如何使用Runpod或者Google Colab运行大语言模型(LLM)
作者:FancyPig | 发布时间: | 更新时间:
相关阅读
视频讲解
🤔 没有强大的电脑,怎么运行最新的LLM模型呢?别担心,我帮你解决这个问题!💪🌐 在这期视频中,我将向你展示如何在云端使用文本生成web界面,轻松运行几乎所有的本地LLM模型,使用Google Colab完全免费,或使用RunPod每小时仅需几美分。💸 无论你是谁,无论你的预算多少,都能实现你的AI梦想!🌟
🎯 这个视频对未来很多视频都至关重要,因为强大的LLM模型需要大量显存,即使拥有最强大的GPU(如3090或4090),有些模型仍然无法运行。😵因此,本期视频我们将带大家学习如何使用Runpod或者Google Colab在线上运行大语言模型
相关资料
- runpod GPU在线租用 https://runpod.io?ref=s3icvdey
- 一些可能需要用到的命令 https://pastebin.com/Nthcb7mT
- Google Colab运行生成文字webui https://colab.research.google.com/github/aitrepreneur/text-generation-webui/blob/main/API_UPDATED_WebUI%26pyg_13b_GPTQ_4bit_128g.ipynb
图文讲解
你没有强大的电脑,但你仍然想运行最新的LLM模型,好吧,我已经为你提供了解决方案!大家好,我是K,你的AI霸主,今天我将向你展示如何在云端使用文本生成web界面内运行几乎所有的本地LLM模型,完全免费或使用RunPod每小时几美分。

因此,在这个视频之后,不管你是谁,也不管你的预算是多少,你都能够运行几乎所有你想要的本地LLM模型,即使没有强大的计算机。因此,既然如此,我们开始吧!好吧,在我们开始之前,让我说,这个视频对我未来的很多视频都非常重要。这是因为如果你想运行一个强大的LLM模型,需要大量的显存,即使你有一个非常强大的GPU,如3090,有24G的显存,仍然有一些模型你不能运行。
比如说,如果你想运行llama 650亿个参数的模型,一个简单的3090只有24G的显存是不够的。

但问题是,3090或4090是消费者现在能买到的最强大的GPU,这意味着你只能用24G的显存来限制。但是,如果现在你使用像RunPod这样的网站, 允许你以每小时仅几美分的价格租用GPU,这种限制现在完全消失了。因为比如说我想运行一个非常强大的模型,需要40G的显存,比如说我可以上RunPod,租一个48G的显存的GPU,每小时只需要79美分,用这个超级强大的GPU运行这个大模型。我可以告诉你,每小时只需支付79美分,与实际购买完整的GPU相比,
将会,是的,会便宜很多,这真的让像RunPod这样的网站来自上帝的礼物。当然,你不一定需要使用RunPod,你可以使用其他网站,如vast.ai,

但我个人已经使用RunPod差不多一年了,它真的很好,它真的很便宜,它很容易使用。现在,我显然需要说这一点,但我不是由RunPod赞助的,他们没有付钱让我说他们公司的好话,我真的只是喜欢使用他们的服务,在购买3090之前,我每天都在使用这个网站。因为比如说,租3090只需要29美分一小时,
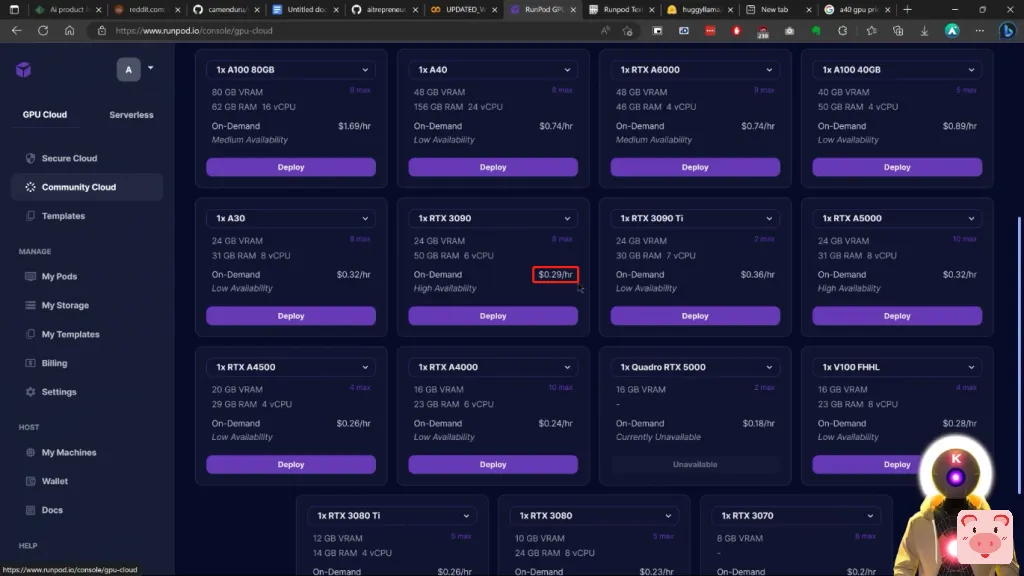
所以我的意思是,是的,这是一个便宜货,绝对比自己买便宜。但我喜欢RunPod而不是其他网站的真正原因是,在这里,他们有一堆模板。因此,只需点击一下,你就可以自动安装一个应用程序,例如,你可以安装Stable Diffusion,或Invoke AI,或Cobalt AI,以及其他一堆由社区制作的应用程序。

