,我将向你展示如何在你的本地机器上安装Langflow,然后我们将建立几个应用程序,包括一个用于QnA检索。我们将提供个pdf文件,然后用Flowise来创建一个信息检索链。如果你不介意编程,并希望在本地运行所有的东西而不离开你的电脑,那么请查看我的项目,名为LocalGPT。这个项目已经在GitHub上流行起来了,我正计划在社区的支持下增加一大堆功能。所以请看一下。链接将在描述中出现。
好了,回到Flowise,让我们来看看安装过程。 他们有一个相当不错的GitHub repo。它在GitHub上已经有大约7000颗星。好的,首先让我们看一下用户界面。这就是用户界面的样子。它是一个简单的拖放界面。
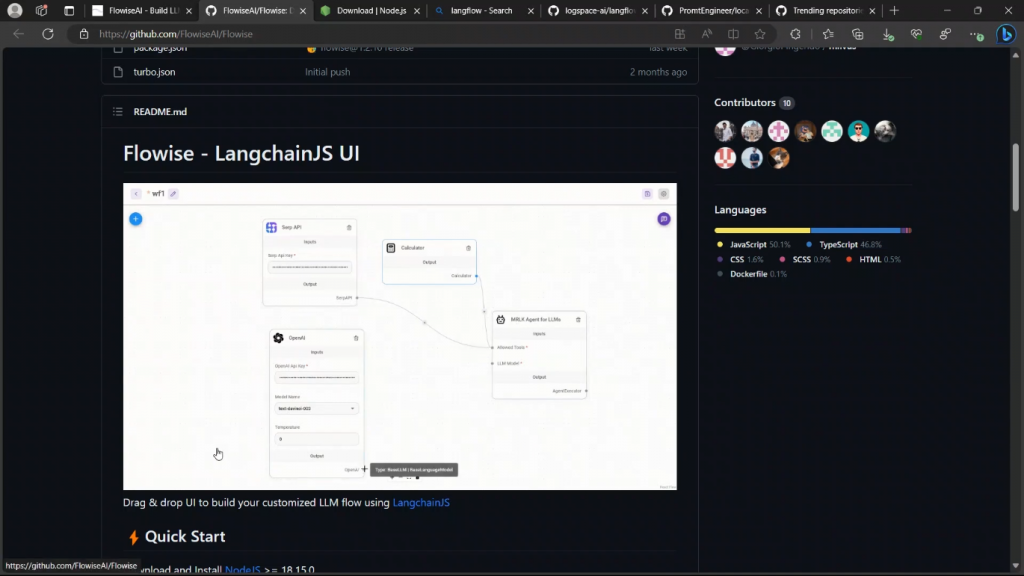
现在,为了安装Flowise,你将需要安装Node.js。因此,使用这个链接进入Node.js网站,根据你的操作系统,你需要安装它。所以我已经安装了它,我使用的是Windows机器。
所以为了测试它,你可以简单地输入npm,然后点击回车,

如果它安装正确的话,你会看到这样的东西。
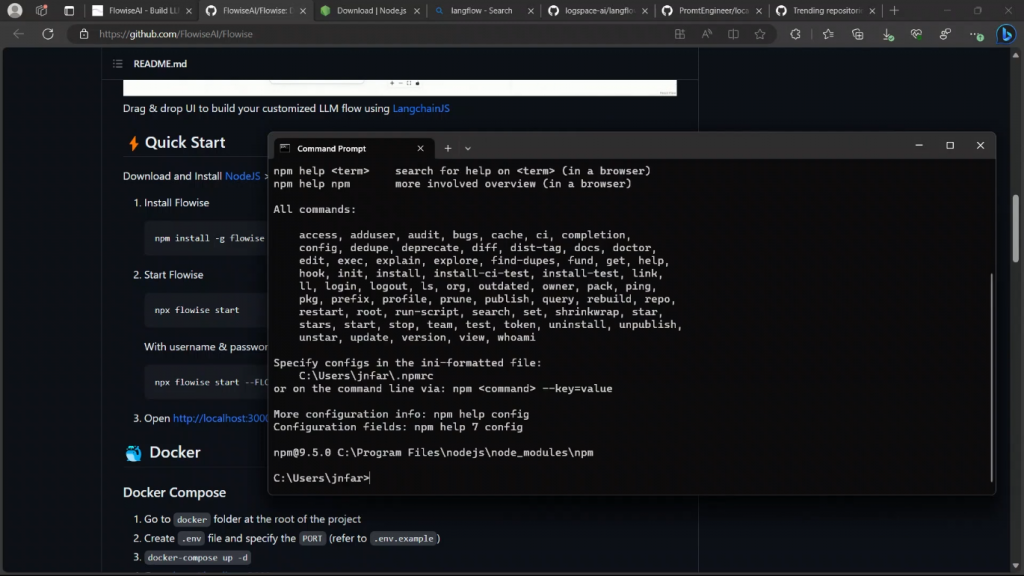
好了,对于简单的安装,我将按照这里的确切说明进行。所以我已经安装了Node.js,所以我要输入npm然后install -g,然后我们要安装Flowise。所以这就是Flowise。点击回车,让我们等待安装完成。
npm install -g flowise
好了,安装完成了。

现在,如果你想启动Flowise,你可以用两种方法来做。你可以简单地输入npx flowise start,或者你可以使用npx flowise start,然后给它一个用户名和密码。如果你想让验证你的用户,这将是很好的方式,你为他们提供一个密码,当你运行Flowise应用程序时,他们将不得不提供这个密码。

