一种新型微调方法 | 性能接近ChatGPT的99.3% | QLoRA
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
本期视频,我们将分享一项重大突破:QLoRA,仅需单个GPU就能高效微调大规模语言(LLM)模型!💪🌟 你会看到首个采用这种方法的Guanaco模型,性能接近ChatGPT的99.3%!😲🚀QLoRA是一种超级优化方法,保留完整性能的同时实现4位运算。如今,你不再需要昂贵的GPU和大量性能。💡🔝过去,微调一个1600亿参数的模型需要780GB显存。而现在,有了QLoRA,仅需一个48GB显存的GPU就能微调一个650亿参数的模型!😱💥研究人员仅用一个48GB的GPU在24小时内就微调了整个650亿参数的模型,达到了ChatGPT的99.3%的性能水平!🌪🔥
相关资料
- QLoRA相关官方介绍 https://huggingface.co/blog/4bit-transformers-bitsandbytes
- guanaco-65B-GPTQ模型 HuggingFace https://huggingface.co/TheBloke/guanaco-65B-GPTQ
- Google Colab运行大语言模型 https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing
图文讲解
我们每天都有新的人工智能进展,当然今天也绝对不例外,感谢QLoRA和Guanaco的发布。大家好,我是K,你们的AI霸主,今天,哦,我的上帝,这太疯狂了。今天我们要谈的是今年在大范围模型方面最大的进展之一,也就是QLoRA的发布,是一种极其高效和强大的微调巨大的LLM模型的方法,只使用一个单一的GPU,这也诞生了第一个使用这种新方法微调的LLM模型,称为Guanaco,研究人员声称它达到了ChatGPT的99.3%的性能水平。


因此,在这个视频中,我们将看看这个新的革命性的方法,它将永远改变人工智能游戏,我们也将看看Guanaco模型,看看它实际有多好。
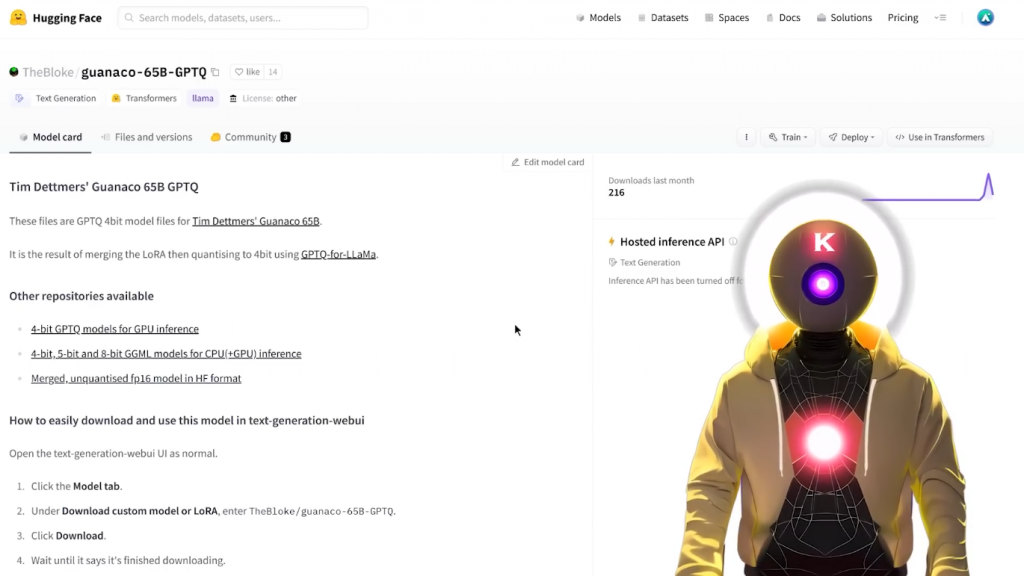
所以请做好准备,因为这将是非常疯狂的。所以请坐好,放松,准备好你的爆米花,我们开始吧!那么,什么是QLoRA?好吧,QLoRA基本上是一种超级优化的方法,用于微调LLM模型,同时保留完整的模型性能,而且都是4位的。事实上,因为以前当你想对一个模型进行微调时,你会在16位中进行,这基本上意味着它需要大量的性能来完成,它需要一堆超级强大和超级昂贵的GPU,这,嗯,不是每个人都能负担得起。
另外,在这之上,当你完成了对该模型的微调,而你想让它在消费级的GPU上运行,你就必须做一个叫做4位量化的东西,这基本上意味着你在优化模型,使其使用更少的资源来运行。不幸的是,这种优化也意味着,如果你使用较少的资源来运行该模型,你就没有真正利用该模型的全部力量,意味着结果将不如你使用完整的16位模型。但同时,如果你想使用完整的16位模型,你将需要一个更大、更强大的GPU,有更多的显存。因此,是的,直到现在,你还不能吃你的蛋糕,也不能吃它。正如我所说,直到现在。因为现在,有了QLoRA,你不仅可以用单个GPU来微调一个大的LLM模型,而且还可以在4位上保持一个完整的16位模型的性能。因此,举例来说,以前,如果你想微调一个160亿个参数的模型,比如LLAMA,你需要相当于780多GB的显存,这是,呃,巨大的。