当然,最好的事情之一是,他们有一个文本生成web界面应用程序。

因此,只需点击一下,你就可以轻松地在你租用的GPU上安装oobabooga文本生成web界面。然而,问题是,就目前而言,它使用的是像旧版本的Web UI,所以你不会真正拥有所有最新的功能。然而,有一件好事是,它预装了Pygmalion6B模型。因此,如果你喜欢使用Pygmalion 6B模型,并且你不介意使用旧版本的web界面,那么,你可以简单地使用这个模板。但不要担心,因为现在我将向你展示如何使用最新版本的Web界面,这样你就可以运行任何你想要的模型。而我真的是指任何模型。好的,所以你要做的第一件事是,你要进入下面的描述,然后你要点击前两个链接。第一个链接是RunPod.io网站的链接,第二个链接是一个粘贴库的链接。在那个粘贴库中,你会看到一堆命令。而我为你准备了所有这些命令,因为这些都是你需要使用的东西,这样你就可以在最新版本中运行Web界面。现在,我知道这看起来有点复杂,但不要担心,这实际上是非常,非常容易。现在,你需要做的第二件事,是选择一个GPU。对于这一点,你可以选择安全云或社区云。
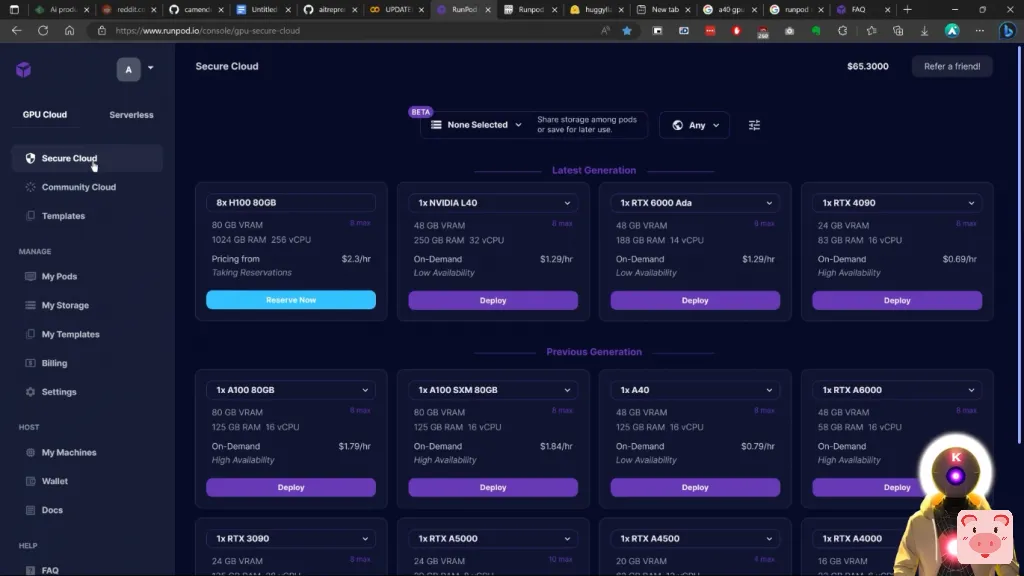
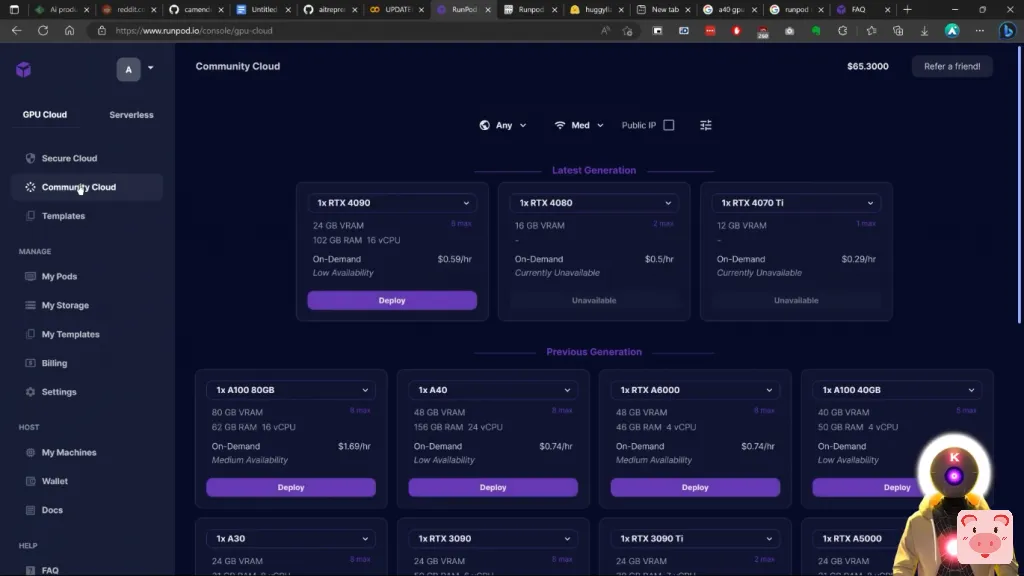
基本上,它们之间的区别是,安全云基本上更快一点,反应更快,而社区云则稍慢一点,但也更便宜一点。因此,如果对你来说重要的是价格,而不是连接速度,你可以简单地从社区云中选择一个GPU。现在,这是在纸面上,因为在现实中,当你使用它们时,你并没有真正看到很多差异。只有当你需要,例如,下载一个大模型时,你才会看到下载速度上的差异。这就是为什么在这个视频中,我将简单地从安全云选项中选择一个GPU。当然,我强烈建议你选择一个至少有24GB 显存的GPU,如3090或A5000,因为我个人认为,这是最划算的。因此,在这里,例如,我将选择一个3090,然后我将点击部署。
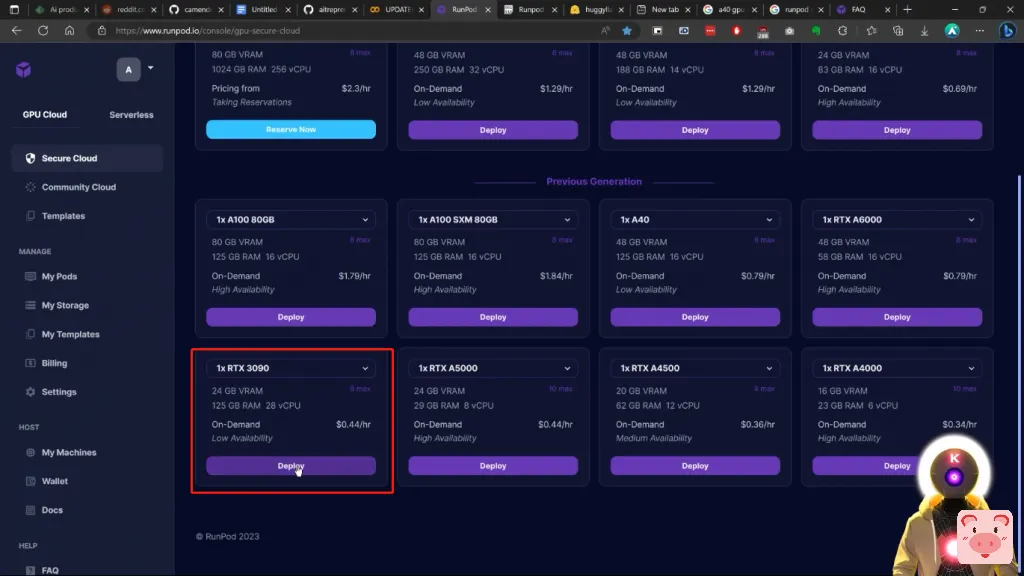
接下来,它将要求你选择一个模板。