但在我的例子中,我将简单地键入第一个选项,所以将是npx flowise,然后我们将只是输入start启动它。好了,一旦你启动了,然后如果你看到这个消息数据源已经启动,Flowise服务正在监听3000端口号,对吧。
npx flowise start
现在,你实际上需要键入或去本地主机的3000端口。
localhost:3000
我个人希望他们能把这个放在这里,因为如果你是新手,你可能会运行这个,然后你不知道实际上发生了什么。现在,为了访问服务器,只需复制这个地址,然后粘贴到你的浏览器中,就可以访问它了。好的,所以我一直在玩它。我创建了几个应用程序。我们将使用这个,但我要做的第一件事是切换到黑暗主题。

因此,让我们看看几个组件。
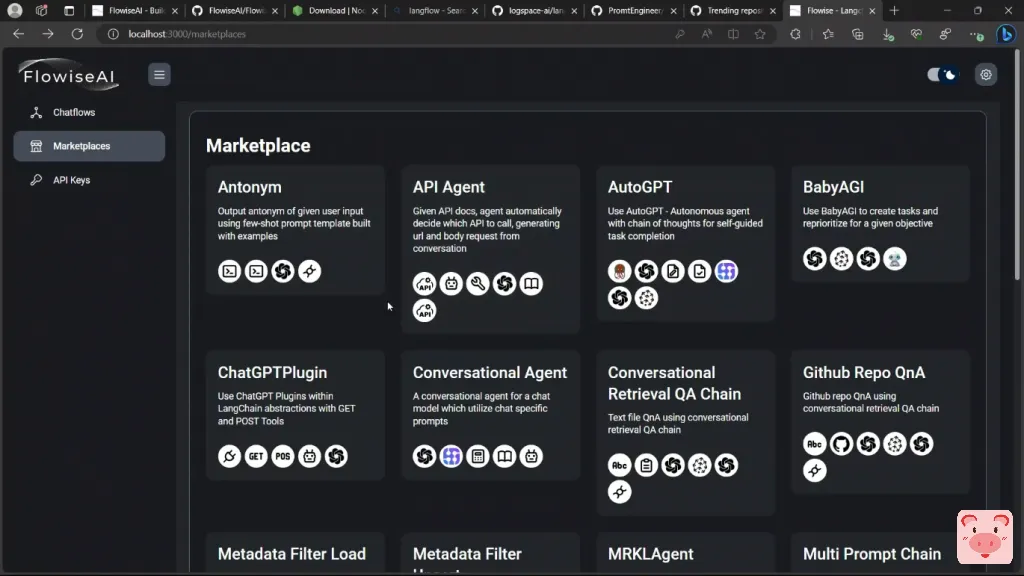
首先是聊天流。所以你创建的每一个流程都会在这里。我已经用它进行了测试,所以我有一个测试流和pdf流。稍后我们会仔细看一下这个特定的流程。那么,在这个市场上,人们已经创建了他们的预建流程,你可以作为一个模板使用。例如,这是一个用于AutoGPT的流程,还有这个用于babyagi的流程,对吧,甚至还有一些用于zapier的流程,如果你想真正将你的事情自动化,对吧。

因此,如果你想使用它们作为模板,只需点击它,

然后点击使用模板,它就会将该流程带入你的新流程,或者他们称之为聊天流程。


所以你可以给它起个名字,然后开始使用它,但我们要先看看你如何从头开始创建一个。因此,只要进入这个添加新的,它将给你一个完全的空白屏幕。

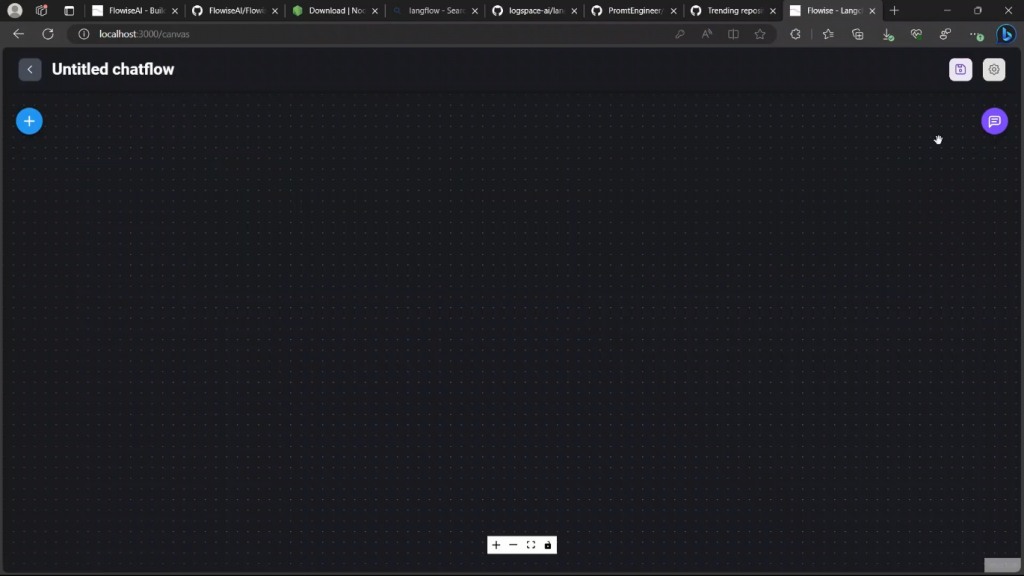
这将是一个介绍性的视频,我们将看看不同的可在flowise中使用的组件,如果有兴趣,我将创建更详细的视频。为了看到哪些组件或模块是可用的,所以点击这个加号节点,它给你所有可用的东西。所以它有一堆你可以使用的代理,你可以创建不同类型的链,它实际上是一个相当全面的列表。