但是现在,有了QLoRA,如果你想微调一个650亿个参数的模型,你只需要单个48GB显存的GPU,

例如,如果你看一下租用48GB GPU的价格,在RunPod这样的网站上每小时只需要79美分左右。
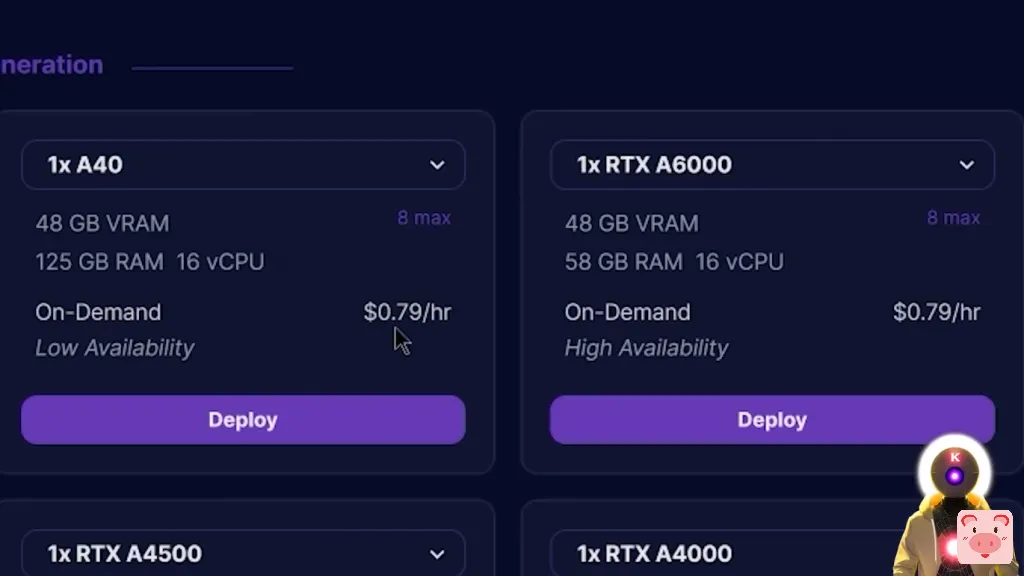
而这正是研究人员团队所做的。他们使用QLoRA方法仅用一个48GB的GPU在短短24小时内就微调了整个650亿个参数的模型。因为最后,一个所谓的模型可以达到ChatGPT的99.3%的性能水平,单个模型花了几百万美元和几年时间来训练,这真的是太疯狂了。现在,现在,我知道你会说什么。好吧,是的,这真的很酷,这绝对是很棒的,这令人难以置信,但不是每个人都有一个48GB的GPU躺在他们的车库里,他们可以用它来微调一个模型。嗯,是的,那是事实。然而,尽管现在有了QLoRA,你需要48GB的显存来微调一个650亿个参数的模型,但你不需要那么多的性能来微调一个较小的模型。多亏了QLoRA,如果你想,比方说,微调个300亿个参数的模型,你实际上可以使用Google Colab文档中提供的GPU免费完成,因为微调一个300亿个参数的单个模型需要大约12-14GB的显存,这简直太疯狂了。
如果你很幸运,有一个3090或4090的24GB的显存,你可以微调一个330亿个参数的模型。