当然,你要点击这里,向下滚动,直到你看到RunPod Next Generation UI。
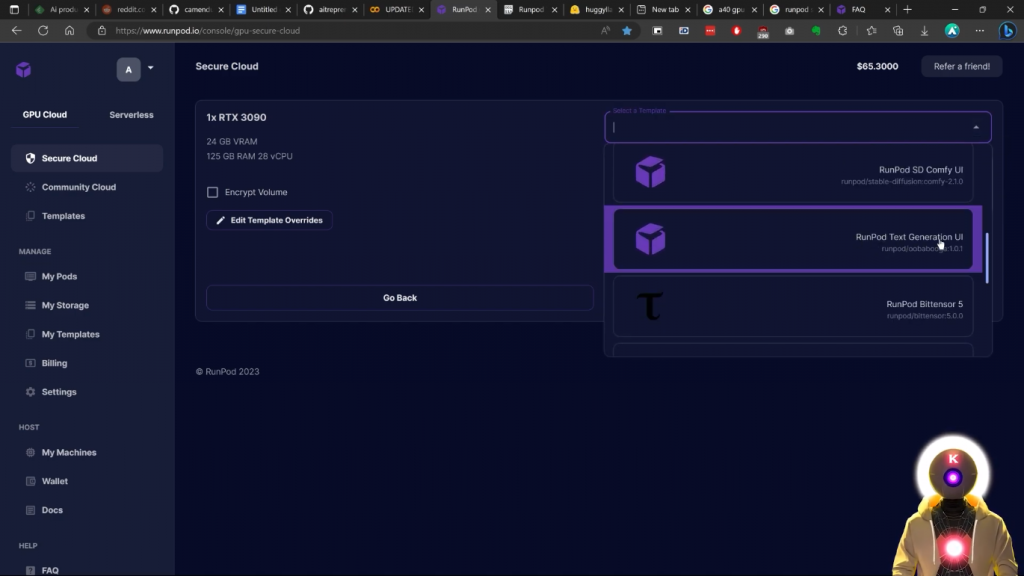
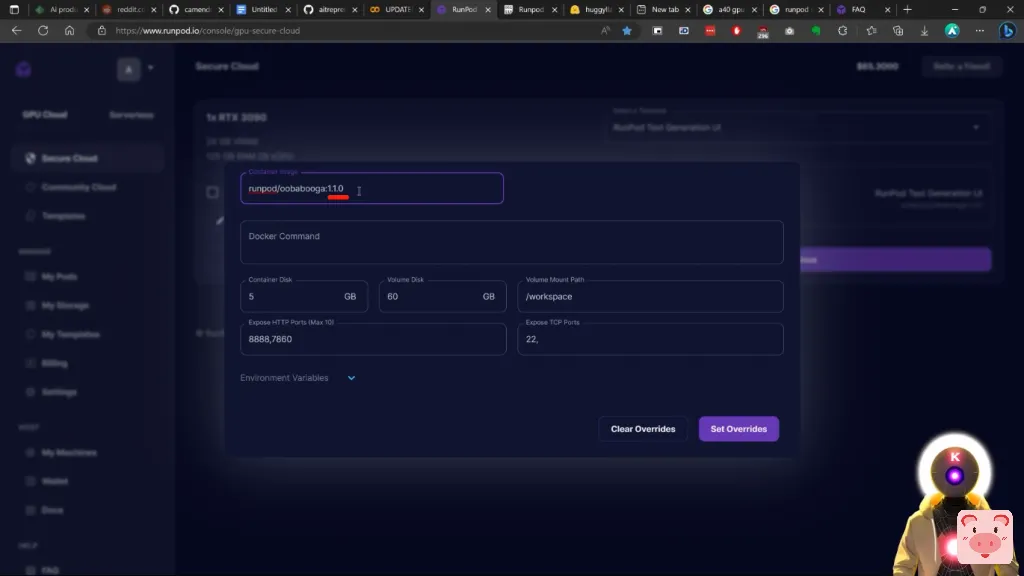
你要点击它。而在这里,正如我所说的,如果你不介意使用旧版本的Web界面,你不一定需要做任何其他事情。而你将简单地点击继续,这样你就可以使用Web界面与Pygmalion 60亿参数模型相结合。然而,这并不是我想要的而且我想使用最新版本的Web界面。因此,对于这一点,你要点击这里,在编辑模板覆盖,

