用AI翻唱歌曲?之前火爆全网的“AI孙燕姿” | Retrieval-based-Voice-Conversion-WebUI
作者:FancyPig | 发布时间: | 更新时间:
杂谈
前几天看到下面的这个“AI孙燕姿”粤语版《爱来的太迟》视频,然后就有了本期视频教程😊
相关阅读
视频讲解
🎉🎶欢迎来到更多Nerdy Roden的极客世界!🌟今天我们将探索神奇的语音转语音技术!🗣️想象一下,用AI变声器把你的声音变成任何人的声音!😱
🚀现在,这一切都可以在一个应用程序中完成,训练速度之快令人惊叹!😎让我来为你介绍:基于检索的语音转换web用户界面!🌐
🎤🎵你可能知道,用AI将人声变成唱歌声音可是一项不小的挑战。🏋️♂️🎶想象一下,让约翰·塞纳💃跳舞,同时听亚伯拉罕·林肯🎤唱最新的K-pop歌曲🎼!首先,你需要收集一堆语音样本,处理它们,训练一个模型,将人声与你要改变的音乐轨道分开,在这些人声上运行你的新AI模型,最后将它们与音乐混合在一起。😅
🥳幸运的是,这个网络界面让所有这些变得轻而易举!🌠质量如何呢?让我们来听一听吧!👂我使用了Pixabay上的一首例子,在不到30分钟的训练时间里,我就可以成为唱歌的人!🎤🎶
🎧让我们先听一下原声片段,然后再听听AI改变后的声音,是不是听起来像我呢?🤔💡想自己试试吗?那就跟着我,我将教你如何实现这一切!👩🏫
💻🐍像使用任何Python软件一样,安装简单易行。最重要的是,它可以在各种操作系统上运行,甚至是微软的Windows!🖥️🎉
🔥快来加入我们,一起探索这个神奇的语音转换世界!🚀🎙️
相关项目
- Retrieval-based-Voice-Conversion-WebUI Github项目地址 https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
- Realtime Voice Changer Github项目地址 https://github.com/w-okada/voice-changer
- VoiceConversionWebUI HuggingFace项目地址 https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main
- 下面视频演示中相关音乐的下载地址 https://pixabay.com/music/happy-childrens-tunes-ponyo-cliff-cartoon-animation-movie-music-song-1383/
图文讲解
你好,欢迎来到更多Nerdy Roden的极客世界,语音转语音技术,是吗?




如果你不知道这是什么,它基本上允许你把一种声音变成另一种声音。有点像有一个人工智能变声器。最重要的是,你所需要的一切现在都在一个应用程序中,而且它的训练也非常快。这就是,基于检索的语音转换web用户界面。

完全不用担心太多。你可能知道,人工智能唱歌的声音转换可能是一项任务,因为在你创建你的杰作视频之前,有多个阶段涉及到约翰-塞纳跳舞,同时听亚伯拉罕-林肯唱最新的K-pop歌曲。

首先,你需要收集一堆语音样本,处理它们,训练一个模型,将人声与你要改变的音乐轨道分开,如果你还没有分开的话,在这些人声上运行你的新人工智能模型,最后将它们与音乐混合在一起。