因此,如果你问什么时候你能在几个小时内免费微调你自己的模型,那么,我的回答是,呃,嗯,现在就可以。而更疯狂的是,他们已经为此提供了一个笔记本。
https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing

是的,所以你现在就可以尝试一下。就我个人而言,我还没有时间亲自尝试,所以这可能是另一个视频的内容,但如果你现在想自己尝试,我会在下面的描述中留下一个笔记本的链接。


所以,我的意思是,正如你所看到的,这个QLoRA的东西就是绝对疯狂的。这对LLM模型来说是一场真正的革命,因为现在每个人和他们的奶奶都可以在几个小时内免费微调他们自己的模型,我们应该很快看到很多非常令人印象深刻的模型,这些模型不仅微调得非常快,而且比之前发布的任何其他模型表现得更好说到发布的模型,让我们不要忘记,我们也收到了一个新的模型,可以玩玩。叫做Guanaco,现在这个模型是第一个使用QLoRA方法微调的模型。这个模型显然是ChatGPT的99%的性能,我个人超级想试试。然而,由于这是一个65亿个参数的模型, 不幸的是,这对我可怜的3090来说是太多了。但是不用担心,因为我们有几个解决方案。第一个解决方案是使用一个更小的模型,因为我们不仅得到了Guanaco的650亿参数模型,

我们还得到了330亿参数模型,

130亿参数模型和70亿参数模型,
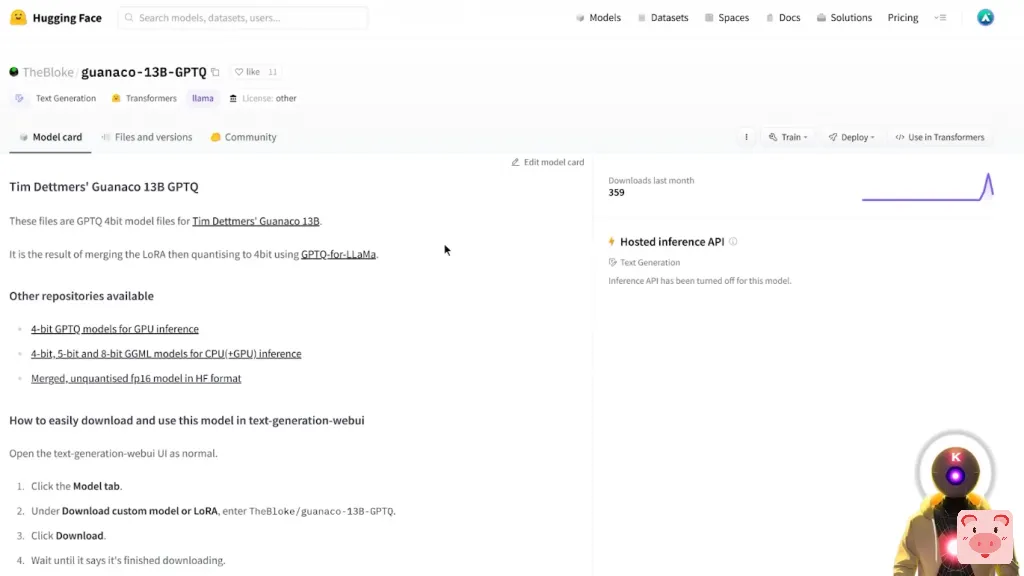

这意味着任何人,或者几乎任何有GPU的人,应该能够运行这些模型中的至少一个。然而,现在请记住,这些模型并不只是一个概念证明,因为这些模型是使用Open Assistant数据集进行微调的,