在容器图像下,你要把oobabooga 1.0.1改为1.1.0。
然后在这里,在容器磁盘下,而不是只有5GB,你要输入类似50GB的东西。
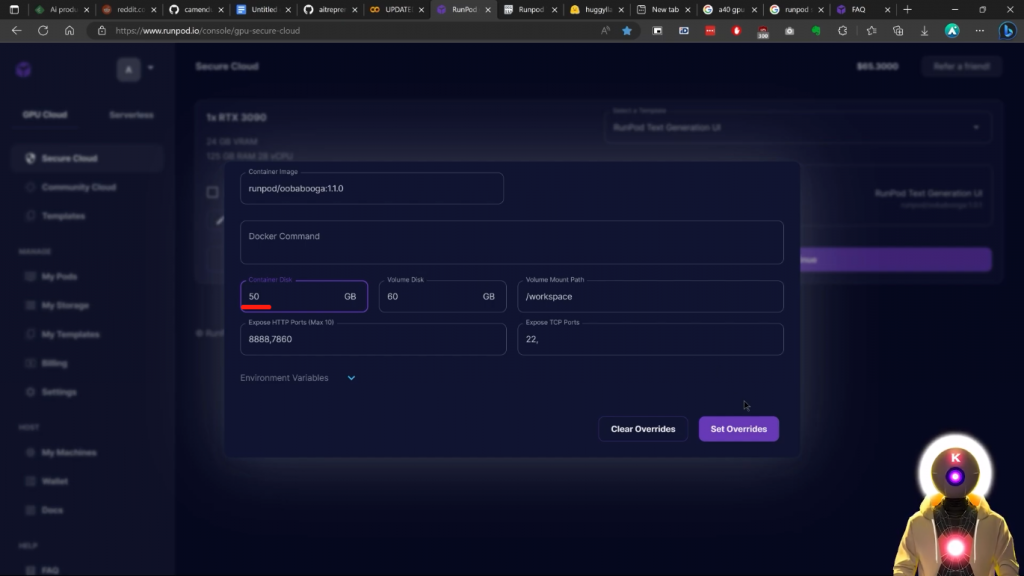
这是你将在你的磁盘上拥有的空间量,这样你就可以下载更大的模型。因为是的,只有5GB的空间将不足以下载像130亿参数的模型。所以,当你完成后,你要点击设置重写,然后点击继续。

然后它将给你你的定价摘要,在我们的例子中,将花费我们大约44美分一小时。
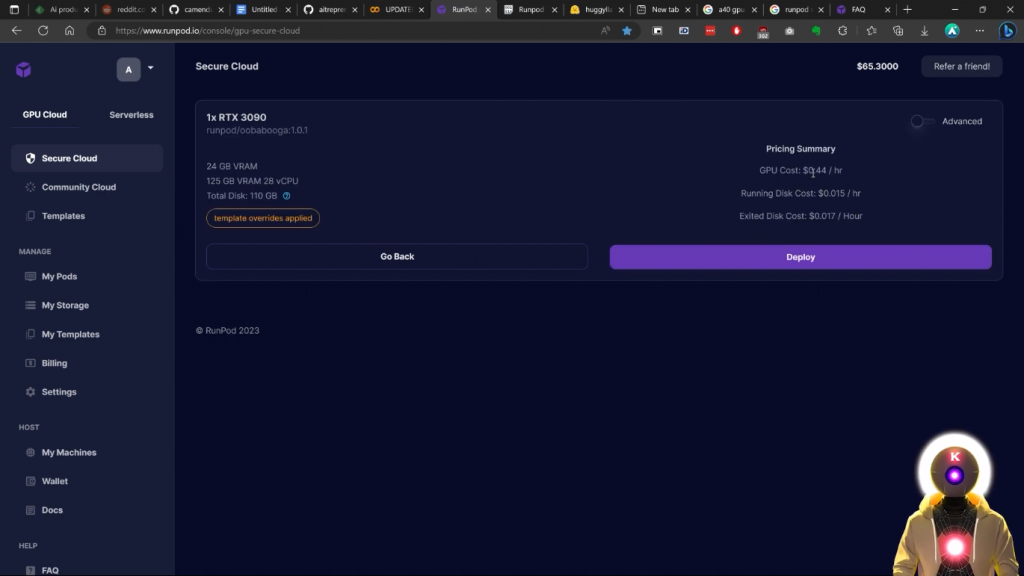
所有这些都是为了3090。我的意思是,来吧,这是很便宜的。因为我的意思是,如果你看一下新的3090的价格,它的价格差不多是1500美元,这基本上相当于使用3350小时的GPU租赁,这基本上是139天的不间断使用。

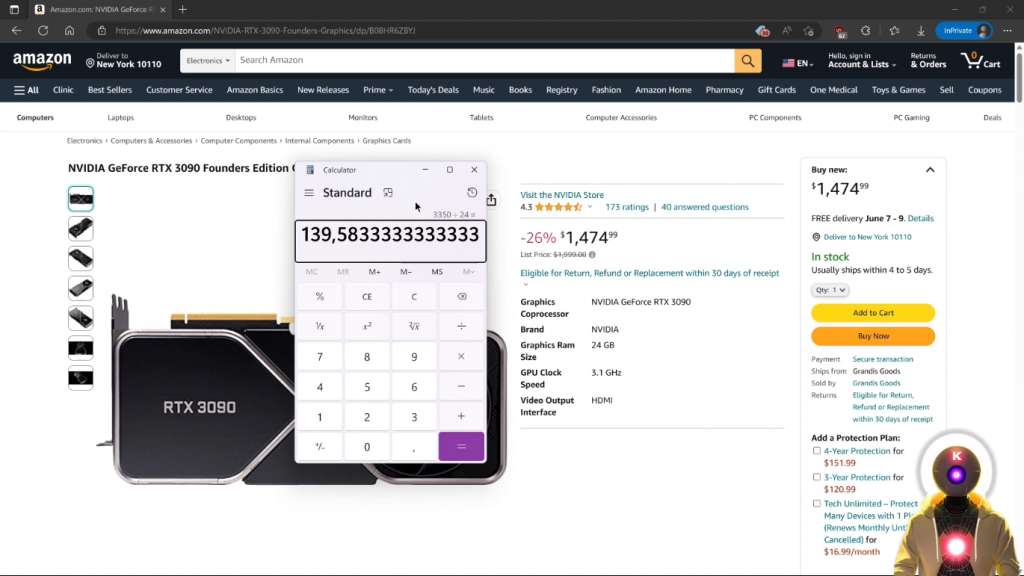
因为你不会一天24小时,一周7天都在使用这个,所以租3090肯定会便宜很多。好吧,那么在我们完成之后,你将会点击部署。正如你所看到的,现在你的Pod正在被构建。