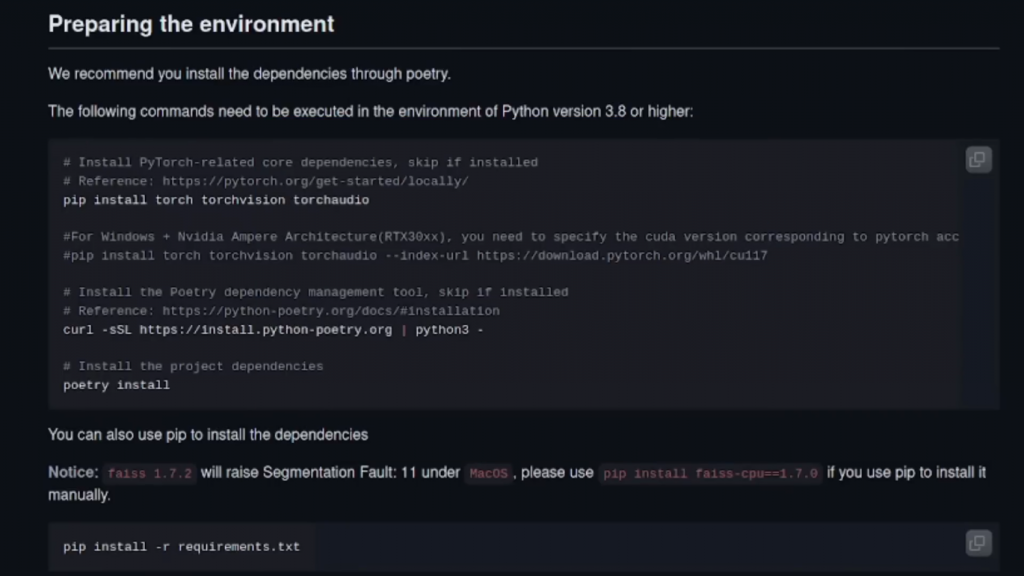
值得庆幸的是,现在所有这些都可以通过这个网络界面完成,质量如何呢?好吧,让我们来听一听。我使用了Pixabay上的一首例子,就是这样,这意味着在不到30分钟的训练时间里,我就可以成为唱歌的人。所以,让我们快速听一下原声片段,这样我们就知道我要转换什么了。然后现在这个声音被这个AI改变了,听起来像我。想自己做这个吗?那就跟着我,我将向你展示具体的方法。与任何Python软件一样,安装绝对是轻而易举的,最重要的是,它可以在一系列的操作系统上工作,甚至是微软的Windows。这里有一个小表,上面有一些要求。

如果你使用微软的Windows,如果你正在使用,很抱歉,我确实希望事情变得更好,你可以做的是下载并安装7-zip,

从Hugging Face页面下载rvc-beta 7zip文件,
https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main

解压,然后使用go-web.bat。正常的安装也可以像他们在这里做的那样,
尽管你可能想下载7-zip档案,因为那里面有所有的模型。就个人而言,我使用Anaconda的虚拟Python 3.10环境进行正常安装,因为我喜欢简单的应用管理。如果你喜欢使用Google Colab,也有一个Google Colab可用。