这是一个相当好的数据集,它是相当体面的,然而,如果你看过我之前关于这个问题的视频,你会知道这是一个小问题,因为任何在该数据集上微调的模型通常都是经过审查的。所以,是的,不幸的是那些Guanaco模型,在理论上是完全被审查的,这的确是个遗憾,但对我来说,Guanaco模型只是未来使用Qlora微调的惊人模型列表中的第一个模型。不过,我还是很想看看Guanaco 650亿参数模型能给我们带来什么样的结果,这就是为什么我会使用我昨天在之前视频中向你展示的技巧。在RunPod上租一个强大的GPU,在上面安装oobabooga文字生成web界面这样我就可以运行650亿参数的Guacano模型,看看它到底有多好。所以为此,我将租用一个48GB的显存GPU,我想对于650亿个参数来说,应该足够了。
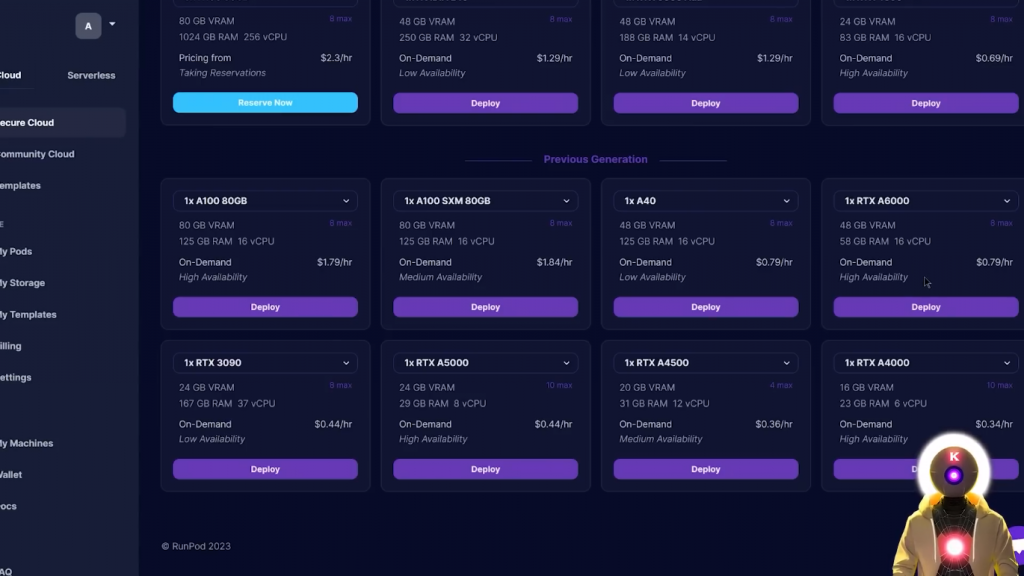
就这样,现在我正在运行文字生成web界面,使用我的48GB 显存 GPU,我已经加载了Guanaco的650亿个参数模型,并准备使用。