现在请记住这是从Langchain获得的灵感。现在如果你不知道Langchain是什么,我建议你看看这个视频。所以在聊天模式方面,他们有Azure聊天,OpenAI,然后甚至他们有Anthropic,它也支持本地化语言模型, 例如Llama CPP或GPT4all。

所以这是非常不错的,然后有文件加载器,所以你可以加载不同类型的文件。
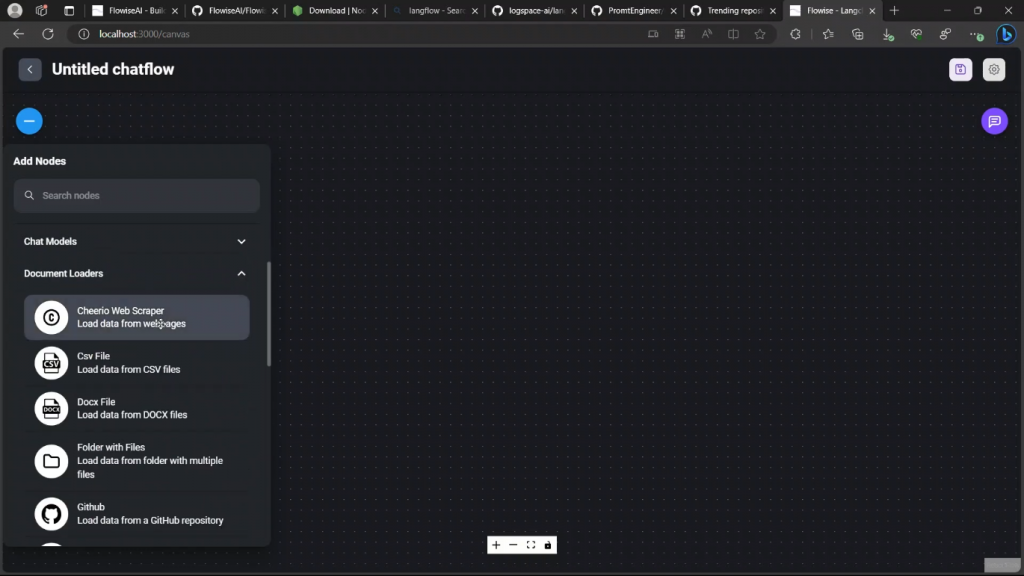
现在在嵌入方面,它支持Azure OpenAI、Cohere、Hugging Face和OpenAI,它还支持不同类型的LLMs。所以它和Langchain里面的东西很相似。
然后是不同类型的记忆,

我想它确实有一个提示模板,所以这是很不错的。

有一些检索器和文本分割器,所以我们将在我们的例子中,使用这个递归文本分割器。

所以这是相当棒的,不同类型的矢量存储。
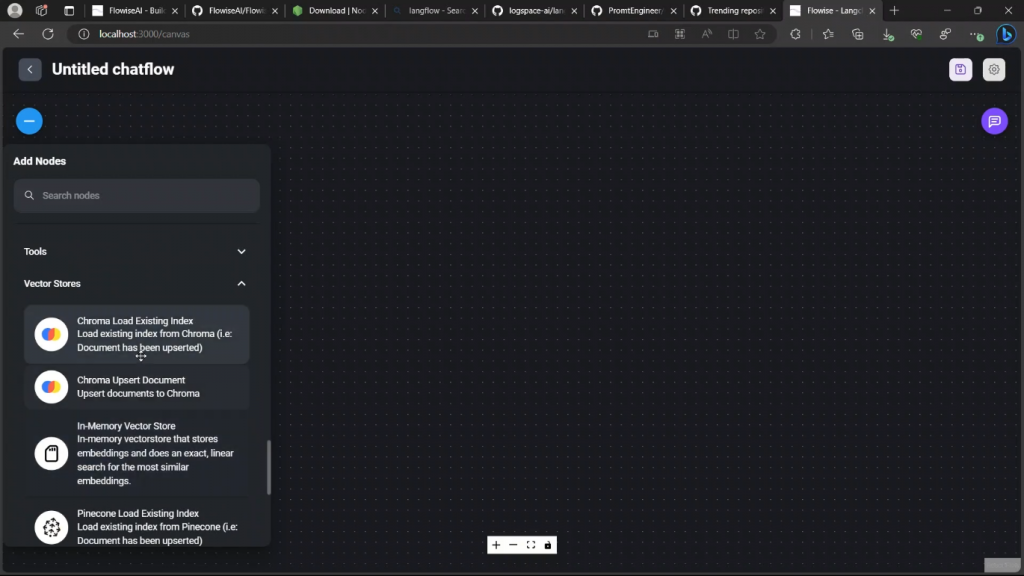
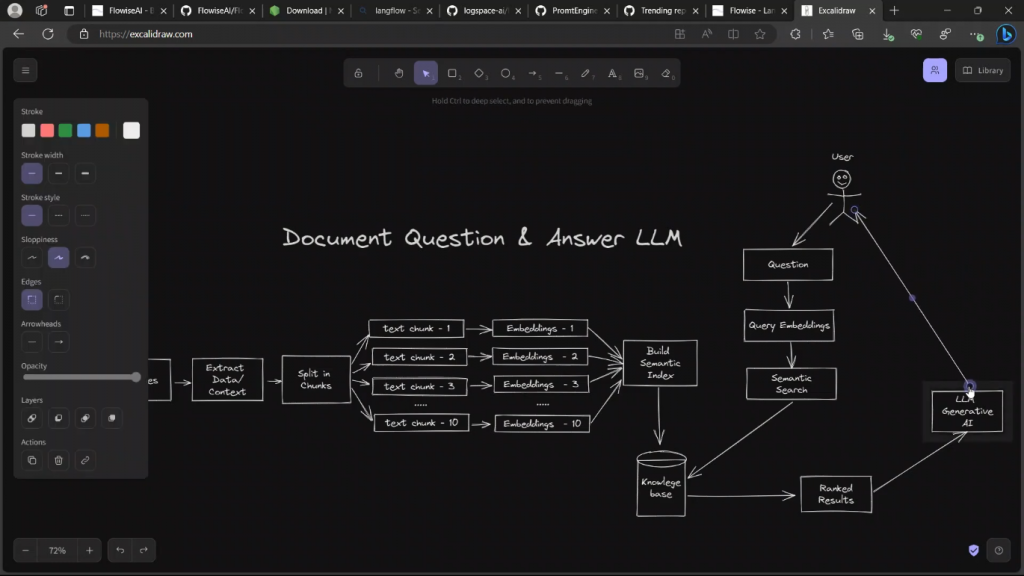
在这个视频中,我们将建立一个文档问答LLM。如果你是我频道的常客,你可能已经看到了这个图。