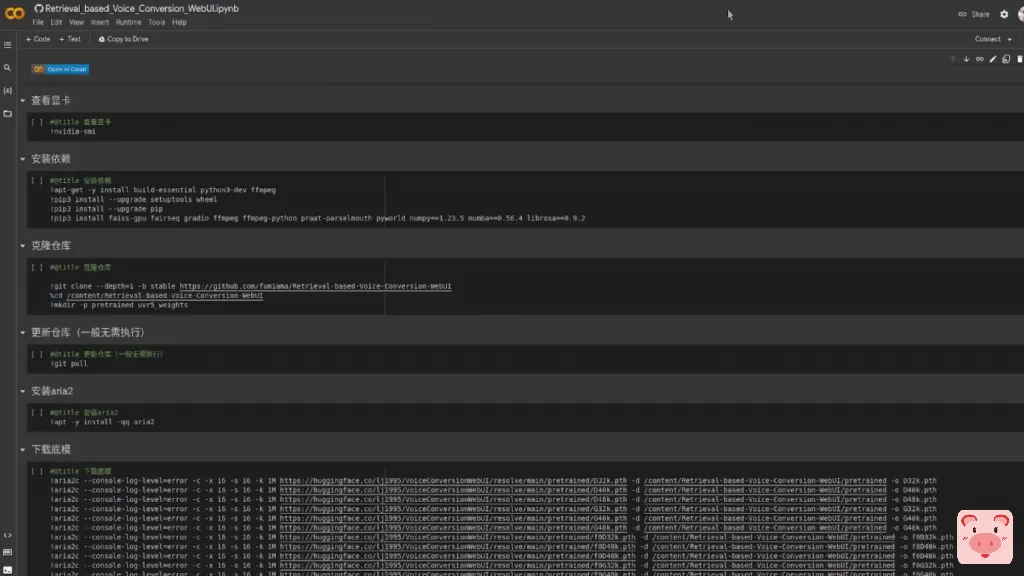
因此,无论你选择何种安装方法,你现在应该已经有了你的网络界面并开始运行。
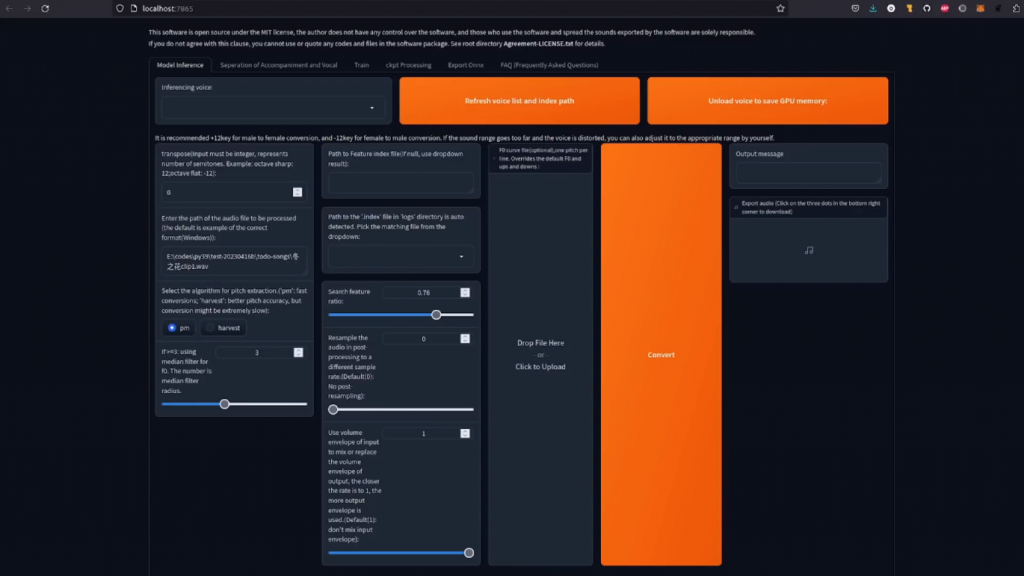
让我们潜入这个迷人的语音转语音技术的世界,看看我们能创造出什么惊人的东西。如果你已经有一个模型,你可以直接进行模型推理,或者像我一样,你可以从训练一个模型开始。如果你没有,还有训练标签。然而,在我们深入研究训练过程之前,我们先快速浏览一下这五个标签。所以首先,你已经有了模型推理,你已经有了伴奏和声乐的分离、训练,检查点处理,所以你可以把检查点混在一起,导出ONNX,这一点我从来没有用过,还有一个FAQ也是如此。首先,如前所述,我们将从训练标签开始,因为这是你将创建你的第一个语音模型的地方。第一步,对于实验名称,只需输入你想给你的项目的名称。所以你可以这样做,例如,Nerdy,因为那是我。至于采样率,我个人更喜欢总是使用40k,而且我总是将他设置为true,因为这似乎是最好的。模型结构,你可以选择版本1或版本2。就个人而言,我更喜欢版本2。线程数,我想,可能会自动选择。