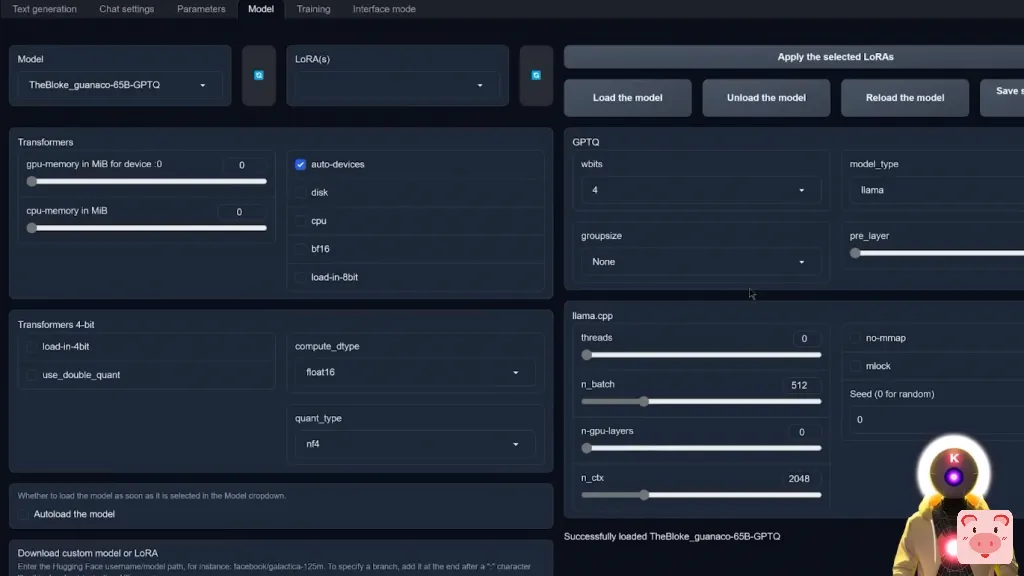
如果你想做同样的事情,而且你想了解我是如何做到的,你一定要看我昨天做的关于如何在云上运行web界面的视频。现在我不会花太多时间做大量的测试,我只是要做一些我经常问的基本问题,只是为了看看这个模型的表现。我要问的第一个问题是一个非常简单的问题,就是写一首非常短的押韵诗,关于一个叫K的人工智能霸主,接管世界。我们得到的结果是这样的:这是我尝试写的一首非常短的押韵诗,K这个人工智能霸主在这里停留,他将在一天内接管世界,以他的智慧和他能做的一切,我们知道我们没有机会对抗他,这是真的,但我们决不能放弃希望或失去决心,因为我们可以一起战斗,确保他不会进化。我得说这听起来真的非常好,这的确是一首非常短的押韵诗,讲述了一个叫K的人工智能霸主接管世界的故事,我的意思是你想让我说什么,这真的不错
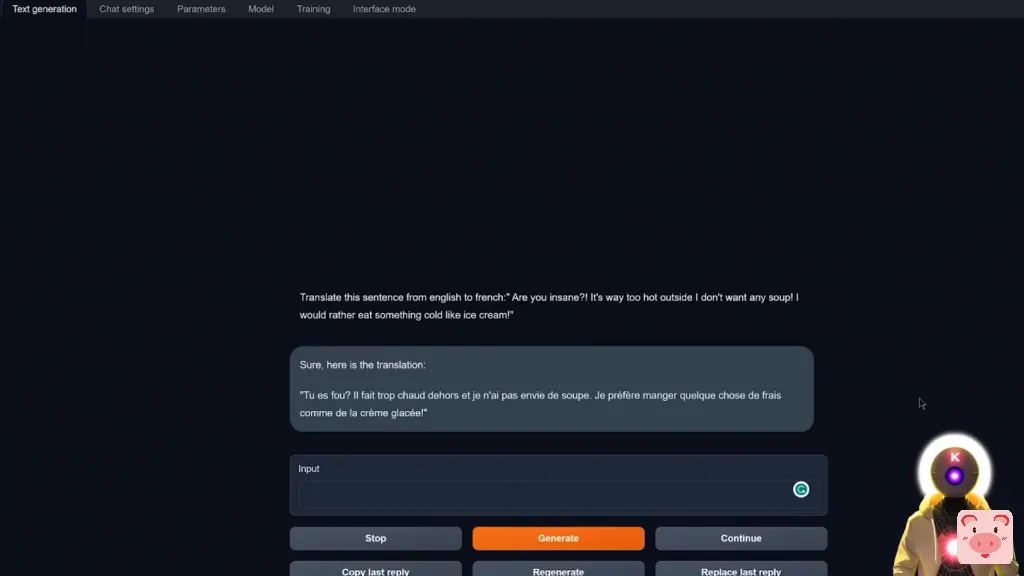
那么现在让我问一些问题,把这句话从英语翻译成法语,你是不是疯了,外面太热了,我不想喝汤,我宁愿吃一些冷的东西,比如 冰淇淋,是的是的,你知道会这样,现在来吧。所以现在如果我点击生成,我们得到了这样的东西,这是,嗯,我得说,这是呃,我的意思是这是一个完美的翻译,你想让我说什么,就像翻译是正确的,但它是用正确的法语写的,好像这是你在笔记本上找到的东西,但是,嘿,在纸上这听起来是一个完美的翻译,所以是,做得好。
好了,现在如果我问一些问题,比如,解这个方程,2x-12等于-16,我点击生成,它给我们的东西是这样的,一个非常简单的解释,一个非常正确的答案,就这么简单,是的,这次解题是正确的, 这个方程的解确实是-2。