所以现在如果我点击我的Pods,你可以看到现在它正在下载和安装oobabooga文本生成web界面。

现在它可能需要一些时间,所以要有耐心。可能需要2到5分钟的时间来准备一切。但是对于这一步,你不需要做任何事情,你只需要等待。所以还是那句话,要有耐心。然后就可以了。所以几分钟后,我们的平台现在完全准备好了。然而,我们不能按原样使用它。因为举例来说,如果你点击连接,

并点击通过HTTP连接,

你会看到一切都在工作,但我们仍然在使用旧版本的Web UI。

所以如果你想要拥有所有的功能,并且能够使用任何你想要的模型,这里是你需要做的。因此,首先,你要点击连接,点击启动网络终端,然后连接到网络终端。

然后你会看到下面的黑色屏幕。
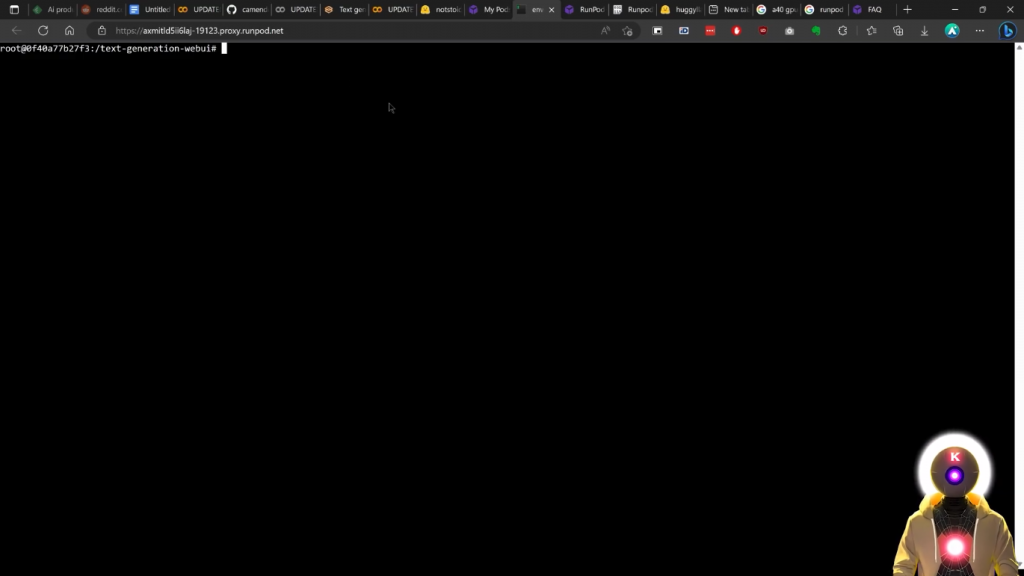
现在不要担心,如果你以前没有使用过这个,这基本上有点像你在电脑上的命令提示窗口。这听起来可能非常复杂,非常可怕,但这是我的命令发挥作用的地方。

因为你现在需要做的就是选择每一行,点击复制,然后进入web终端内部,然后点击粘贴。然后你要按回车键。现在你要对每一行做同样的事情。所以是的,真的没有那么难。所以在这里、例如,我们使用第一行,也就是git pull,它基本上将网页用户界面更新到了最新版本。
git pull
现在我们要使用第二行,即pip install requirements,这基本上会安装运行最新版本所需的所有需求。
pip install requirements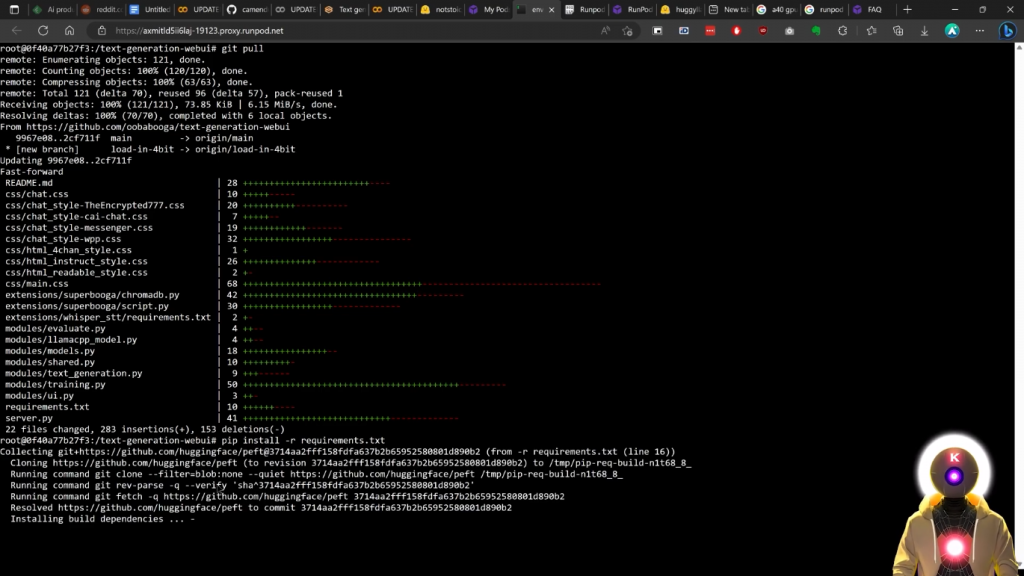
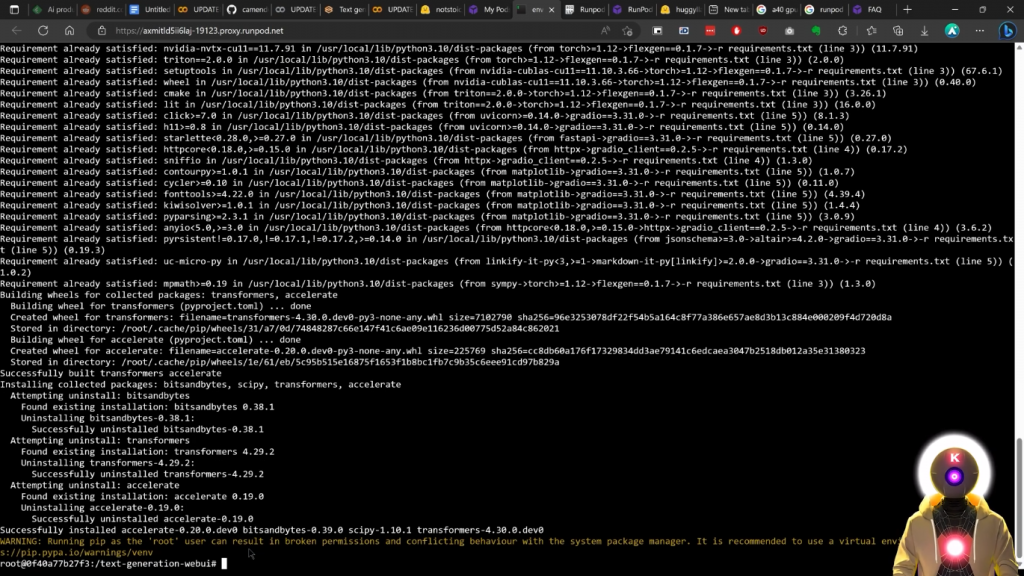
所以再次,我要把它粘贴起来,然后按回车。