因此,基本上我们将上传PDF文件,然后它将把它分成不同的子文件。它将计算每个子文件的嵌入,并将创建一个矢量存储,然后每当有新的查询或问题出现时,我们将使用我们用于矢量存储的相同嵌入模型来计算嵌入。在向量存储上进行语义搜索,以检索知识页面或向量存储里面最相关的文档或块,然后对这些结果进行排序,将这些结果反馈给生成式大型语言模型,用户就会得到一个回应。如果你对这些概念感到陌生,我强烈建议你看看这段视频,

其中有极多的细节,并解释了这些组件中的每一个。好的,我们将要提供的信息是以PDF的形式提供的。所以我们首先需要一个PDF文档加载器。

所以简单地进入文档加载器,查看PDF加载器的位置。
所以你可以简单地把它拖到这里。
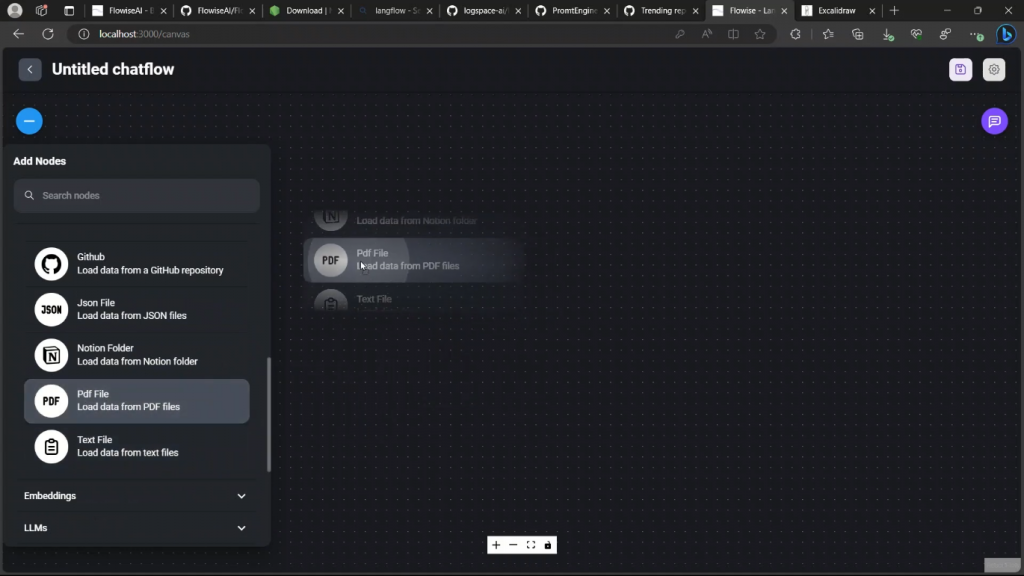
我要把它放大一点,以便我们能看到所有的东西。在这种情况下,它让你上传一个文件。现在,如果你简单地点击它,
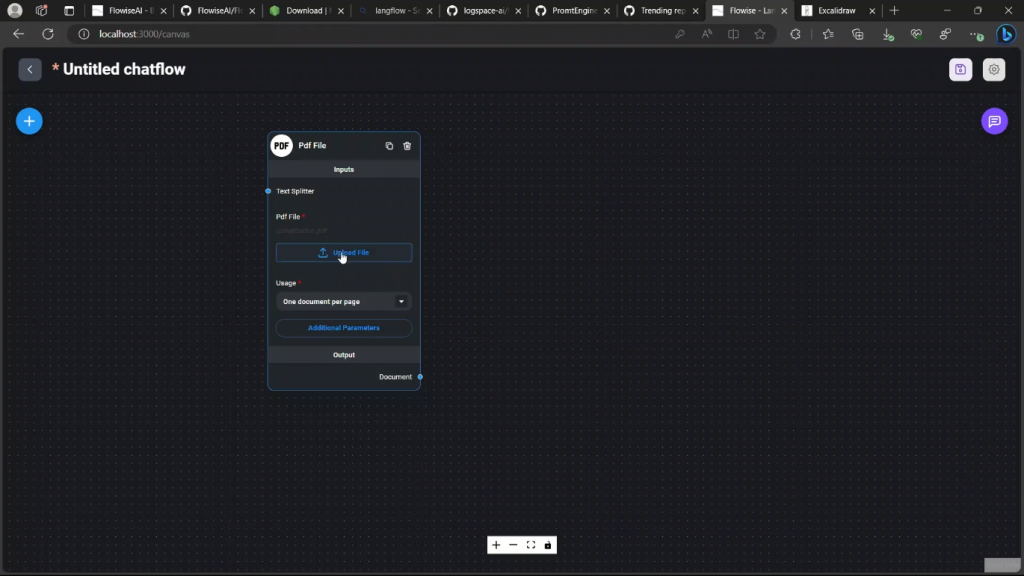
它将带你到你的电脑,你可以上传你的文件。在这种情况下,我们将上传美国的宪法。