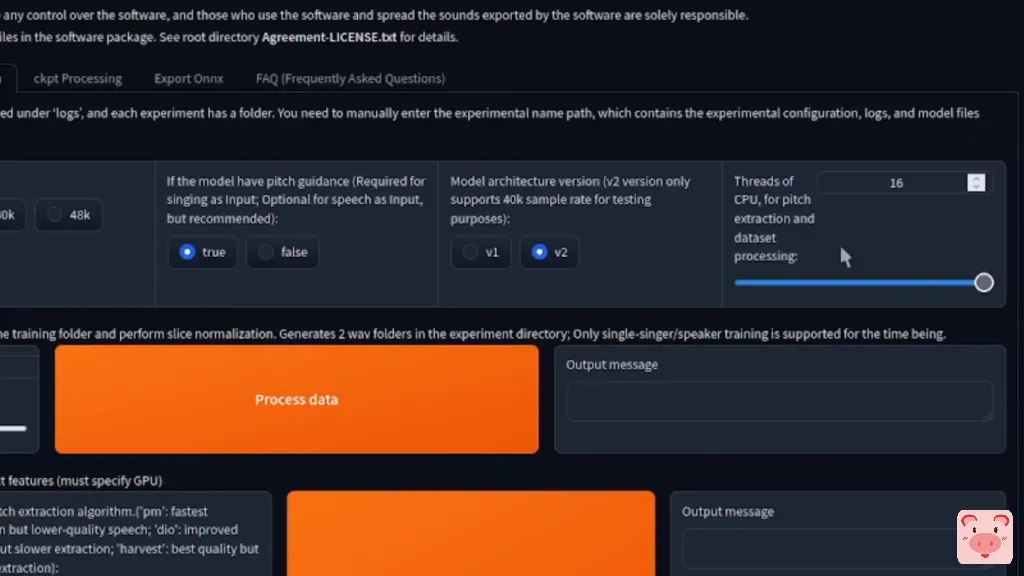
恭喜你,你现在已经完成了第一步。下一步是第2A步。

它在这里问的第一件事是训练目录的路径。如果你不熟悉计算机上的文件和目录等术语,这部分可能会很令人困惑。你可以把目录看作是电脑里的盒子,在这个例子中,你可以用它来组织你的文件。我把它们放到训练目录中。所以,这就是我的路径,traing/nerd
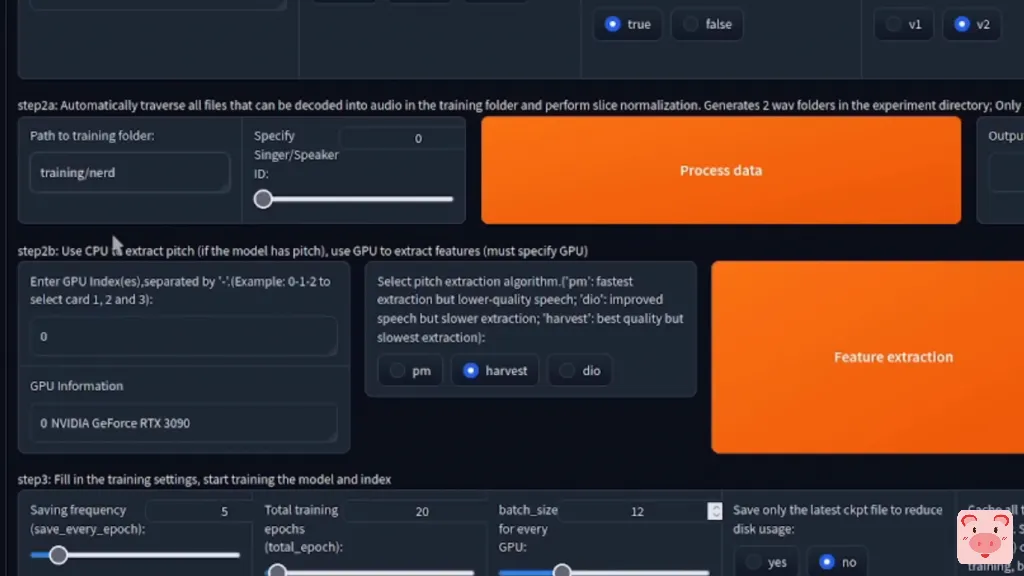
如果我们快速看一下这个目录,你可以看到,它绝对充满了音频文件。

如果你的名字不同,你可能希望使用其他东西,但这完全取决于你。尽管我已经把我的样本分成了大约250段,但实际上你不需要太担心,因为这个程序会自动处理长的音频并进行相应的分割。一般来说,总的音频要求在10到50分钟之间。任何人声都可以,唱歌、说话都可以,只要确保背景中没有任何音乐。应该全部是一个人,只有人声好了,现在你已经把所有的样本放在目录里了,你可以直接点击处理数据。
这将需要几秒钟,为你处理所有的样本。