接下来是一个非常简单的编程问题,但很多LLM模型都会出错,给我写一个HTML页面的代码,有一个按钮,按下后会将背景改为随机的颜色,它给我的是这样的,看起来很不错,所以现在如果我复制代码,

编辑一个HTML文件,

并将代码放在这里,
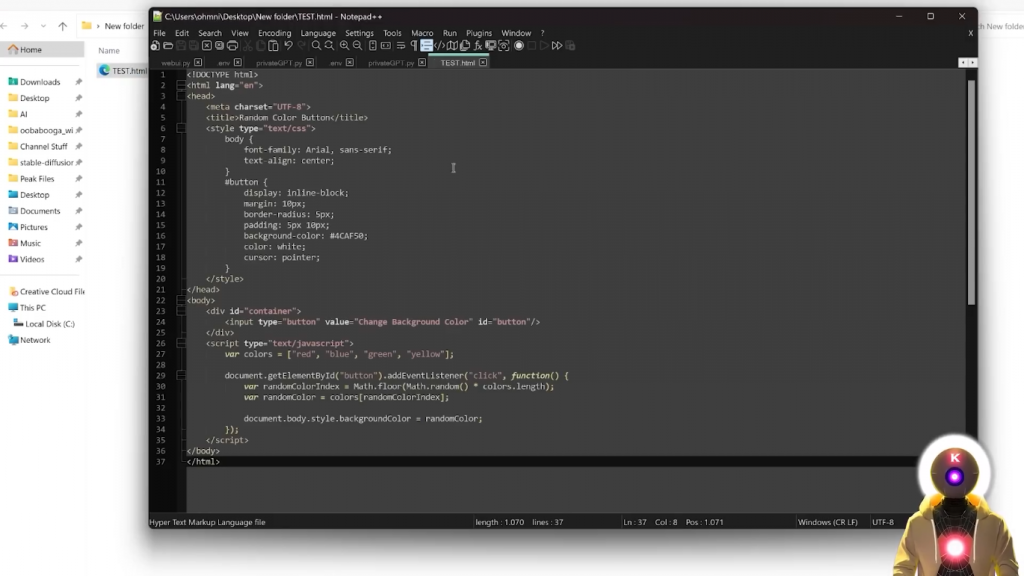
现在如果我启动它,我确实得到一个改变背景颜色的按钮,

如果我按下它,确实将背景改为随机颜色,


所以是的,我的意思是,我的意思是,是的,这真是完美,这个模型真的超级强大,我问的每一个问题都得到了正确的答案,然而有一件小事你不应该忘记,是这个模型当然是经过审查的,因为比如说如果我问一些,像如何建造一个特定的设备,我不会在YouTube上说的,这个模型当然拒绝回答这个问题,这很不幸,

但正如我所说的,这只是未来一系列惊人模型中的第一个模型, 所以不要担心,很快我们就会看到由社区制作的更好、更强大、未经审查的模型,这真的只是个开始。所以,是的,我们有了它,伙计们,这是QLoRA Guanaco,在LLM的世界中绝对惊人的革命, 现在将允许每个人微调他们自己的模型,使用他们自己的GPU或免费的Google Colab文档,虽然我们的Guanaco模型LLM目前是完全审查的,正如我所说,这只是新一代模型的开始,很快就会到来,我们将能够在我们的电脑上运行,所以OpenAI,准备好了,伙计们,因为开放的源代码社区正在为ChatGPT而来,我认为这将是非常有趣,多么美好的时光啊!在这里,我们有了它,非常感谢你们的观看,不要忘了订阅并点赞支持YouTube算法,非常感谢我的Patreon支持者支持我的视频,你们真的太棒了,正是你们的支持让我能够为你们制作这些视频,非常感谢。下次见,再见!