现在它需要一个输入,对吧以及一个输出,它所期望的输入是一个文本分割器。所以我们需要提供一个文本分割器,用它将我们的PDF文件分割成小块或文件。好的,为此我们将再次回到过去,然后我们将看一下文本分割器。现在在这种情况下,我将使用递归字符分割器。
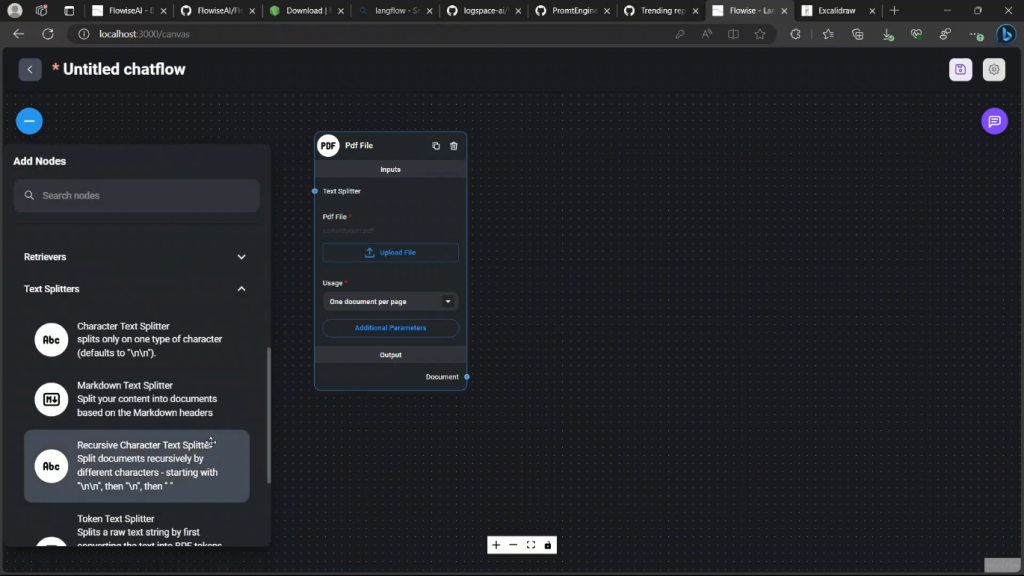
现在,为了将其连接为输入所以你只需把它拖到这里,现在你就有了你的文本分割器。

现在就整体架构图而言,所以我们在这里。我们只是简单地将我们的文件分割或拆分成不同的块。现在,默认情况下,每个块的大小是约1000个标记,我通常喜欢把重叠的部分。

接下来我们需要添加两个组件。一个是嵌入计算部分,第二个是向量存储。所以我们来添加嵌入部分。为了简单起见,我们将简单地使用OpenAI的嵌入,

但在后面的视频中,我将向你展示如何连接其他类型的嵌入。例如,来自Hugging FaceHub的嵌入,它是开源的,可以免费使用。现在,接下来我们需要把这些文件以及嵌入放在一起,并把它们放在一个矢量存储中,这样我们就可以开始计算嵌入。你这样做的方法是,我们将使用一个矢量存储。因此,让我们进入矢量存储部分,这里有不同的选择。所以,你可以使用ChromaDB、记忆矢量存储(In-Memory Vector Store)、PineCone以及其他一些选项。对于这个简单的例子,我将会使用记忆矢量存储。现在在这种情况下,我们只需连接我们创建的文件块和嵌入模型。
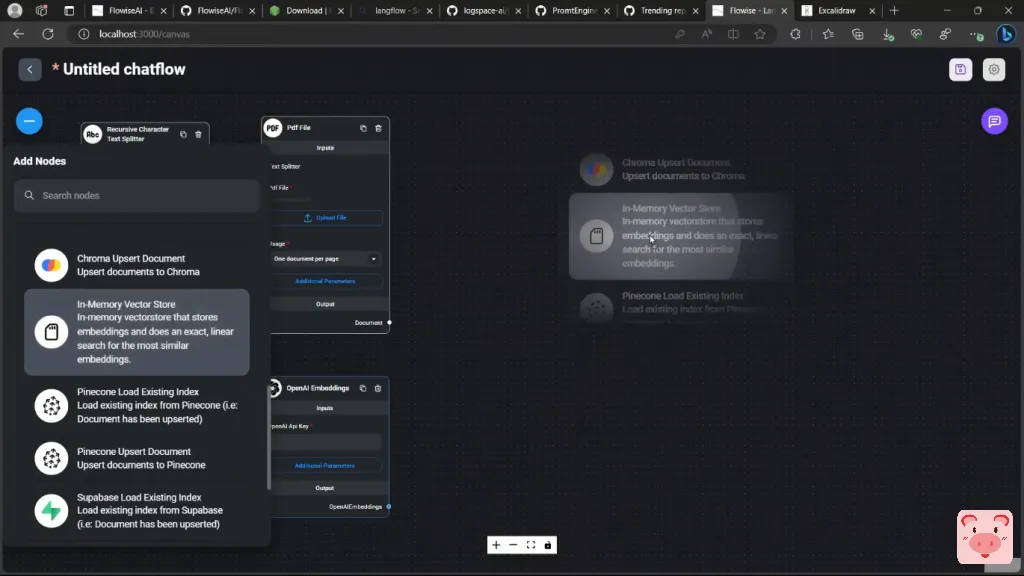
所以这是OpenAI的嵌入模型,输出将是一个内存检索器。所以理论上,我们创建了一个知识库。现在我们需要处理第二个部分,即当有人问问题时实际的信息检索部分。因此,为此我们将创建一个对话式检索的问题和答案链。