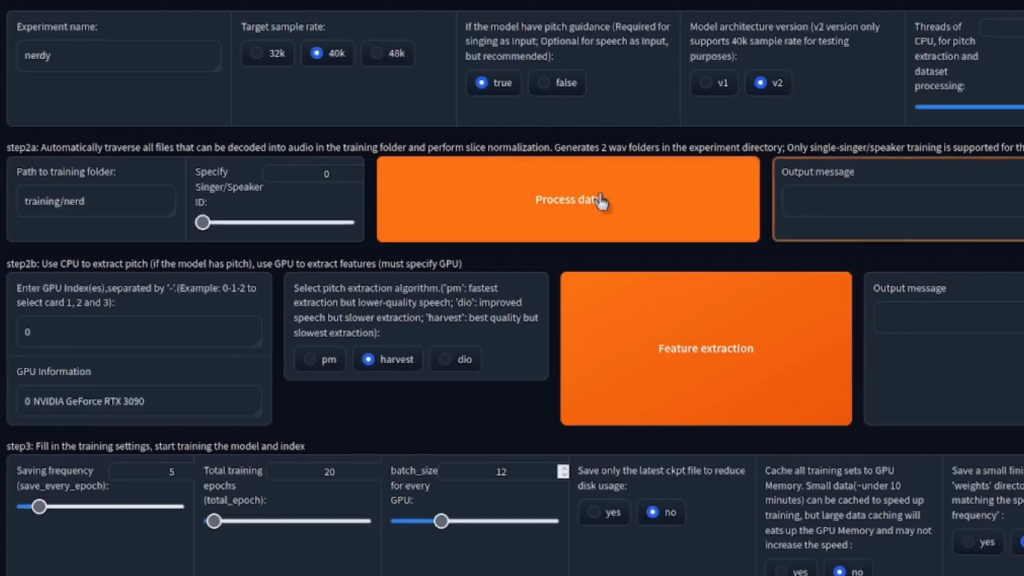
现在你已经准备好进入第2B步。

如果你有多块显卡,那么你可以把它们放在这里,但我只有一块GPU,所以我只是保持原样。默认值绝对没问题。接下来,您可以进行音高提取,它有三个选项。就个人而言,我总是选择harvest。pm速度快但质量低,dio稍慢但质量好,而harvest是最慢的但质量最好。因此,在那里选择了harvest,我只是点击特征提取。

这将花几秒钟时间,完成这个任务。
第三步。

好了,在这里,大多数情况下,你可以继续,点击那个一键训练按钮。

大约10分钟后回来,你就会有一个模型。然而,如果你像我一样,确实喜欢改变一些东西,你在那里有一些选项,用于保存完整模型的频率、总的历时数、GPU批次大小,以及一些保存的选项。就我个人而言,对于第二版的模型,我喜欢的设置方式是将其设置为10。我做的总训练历时为200,这是你需要的最大的历时。由于我有一个非常大的GPU,我有24G的VRAM,批次大小为40,因为这是我的GPU可以处理的最大数量。

我喜欢点击是,只保存最新的检查点。我把缓存全部放在no上,我说yes来保存小的成品模型。

因此,在你通过一键式训练进行模型训练时,我建议你也去看一下常见问题标签。

这里有相当多的信息,特别有用的是问题9和问题10。

总共多少个 epochs 是最佳的,需要多少训练集的时间。
现在你已经有了你的第一个语音模型,现在是时候做AI语音转语音的事情了。如果你已经有了你想转换的声音,你可以直接跳到模型推理。

但是,如果你想做的事情是改变一首歌曲的歌手,而你又没有的人声素材,就像我在这里做的那样,那么你首先需要把这些人声从背景音乐中分离出来,这就是分离标签的用武之地。

再一次,那些文件和目录开始发挥作用,因为你需要知道你的音乐文件保存在哪里。
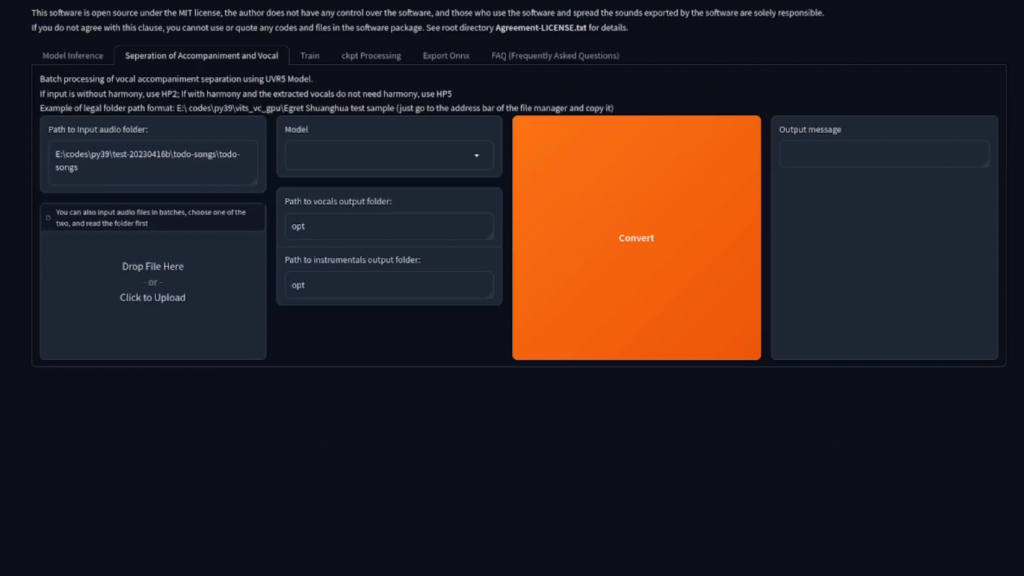
第一个方框是如果你想从一个给定的目录中转换多个文件,因为我倾向于一次只做一个,我删除这个,然后用下面的方框代替。模型选择有两个选项,就像上面说的那样,HP2用于没有和声的输入,或者如果有和声且提取的人声不需要和声,则使用HP5。