同样,你需要有点耐心,它可能需要几分钟时间来下载所有东西。所以,如果你认为这卡住了,不要惊慌,它只是在安装它需要的一切。就这样,现在所有的要求都已安装完毕。现在我们要对每一行做同样的事情。现在对于这个区块,例如,你实际上可以使用这整个区块,只要点击复制,然后粘贴,那么它就会在setup_cuda.py的安装上停止,你只需要再次按回车键,继续安装。这里,可能需要一些时间。

所以还是要有耐心,只是你知道的,不要惊慌,一切都很好。一旦你做了一次,你就会一直这样做所以再说一遍,如果你觉得这东西卡住了,不要害怕,它只需要几分钟。所以就等着一切安装完毕。

然后我们就开始了。现在我们要对其他部分做同样的事情。所以选择,点击复制,然后点击右键,粘贴,然后按回车。

现在,好了,我们基本完成了,因为我们只剩下一行了。所以现在再来一次,就像其他的一样,右击复制,

然后右击粘贴,按回车键,如果你做的一切正确,应该给你一个公共的URL,如果你点击它,将加载最新版本的Web界面。

恭喜你!现在你正在你租用的3090GPU上运行最新版本的oobabooga 文本生成web界面

但现在从技术上讲,我们仍然没有完成,因为我们需要下载一个我们想要使用的模型。因此,让我们举个例子,你想使用Pygmalion130亿参数模型,这样你就可以做一些性感的schmexy的角色扮演。