所以我将进入链的部分,然后我们将看看这个对话式检索的问题和答案文件Q&A链。
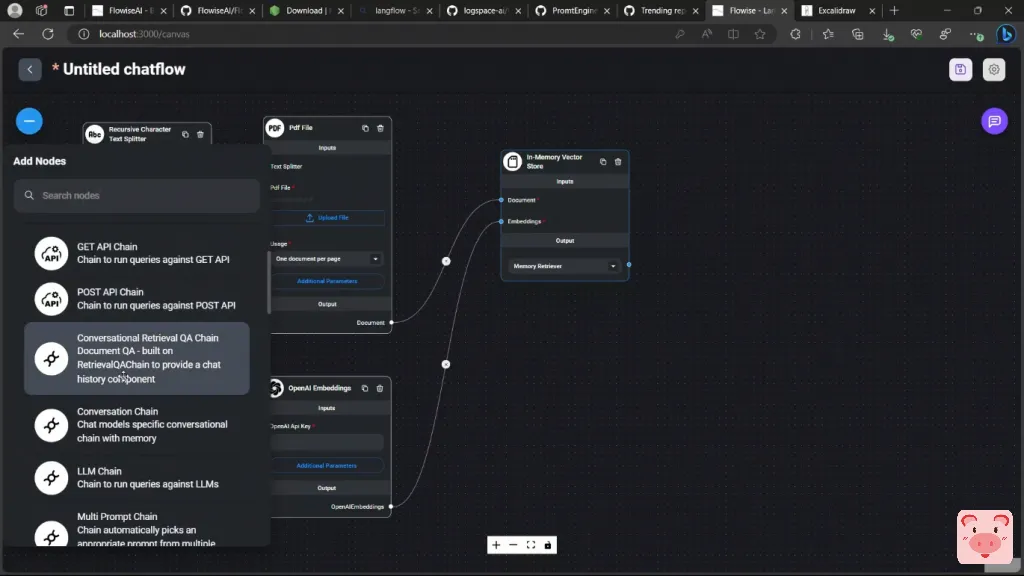
所以让我们把它带到这里。现在它期望有两个输入。一个是语言模型,第二个是向量存储检索器。所以向量存储检索器是从这里输入的,

现在我们需要添加一个语言模型,这就是这里的语言模型。

实际上,我已经表示了两次,所以我打算把它去掉,所以这就是它的样子。
我们会得到结果,现在我们需要一个语言模型在我们的链条中,或者实际上在聊天流程中。因此,让我们简单地去看看这里的不同的LLMs。所以对于这个简单例子,我将使用OpenAI的LLM。

所以我将把它带到这里,然后我们需要连接它。

好的,就是这样。现在就不同的模型而言,我认为它现在不支持ChatGPT或GPT-4。

我可能是错的,但这里是你看到的选项。现在也有一些额外的参数。例如,最大令牌最大令牌顶部概率、批处理大小超时等等。你可以调整这些参数。同样,对于OpenAI的嵌入模型,也有一些额外的参数,或者你甚至可以看一下pdf文件阅读器,对吗。所以有不同的选项,你可以设置。在这个简单的例子中,我们不打算改变任何东西,但我们将保持一切默认。好的,现在因为我们使用OpenAI作为模型,既用于嵌入,也用于LLM,所以我们需要提供我们的OpenAI API密钥。好的,我复制了我的API密钥。我要把它贴在这里,也贴在这里,对吧,

然后你需要做的是你需要简单地去保存你的聊天流程。因此,让我们把它称为DOC_Chat。

好的,我现在要保存这个。好的,一旦你保存它,你会看到这个代码符号。现在这为您提供了几个选项。

例如,如果你想把这个嵌入到一个html文件中,那么你所需要做的就是简单地复制这个html并把它添加到你的html文件中,你就会有一个聊天栏,同样你也可以在API调用中使用这个。
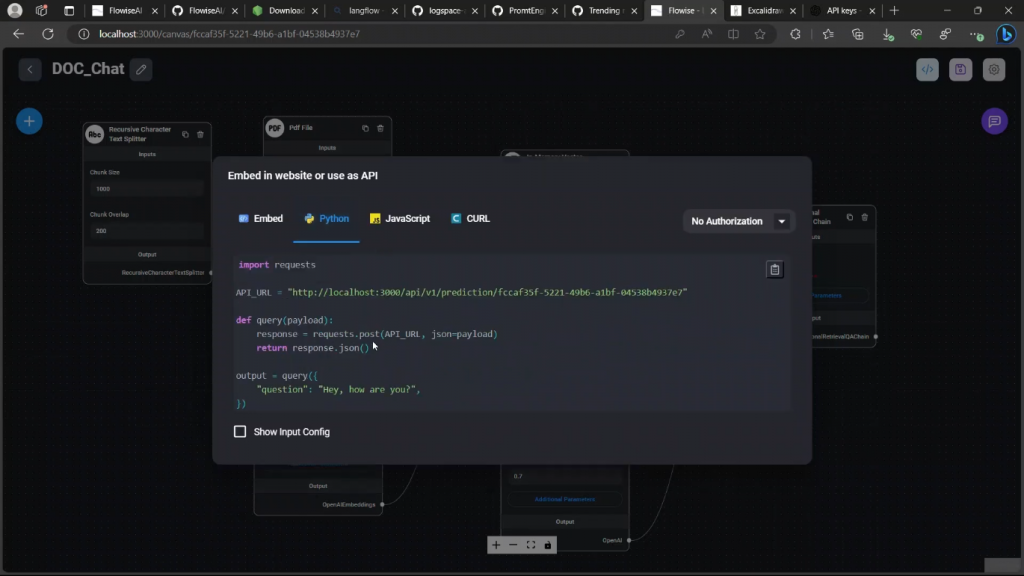
例如,这里是API URL,如果你用Python做的话。现在注意到它使用的是你的本地主机,对吧。所以为了在生产环境中部署它,你可能想把它托管在其他地方,但这是你要做的查询方式。我们将在另一个视频中看到这一点,对吧。然后有一个简单的示例代码,可以在javascript中准确地做到这一点,或者如果你想通过命令行做到这一点。