基本上,如果你不确定,都用,听一下输出,看看哪个最适合你。在我的例子中,我打算在这里使用HP2。
默认情况下,输出会进入OPT目录,所以如果你愿意,可以随意改变输出路径。当你准备好了,按下巨大的橙色转换按钮,你就可以把人声从音乐中分离出来了,让我们快速听一下。

当然,这里有几秒钟的沉默。好了。总之,这做得很好。我们已经得到了人声,没有音乐,即使声音里有一点回声或其他东西。

好了,现在我们准备好了,可以进行推理了。
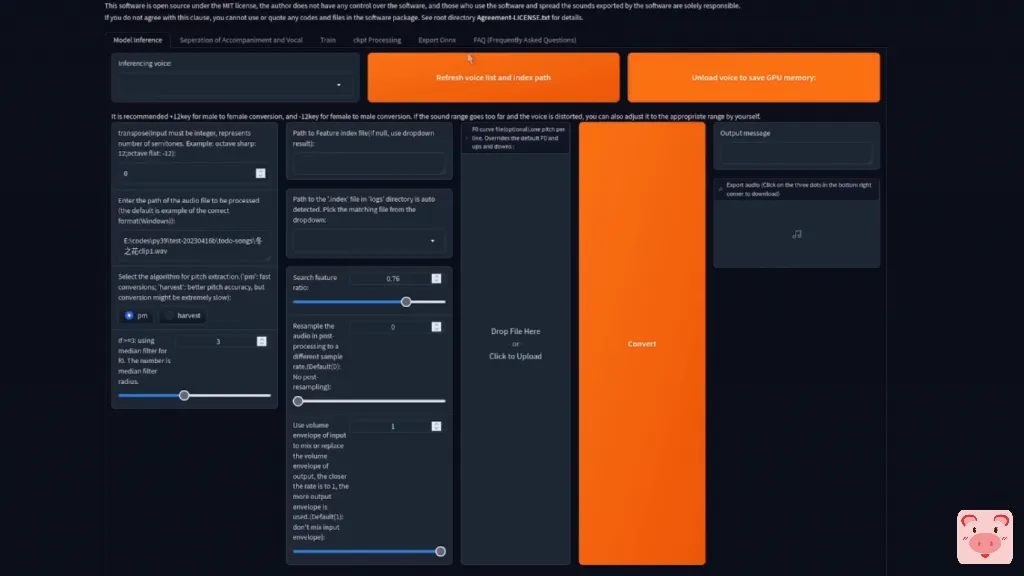
这一页看起来确实很大,但实际上它是两个在一起的东西。 上半部分是单声道转换,那里也有一个批处理的。因此,我将只是通过这一个。批处理基本上是一样的,但你一次要一次加载。同样,这里的一切都很简单。按下那个巨大的刷新按钮,然后你应该看到你的选项出现在这个小下拉中。

我的列表绝对是巨大的,因为所有的女孩都会同意,但你第一次可能只有一个选项在那里。

所以选择那个。我打算选那个,因为那是我训练有素的声音。接下来,你要选择一个音高,就像上面说的那样。对于从低到高的转换,用+12。如果差不多,就用0。

而对于高声到低声的转换,用-12。在这种情况下,源声音是相当高的。我的声音有点低,所以我要用-12。再一次,那些文件和目录在这里发挥了作用。所以把你的人声的路径放进去。如果你做了那个默认的声音分离,那么你的OPT目录里就会有两个文件。你要的是开始人声的那个。所以在我的OPT目录中,有那个WAV文件的长名字,就是以人声开头的那个。对于音高提取,也是如此,pm是快速的,harvest是最佳的。所以我喜欢选择harvest。除了这个索引的路径,其他的我都保留在默认状态,这个路径应该有一个下拉菜单。