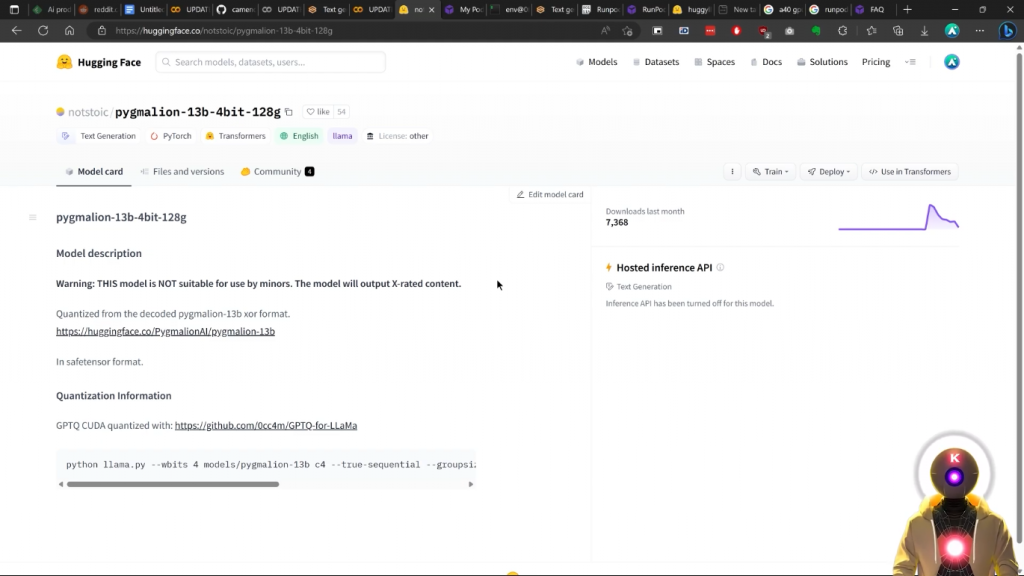
好吧,你可以点击下面描述中的链接,你就会到达这个页面,然后你要点击这里的小图标,复制整个名称。然后在模型标签下,在下载自定义模型或LoRa下,你要在这里粘贴这个名字,然后点击下载。
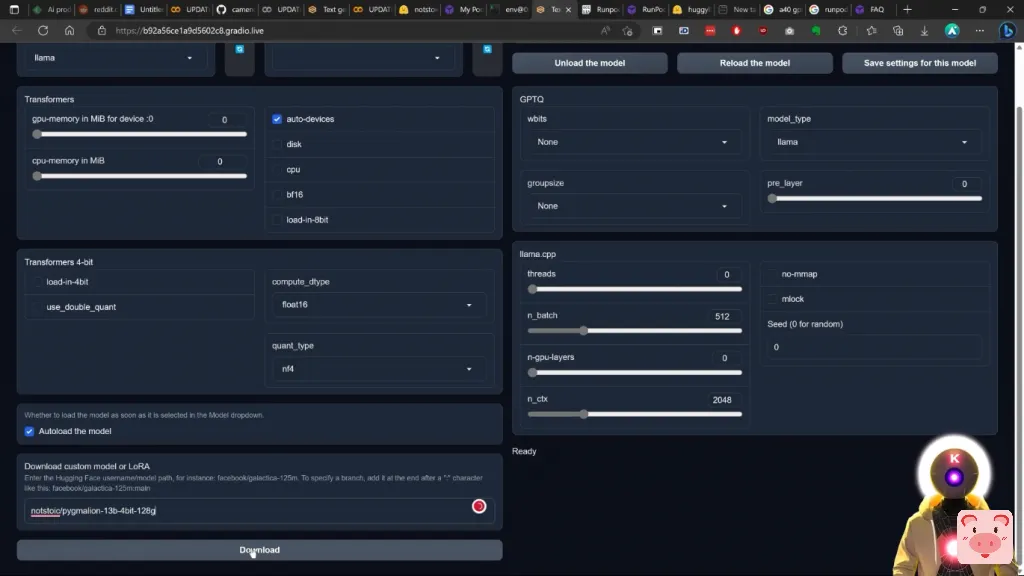
这将开始下载你的模型。现在再次强调,要有耐心,可能需要一些时间,毕竟这是一个7GB的模型,
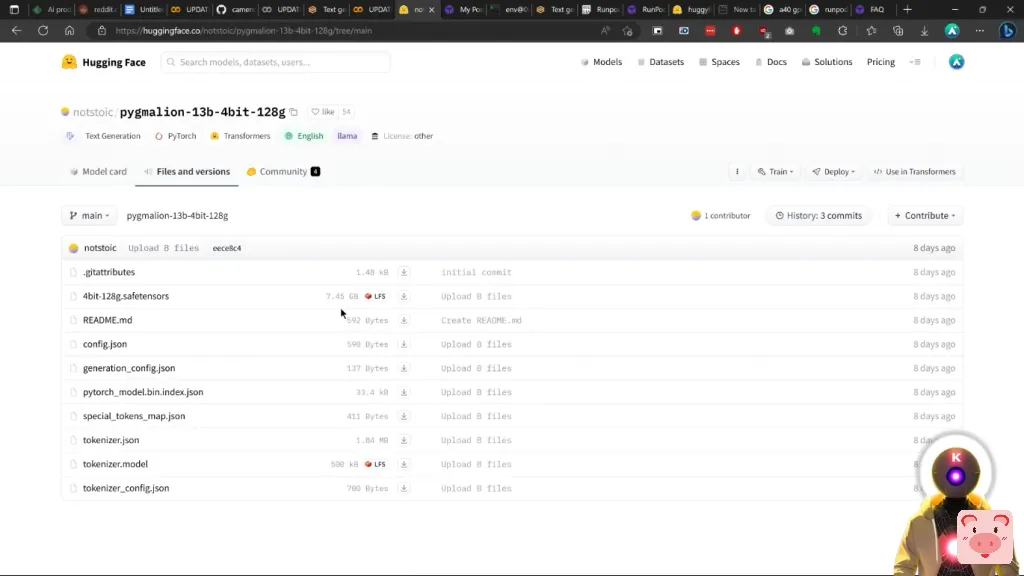
但下载速度相当不错, 所以应该是相当快。是的,就这样,在大约1分钟内,我们为Pygmalion 130亿模型下载了个8GB的文件。
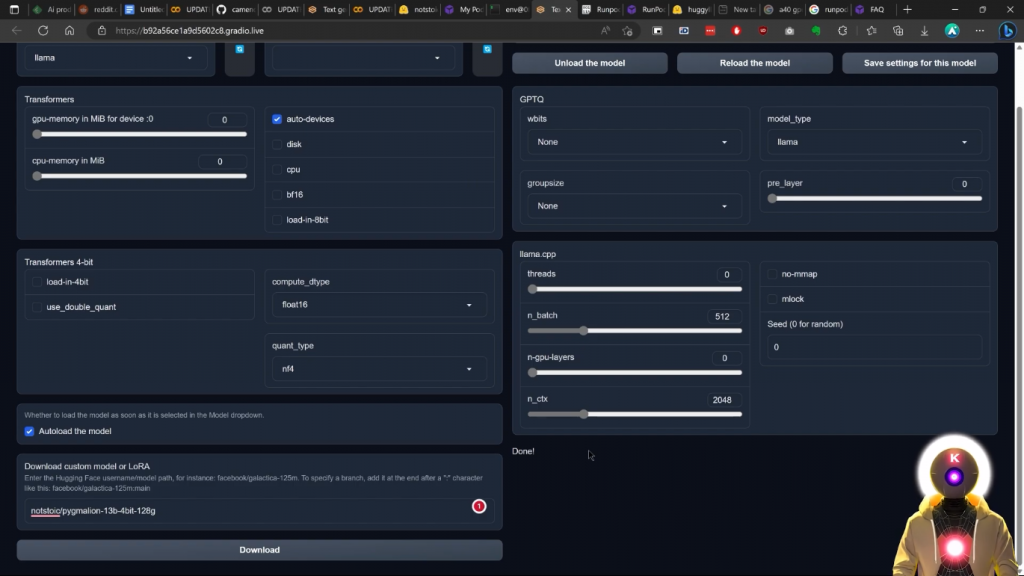
现在,如果你想加载模型,首先你要取消对自动加载模型的勾选,这很烦人,然后你要点击这里来刷新列表,然后选择Pygmalion 130亿模型。确保你已经激活了自动设备,这里的GPTQ参数,你要选择WBITS为4,组大小为128,模型类型为Lama。然后你要点击加载模型的按钮。经过几秒钟的加载,我们的Pygmalion 130亿模型现在已经完全加载并准备使用。