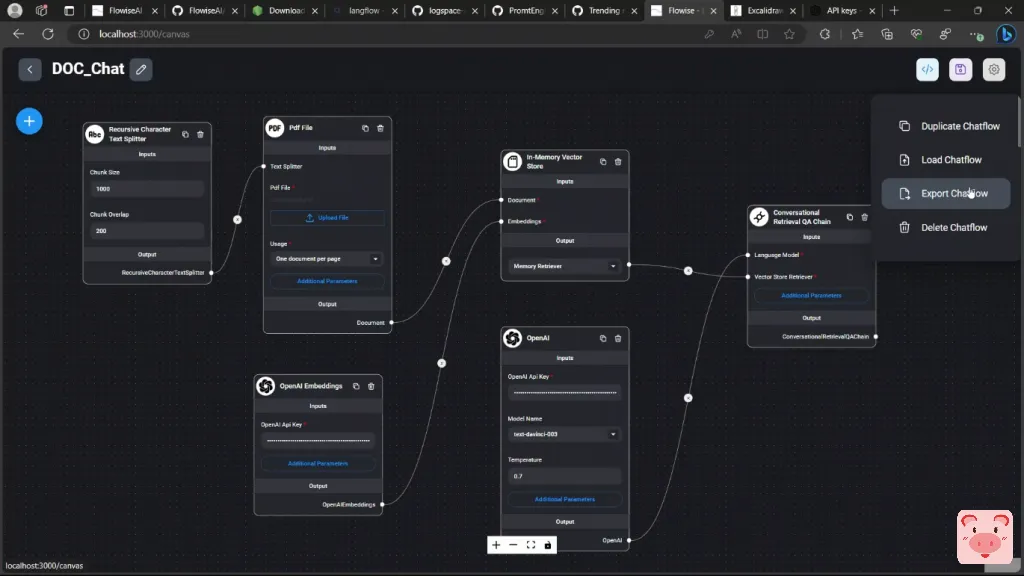
现在在其他选项方面,你可以复制你的聊天流程,或者如果你已经导出了聊天流程,你也可以加载它。

如果你导出这个聊天流程,它将简单地创建个json文件,其中有所有这些信息列在里面。
现在,一旦你创建了你的流程,然后点击保存。你可能需要等待一下,但随后你可以点击这个聊天标志,你可以输入你的问题并开始与你的文件聊天。现在,有时当你点击这个时,你会看到这个是灰色的,你不能与机器人聊天。

在这种情况下,我实际上会建议你简单地进入终端,对吧。输入ctrl c,这样它就会停止你的web服务器,并再次启动它,对吧,并再次进入同一进程这似乎有帮助。
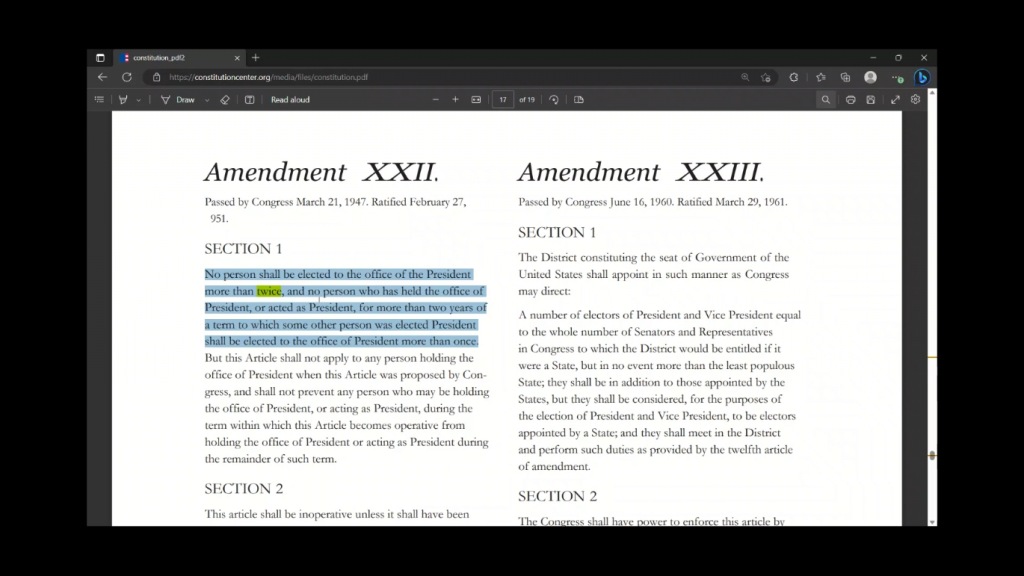
好了,我们可以开始和文件聊天了,让我问几个简单的问题。所以我想问的第一个问题是,总统的任期限制是什么,让我们看看它得出的结果。这就是它得出的结果。