这里有一个我想使用的,因为它与那个推理声音相匹配。好了,现在你可以继续,点击那个非常小的转换按钮,在短短的几秒钟内,你应该有你的输出。
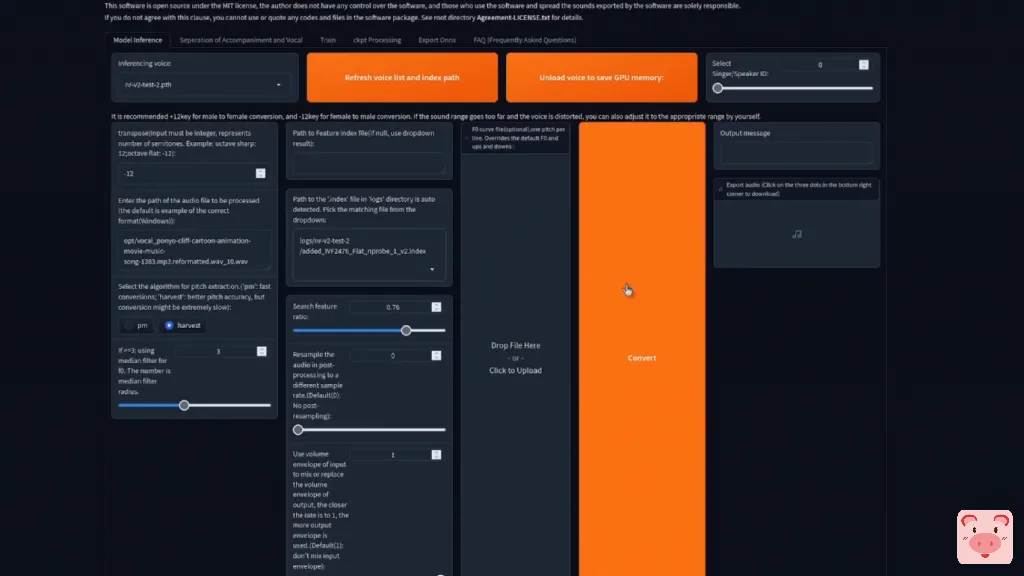
就在那里。对,就在那里。

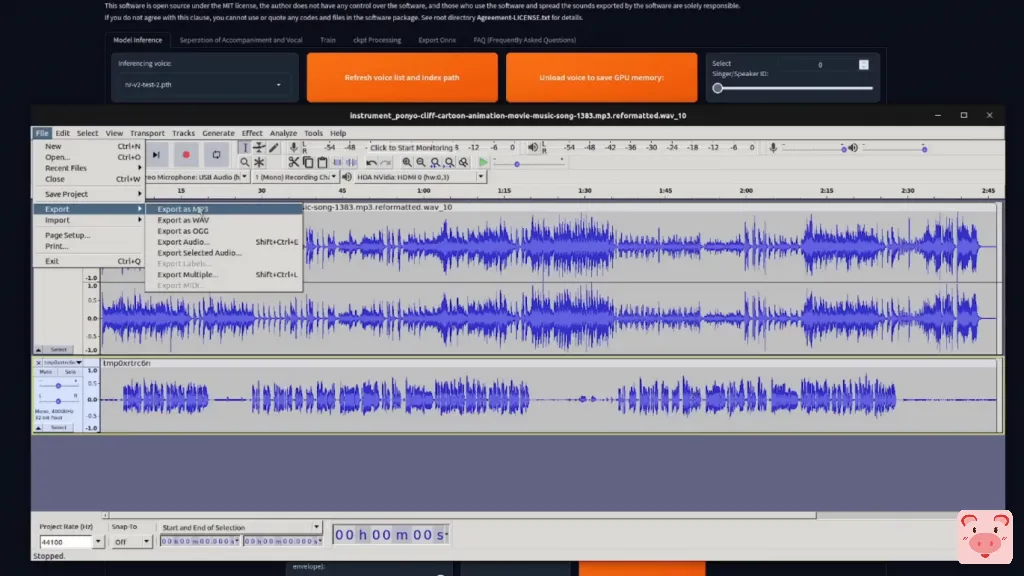
这可真够酷的。这是相当酷的。这就是我。现在你可以右键点击它,将音频保存为。

我也要把它放在我的OPT目录里。我在这里使用Audacity。

我已经有了器乐,所以我只需把另一个声音拖进来,然后我可以点击文件,导出为任何我想要的,它将把这两个声音混合在一起。
另外,如果你认为这很酷,你可能也会喜欢本期视频。