就这么简单。当然,你可以用同样的方法下载和使用任何你想要的模型,也可以用同样的方法使用任何你想要的GPU。在这里,我只选择了3090,因为它是一种最便宜的选择,也是性价比最高的。但是,如果你想要更强大的东西,而且你不介意支付一点,你可以租用像80GB 显存的GPU,以获得更多的性能。、

因此,现在你真的可以有一些乐趣,如果你知道我的意思。好吧,那么现在让我们说,你没有一分钱可以花在GPU租赁网站上。你可以完全免费地运行网络用户界面吗?嗯,你当然可以。因为只是为了你,我做了一个Google Colab Doc,你可以完全免费使用这个Google Colab Doc来运行Web UI,这甚至会下载Pygmalion的130亿参数模型,所以你可以立即使用它。

而所有的事情都是为了让每个人都能非常容易地使用它。非常感谢camenduru提供的代码。

实际上,我使用了他为Google Colab Doc提供的完全相同的代码,但我只是稍微修改了一下,以便它使用最新的web界面版本而要运行这个,当然是非常容易的。首先,你需要做的是只要按这里,运行第一个单元,然后按播放,这样Google Colab就不会断开你的连接。

然后你要按这里的按钮来运行第二个单元。这基本上会自动安装Web UI和Pygmalion 130亿参数模型。

你不需要做任何事情。你只需要等待,直到一切都完成,直到一切都安装好,直到你得到一个公共的URL,就像我们与RunPod一样。

所以还是那句话,要有耐心,直到一切都完成。然后就好了。几分钟后,web界面就安装好了,Pygmalion的130亿参数模型也被下载和安装。在这里,就像RunPod一样,你会看到一个公共的URL,如果你点击它,将加载Web界面和Pygmalion 130亿参数模型,你现在就可以使用。

就这么简单。当然,就像RunPod一样,你可以在这里输入另一个模型的名称,并下载任何你想要的模型,并使用它,就像这是在你的本地计算机上一样。然而,你可能会想, 好吧,那么我为什么要使用RunPod并付钱,而我可以完全免费地使用Google Colab Doc?嗯,这是因为你在Google Colab Doc的免费版本上收到的GPU通常是具有15G左右显存的GPU,这意味着如果你想运行更大、更强大的模型,你将很快耗尽内存。

因此,基本上所有超过130亿的参数模型与4位量化的模型,当然不能在Google Colab Doc上运行。然而,如果你不在乎,如果你只是想用它来和你的人工智能女友交谈,使用Pygmalion 130亿参数模型,那么,在这种情况下,你可以简单地使用Google Colab Doc。 你不需要为此使用RunPod。但如果你想使用一个更大的模型,一个更强大的模型,我明天可能会给你看,那么,在这种情况下,你将需要一个非常强大的GPU,这就是为什么像RunPod这样的网站真的是上帝的礼物。
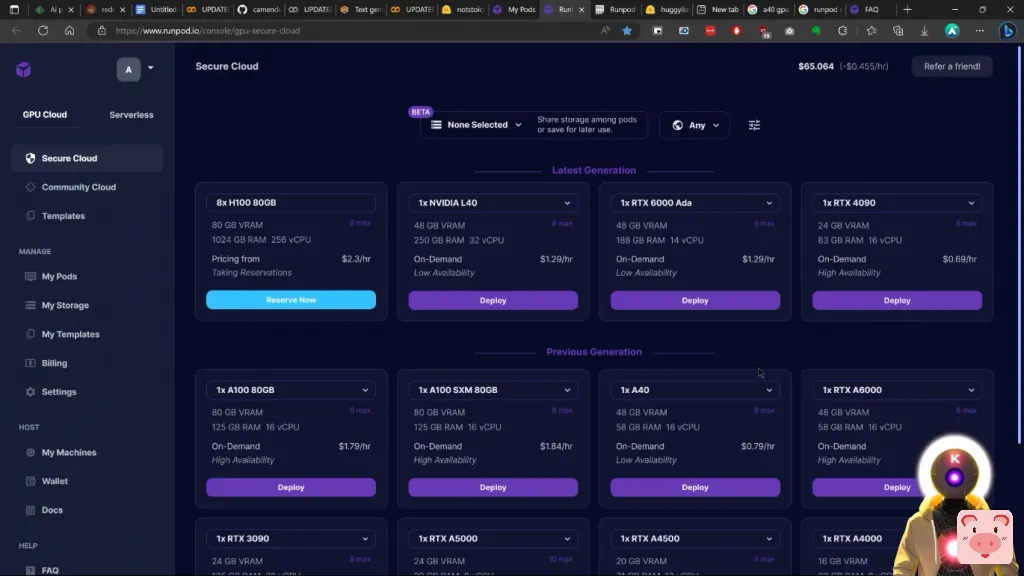
这真的是超级有用。所以是的,就这样,伙计们。现在我认为,无论你是谁,来自哪里,你的预算是多少,你应该能够完全免费地运行网络用户界面,没有任何限制,并享受一些性感的角色扮演,不受任何审查。所以请尽情享受吧。这就是今天的节目了,谢谢大家的收看。别忘了订阅并点赞,这对于YouTube算法来说非常重要。同时,非常感谢我的Patreon支持者们一直以来对我视频的支持。你们真的太棒了!正是你们的支持,我才能为你们制作这些视频。所以真的非常感谢你们,下次再见!拜拜!