因此,任何人都不应该被选入总统办公室超过两次,而且在其他人当选为总统的任期内,担任总统或当选为总统超过两年的人,不得被选入总统办公室超过一次。

好吧,这是一个非常有趣的答案,但让我们看看我们是否能在原始宪法中找到这个。好的,所以看起来它实际上只是从这里得到了答案,并返回了整个小段。这很有意思。
好的,接下来我问它根据文件的文本,美国有多少个州。由于最后一个修正案是基于1992年的,所以它实际上得出了50个州的正确答案。
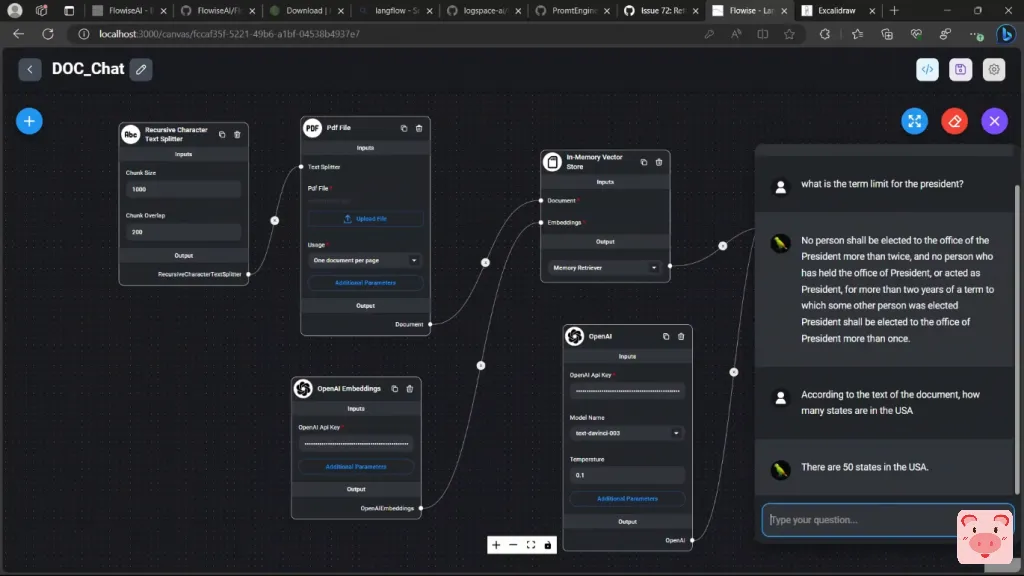
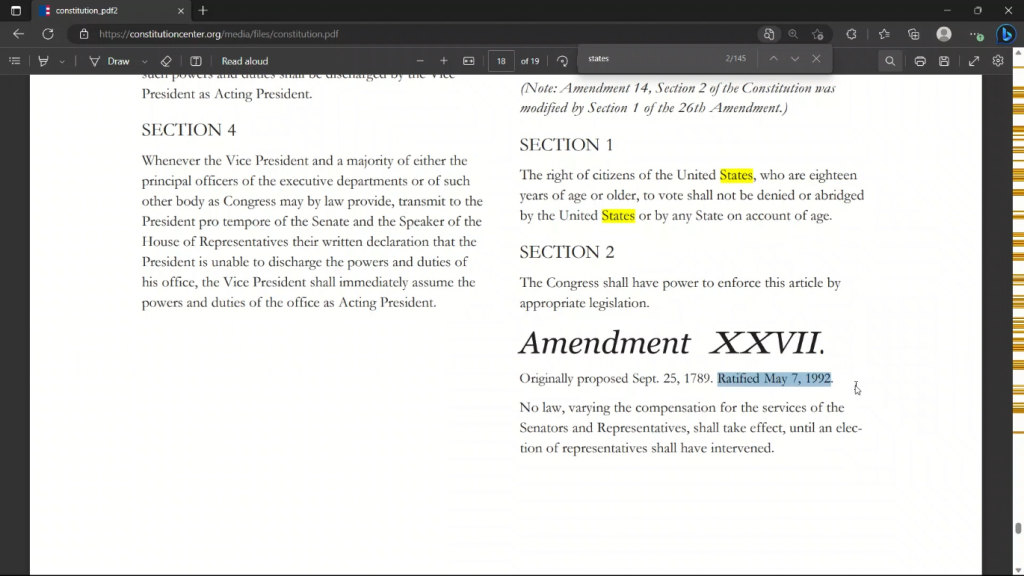
现在,我问的另一个问题是,会议和国会的作用是什么,它有点像得出了这个答案。

现在要意识到的一件事是,我们使用text-davinci-003作为大语言模型。这意味着它实际上也能获得当前的信息。现在为了简单地从文件中提取信息,我们需要做一些提示工程。在随后的视频中,我将向你展示如何设计提示词,以便强迫模型只从你提供的文件中提取信息。总的来说,Flowise就像Langflow一样是一个伟大的无代码工具,可以让你在大型语言模型的基础上建立强大的应用程序。我建议大家实际检查一下这两个工具。如果你想在大型语言模型的基础上建立自己的应用程序,并想弄清楚其可行性,我确实提供咨询服务。如果需要咨询,请查看视频描述或置顶评论以获取更多详细信息。我们还有一个discord服务器,它实际上正在增长,有一些很棒的人在不同的项目中互相帮助。如果你正在寻找一个志同道合的人的社区,我会推荐大家去看看。如果你喜欢你在这个频道上看到的东西,并想支持它,你可以查看视频描述中的几个链接,了解如何做到这一点。一如既往地感谢您观看,我们下期再见!